
實(shí)操教程|使用Python+OpenCV實(shí)現(xiàn)姿態(tài)估計(jì)

極市導(dǎo)讀
本文詳細(xì)介紹了如何使用Mediapipe和OpenCV實(shí)現(xiàn)姿態(tài)估計(jì),附有相關(guān)代碼及視頻。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
什么是OpenCV?
計(jì)算機(jī)視覺是一個(gè)能夠理解圖像和視頻如何存儲(chǔ)和操作的過程,它還有助于從圖像或視頻中檢索數(shù)據(jù)。計(jì)算機(jī)視覺是人工智能的一部分。
計(jì)算機(jī)視覺在自動(dòng)駕駛汽車,物體檢測(cè),機(jī)器人技術(shù),物體跟蹤等方面發(fā)揮著重要作用。
OpenCV
OpenCV是一個(gè)開放源代碼庫,主要用于計(jì)算機(jī)視覺,圖像處理和機(jī)器學(xué)習(xí)。通過OpenCV,它可以為實(shí)時(shí)數(shù)據(jù)提供更好的輸出,我們可以處理圖像和視頻,以便實(shí)現(xiàn)的算法能夠識(shí)別諸如汽車,交通信號(hào)燈,車牌等物體以及人臉,或者甚至是人類的筆跡。借助其他數(shù)據(jù)分析庫,OpenCV能夠根據(jù)自己的需求處理圖像和視頻。
可以在這里獲取有關(guān)OpenCV的更多信息 https://opencv.org/
我們將與OpenCV-python一起使用的庫是Mediapipe
什么是Mediapipe?
Mediapipe是主要用于構(gòu)建多模式音頻,視頻或任何時(shí)間序列數(shù)據(jù)的框架。借助MediaPipe框架,可以構(gòu)建令人印象深刻的ML管道,例如TensorFlow,TFLite等推理模型以及媒體處理功能。
使用Mediapipe的最先進(jìn)的ML模型
-
人臉檢測(cè) -
多手跟蹤 -
頭發(fā)分割 -
目標(biāo)檢測(cè)與追蹤 -
Objectron:3D對(duì)象檢測(cè)和跟蹤 -
AutoFlip:自動(dòng)視頻裁剪管道 -
姿態(tài)估計(jì)
姿態(tài)估計(jì)
通過視頻或?qū)崟r(shí)饋送進(jìn)行人體姿態(tài)估計(jì)在諸如全身手勢(shì)控制,量化體育鍛煉和手語識(shí)別等各個(gè)領(lǐng)域中發(fā)揮著至關(guān)重要的作用。
例如,它可用作健身,瑜伽和舞蹈應(yīng)用程序的基本模型。它在增強(qiáng)現(xiàn)實(shí)中找到了自己的主要作用。
Media Pipe Pose是用于高保真人體姿勢(shì)跟蹤的框架,該框架從RGB視頻幀獲取輸入并推斷出整個(gè)人類的33個(gè)3D界標(biāo)。當(dāng)前最先進(jìn)的方法主要依靠強(qiáng)大的桌面環(huán)境進(jìn)行推理,而此方法優(yōu)于其他方法,并且可以實(shí)時(shí)獲得很好的結(jié)果。
姿勢(shì)地標(biāo)模型
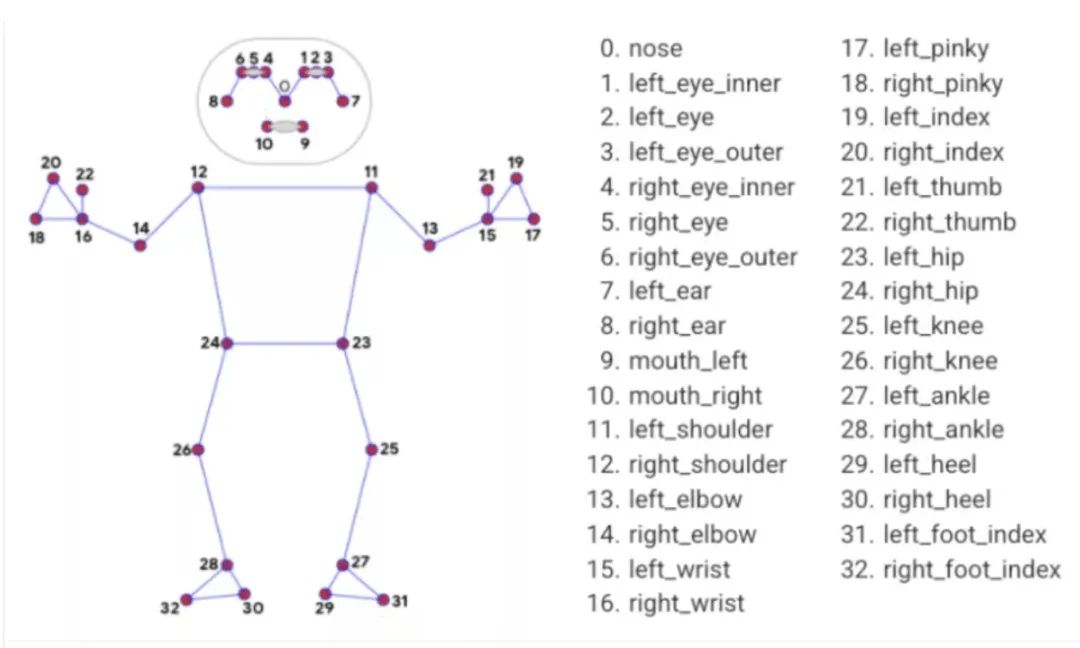
來源:https://google.github.io/mediapipe/solutions/pose.html
現(xiàn)在開始
首先,安裝所有必需的庫。
– pip install OpenCV-python– pip install mediapipe
下載任何類型的視頻,例如跳舞,跑步等。
我們將利用這些視頻進(jìn)行姿勢(shì)估計(jì)。我正在使用下面的鏈接中提供的視頻。
https://drive.google.com/file/d/1kFWHaAaeRU4biZ_1wKZlL4KCd0HSoNYd/view?usp=sharing
為了檢查mediapipe是否正常工作,我們將使用上面下載的視頻實(shí)現(xiàn)一個(gè)小的代碼。
import cv2import mediapipe as mpimport timempPose = mp.solutions.posepose = mpPose.Pose()mpDraw = mp.solutions.drawing_utils#cap = cv2.VideoCapture(0)cap = cv2.VideoCapture('a.mp4')pTime = 0while True:success, img = cap.read()imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)results = pose.process(imgRGB)print(results.pose_landmarks)if results.pose_landmarks:mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS)for id, lm in enumerate(results.pose_landmarks.landmark):h, w,c = img.shapeprint(id, lm)cx, cy = int(lm.x*w), int(lm.y*h)cv2.circle(img, (cx, cy), 5, (255,0,0), cv2.FILLED)cTime = time.time()fps = 1/(cTime-pTime)pTime = cTimecv2.putText(img, str(int(fps)), (50,50), cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0), 3)cv2.imshow("Image", img)cv2.waitKey(1)
在上面的內(nèi)容中,你可以很容易地使用OpenCV從名為“ a.mp4”的視頻中讀取幀,并將幀從BGR轉(zhuǎn)換為RGB圖像,并使用mediapipe在整個(gè)處理后的幀上繪制界標(biāo)。最后,我們將獲得具有地標(biāo)的視頻輸出,如下所示。
變量“ cTime”,“ pTime”和“ fps”用于計(jì)算每秒的讀取幀。你可以在下面的輸出中看到左角的幀數(shù)。
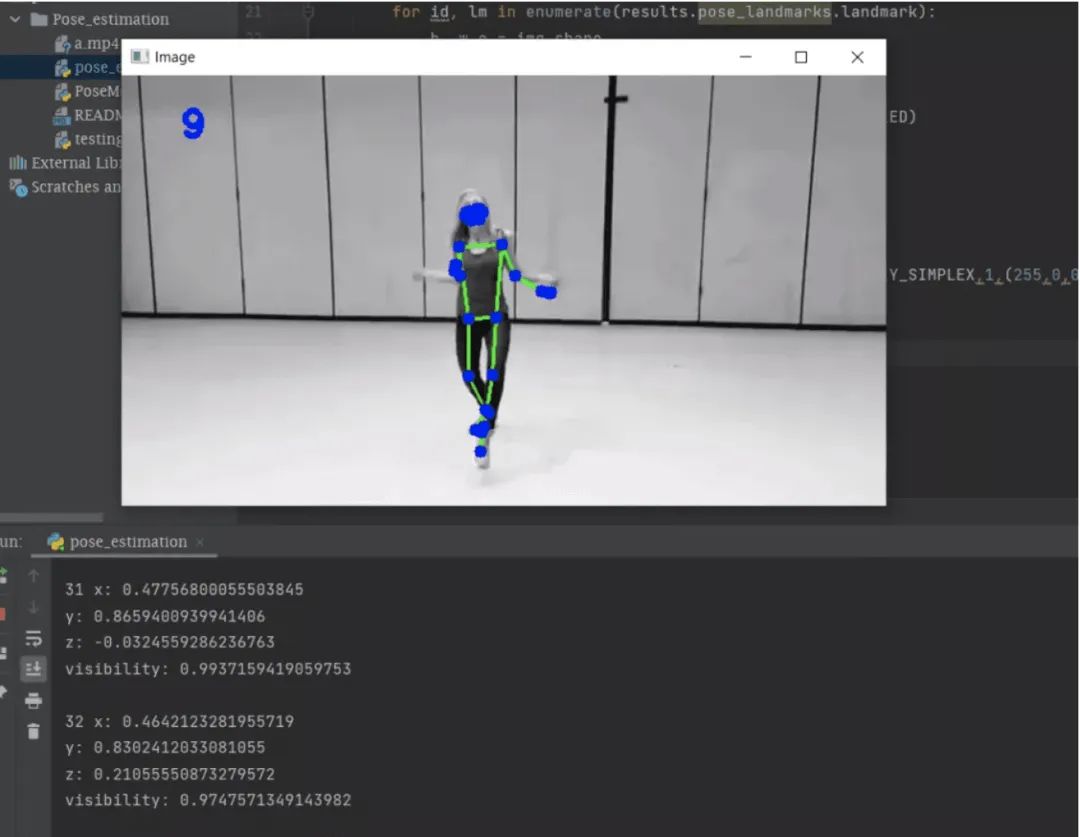
終端部分中的輸出是mediapipe檢測(cè)到的界標(biāo)。
姿勢(shì)界標(biāo)
你可以在上圖的終端部分中看到姿勢(shì)界標(biāo)的列表。每個(gè)地標(biāo)包括以下內(nèi)容:
-
x和y:這些界標(biāo)坐標(biāo)分別通過圖像的寬度和高度歸一化為[0.0,1.0]。 -
z:通過將臀部中點(diǎn)處的深度作為原點(diǎn)來表示界標(biāo)深度,并且z值越小,界標(biāo)與攝影機(jī)越近。z的大小幾乎與x的大小相同。 -
可見性:[0.0,1.0]中的值,指示界標(biāo)在圖像中可見的可能性。
MediaPipe運(yùn)行得很好。
讓我們創(chuàng)建一個(gè)用于估計(jì)姿勢(shì)的模塊,并且將該模塊用于與姿態(tài)估計(jì)有關(guān)的任何其他項(xiàng)目。另外,你可以在網(wǎng)絡(luò)攝像頭的幫助下實(shí)時(shí)使用它。
創(chuàng)建一個(gè)名為“ PoseModule”的python文件
import cv2import mediapipe as mpimport timeclass PoseDetector:def __init__(self, mode = False, upBody = False, smooth=True, detectionCon = 0.5, trackCon = 0.5):self.mode = modeself.upBody = upBodyself.smooth = smoothself.detectionCon = detectionConself.trackCon = trackConself.mpDraw = mp.solutions.drawing_utilsself.mpPose = mp.solutions.poseself.pose = self.mpPose.Pose(self.mode, self.upBody, self.smooth, self.detectionCon, self.trackCon)def findPose(self, img, draw=True):imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)self.results = self.pose.process(imgRGB)#print(results.pose_landmarks)if self.results.pose_landmarks:if draw:self.mpDraw.draw_landmarks(img, self.results.pose_landmarks, self.mpPose.POSE_CONNECTIONS)return imgdef getPosition(self, img, draw=True):lmList= []if self.results.pose_landmarks:for id, lm in enumerate(self.results.pose_landmarks.landmark):h, w, c = img.shape#print(id, lm)cx, cy = int(lm.x * w), int(lm.y * h)lmList.append([id, cx, cy])if draw:cv2.circle(img, (cx, cy), 5, (255, 0, 0), cv2.FILLED)return lmListdef main():cap = cv2.VideoCapture('videos/a.mp4') #make VideoCapture(0) for webcampTime = 0detector = PoseDetector()while True:success, img = cap.read()img = detector.findPose(img)lmList = detector.getPosition(img)print(lmList)cTime = time.time()fps = 1 / (cTime - pTime)pTime = cTimecv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)cv2.imshow("Image", img)cv2.waitKey(1)if __name__ == "__main__":main()
這是姿態(tài)估計(jì)所需的代碼,在上面,有一個(gè)名為“ PoseDetector”的類,在其中我們創(chuàng)建了兩個(gè)對(duì)象“ findPose”和“ getPosition”。
在這里,名為“ findPose”的對(duì)象將獲取輸入幀,并借助名為mpDraw的mediapipe函數(shù),它將繪制身體上的界標(biāo),而對(duì)象“ getPosition””將獲得檢測(cè)區(qū)域的坐標(biāo),我們還可以借助此對(duì)象高亮顯示任何坐標(biāo)點(diǎn)。
在main函數(shù)中,我們將進(jìn)行測(cè)試運(yùn)行,你可以通過將main函數(shù)中的第一行更改為“ cap = cv2.VideoCapture(0)”來從網(wǎng)絡(luò)攝像頭中獲取實(shí)時(shí)數(shù)據(jù)。
由于我們?cè)谏厦娴奈募袆?chuàng)建了一個(gè)類,因此我們將在另一個(gè)文件中使用它。
現(xiàn)在是最后階段
import cv2import timeimport PoseModule as pmcap = cv2.VideoCapture(0)pTime = 0detector = pm.PoseDetector()while True:success, img = cap.read()img = detector.findPose(img)lmList = detector.getPosition(img)print(lmList)cTime = time.time()fps = 1 / (cTime - pTime)pTime = cTimecv2.putText(img, str(int(fps)), (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 3)cv2.imshow("Image", img)cv2.waitKey(1)
在這里,代碼將僅調(diào)用上面創(chuàng)建的模塊,并在輸入視頻或網(wǎng)絡(luò)攝像頭的實(shí)時(shí)數(shù)據(jù)上運(yùn)行整個(gè)算法。這是測(cè)試視頻的輸出。

完整的代碼可在下面的GitHub鏈接中找到。
https://github.com/BakingBrains/Pose_estimation
鏈接到Y(jié)ouTube視頻:https://www.youtube.com/watch?v=brwgBf6VB0I
如果覺得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“CNN綜述”獲取67頁綜述深度卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)~

# CV技術(shù)社群邀請(qǐng)函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
