
神經(jīng)網(wǎng)絡(luò)復(fù)雜度分析
前言
一,模型計(jì)算量分析
卷積層FLOPs計(jì)算
全連接層的 FLOPs 計(jì)算
二,模型參數(shù)量分析
卷積層參數(shù)量
BN層參數(shù)量
全連接層參數(shù)量
三,模型內(nèi)存訪問(wèn)代價(jià)計(jì)算
卷積層 MAC 計(jì)算
四,一些概念
雙精度、單精度和半精度
浮點(diǎn)計(jì)算能力
硬件利用率(Utilization)
五,參考資料
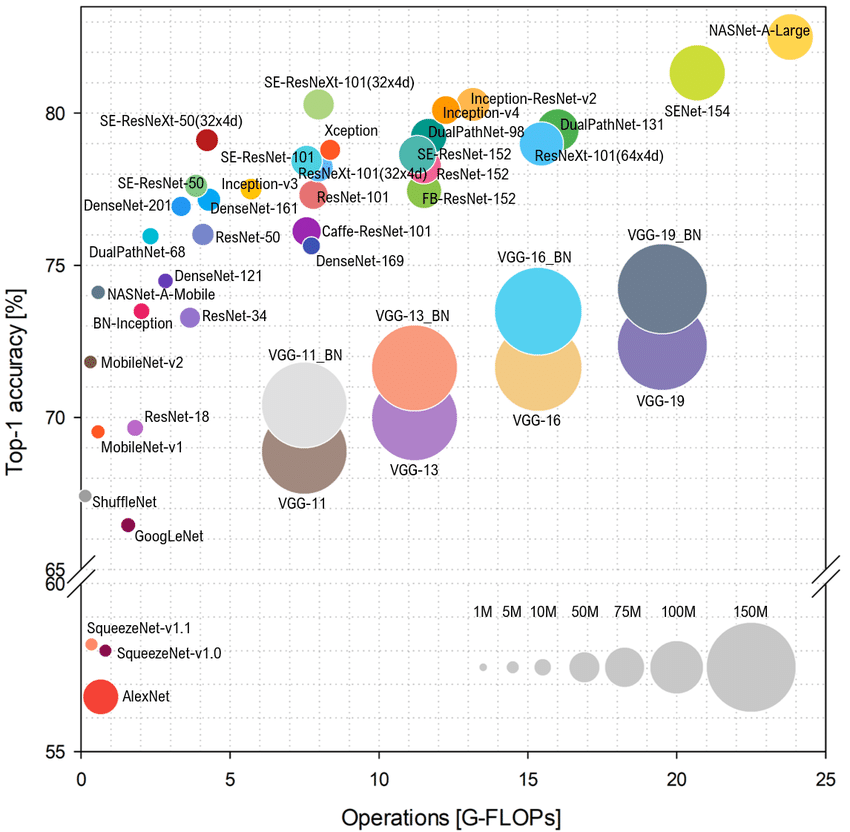
前言
現(xiàn)階段的輕量級(jí)模型 MobileNet/ShuffleNet 系列、CSPNet、RepVGG、VoVNet 等都必須依賴于于具體的計(jì)算平臺(tái)(如 CPU/GPU/ASIC 等)才能更完美的發(fā)揮網(wǎng)絡(luò)架構(gòu)。
1,計(jì)算平臺(tái)主要有兩個(gè)指標(biāo):算力 和 帶寬 。
算力指的是計(jì)算平臺(tái)每秒完成的最大浮點(diǎn)運(yùn)算次數(shù),單位是 FLOPS帶寬指的是計(jì)算平臺(tái)一次每秒最多能搬運(yùn)多少數(shù)據(jù)(每秒能完成的內(nèi)存交換量),單位是 Byte/s。
計(jì)算強(qiáng)度上限 ,上面兩個(gè)指標(biāo)相除得到計(jì)算平臺(tái)的計(jì)算強(qiáng)度上限。它描述了單位內(nèi)存交換最多用來(lái)進(jìn)行多少次計(jì)算,單位是 FLOPs/Byte。
這里所說(shuō)的“內(nèi)存”是廣義上的內(nèi)存。對(duì)于
CPU而言指的就是真正的內(nèi)存(RAM);而對(duì)于GPU則指的是顯存。
2,和計(jì)算平臺(tái)的兩個(gè)指標(biāo)相呼應(yīng),模型也有兩個(gè)主要的反饋速度的間接指標(biāo):計(jì)算量 FLOPs 和訪存量 MAC。
計(jì)算量(FLOPs):指的是輸入單個(gè)樣本(一張圖像),模型完成一次前向傳播所發(fā)生的浮點(diǎn)運(yùn)算次數(shù),即模型的時(shí)間復(fù)雜度,單位是 FLOPs。訪存量(MAC):指的是輸入單個(gè)樣本(一張圖像),模型完成一次前向傳播所發(fā)生的內(nèi)存交換總量,即模型的空間復(fù)雜度,單位是 Byte,因?yàn)閿?shù)據(jù)類型通常為float32,所以需要乘以4。CNN網(wǎng)絡(luò)中每個(gè)網(wǎng)絡(luò)層MAC的計(jì)算分為讀輸入feature map大小、權(quán)重大小(DDR讀)和寫(xiě)輸出feature map大小(DDR寫(xiě))三部分。模型的計(jì)算強(qiáng)度 :,即計(jì)算量除以訪存量后的值,表示此模型在計(jì)算過(guò)程中,每 Byte內(nèi)存交換到底用于進(jìn)行多少次浮點(diǎn)運(yùn)算。單位是FLOPs/Byte。可以看到,模計(jì)算強(qiáng)度越大,其內(nèi)存使用效率越高。模型的理論性能 :我們最關(guān)心的指標(biāo),即模型在計(jì)算平臺(tái)上所能達(dá)到的每秒浮點(diǎn)運(yùn)算次數(shù)(理論值)。單位是 FLOPS or FLOP/s。Roof-line Model給出的就是計(jì)算這個(gè)指標(biāo)的方法。
3,Roofline 模型講的是程序在計(jì)算平臺(tái)的算力和帶寬這兩個(gè)指標(biāo)限制下,所能達(dá)到的理論性能上界,而不是實(shí)際達(dá)到的性能,因?yàn)閷?shí)際計(jì)算過(guò)程中還有除算力和帶寬之外的其他重要因素,它們也會(huì)影響模型的實(shí)際性能,這是 Roofline Model 未考慮到的。例如矩陣乘法,會(huì)因?yàn)?cache 大小的限制、GEMM 實(shí)現(xiàn)的優(yōu)劣等其他限制,導(dǎo)致你幾乎無(wú)法達(dá)到 Roofline 模型所定義的邊界(屋頂)。
所謂 “Roof-line”,指的就是由計(jì)算平臺(tái)的算力和帶寬上限這兩個(gè)參數(shù)所決定的“屋頂”形態(tài),如下圖所示。
算力決定“屋頂”的高度(綠色線段) 帶寬決定“房檐”的斜率(紅色線段)
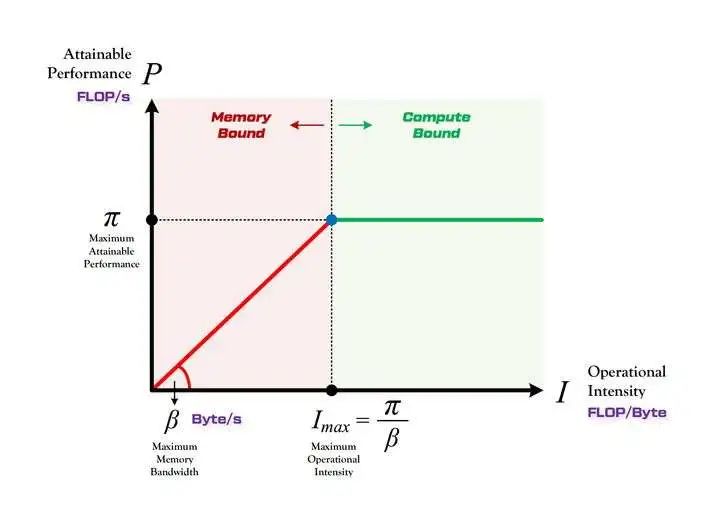
Roof-line 劃分出的兩個(gè)瓶頸區(qū)域定義如下:

個(gè)人感覺(jué)如果在給定計(jì)算平臺(tái)上做模型部署工作,因?yàn)樾酒乃懔σ讯ǎこ處熌茏龅闹饕ぷ鲬?yīng)該是提升帶寬。
一,模型計(jì)算量分析
終端設(shè)備上運(yùn)行深度學(xué)習(xí)算法需要考慮內(nèi)存和算力的需求,因此需要進(jìn)行模型復(fù)雜度分析,涉及到模型計(jì)算量(時(shí)間/計(jì)算復(fù)雜度)和模型參數(shù)量(空間復(fù)雜度)分析。
為了分析模型計(jì)算復(fù)雜度,一個(gè)廣泛采用的度量方式是模型推斷時(shí)浮點(diǎn)運(yùn)算的次數(shù) (FLOPs),即模型理論計(jì)算量,但是,它是一個(gè)間接的度量,是對(duì)我們真正關(guān)心的直接度量比如速度或者時(shí)延的一種近似估計(jì)。
本文的卷積核尺寸假設(shè)為為一般情況,即正方形,長(zhǎng)寬相等都為 K。
FLOPs:floating point operations 指的是浮點(diǎn)運(yùn)算次數(shù),理解為計(jì)算量,可以用來(lái)衡量算法/模型時(shí)間的復(fù)雜度。FLOPS:(全部大寫(xiě)),Floating-point Operations Per Second,每秒所執(zhí)行的浮點(diǎn)運(yùn)算次數(shù),理解為計(jì)算速度,是一個(gè)衡量硬件性能/模型速度的指標(biāo)。MACCs:multiply-accumulate operations,乘-加操作次數(shù),MACCs大約是 FLOPs 的一半。將 視為一個(gè)乘法累加或1個(gè)MACC。
注意相同 FLOPs 的兩個(gè)模型其運(yùn)行速度是會(huì)相差很多的,因?yàn)橛绊懩P瓦\(yùn)行速度的兩個(gè)重要因素只通過(guò) FLOPs 是考慮不到的,比如 MAC(Memory Access Cost)和網(wǎng)絡(luò)并行度;二是具有相同 FLOPs 的模型在不同的平臺(tái)上可能運(yùn)行速度不一樣。
注意,網(wǎng)上很多文章將 MACCs 與 MACC 概念搞混,我猜測(cè)可能是機(jī)器翻譯英文文章不準(zhǔn)確的緣故,可以參考此鏈接了解更多。需要指出的是,現(xiàn)有很多硬件都將乘加運(yùn)算作為一個(gè)單獨(dú)的指令。
卷積層 FLOPs 計(jì)算
卷積操作本質(zhì)上是個(gè)線性運(yùn)算,假設(shè)卷積核大小相等且為 。這里給出的公式寫(xiě)法是為了方便理解,大多數(shù)時(shí)候?yàn)榱朔奖阌洃洠瑫?huì)寫(xiě)成比如 。
(不考慮bias) (考慮bias) (考慮bias)
為輸入特征圖通道數(shù), 為過(guò)卷積核尺寸, 為輸出特征圖的高,寬和通道數(shù)。二維卷積過(guò)程如下圖所示:
二維卷積是一個(gè)相當(dāng)簡(jiǎn)單的操作:從卷積核開(kāi)始,這是一個(gè)小的權(quán)值矩陣。這個(gè)卷積核在 2 維輸入數(shù)據(jù)上「滑動(dòng)」,對(duì)當(dāng)前輸入的部分元素進(jìn)行矩陣乘法,然后將結(jié)果匯為單個(gè)輸出像素。
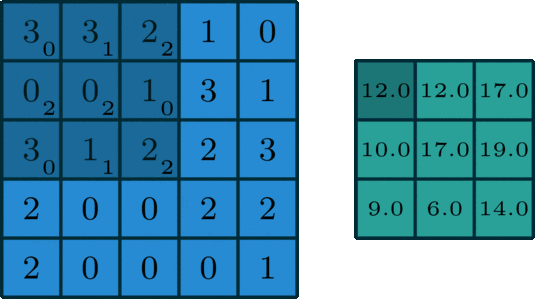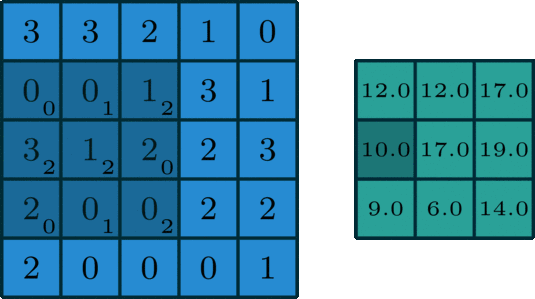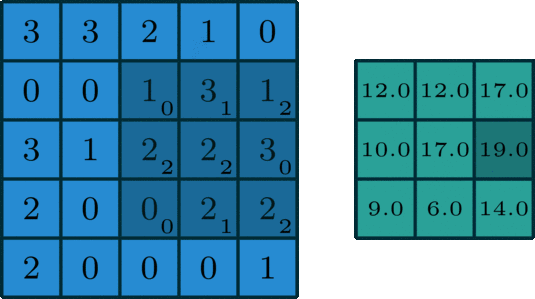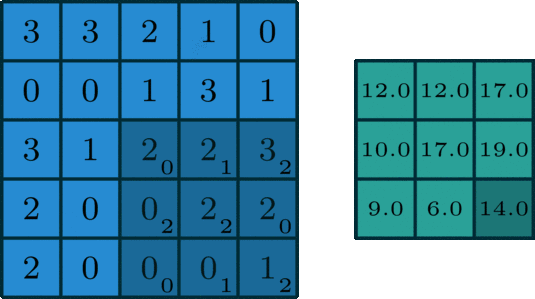
公式解釋,參考這里,如下:
理解 FLOPs 的計(jì)算公式分兩步。括號(hào)內(nèi)是第一步,計(jì)算出output feature map 的一個(gè) pixel,然后再乘以 ,從而拓展到整個(gè) output feature map。括號(hào)內(nèi)的部分又可以分為兩步:。第一項(xiàng)是乘法運(yùn)算次數(shù),第二項(xiàng)是加法運(yùn)算次數(shù),因?yàn)? 個(gè)數(shù)相加,要加 次,所以不考慮 bias 的情況下,會(huì)有一個(gè) -1,如果考慮 bias,剛好中和掉,括號(hào)內(nèi)變?yōu)?span style="cursor:pointer;">。
所以卷積層的 ( 為輸入特征圖通道數(shù), 為過(guò)濾器尺寸,為輸出特征圖的高,寬和通道數(shù))。
全連接層的 FLOPs 計(jì)算
全連接層的 , 是輸入層的維度, 是輸出層的維度。
二,模型參數(shù)量分析
模型參數(shù)數(shù)量(params):指模型含有多少參數(shù),直接決定模型的大小,也影響推斷時(shí)對(duì)內(nèi)存的占用量,單位通常為
M,GPU端通常參數(shù)用float32表示,所以模型大小是參數(shù)數(shù)量的4倍。這里考慮的卷積核長(zhǎng)寬是相同的一般情況,都為K。
模型參數(shù)量的分析是為了了解內(nèi)存占用情況,內(nèi)存帶寬其實(shí)比 FLOPs 更重要。目前的計(jì)算機(jī)結(jié)構(gòu)下,單次內(nèi)存訪問(wèn)比單次運(yùn)算慢得多的多。對(duì)每一層網(wǎng)絡(luò),端側(cè)設(shè)備需要:
從主內(nèi)存中讀取輸入向量 / feature map;從主內(nèi)存中讀取權(quán)重并計(jì)算點(diǎn)積; 將輸出向量或 feature map寫(xiě)回主內(nèi)存。
MAes:memory accesse,內(nèi)存訪問(wèn)次數(shù)。
卷積層參數(shù)量
卷積層權(quán)重參數(shù)量 = 。
為輸入特征圖通道數(shù), 為過(guò)濾器(卷積核)尺寸, 為輸出的特征圖的 channel 數(shù)(也是 filter 的數(shù)量),算式第二項(xiàng)是偏置項(xiàng)的參數(shù)量 。(一般不寫(xiě)偏置項(xiàng),偏置項(xiàng)對(duì)總參數(shù)量的數(shù)量級(jí)的影響可以忽略不記,這里為了準(zhǔn)確起見(jiàn),把偏置項(xiàng)的參數(shù)量也考慮進(jìn)來(lái)。)
假設(shè)輸入層矩陣維度是 96×96×3,第一層卷積層使用尺寸為 5×5、深度為 16 的過(guò)濾器(卷積核尺寸為 5×5、卷積核數(shù)量為 16),那么這層卷積層的參數(shù)個(gè)數(shù)為 5×5×3×16+16=1216個(gè)。
BN 層參數(shù)量
BN 層參數(shù)量 = 。
其中 為輸入的 channel 數(shù)(BN層有兩個(gè)需要學(xué)習(xí)的參數(shù),平移因子和縮放因子)
全連接層參數(shù)量
全連接層參數(shù)量 = 。
為輸入向量的長(zhǎng)度, 為輸出向量的長(zhǎng)度,公式的第二項(xiàng)為偏置項(xiàng)參數(shù)量。(目前全連接層已經(jīng)逐漸被 Global Average Pooling 層取代了。) 注意,全連接層的權(quán)重參數(shù)量(內(nèi)存占用)遠(yuǎn)遠(yuǎn)大于卷積層。
三,模型內(nèi)存訪問(wèn)代價(jià)計(jì)算
MAC(memory access cost) 內(nèi)存訪問(wèn)代價(jià)也叫內(nèi)存使用量,指的是輸入單個(gè)樣本(一張圖像),模型/卷積層完成一次前向傳播所發(fā)生的內(nèi)存交換總量,即模型的空間復(fù)雜度,單位是 Byte。
CNN 網(wǎng)絡(luò)中每個(gè)網(wǎng)絡(luò)層 MAC 的計(jì)算分為讀輸入 feature map 大小(DDR 讀)、權(quán)重大小(DDR 讀)和寫(xiě)輸出 feature map 大小(DDR 寫(xiě))三部分。
卷積層 MAC 計(jì)算
以卷積層為例計(jì)算 MAC,可假設(shè)某個(gè)卷積層輸入 feature map 大小是 (Cin, Hin, Win),輸出 feature map 大小是 (Hout, Wout, Cout),卷積核是 (Cout, Cin, K, K),理論 MAC(理論 MAC 一般小于 實(shí)際 MAC)計(jì)算公式如下:
# 端側(cè)推理IN8量化后模型,單位一般為 1 byte
input = Hin x Win x Cin # 輸入 feature map 大小
output = Hout x Wout x Cout # 輸出 feature map 大小
weights = K x K x Cin x Cout + bias # bias 是卷積層偏置
ddr_read = input + weights
ddr_write = output
MAC = ddr_read + ddr_write
feature map大小一般表示為 (N, C, H, W),MAC指標(biāo)一般用在端側(cè)模型推理中,端側(cè)模型推理模式一般都是單幀圖像進(jìn)行推理,即N = 1(batch_size = 1),不同于模型訓(xùn)練時(shí)的batch_size大小一般大于 1。
四,一些概念
雙精度、單精度和半精度
CPU/GPU 的浮點(diǎn)計(jì)算能力得區(qū)分不同精度的浮點(diǎn)數(shù),分為雙精度 FP64、單精度 FP32 和半精度 FP16。因?yàn)椴捎貌煌粩?shù)的浮點(diǎn)數(shù)的表達(dá)精度不一樣,所以造成的計(jì)算誤差也不一樣,對(duì)于需要處理的數(shù)字范圍大而且需要精確計(jì)算的科學(xué)計(jì)算來(lái)說(shuō),就要求采用雙精度浮點(diǎn)數(shù),而對(duì)于常見(jiàn)的多媒體和圖形處理計(jì)算,32 位的單精度浮點(diǎn)計(jì)算已經(jīng)足夠了,對(duì)于要求精度更低的機(jī)器學(xué)習(xí)等一些應(yīng)用來(lái)說(shuō),半精度 16 位浮點(diǎn)數(shù)就可以甚至 8 位浮點(diǎn)數(shù)就已經(jīng)夠用了。對(duì)于浮點(diǎn)計(jì)算來(lái)說(shuō), CPU 可以同時(shí)支持不同精度的浮點(diǎn)運(yùn)算,但在 GPU 里針對(duì)單精度和雙精度就需要各自獨(dú)立的計(jì)算單元。
浮點(diǎn)計(jì)算能力
FLOPS:每秒浮點(diǎn)運(yùn)算次數(shù),每秒所執(zhí)行的浮點(diǎn)運(yùn)算次數(shù),浮點(diǎn)運(yùn)算包括了所有涉及小數(shù)的運(yùn)算,比整數(shù)運(yùn)算更費(fèi)時(shí)間。下面幾個(gè)是表示浮點(diǎn)運(yùn)算能力的單位。我們一般常用 TFLOPS(Tops) 作為衡量 NPU/GPU 性能/算力的指標(biāo),比如海思 3519AV100 芯片的算力為 1.7Tops 神經(jīng)網(wǎng)絡(luò)運(yùn)算性能。
MFLOPS(megaFLOPS):等于每秒一佰萬(wàn)(=10^6)次的浮點(diǎn)運(yùn)算。GFLOPS(gigaFLOPS):等于每秒拾億(=10^9)次的浮點(diǎn)運(yùn)算。TFLOPS(teraFLOPS):等于每秒萬(wàn)億(=10^12)次的浮點(diǎn)運(yùn)算。PFLOPS(petaFLOPS):等于每秒千萬(wàn)億(=10^15)次的浮點(diǎn)運(yùn)算。EFLOPS(exaFLOPS):等于每秒百億億(=10^18)次的浮點(diǎn)運(yùn)算。
硬件利用率(Utilization)
在這種情況下,利用率(Utilization)是可以有效地用于實(shí)際工作負(fù)載的芯片的原始計(jì)算能力的百分比。深度學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)使用相對(duì)數(shù)量較少的計(jì)算原語(yǔ)(computational primitives),而這些數(shù)量很少的計(jì)算原語(yǔ)卻占用了大部分計(jì)算時(shí)間。矩陣乘法(MM)和轉(zhuǎn)置是基本操作。MM 由乘法累加(MAC)操作組成。OPs/s(每秒完成操作的數(shù)量)指標(biāo)通過(guò)每秒可以完成多少個(gè) MAC(每次乘法和累加各被認(rèn)為是 1 個(gè) operation,因此 MAC 實(shí)際上是 2 個(gè) OP)得到。所以我們可以將利用率定義為實(shí)際使用的運(yùn)算能力和原始運(yùn)算能力的比值,從而得出算力利用率計(jì)算公式如下:
五,參考資料
https://arxiv.org/pdf/1611.06440.pdf 神經(jīng)網(wǎng)絡(luò)參數(shù)量的計(jì)算:以UNet為例 How fast is my model? MobileNetV1 & MobileNetV2 簡(jiǎn)介 雙精度,單精度和半精度 AI硬件的Computational Capacity詳解 Roofline Model與深度學(xué)習(xí)模型的性能分析 Benchmark Analysis of Representative Deep Neural Network Architectures