
Fluentd 簡明教程
 如果你的應(yīng)用運(yùn)行在分布式架構(gòu)上,你很可能會(huì)使用集中式日志系統(tǒng)來收集它們的日志,其中我們使用比較廣泛的一個(gè)工具就是 fluentd,包括在容器化時(shí)代用來收集 Kubernetes 集群應(yīng)用日志 fluentd 也是使用非常多的。本我們將解釋它是如何工作的,以及如何根據(jù)需求來調(diào)整配置 fluentd。
如果你的應(yīng)用運(yùn)行在分布式架構(gòu)上,你很可能會(huì)使用集中式日志系統(tǒng)來收集它們的日志,其中我們使用比較廣泛的一個(gè)工具就是 fluentd,包括在容器化時(shí)代用來收集 Kubernetes 集群應(yīng)用日志 fluentd 也是使用非常多的。本我們將解釋它是如何工作的,以及如何根據(jù)需求來調(diào)整配置 fluentd。
基本概念
我們可能有在 bash 中執(zhí)行過 tail -f myapp.log | grep "what I want" > example.log 這樣的命令,這其實(shí)就是 fluentd 比較擅長做的事情,tail 日志或者接收某種形式的數(shù)據(jù),然后過濾轉(zhuǎn)換,最后發(fā)送到后端存儲(chǔ)中,我們可以將上面的命令分成多段來分析。
輸入
tail?-f?myapp.log
我們要對(duì)一個(gè)文件進(jìn)行長期的 tail,每當(dāng)有什么日志信息被添加到文件中,它就會(huì)顯示在屏幕上。這在 fluentd 中叫做**輸入插件**,tail 只是其中之一,但還有很多其他可用的插件。
過濾
|?grep?"what?I?want"
在這里,我們從尾部 -f 的輸出中,只過濾包含我們想要的字符串的日志行,在 fluentd 中這叫做**過濾插件**。
輸出
>?example.log
在這里,我們將 grep 命令過濾后的輸出保存到一個(gè)名為 example.log 的文件中。在 fluentd 中,這就是**輸出插件,**除了寫到文件之外,fluentd 還有很多插件可以把你的日志輸出到其他地方。
這就是 fluentd 的最基本的運(yùn)行流程,你可以讀取日志,然后處理,然后把它發(fā)送到另一個(gè)地方做進(jìn)一步的分析。接下來讓我們用一個(gè)小 demo 來實(shí)踐這些概念,看看這3個(gè)插件是如何在一起工作的。
Demo
在這個(gè)demo 中,我們將使用 fluentd 來讀取 docker 應(yīng)用日志。
設(shè)置
這里我們將 demo 相關(guān)的配置放置到了 Github 倉庫:https://github.com/r1ckr/fluentd-simplified,克隆后最終會(huì)得到以下目錄結(jié)構(gòu)。
fluentd/
????├──?etc/
????│???└──?fluentd.conf
????├──?log/
????│???└──?kong.log
????└──?output/
其中的 output/ 是 fluentd 寫入日志文件的目錄,在 log/kong.log 中,有一些來自本地運(yùn)行的 kong 容器的日志,它們都是 docker 格式的日志。
{
????"log":"2019/07/31?22:19:52?[notice]?1#0:?start?worker?process?32\n",
????"stream":"stderr",
????"time":"2019-07-31T22:19:52.3754634Z"
}
這個(gè)文件的每一行都是一個(gè) json 文件,這就是 docker 默認(rèn)驅(qū)動(dòng)的日志格式。我們將對(duì)這個(gè)文件進(jìn)行 tail 和解析操作,它有應(yīng)用日志和訪問日志混合在一起。我們的目標(biāo)是只獲取訪問日志。etc/fluentd.conf 是我們的 fluentd 配置,其中有一個(gè)輸入和一個(gè)輸出部分,我們稍后會(huì)仔細(xì)來分析,首先運(yùn)行 fluentd 容器。
運(yùn)行 fluentd
$?chmod?777?output/
$?docker?run?-ti?--rm?\
-v?$(pwd)/etc:/fluentd/etc?\
-v?$(pwd)/log:/var/log/?\
-v?$(pwd)/output:/output?\
fluent/fluentd:v1.11-debian-1?-c?/fluentd/etc/fluentd-simplified-finished.conf?-v
注意上面的運(yùn)行命令和我們要掛載的卷
etc/是掛載在容器內(nèi)部的/fluentd/etc/目錄下的,以覆蓋 fluentd 的默認(rèn)配置。log/掛載到/var/log/,最后在容器里面掛載到/var/log/kong.log。output/掛載到/output,以便能夠看到 fluentd 寫入磁盤的內(nèi)容。
運(yùn)行容器后,會(huì)出現(xiàn)如下所示的錯(cuò)誤信息:
2020-10-16?03:35:28?+0000?[info]:?#0?fluent/log.rb:327:info:?fluentd?worker?is?now?running?worker=0
這意味著 fluentd 已經(jīng)啟動(dòng)并運(yùn)行了。現(xiàn)在我們知道了 fluentd 是如何運(yùn)行的了,接下來我們來看看配置文件的一些細(xì)節(jié)。
Fluentd 配置
輸入輸出
首先查看 input 部分
<source>
??@type?tail
??path?"/var/log/*.log"
??tag?"ninja.*"
??read_from_head?true
??
????@type?"json"
????time_format?"%Y-%m-%dT%H:%M:%S.%NZ"
????time_type?string
??
source>
我們來仔細(xì)查看下這幾個(gè)配置:
@type tail:是我們想要的輸入類型, 這和 tail -f非常相似。path "/var/log/*.log":表示它將跟蹤任何以 .log結(jié)尾的文件,每個(gè)文件都會(huì)產(chǎn)生自己的標(biāo)簽,比如:var.log.kong.log。tag "ninja.*":這將在這個(gè)源創(chuàng)建的每個(gè)標(biāo)簽前加上 ninja.,本例中,我們只有一個(gè)以ninja.var.log.kong.log結(jié)束的文件。read_from_head true:表示讀取整個(gè)文件,而不只是新的日志行。 部分:由于 docker 日志的每一行都是一個(gè) json 對(duì)象,所以我們將以 json 的方式進(jìn)行解析。
然后是輸出 output 部分的配置。
#?Output
??@type?file
??path?/output/example.log
??
????timekey?1d
????timekey_use_utc?true
????timekey_wait?1m
??
在這個(gè)配置中,有兩個(gè)重要的部分。
** >:這表示我們要匹配 fluentd 中的所有標(biāo)簽,我們這里只有一個(gè),就是上面輸入插件創(chuàng)建的那個(gè)。 path /output/example:這是保存緩沖區(qū)的目錄名,也是每個(gè)日志文件的開頭名稱。
output
├──?example
│???├──?buffer.b5b1c174b5e82c806c7027bbe4c3e20fd.log
│???└──?buffer.b5b1c174b5e82c806c7027bbe4c3e20fd.log.meta
├──?example.20190731.log
└──?example.20200510.log
有了這個(gè)配置,我們就有了一個(gè)非常簡單的輸入/輸出管道了。
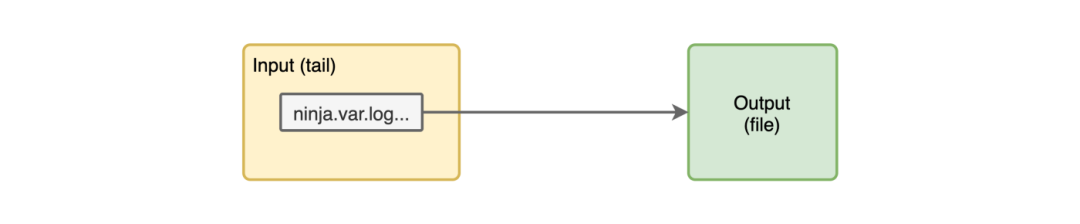
現(xiàn)在我們可以來看看 fluentd 創(chuàng)建的一個(gè)文件中的一些日志 example.20200510.log。
2020-05-10T17:04:17+00:00?ninja.var.log.kong.log?{"log":"2020/05/10?17:04:16?[warn]?35#0:?*4?[lua]?globalpatches.lua:47:?sleep():?executing?a?blocking?'sleep'?(0.004?seconds),?context:?init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:17+00:00?ninja.var.log.kong.log?{"log":"2020/05/10?17:04:16?[warn]?33#0:?*2?[lua]?globalpatches.lua:47:?sleep():?executing?a?blocking?'sleep'?(0.008?seconds),?context:?init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:17+00:00?ninja.var.log.kong.log?{"log":"2020/05/10?17:04:17?[warn]?32#0:?*1?[lua]?mesh.lua:86:?init():?no?cluster_ca?in?declarative?configuration:?cannot?use?node?in?mesh?mode,?context:?init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:30+00:00?ninja.var.log.kong.log?{"log":"172.17.0.1?-?-?[10/May/2020:17:04:30?+0000]?\"GET?/?HTTP/1.1\"?404?48?\"-\"?\"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:05:38+00:00?ninja.var.log.kong.log?{"log":"172.17.0.1?-?-?[10/May/2020:17:05:38?+0000]?\"GET?/users?HTTP/1.1\"?401?26?\"-\"?\"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:06:24+00:00?ninja.var.log.kong.log?{"log":"172.17.0.1?-?-?[10/May/2020:17:06:24?+0000]?\"GET?/users?HTTP/1.1\"?499?0?\"-\"?\"curl/7.59.0\"\n","stream":"stdout"}
注意上面的日志,每行都有3列,格式為:
log>????log>????log>
注意:標(biāo)簽都是 "ninja" 字符串加上目錄路徑和文件名,之間使用". "分隔。
過濾
現(xiàn)在我們已經(jīng)在 fluentd 中實(shí)現(xiàn)了日志的收集,接下來讓我們對(duì)它進(jìn)行一些過濾操作。
到目前為止,我們已經(jīng)實(shí)現(xiàn)了前面那條命令的2個(gè)部分,tail -f /var/log/*.log 和 > example.log 工作正常,但是如果你看一下輸出,我們有訪問日志和應(yīng)用日志混合在一起,現(xiàn)在我們需要實(shí)現(xiàn) grep 'what I want' 過濾。
在這個(gè)例子中,我們只想要訪問日志,丟棄其他的日志行。比如說,通過 HTTP 進(jìn)行 grepping 會(huì)給我們提供所有的訪問日志,并將應(yīng)用日志排除在外,下面的配置就可以做到這一點(diǎn)。
??@type?grep
??
????key?log
????pattern?/HTTP/
??
我們來分析下這個(gè)過濾配置:
>**:表示我們將只過濾以 ninja.var.log.kong開頭的標(biāo)簽日志。@type grep:使用 grep 這個(gè)插件進(jìn)行過濾。 部分:這里我們要在日志內(nèi)容的記錄鍵中提取 "HTTP", 通過這個(gè)配置,我們的 fluentd 管道中添加了一個(gè)新的塊。
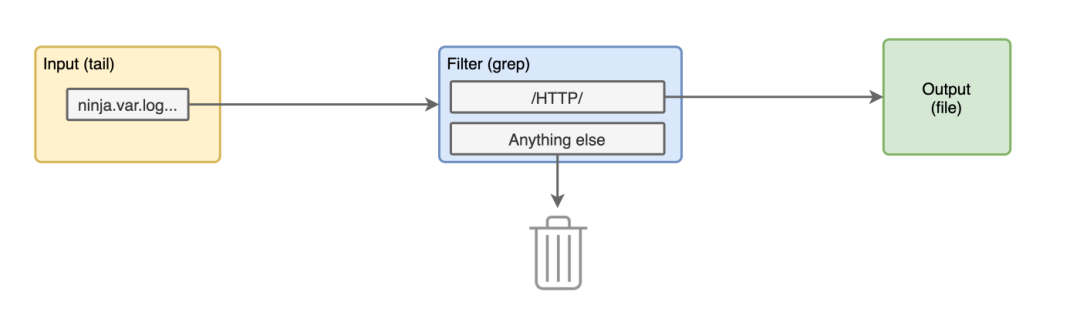
現(xiàn)在我們停止并再次運(yùn)行容器。我們應(yīng)該在輸出日志中看到一些不同的日志了,沒有應(yīng)用日志,只有訪問日志數(shù)據(jù)。
2020-05-10T17:04:30+00:00?ninja.var.log.kong.log?{"log":"172.17.0.1?-?-?[10/May/2020:17:04:30?+0000]?\"GET?/?HTTP/1.1\"?404?48?\"-\"?\"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:05:38+00:00?ninja.var.log.kong.log?{"log":"172.17.0.1?-?-?[10/May/2020:17:05:38?+0000]?\"GET?/users?HTTP/1.1\"?401?26?\"-\"?\"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:06:24+00:00?ninja.var.log.kong.log?{"log":"172.17.0.1?-?-?[10/May/2020:17:06:24?+0000]?\"GET?/users?HTTP/1.1\"?499?0?\"-\"?\"curl/7.59.0\"\n","strea
解析訪問日志
為了熟悉我們的配置,下面讓我們添加一個(gè)解析器插件來從訪問日志中提取一些其他有用的信息。在 grep 過濾器后使用下面配置。
??@type?parser
??key_name?log
??
????@type?nginx
??
同樣我們來仔細(xì)查看下這個(gè)配置:
>**:我們將解析所有以 ninja.var.log.kong開頭的標(biāo)簽,就像上面的一樣。@type parser:過濾器的類型是 parser 解析器。 我們將對(duì)日志內(nèi)容的 log key 進(jìn)行解析。 由于這些都是 nginx 的訪問日志,我們將使用 @type nginx 的解析器。
現(xiàn)在我們的管道是下面這個(gè)樣子了。
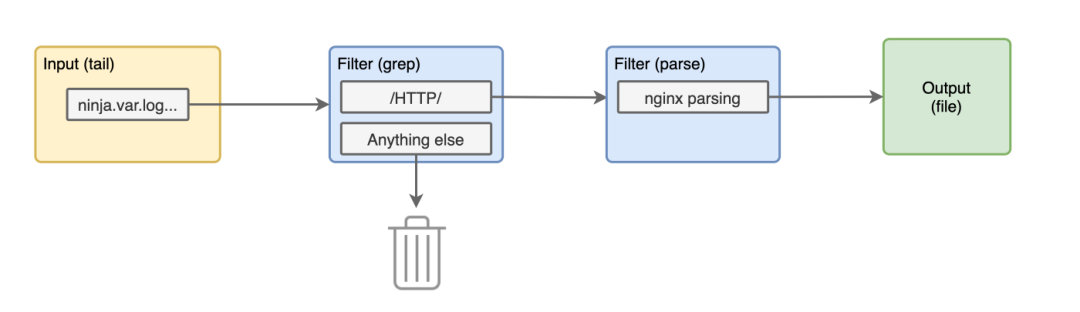
我們?cè)俅沃匦逻\(yùn)行容器,現(xiàn)在的訪問日志應(yīng)該是這樣的了。
2020-05-10T17:04:30+00:00?ninja.var.log.kong.log?{"remote":"172.17.0.1","host":"-","user":"-","method":"GET","path":"/","code":"404","size":"48","referer":"-","agent":"curl/7.59.0","http_x_forwarded_for":""}
這是之前日志中的第一個(gè)訪問日志,現(xiàn)在日志內(nèi)容完全不同了,我們的鍵從日志流,變成了 remote、host、user、method、path、code、size、referer、agent 以及 http_x_forwarded_for。如果我們要把這個(gè)保存到 Elasticsearch 中,我們將能夠通過 method=GET 或其他組合進(jìn)行過濾了。
當(dāng)然我們還可以更進(jìn)一步,在 remote 字段中使用 geoip 插件來提取我們我們 API 的客戶端的地理位置信息,大家可以自行測試,不過需要注意的時(shí)候需要我們的鏡像中包含這些插件。
總結(jié)
現(xiàn)在我們知道了如何用 docker 來讓 fluentd 讀取配置文件,我們了解了一些常用的 fluentd 配置,我們能夠從一些日志數(shù)據(jù)中來過濾、解析提取有用的信息。
原文鏈接:https://scaleout.ninja/post/fluentd-simplified/
推薦閱讀



 ?點(diǎn)擊屏末?|?閱讀原文?|?即刻學(xué)習(xí)
?點(diǎn)擊屏末?|?閱讀原文?|?即刻學(xué)習(xí)