
NLP的“第四范式”之Prompt Learning總結(jié):44篇論文逐一梳理
作者?|?楊浩?@阿里達(dá)摩院??
研究方向?|?自然語(yǔ)言處理?
整理?|?Paperweekly


論文整理——按照時(shí)間線
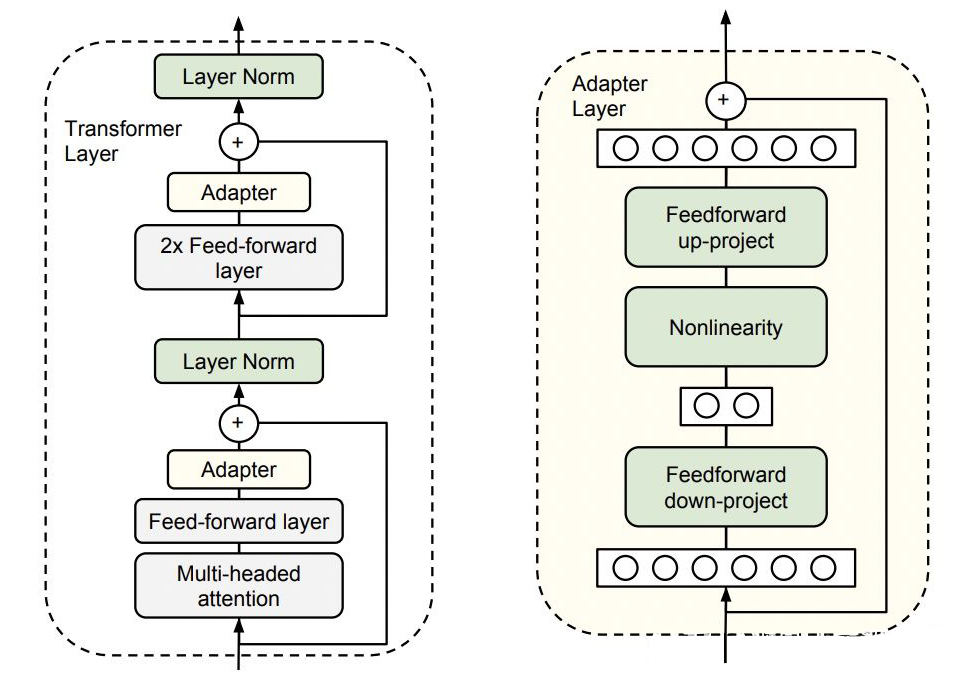
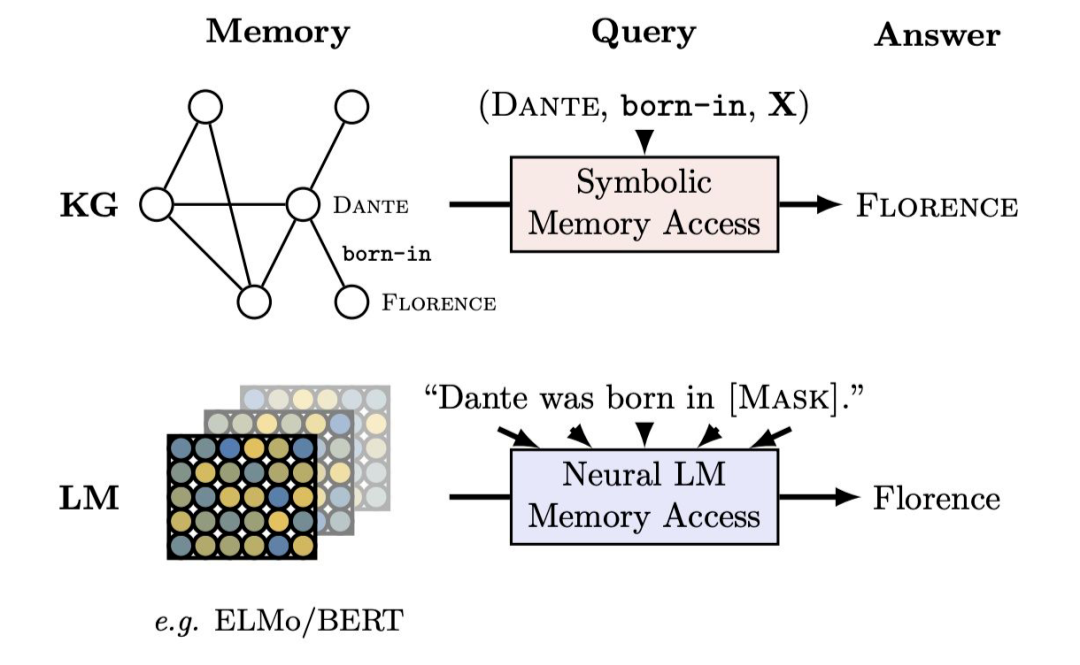
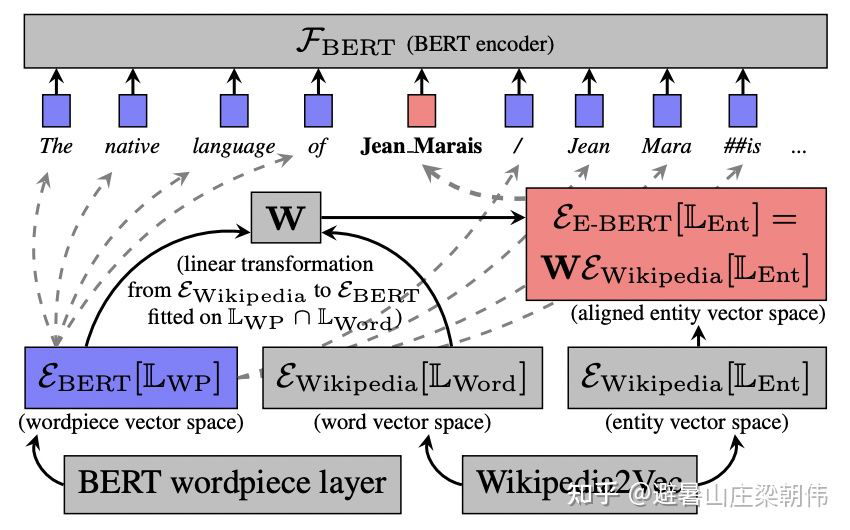
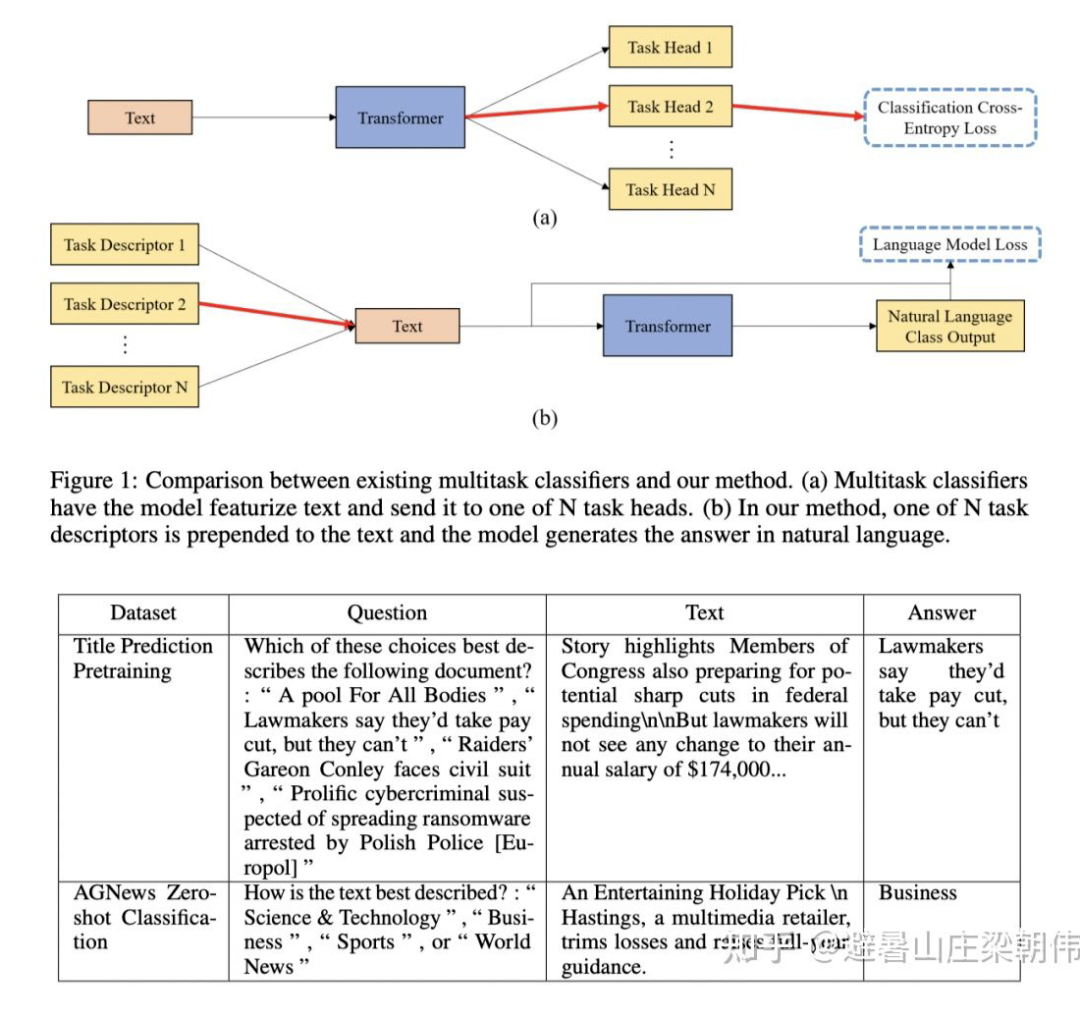


method:

motivation:?
adapter 的延續(xù),將原來的參數(shù)上增加新參數(shù)(L0 正則約束稀疏性)
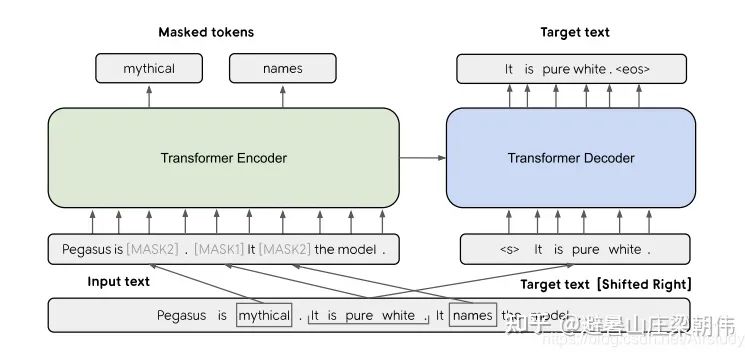
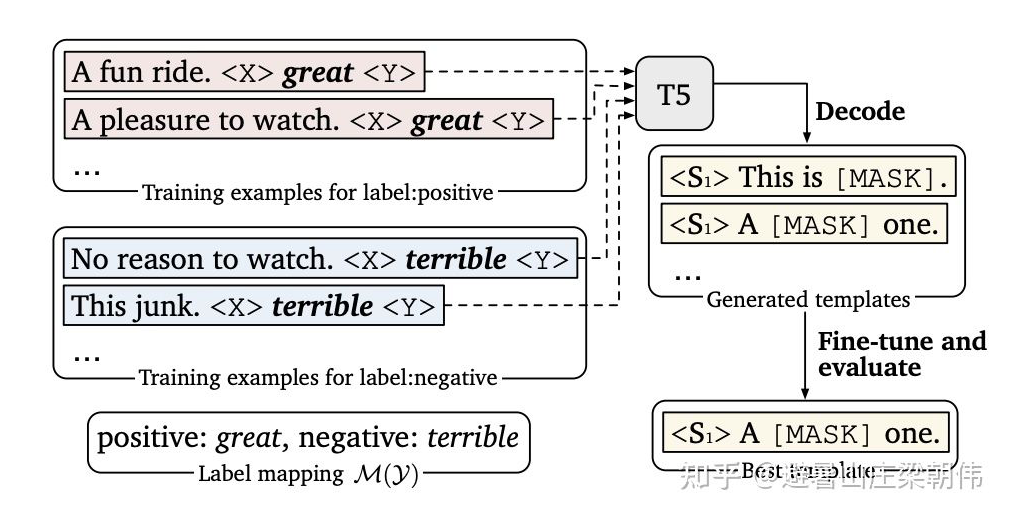
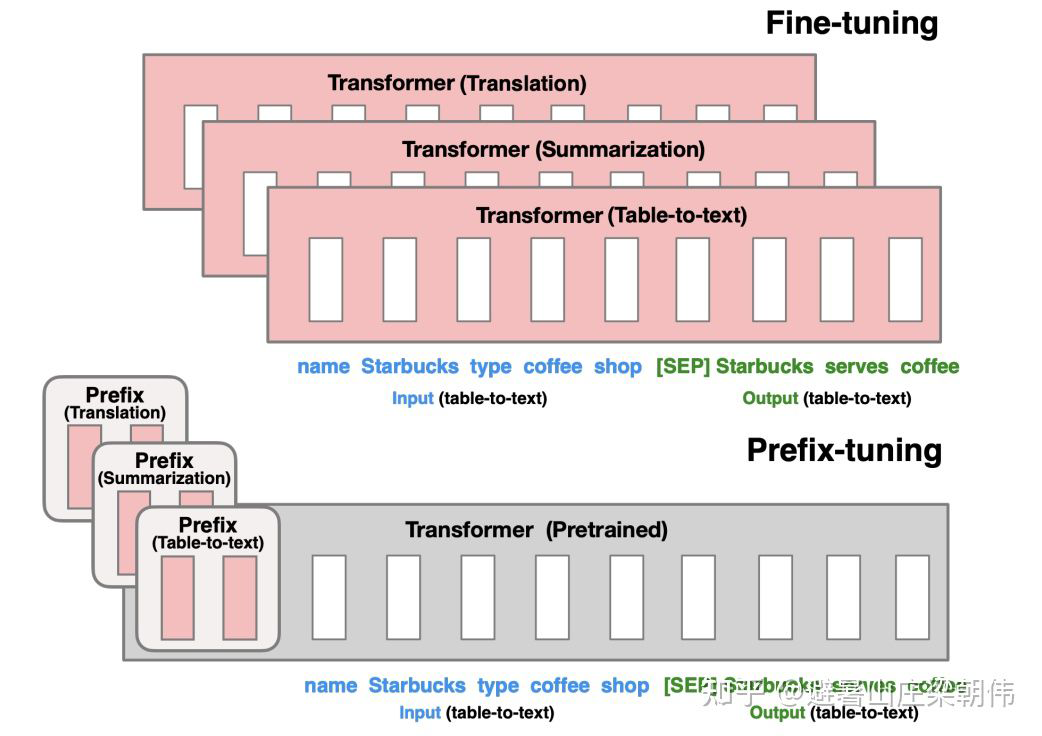


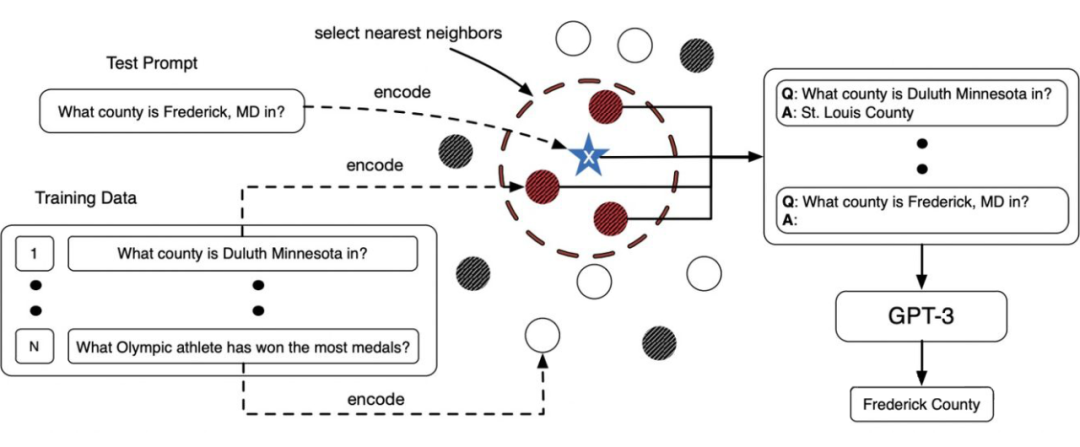
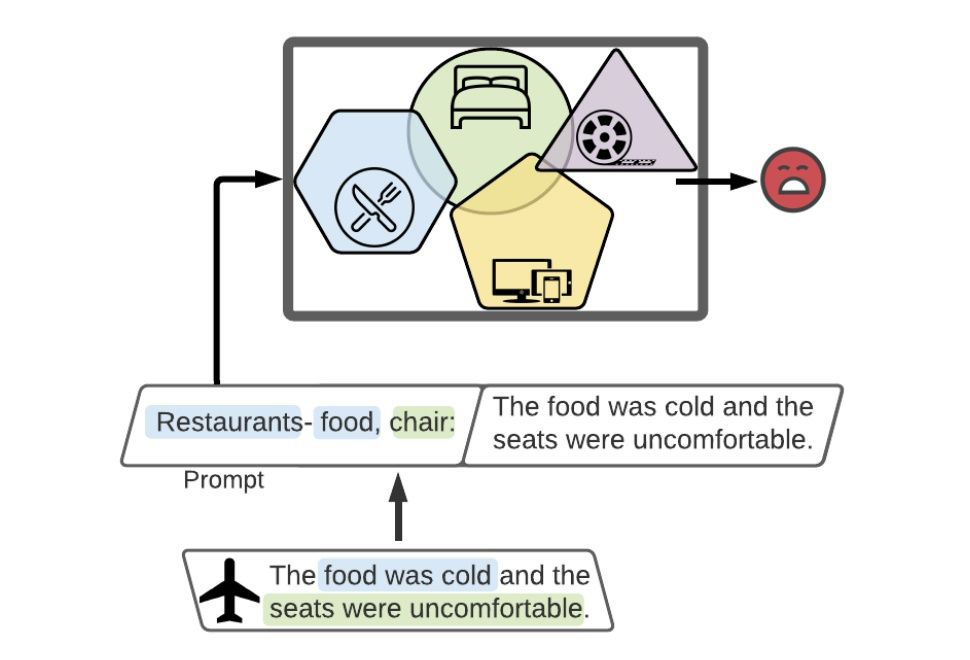
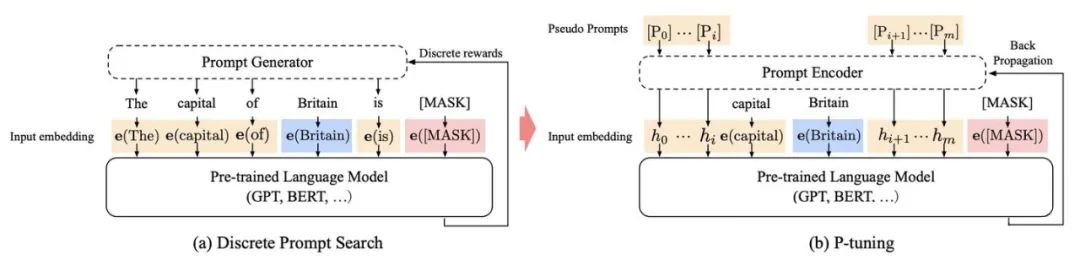


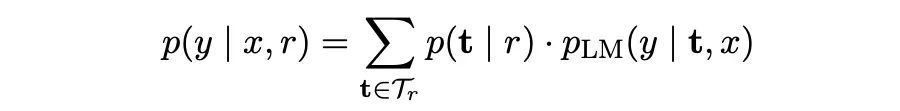





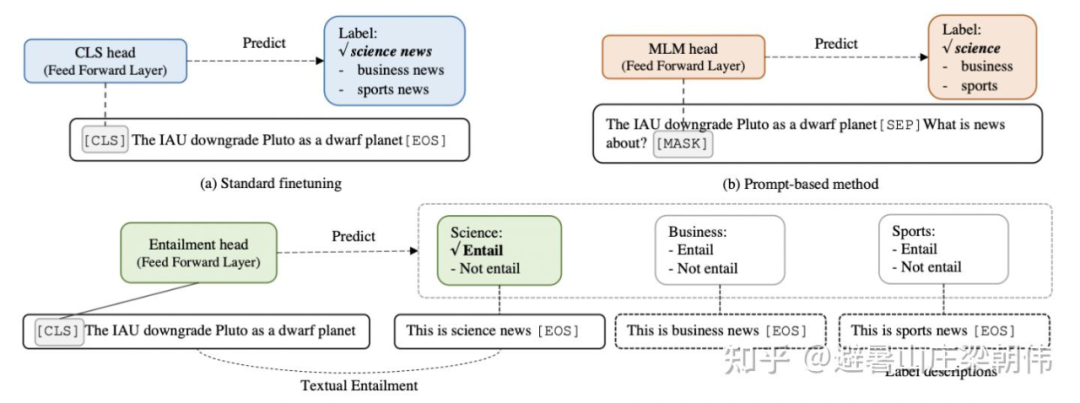
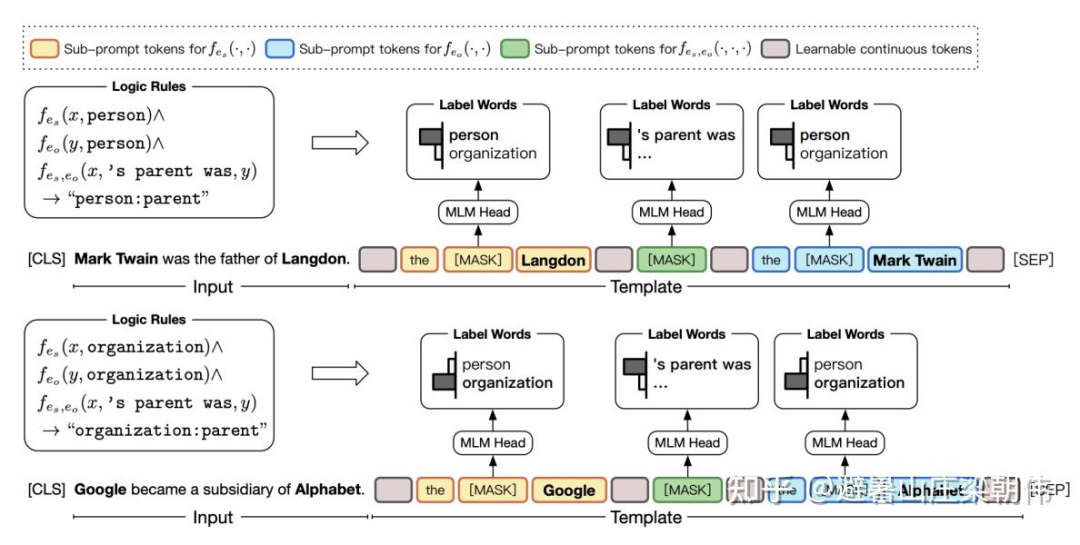
method:

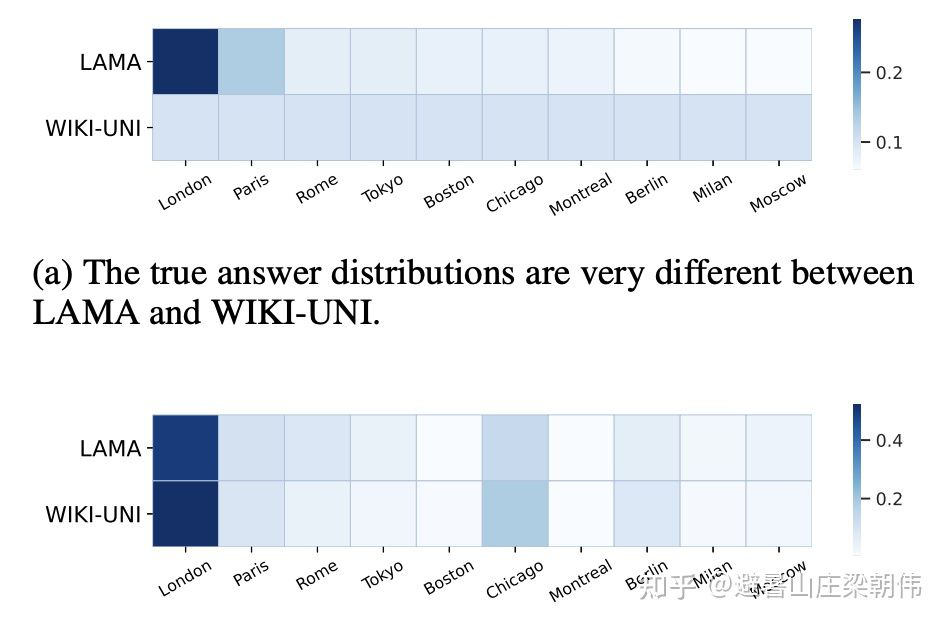
motivation:
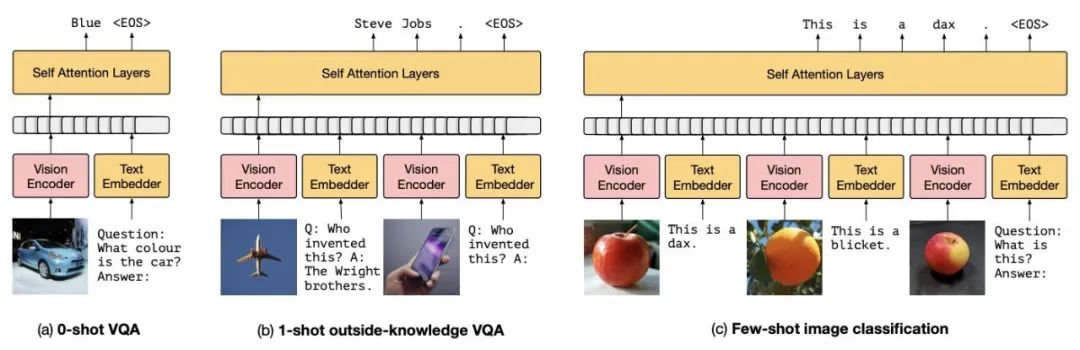
基于 prompt-tuning 的多模態(tài)小樣本學(xué)習(xí)模型
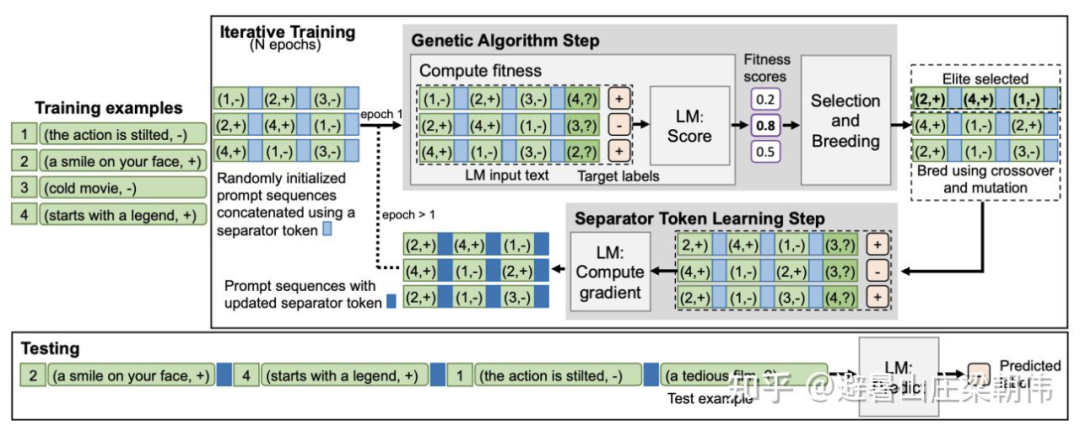
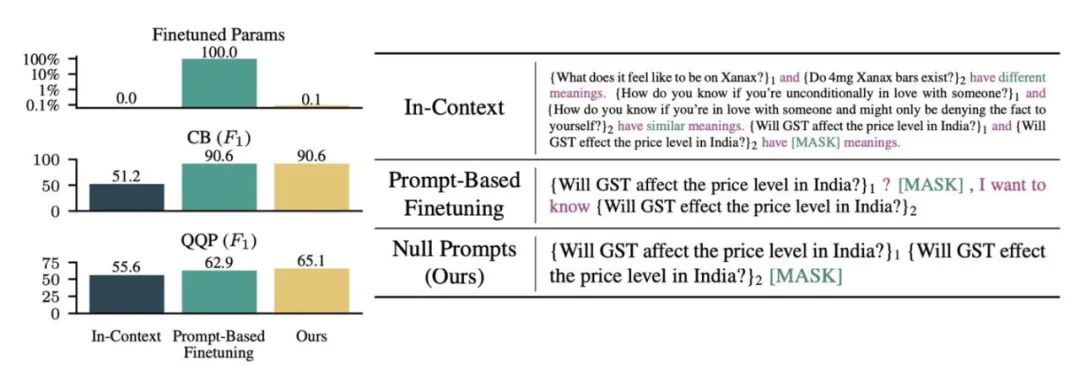
motivation:
method:
motivation:


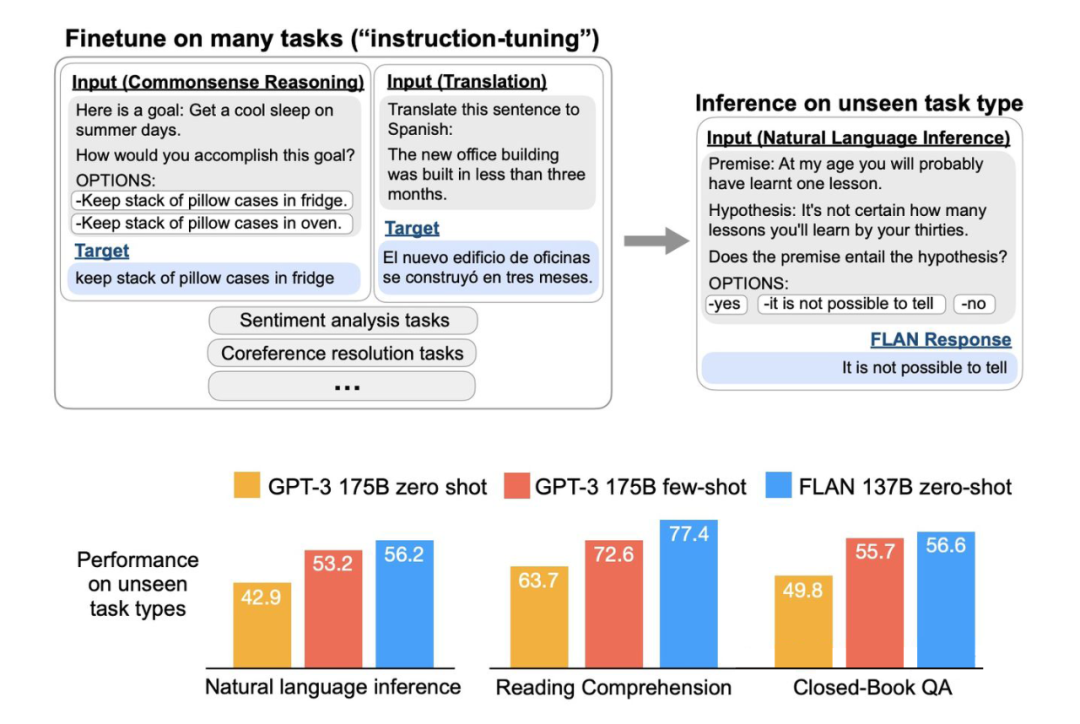
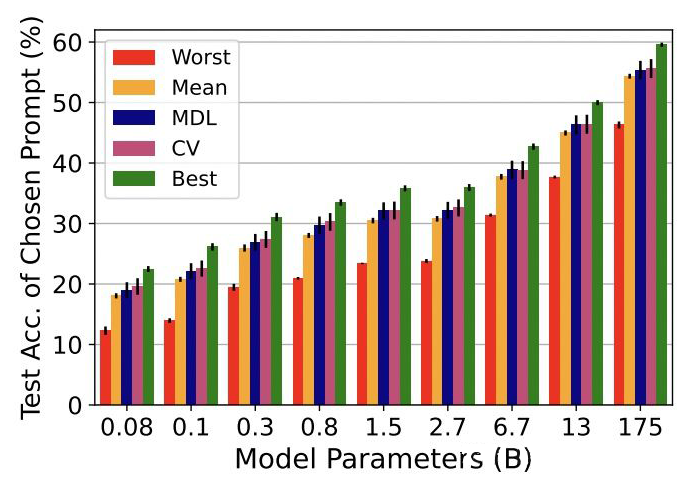
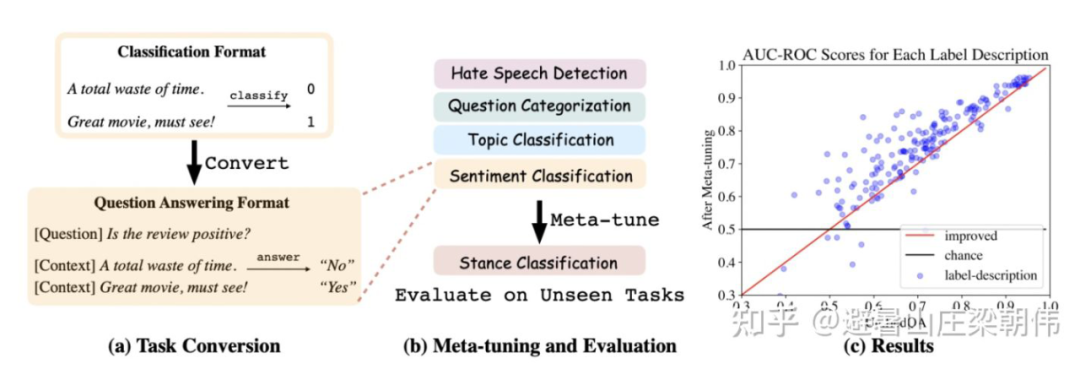
prompt pretraining 用于下游任務(wù),提供好的初始化 prompt,使得效果更穩(wěn)定

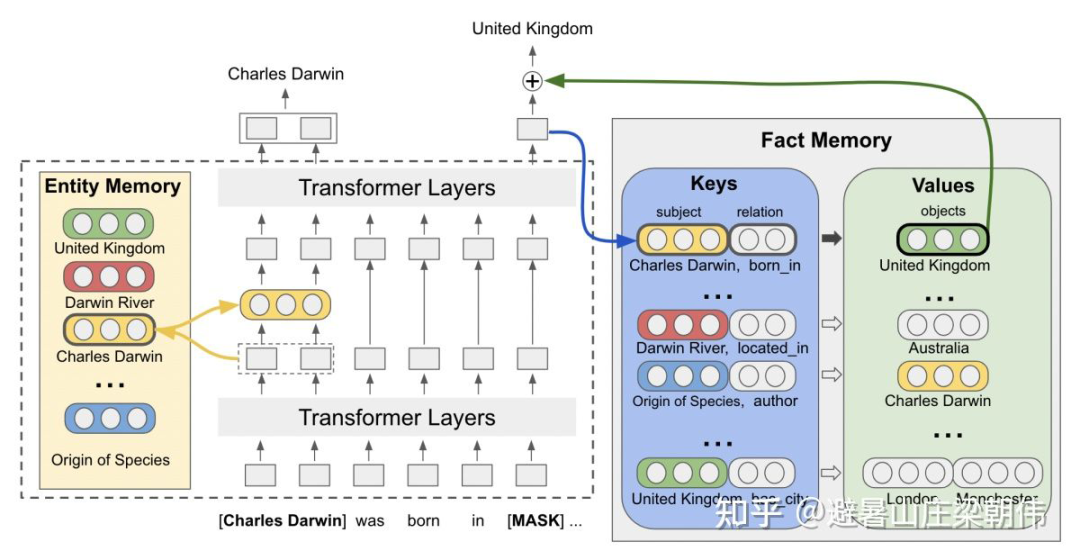
motivation:
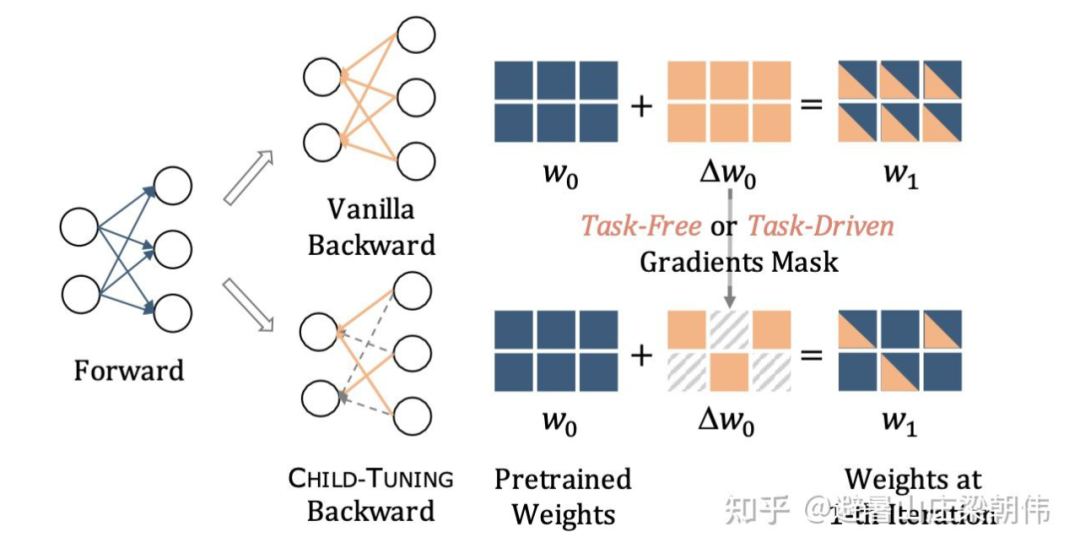
利用大規(guī)模預(yù)訓(xùn)練模型提供的強(qiáng)大知識(shí),決海量參數(shù)與少量標(biāo)注樣本的不匹配問題,在前向傳播的時(shí)候保持與正常 fine-tune 一樣,利用整個(gè)模型的參數(shù)來編碼輸入樣本;在后向傳播傳播更新參數(shù)的時(shí)候,無需利用少量樣本來調(diào)整海量參數(shù),而是僅僅更新這么龐大的參數(shù)網(wǎng)絡(luò)中的一部分,即網(wǎng)絡(luò)中的一個(gè) Child Network。在 full-shot 和 few-shot 上超過 finetune。整個(gè)方法沒有利用 prompt。
Step1:在預(yù)訓(xùn)練模型中發(fā)現(xiàn)確認(rèn) Child Network,并生成對(duì)應(yīng)的 Gradients Mask;
Step2:在后向傳播計(jì)算完梯度之后,僅僅對(duì) Child Network 中的參數(shù)進(jìn)行更新,而其他參數(shù)保持不變。
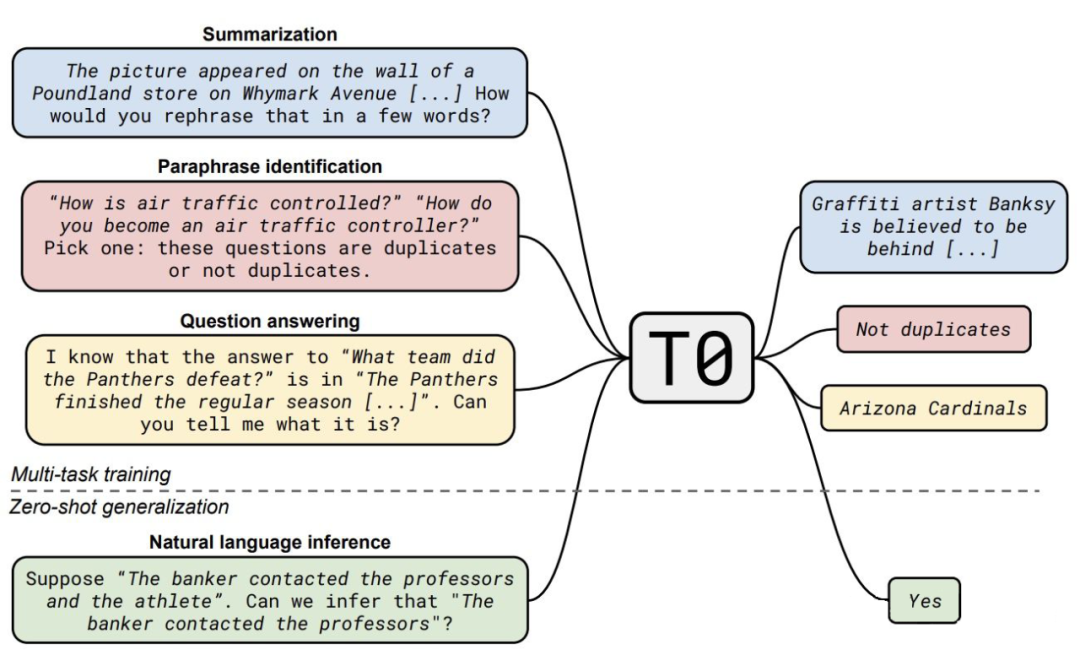

總結(jié)
一起交流
想和你一起學(xué)習(xí)進(jìn)步!『NewBeeNLP』目前已經(jīng)建立了多個(gè)不同方向交流群(機(jī)器學(xué)習(xí) / 深度學(xué)習(xí) / 自然語(yǔ)言處理 / 搜索推薦 / 圖網(wǎng)絡(luò) / 面試交流 /?等),名額有限,趕緊添加下方微信加入一起討論交流吧!(注意一定o要備注信息才能通過)
-?END?-

2021-11-03
2021-11-02
2021-11-01


評(píng)論
圖片
表情