
你可能也會掉進這個簡單的 String 的坑

背景
石頭同學(xué)是某大公司高級開發(fā)工程師,某日收到不少錯誤告警信息,于是便去開始排查。
跟蹤日志發(fā)現(xiàn)是某個服務(wù)拋出的異常信息,奇怪的是這個服務(wù)上線也有一段時間了。之前很少看到類似的錯誤信息,最近偶爾多了起來。
后來才定位到是因為服務(wù)調(diào)用了某外部接口,發(fā)現(xiàn)對方對參數(shù)長度做了限制,如果輸入?yún)?shù)超過 1000 bytes,就直接拋異常,代碼類似如下:
/*** @param status* @param result, the size should less than 1000 bytes* @throws Exception*/public XXResult(boolean status, String result) {if (result != null && result.getBytes().length > 1000) {throw new RuntimeException("result size more than 1000 bytes!");}......}
心想,這還不簡單,咱們的?result?也不是什么關(guān)鍵性的東西,你有限制,我直接 trim 一下不就行了?

解決方案
于是三下五除二,給搞了個?trim?方法,支持傳不同參數(shù)按需 trim,代碼如下:
/*** 將給定的字符串 trim 到指定大小* @param input* @param trimTo 需要 trim 的字節(jié)長度* @return trim 后的 String*/public static String trimAsByte(String input, int trimTo) {if (Objects.isNull(input)) {return null;}byte[] bytes = input.getBytes();if (bytes.length > trimTo) {byte [] subArray = Arrays.copyOfRange(bytes, 0, trimTo);return new String(subArray);}return input;}
再在需要調(diào)用外部服務(wù)的地方,先調(diào)用這個?trimAsByte?方法,一頓操作連忙上線,一切完美~

災(zāi)難現(xiàn)場
一切完美,石頭哥也是這樣認為的。然后幸福總是短暫的。
經(jīng)過一段時間后(前面也提到,業(yè)務(wù)場景確實是偶發(fā)的),相同的錯誤仍然發(fā)生了。
簡直不敢相信,都 trim 了為啥還會超出?你也幫忙想想,是哪里的問題?

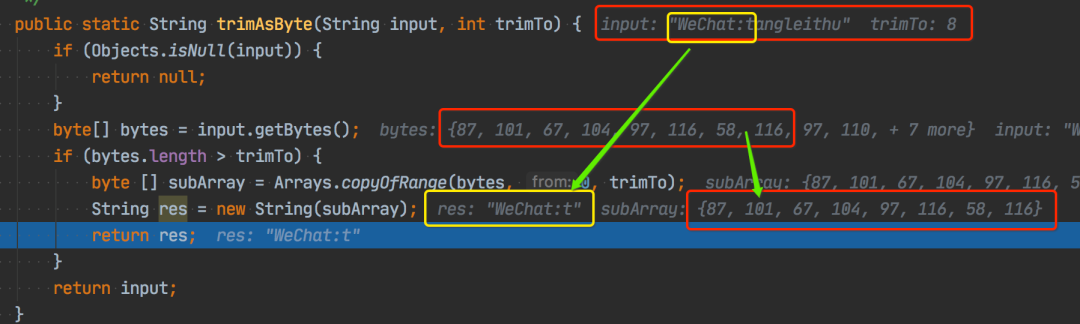
看看上面的例子(為了方便展示,簡單修改文首代碼了下),
trimAsByte("WeChat:tangleithu",?8)
輸入字符串?WeChat:tangleithu?太長了,只 trim 到剩下 8 個字節(jié),對應(yīng)的字節(jié)數(shù)組是從?[87,101,67,104,97,116,58,116,97,110,103,108,101,105,116,104,117]?變?yōu)榱?[87,101,67,104,97,116,58,116],字符串變成了?WeChat:t?,結(jié)果正確。
其實在寫這個方法的時候還是太草率了,本應(yīng)該很容易想到中文的情況的,我們來試試:
trimAsByte("程序猿石頭",?8)
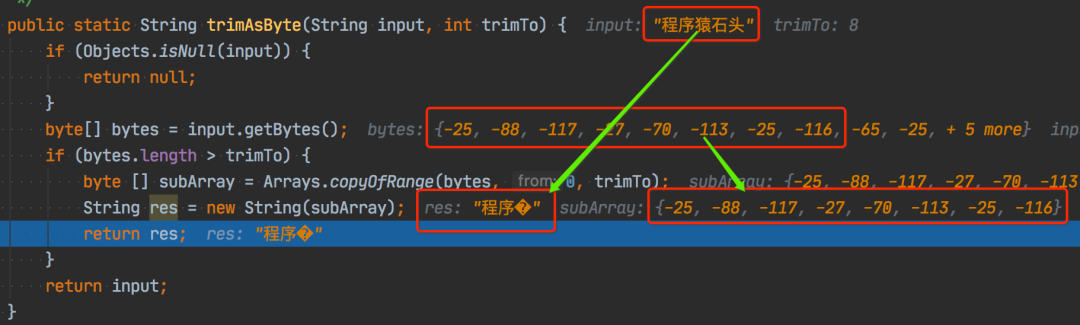
看上述截圖,悲劇了,輸入程序猿石頭,3 個字節(jié)一個漢字,一共 15 個字節(jié)?[-25,-88,-117,-27,-70,-113,-25,-116,-65,-25,-97,-77,-27,-92,-76],trim 到 8 位,剩下前 8 位?[-25,-88,-117,-27,-70,-113,-25,-116]?也正確。再?new String,又變成3 個 “中文” 了,雖然第 3 個“中文”,咱也不認識,咱也不敢問到底讀啥,總之再轉(zhuǎn)換成字節(jié)數(shù)組,長度多了 1 個,變成 9 了。
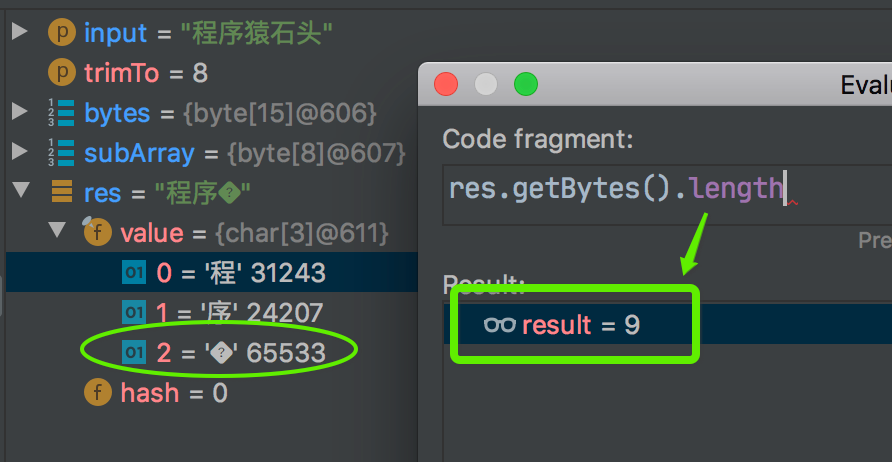
問題算是定位到了。
不禁要問,為什么?
來看看這個 String 的構(gòu)造函數(shù),看看上面注釋才發(fā)現(xiàn),其實我們忽略了一個很重要的概念,就是編碼方式。
/*** Constructs a new {@code String} by decoding the specified array of bytes* using the platform's default charset. The length of the new {@code* String} is a function of the charset, and hence may not be equal to the* length of the byte array.**The behavior of this constructor when the given bytes are not valid
* in the default charset is unspecified. The {@link* java.nio.charset.CharsetDecoder} class should be used when more control* over the decoding process is required.** @param bytes* The bytes to be decoded into characters** @since JDK1.1*/public String(byte bytes[]) {//this(bytes, 0, bytes.length);checkBounds(bytes, offset, length);this.value = StringCoding.decode(bytes, offset, length);}
當(dāng)我們用默認的構(gòu)造函數(shù) new String 的時候,只是用了系統(tǒng)默認的編碼(本文是“UTF-8”)去嘗試解碼,構(gòu)造出字符串。
所以,當(dāng)我們在用字節(jié)數(shù)組(字節(jié)流)來表達具體的語義的時候,一定要約定好以什么方式進行編碼,本文不具體闡述編碼問題了。下面用一個例子來解釋上文的現(xiàn)象:
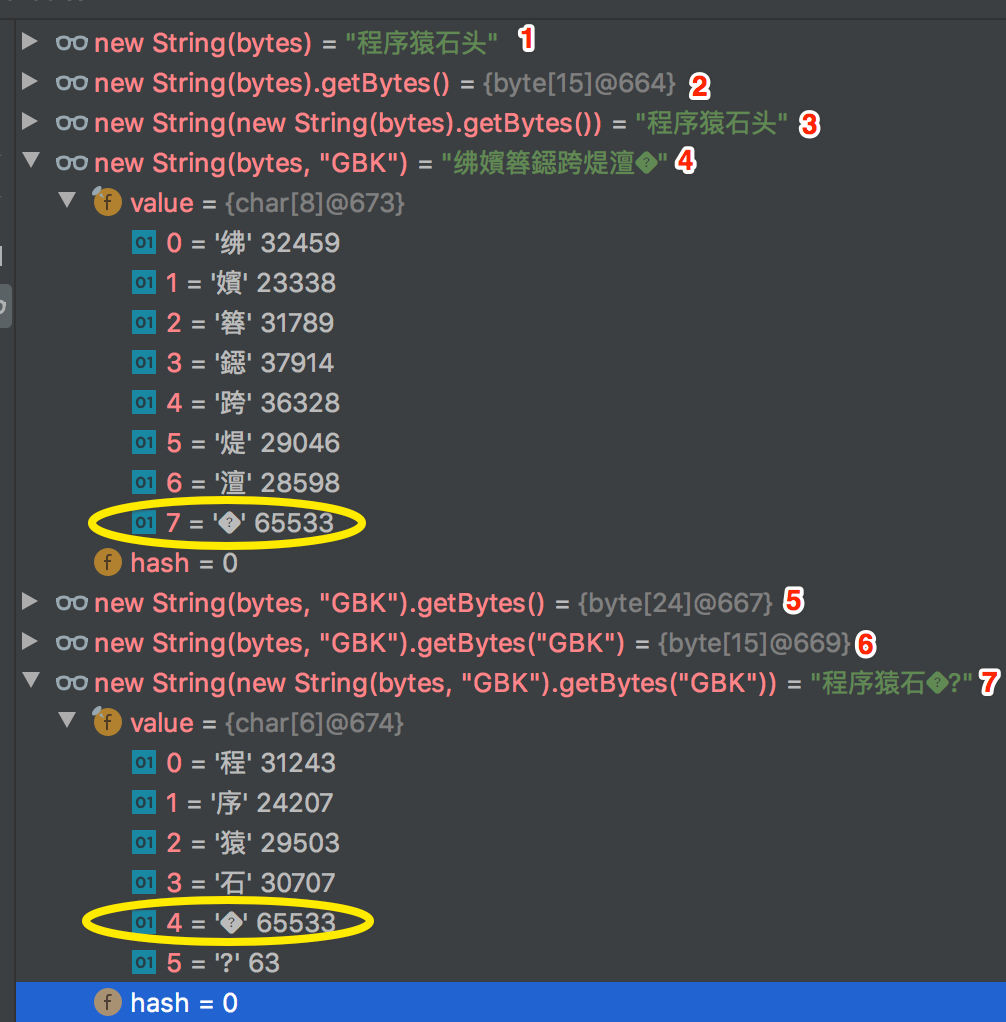
[-25,-88,-117,-27,-70,-113,-25,-116,-65,-25,-97,-77,-27,-92,-76]?仍然用這串字節(jié)數(shù)組來實驗,這串字節(jié)數(shù)組,如果用 “UTF-8” 編碼去解釋,那么其想表達的語義就是中文“程序猿石頭”,從上文標(biāo)注的 1,2,3 中可以看出來,沒有寫即用了系統(tǒng)中的默認編碼“UTF-8”。
假設(shè)按照 “GBK” 來解釋(標(biāo)注 4),就是表達的 “紼嬪簭鐚跨煶澶?”,注意看下其中的???是不是似曾相識;
注意標(biāo)注 5,通過 GBK 解釋構(gòu)造字符串后,再通過默認的 “UTF-8” 獲取字節(jié)數(shù)組,長度就變成 24 了,然后還通過 “GBK” 編碼得到的字節(jié)數(shù)組長度為 15(標(biāo)注 6),再試圖構(gòu)造字符串(標(biāo)注 7),其中“程序猿石頭”的“頭”字,已經(jīng)沒了。說明這個轉(zhuǎn)換過程中,其實信息已經(jīng)被丟了。
上面的???其實是 UNICODE 編碼方式中的一個特殊的字符,也就是 0xFFFD(65535),其實是一個占位符(REPLACEMENT CHARACTER),用來表達未知的、沒辦法表達的東東。上文中在進行編碼轉(zhuǎn)換過程中,出現(xiàn)了這個玩意,其實也就是沒辦法準(zhǔn)確表達含義,會被替換成這個東西,因此信息也就丟失了。你可以試試前面的例子,比如把前 8 個字節(jié)中的最后一兩個字節(jié)隨便改改,都是一樣的。

總結(jié)
總結(jié)一下,其實本來是一個很簡單的問題,卻經(jīng)過幾次修改才最終解決,說明對 “基礎(chǔ)” 掌握得還是不夠,一個重要的點是,在處理二進制數(shù)據(jù)的時候,一定要聯(lián)想到 “編碼” 方式。
另外,提醒我們,看似簡單的問題,我們往往容易忽略。比如如果單純看到文中提到的這個trim?方法,其實很容易寫個單元測試就能盡早發(fā)現(xiàn)有問題
