
Redis簡明教程
本文公眾號來源:柳樹的絮叨叨
作者:SexyCode
Redis是啥?用Redis官方的話來說就是:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.
Redis是一個開源的、基于內(nèi)存的數(shù)據(jù)結(jié)構(gòu)存儲器,可以用作數(shù)據(jù)庫、緩存和消息中間件。
What??? 這玩意把數(shù)據(jù)放在內(nèi)存,還想當(dāng)數(shù)據(jù)庫使?為什么是“data structure store”,而不是“data store”?還能用作消息中間件??你這么牛,你咋不上天?
是的,Redis就是這么牛 ( ̄▽ ̄)~*
我們只需從Redis最常用的功能——緩存,開始了解,上面那些問題也就迎刃而解了。
1、你會怎樣實現(xiàn)一個緩存?如果你是Redis新手,或者此前從未接觸過Redis,那么這篇文章不僅能幫你快速了解Redis的實現(xiàn)原理,還能幫你了解一些架構(gòu)設(shè)計的藝術(shù);如果你是Redis老司機(jī),那么,希望這篇文章能帶給你一些新的東西。
假設(shè)讓你設(shè)計一個緩存,你會怎么做?
相信大家都會想到用Map來實現(xiàn),就像這樣:
String value = map.get("someKey");
if(null == value) {
? value = queryValueFromDB("someKey");
}
那用什么Map呢?HashMap、TreeMap這些都線程不安全,那就用HashTable或者ConcurrentHashMap好了。
不管你用什么樣的Map,它的背后都是key-value的Hash表結(jié)構(gòu),目的就是為了實現(xiàn)O(1)復(fù)雜度的查找算法,Redis也是這樣實現(xiàn)的,另一個常用的緩存框架Memcached也是。
Hash表的數(shù)據(jù)結(jié)構(gòu)是怎樣的呢?相信很多人都知道,這里簡單畫個圖: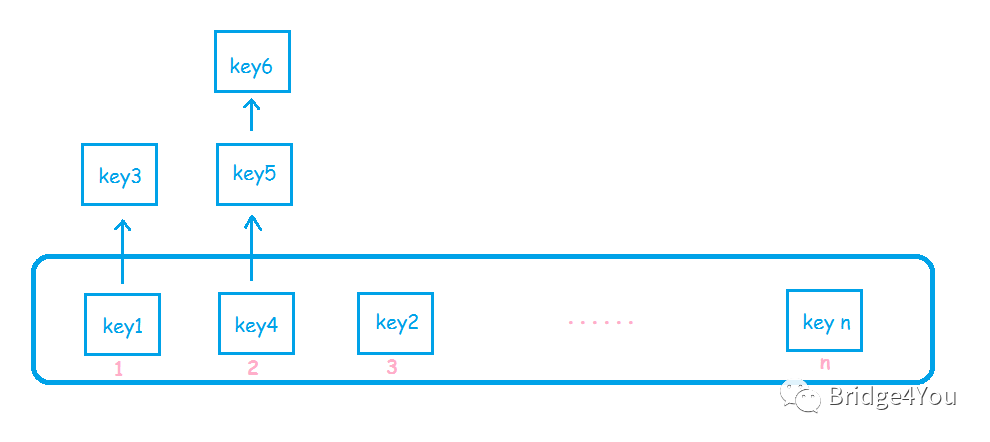
簡單說,Hash表就是一個數(shù)組,而這個數(shù)組的元素,是一個鏈表。
為什么元素是鏈表?理論上,如果我們的數(shù)組可以做成無限大,那么每來一個key,我們都可以把它放到一個新的位置。但是這樣很明顯不可行,數(shù)組越大,占用的內(nèi)存就越大。
所以我們需要限制數(shù)組的大小,假設(shè)是16,那么計算出key的hash值后,對16取模,得出一個0~15的數(shù),然后放到數(shù)組對應(yīng)的位置上去。
好,現(xiàn)在key1放到index為2的位置,突然又來了一個key9,剛好他也要放到index為2的位置,那咋辦,總不能把人家key1給踢掉吧?所以key1的信息必須存儲在一個鏈表結(jié)構(gòu)里面,這樣key9來了之后,只需要把key1所在的鏈表節(jié)點的next,指向key9的鏈表節(jié)點即可。
這樣就沒問題了嗎?想象一下,如果鏈表越來越長,會有什么問題?
很明顯,鏈表越長,Hash表的查詢、插入、刪除等操作的性能都會下降,極端情況下,如果全部元素都放到了一個鏈表里頭,復(fù)雜度就會降為O(n),也就和順序查找算法無異了。(正因如此,Java8里頭的HashMap在元素增長到一定程度時會從鏈表轉(zhuǎn)成一顆紅黑樹,來減緩查找性能的下降)
怎么解決?rehash。
關(guān)于rehash,這里就不細(xì)講了,大家可以先了解一下Java HashMap的resize函數(shù),然后再通過這篇文章:A little internal on redis key value storage implementation 去了解Redis的rehash算法,你會驚訝的發(fā)現(xiàn)Redis里頭居然是兩個HashTable。
好,上面帶大家從一個及其微觀的角度窺視了Redis,下面幾個小節(jié),再帶大家用宏觀的視角去觀察Redis。
2、C/S架構(gòu)作為Redis用戶,我們要怎樣把數(shù)據(jù)放到上面提到的Hash表里呢?
我們可以通過Redis的命令行,當(dāng)然也可以通過各種語言的Redis API,在代碼里面對Hash表進(jìn)行操作,這些都是Redis客戶端(Client),而Hash表所在的是Redis服務(wù)端(Server),也就是說Redis其實是一個C/S架構(gòu)。
顯然,Client和Server可以是在一臺機(jī)器上的,也可以不在: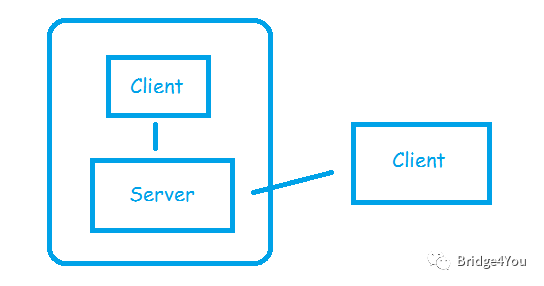
如果你想玩一下Redis,又不想自己搭建環(huán)境,可以試一下這一個非常好玩的網(wǎng)頁:Try Redis,你可以按照上面的提示,熟悉Redis的基礎(chǔ)命令,感受一下Redis的C/S模式。
值得一提的是,Redis的Server是單線程服務(wù)器,基于Event-Loop模式來處理Client的請求,這一點和NodeJS很相似。使用單線程的好處包括:
不必考慮線程安全問題。很多操作都不必加鎖,既簡化了開發(fā),又提高了性能;
減少線程切換損耗的時間。線程一多,CPU在線程之間切來切去是非常耗時的,單線程服務(wù)器則沒有了這個煩惱;
當(dāng)然,單線程服務(wù)器最大的問題自然是無法充分利用多處理器,不過沒關(guān)系,別忘了現(xiàn)在的機(jī)器很便宜。請繼續(xù)往下看。
3、集群好,現(xiàn)在我們已經(jīng)知道了Redis是一個C/S架構(gòu)的框架,那就讓我們開始用Redis來緩存信息,緩解數(shù)據(jù)庫的壓力吧!
我們搭起了這樣一個框架,一臺客戶端,一臺Redis緩存服務(wù)器: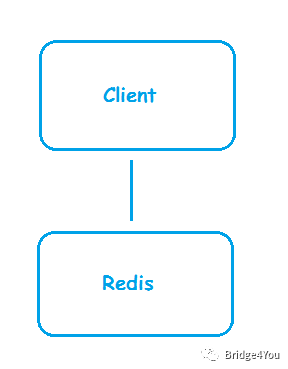
一開始風(fēng)和日麗,系統(tǒng)運行良好。
后來,我們系統(tǒng)中使用Redis的客戶端越來越多,變成了這樣: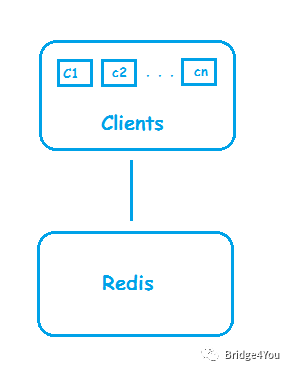
這帶來了兩個問題:
Redis內(nèi)存不足:隨著使用Redis的客戶端越來越多,Redis上的緩存數(shù)據(jù)也越來越大,而一臺機(jī)器的內(nèi)存畢竟是有限的,放不了那么多數(shù)據(jù);
Redis吞吐量低:客戶端變多了,可Redis還是只有一臺,而且我們已經(jīng)知道,Redis是單線程的!這就好比我開了一家飯店,一開始每天只有100位客人,我雇一位服務(wù)員就可以,后來生意好了,每天有1000位客人,可我還是只雇一位服務(wù)員。一臺機(jī)器的帶寬和處理器都是有限的,Redis自然會忙不過來,吞吐量已經(jīng)不足以支撐我們越來越龐大的系統(tǒng)。
分析完問題,解決思路也就再清晰不過了——集群。一臺Redis不夠,那就再加多幾臺!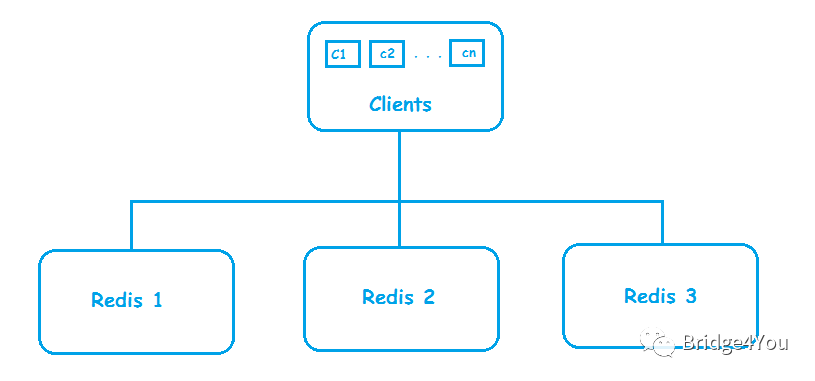
客戶端的請求會通過負(fù)載均衡算法(通常是一致性Hash),分散到各個Redis服務(wù)器上。
通過集群,我們實現(xiàn)了兩個特性:
擴(kuò)大緩存容量;
提升吞吐量;
解決了上面提到的兩個問題。
4、主從復(fù)制好,現(xiàn)在我們已經(jīng)把Redis升級到了集群,真可謂效果杠杠的,可運行了一段時間后,運維又過來反饋了兩個問題:
數(shù)據(jù)可用性差:如果其中一臺Redis掛了,那么上面全部的緩存數(shù)據(jù)都會丟失,導(dǎo)致原來可以從緩存中獲取的請求,都去訪問數(shù)據(jù)庫了,數(shù)據(jù)庫壓力陡增。
數(shù)據(jù)查詢緩慢:監(jiān)測發(fā)現(xiàn),每天有一段時間,Redis 1的訪問量非常高,而且大多數(shù)請求都是去查一個相同的緩存數(shù)據(jù),導(dǎo)致Redis 1非常忙碌,吞吐量不足以支撐這個高的查詢負(fù)載。
問題分析完,要想解決可用性問題,我們第一個想到的,就是數(shù)據(jù)庫里頭經(jīng)常用到的Master-Slave模式,于是,我們給每一臺Redis都加上了一臺Slave: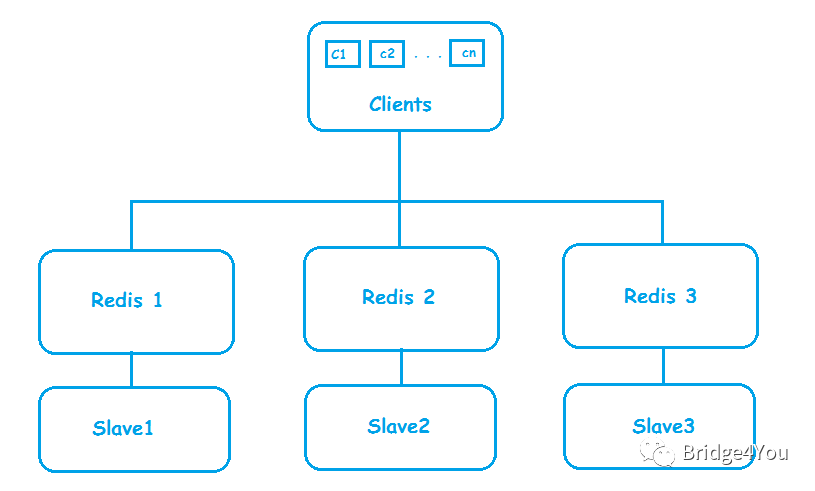
通過Master-Slave模式,我們又實現(xiàn)了兩個特性:
數(shù)據(jù)高可用:Master負(fù)責(zé)接收客戶端的寫入請求,將數(shù)據(jù)寫到Master后,同步給Slave,實現(xiàn)數(shù)據(jù)備份。一旦Master掛了,可以將Slave提拔為Master;
提高查詢效率:一旦Master發(fā)現(xiàn)自己忙不過來了,可以把一些查詢請求,轉(zhuǎn)發(fā)給Slave去處理,也就是Master負(fù)責(zé)讀寫或者只負(fù)責(zé)寫,Slave負(fù)責(zé)讀;
為了讓Master-Slave模式發(fā)揮更大的威力,我們當(dāng)然可以放更多的Slave,就像這樣: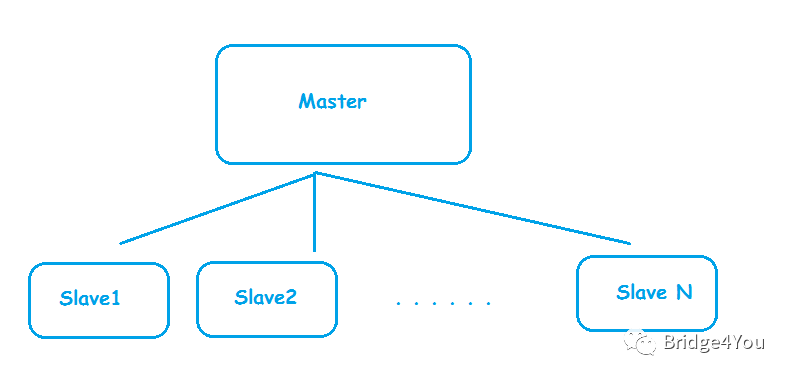
可這樣又引發(fā)了另一個問題,那就是Master進(jìn)行數(shù)據(jù)備份的工作量變大了,Slava每增加一個,Master就要多備份一次,于是又有了Master/slave chains的架構(gòu):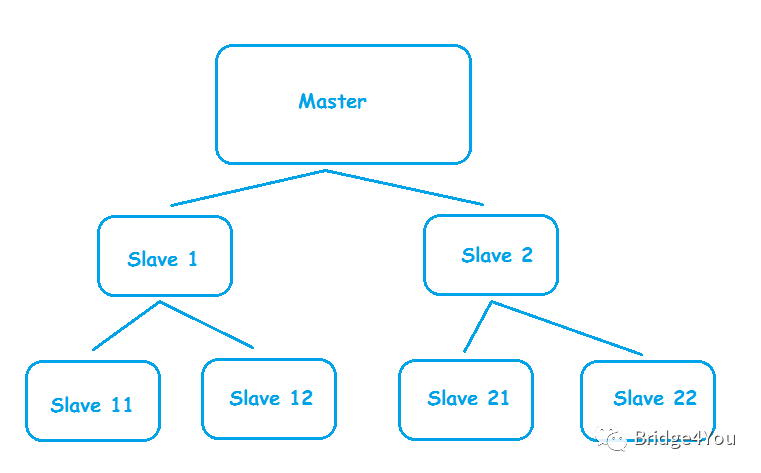
沒錯,我們讓Slave也有自己的Slave,有點像古代的分封制。
這樣最頂層的Master的備份壓力就沒那么大了,它只需要備份兩次,然后讓那它底下的那兩臺Slave再去和他們的Slave備份。
5、Redis沒那么簡單關(guān)于Master/slave chains,大家可以參考這篇文章?RedisLab Master/slave chains
這篇文章只是帶大家逛一逛Redis的莊園,讓大家從微觀到宏觀,對Redis有一個初步的了解。
事實上,Redis內(nèi)部要處理的問題還有很多:
數(shù)據(jù)結(jié)構(gòu)。文章一開頭提到了,Redis不僅僅是數(shù)據(jù)存儲器,而是數(shù)據(jù)結(jié)構(gòu)存儲器。那是因為Redis支持客戶端直接往里面塞各種類型的數(shù)據(jù)結(jié)構(gòu),比如String、List、Set、SortedSet、Map等等。你或許會問,這很了不起嗎?我自己在Java里寫一個HashTable不也可以放各種數(shù)據(jù)結(jié)構(gòu)?呵呵,要知道你的HashTable只能放Java對象,人家那可是支持多語言的,不管你的客戶端是Java還是Python還是別的,都可以往Redis塞數(shù)據(jù)結(jié)構(gòu)。這一點也是Redis和Memcached相比,非常不同的一點。當(dāng)然Redis要支持?jǐn)?shù)據(jù)結(jié)構(gòu)存儲,是以犧牲更多內(nèi)存為代價的,正所謂有利必有弊。關(guān)于Redis里頭的數(shù)據(jù)結(jié)構(gòu),大家可以參考:Redis Data Types
剔除策略。緩存數(shù)據(jù)總不能無限增長吧,總得剔除掉一些數(shù)據(jù),好讓新的緩存數(shù)據(jù)放進(jìn)來吧?這就需要LRU算法了,大家可以參考:Redis Lru Cache
負(fù)載均衡。用到了集群,就免不了需要用到負(fù)載均衡,用什么負(fù)載均衡算法?在哪里使用負(fù)載均衡?這點大家可以參考:Redis Partitioning
Presharding。如果一開始只有三臺Redis服務(wù)器,后來發(fā)現(xiàn)需要加多一臺才能滿足業(yè)務(wù)需要,要怎么辦?Redis提供了一種策略,叫:Presharding
數(shù)據(jù)持久化。如果我的機(jī)器突然全部斷電了,我的緩存數(shù)據(jù)還能恢復(fù)嗎?Redis說,相信我,可以的,不然我怎么用作數(shù)據(jù)庫?去看看這個:Redis Persistence
數(shù)據(jù)同步。這篇文章里提到了主從復(fù)制,那么Redis是怎么進(jìn)行主從復(fù)制的呢?根據(jù)CAP理論,既然我們已經(jīng)選擇了集群,也就是P,分區(qū)容忍性,那么剩下那兩個,Consistency和Availability只能選擇一個了,那么Redis到底是支持最終一致性還是強(qiáng)一致性呢?可以參考:Redis Replication
……
官網(wǎng):
Redis官網(wǎng)(之所以建議看官網(wǎng),是因為這是一手的學(xué)習(xí)資料,其他資料都最多只能算二手,一手資料意味著最權(quán)威,準(zhǔn)確性最高)
Try Redis(如果你懶得裝環(huán)境,這或許是一個不錯的選擇… )
書籍(可以參考):
Redis實戰(zhàn)
Redis設(shè)計與實現(xiàn)
Redis開發(fā)與運維
公眾號文章導(dǎo)航:兩年嘔心瀝血的文章!(包含原創(chuàng)Redis文章)
長按掃碼可關(guān)注獲取?
在看和分享對我非常重要!