
基于 Python 的 11 種經典數據降維算法
日期:2020年09月08日
正文共:4302字15圖
預計閱讀時間:11分鐘
來源:雷課
 MNIST 手寫數字數據集
MNIST 手寫數字數據集使得數據集更易使用
確保變量之間彼此獨立
降低算法計算運算成本


線性降維方法:PCA 、ICA LDA、LFA、LPP(LE 的線性表示)
非線性降維方法:
基于核函數的非線性降維方法——KPCA 、KICA、KDA
基于特征值的非線性降維方法(流型學習)——ISOMAP、LLE、LE、LPP、LTSA、MVU
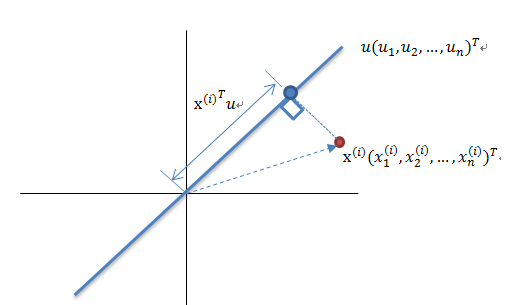
算法輸入:數據集 Xmxn;
按列計算數據集 X 的均值 Xmean,然后令 Xnew=X?Xmean;
求解矩陣 Xnew 的協(xié)方差矩陣,并將其記為 Cov;
計算協(xié)方差矩陣 COV 的特征值和相應的特征向量;
將特征值按照從大到小的排序,選擇其中最大的 k 個,然后將其對應的 k 個特征向量分別作為列向量組成特征向量矩陣 Wnxk;
計算 XnewW,即將數據集 Xnew 投影到選取的特征向量上,這樣就得到了我們需要的已經降維的數據集 XnewW。
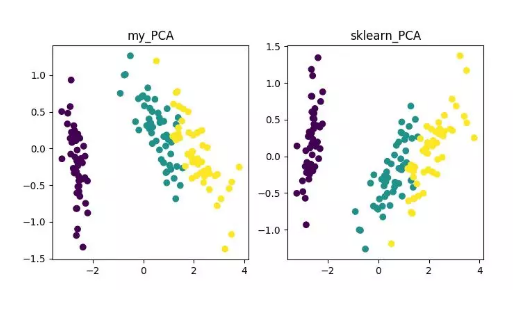
from __future__ import print_functionfrom sklearn import datasetsimport matplotlib.pyplot as pltimport matplotlib.cm as cmximport matplotlib.colors as colorsimport numpy as np%matplotlib inlinedef shuffle_data(X, y, seed=None):if seed:np.random.seed(seed)idx = np.arange(X.shape[0])np.random.shuffle(idx)return X[idx], y[idx]# 正規(guī)化數據集 Xdef normalize(X, axis=-1, p=2):lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))lp_norm[lp_norm == 0] = 1return X / np.expand_dims(lp_norm, axis)# 標準化數據集 Xdef standardize(X):X_std = np.zeros(X.shape)mean = X.mean(axis=0)std = X.std(axis=0)# 做除法運算時請永遠記住分母不能等于 0 的情形# X_std = (X - X.mean(axis=0)) / X.std(axis=0)for col in range(np.shape(X)[1]):if std[col]:X_std[:, col] = (X_std[:, col] - mean[col]) / std[col]return X_std# 劃分數據集為訓練集和測試集def train_test_split(X, y, test_size=0.2, shuffle=True, seed=None):if shuffle:X, y = shuffle_data(X, y, seed)n_train_samples = int(X.shape[0] * (1-test_size))x_train, x_test = X[:n_train_samples], X[n_train_samples:]y_train, y_test = y[:n_train_samples], y[n_train_samples:]return x_train, x_test, y_train, y_test# 計算矩陣 X 的協(xié)方差矩陣def calculate_covariance_matrix(X, Y=np.empty((0,0))):if not Y.any():Y = Xn_samples = np.shape(X)[0]covariance_matrix = (1 / (n_samples-1)) * (X - X.mean(axis=0)).T.dot(Y - Y.mean(axis=0))return np.array(covariance_matrix, dtype=float)# 計算數據集 X 每列的方差def calculate_variance(X):n_samples = np.shape(X)[0]variance = (1 / n_samples) * np.diag((X - X.mean(axis=0)).T.dot(X - X.mean(axis=0)))return variance# 計算數據集 X 每列的標準差def calculate_std_dev(X):std_dev = np.sqrt(calculate_variance(X))return std_dev# 計算相關系數矩陣def calculate_correlation_matrix(X, Y=np.empty([0])):# 先計算協(xié)方差矩陣covariance_matrix = calculate_covariance_matrix(X, Y)# 計算 X, Y 的標準差std_dev_X = np.expand_dims(calculate_std_dev(X), 1)std_dev_y = np.expand_dims(calculate_std_dev(Y), 1)correlation_matrix = np.divide(covariance_matrix, std_dev_X.dot(std_dev_y.T))return np.array(correlation_matrix, dtype=float)class PCA():"""主成份分析算法 PCA,非監(jiān)督學習算法."""def __init__(self):self.eigen_values = Noneself.eigen_vectors = Noneself.k = 2def transform(self, X):"""將原始數據集 X 通過 PCA 進行降維"""covariance = calculate_covariance_matrix(X)# 求解特征值和特征向量self.eigen_values, self.eigen_vectors = np.linalg.eig(covariance)# 將特征值從大到小進行排序,注意特征向量是按列排的,即 self.eigen_vectors 第 k 列是 self.eigen_values 中第 k 個特征值對應的特征向量idx = self.eigen_values.argsort()[::-1]eigenvalues = self.eigen_values[idx][:self.k]eigenvectors = self.eigen_vectors[:, idx][:, :self.k]# 將原始數據集 X 映射到低維空間X_transformed = X.dot(eigenvectors)return X_transformeddef main():# Load the datasetdata = datasets.load_iris()X = data.datay = data.target# 將數據集 X 映射到低維空間X_trans = PCA().transform(X)x1 = X_trans[:, 0]x2 = X_trans[:, 1]cmap = plt.get_cmap('viridis')colors = [cmap(i) for i in np.linspace(0, 1, len(np.unique(y)))]class_distr = []# Plot the different class distributionsfor i, l in enumerate(np.unique(y)):_x1 = x1[y == l]_x2 = x2[y == l]_y = y[y == l]class_distr.append(plt.scatter(_x1, _x2, color=colors[i]))# Add a legendplt.legend(class_distr, y, loc=1)# Axis labelsplt.xlabel('Principal Component 1')plt.ylabel('Principal Component 2')plt.show()if __name__ == "__main__":main()
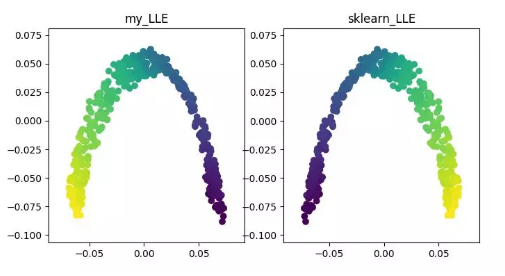
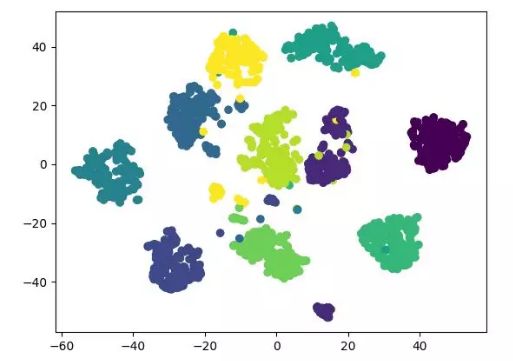
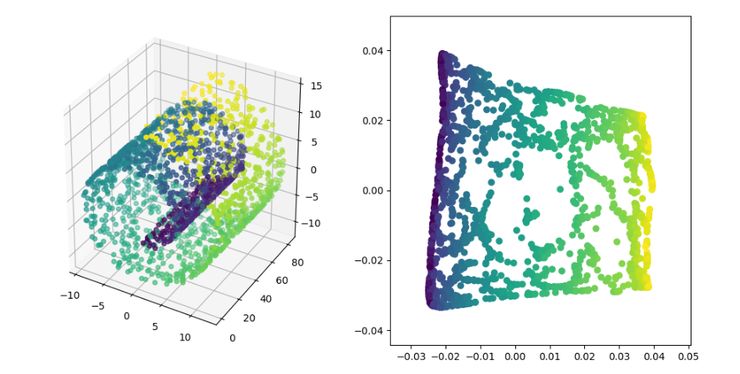
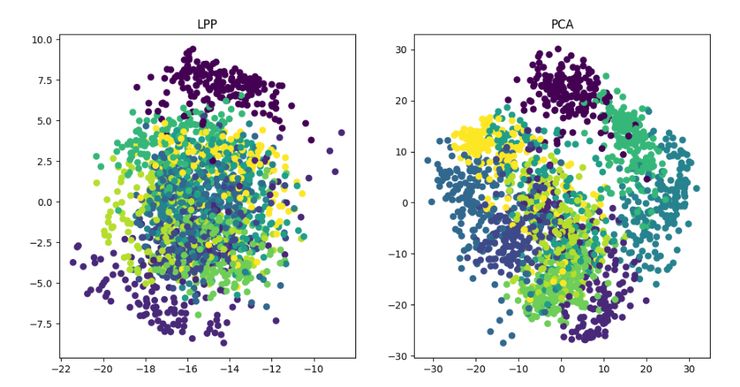
—?THE END —

評論
圖片
表情