
基于 Python 的 11 種經(jīng)典數(shù)據(jù)降維算法
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達


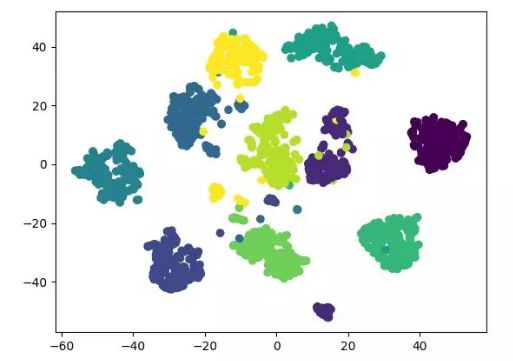
 MNIST 手寫數(shù)字數(shù)據(jù)集
MNIST 手寫數(shù)字數(shù)據(jù)集使得數(shù)據(jù)集更易使用
確保變量之間彼此獨立
降低算法計算運算成本


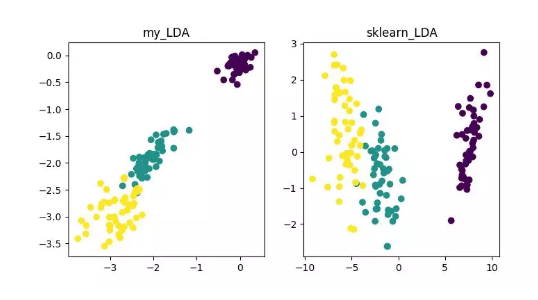
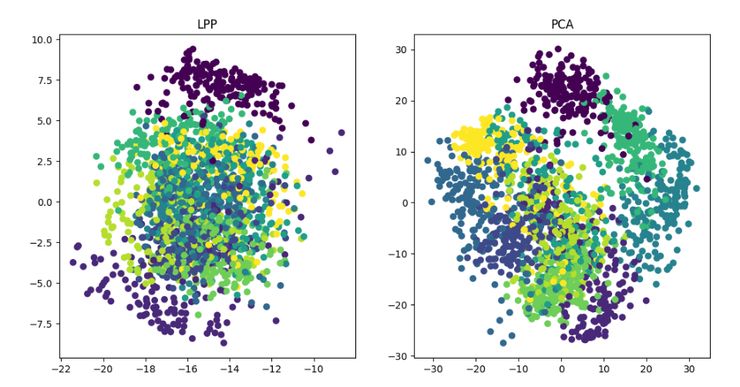
線性降維方法:PCA 、ICA LDA、LFA、LPP(LE 的線性表示)
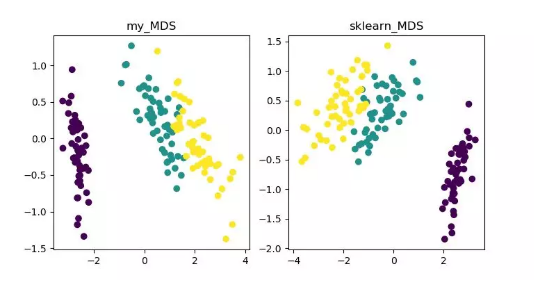
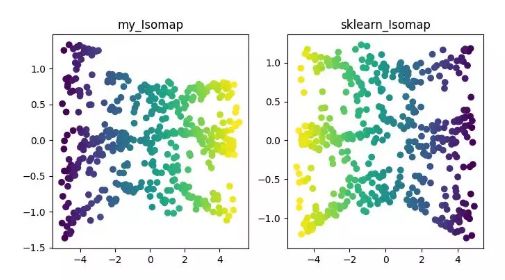
非線性降維方法:
基于核函數(shù)的非線性降維方法——KPCA 、KICA、KDA
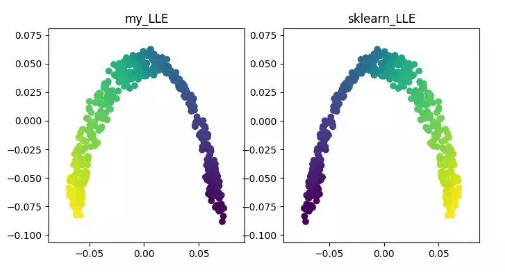
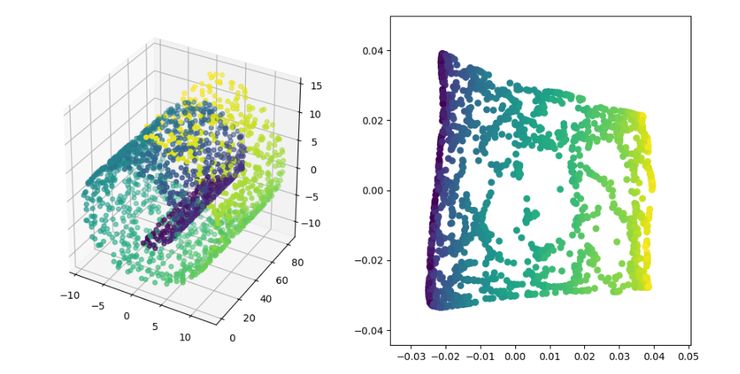
基于特征值的非線性降維方法(流型學習)——ISOMAP、LLE、LE、LPP、LTSA、MVU
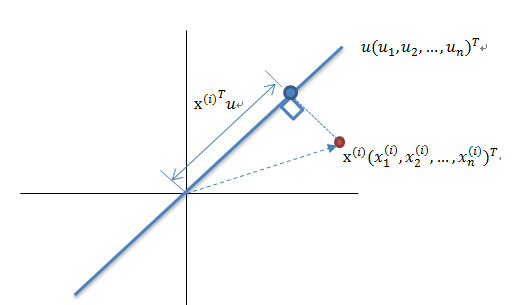
算法輸入:數(shù)據(jù)集 Xmxn;
按列計算數(shù)據(jù)集 X 的均值 Xmean,然后令 Xnew=X?Xmean;
求解矩陣 Xnew 的協(xié)方差矩陣,并將其記為 Cov;
計算協(xié)方差矩陣 COV 的特征值和相應(yīng)的特征向量;
將特征值按照從大到小的排序,選擇其中最大的 k 個,然后將其對應(yīng)的 k 個特征向量分別作為列向量組成特征向量矩陣 Wnxk;
計算 XnewW,即將數(shù)據(jù)集 Xnew 投影到選取的特征向量上,這樣就得到了我們需要的已經(jīng)降維的數(shù)據(jù)集 XnewW。
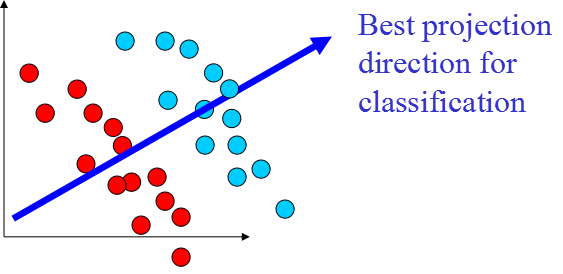
from __future__ import print_function
from sklearn import datasets
import matplotlib.pyplot as plt
import matplotlib.cm as cmx
import matplotlib.colors as colors
import numpy as np
%matplotlib inline
def shuffle_data(X, y, seed=None):
if seed:
np.random.seed(seed)
idx = np.arange(X.shape[0])
np.random.shuffle(idx)
return X[idx], y[idx]
# 正規(guī)化數(shù)據(jù)集 X
def normalize(X, axis=-1, p=2):
lp_norm = np.atleast_1d(np.linalg.norm(X, p, axis))
lp_norm[lp_norm == 0] = 1
return X / np.expand_dims(lp_norm, axis)
# 標準化數(shù)據(jù)集 X
def standardize(X):
X_std = np.zeros(X.shape)
mean = X.mean(axis=0)
std = X.std(axis=0)
# 做除法運算時請永遠記住分母不能等于 0 的情形
# X_std = (X - X.mean(axis=0)) / X.std(axis=0)
for col in range(np.shape(X)[1]):
if std[col]:
X_std[:, col] = (X_std[:, col] - mean[col]) / std[col]
return X_std
# 劃分數(shù)據(jù)集為訓練集和測試集
def train_test_split(X, y, test_size=0.2, shuffle=True, seed=None):
if shuffle:
X, y = shuffle_data(X, y, seed)
n_train_samples = int(X.shape[0] * (1-test_size))
x_train, x_test = X[:n_train_samples], X[n_train_samples:]
y_train, y_test = y[:n_train_samples], y[n_train_samples:]
return x_train, x_test, y_train, y_test
# 計算矩陣 X 的協(xié)方差矩陣
def calculate_covariance_matrix(X, Y=np.empty((0,0))):
if not Y.any():
Y = X
n_samples = np.shape(X)[0]
covariance_matrix = (1 / (n_samples-1)) * (X - X.mean(axis=0)).T.dot(Y - Y.mean(axis=0))
return np.array(covariance_matrix, dtype=float)
# 計算數(shù)據(jù)集 X 每列的方差
def calculate_variance(X):
n_samples = np.shape(X)[0]
variance = (1 / n_samples) * np.diag((X - X.mean(axis=0)).T.dot(X - X.mean(axis=0)))
return variance
# 計算數(shù)據(jù)集 X 每列的標準差
def calculate_std_dev(X):
std_dev = np.sqrt(calculate_variance(X))
return std_dev
# 計算相關(guān)系數(shù)矩陣
def calculate_correlation_matrix(X, Y=np.empty([0])):
# 先計算協(xié)方差矩陣
covariance_matrix = calculate_covariance_matrix(X, Y)
# 計算 X, Y 的標準差
std_dev_X = np.expand_dims(calculate_std_dev(X), 1)
std_dev_y = np.expand_dims(calculate_std_dev(Y), 1)
correlation_matrix = np.divide(covariance_matrix, std_dev_X.dot(std_dev_y.T))
return np.array(correlation_matrix, dtype=float)
class PCA():
"""
主成份分析算法 PCA,非監(jiān)督學習算法.
"""
def __init__(self):
self.eigen_values = None
self.eigen_vectors = None
self.k = 2
def transform(self, X):
"""
將原始數(shù)據(jù)集 X 通過 PCA 進行降維
"""
covariance = calculate_covariance_matrix(X)
# 求解特征值和特征向量
self.eigen_values, self.eigen_vectors = np.linalg.eig(covariance)
# 將特征值從大到小進行排序,注意特征向量是按列排的,即 self.eigen_vectors 第 k 列是 self.eigen_values 中第 k 個特征值對應(yīng)的特征向量
idx = self.eigen_values.argsort()[::-1]
eigenvalues = self.eigen_values[idx][:self.k]
eigenvectors = self.eigen_vectors[:, idx][:, :self.k]
# 將原始數(shù)據(jù)集 X 映射到低維空間
X_transformed = X.dot(eigenvectors)
return X_transformed
def main():
# Load the dataset
data = datasets.load_iris()
X = data.data
y = data.target
# 將數(shù)據(jù)集 X 映射到低維空間
X_trans = PCA().transform(X)
x1 = X_trans[:, 0]
x2 = X_trans[:, 1]
cmap = plt.get_cmap('viridis')
colors = [cmap(i) for i in np.linspace(0, 1, len(np.unique(y)))]
class_distr = []
# Plot the different class distributions
for i, l in enumerate(np.unique(y)):
_x1 = x1[y == l]
_x2 = x2[y == l]
_y = y[y == l]
class_distr.append(plt.scatter(_x1, _x2, color=colors[i]))
# Add a legend
plt.legend(class_distr, y, loc=1)
# Axis labels
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
if __name__ == "__main__":
main()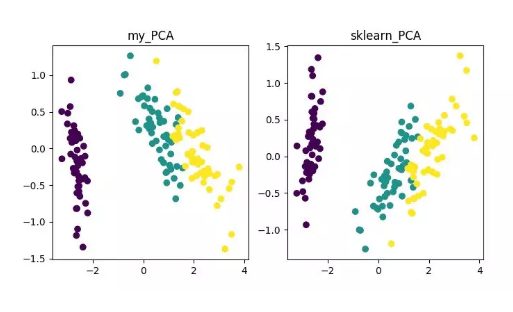
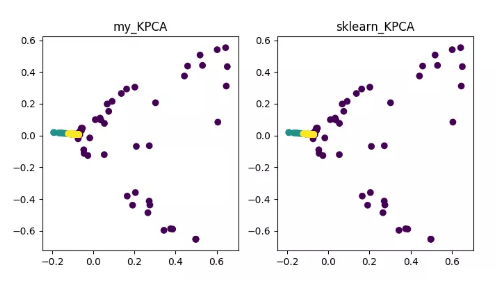
KPCA(kernel PCA)
好消息!
小白學視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~
評論
圖片
表情