
2020 神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索(NAS)最新技術(shù)綜述

極市導(dǎo)讀
?近年來(lái)有關(guān)NAS的優(yōu)秀的工作層出不窮,分別從不同的角度來(lái)提升NAS算法。為了讓初學(xué)者更好的進(jìn)行NAS相關(guān)的研究,本文從其產(chǎn)生的背景到未來(lái)的發(fā)展方向,全面而系統(tǒng)的綜述了NAS的挑戰(zhàn)和解決方案。>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
【內(nèi)容速覽】你可能感興趣的內(nèi)容:
NAS是什么?由什么組成?常用算法是什么?
Add操作要比concate操作更加有效。
寬而淺的單元(采用channel個(gè)數(shù)多,但層數(shù)不多)在訓(xùn)練過(guò)程中更容易收斂,但是缺點(diǎn)是泛化性能很差。
能根據(jù)網(wǎng)絡(luò)前幾個(gè)epoch的表現(xiàn)就確定這個(gè)網(wǎng)絡(luò)是否能夠取得更高性能的預(yù)測(cè)器(性能預(yù)測(cè))。
根據(jù)候選網(wǎng)絡(luò)結(jié)構(gòu)的表示就可以預(yù)測(cè)這個(gè)模型未來(lái)的表現(xiàn)(性能預(yù)測(cè))。
分類的backbone和其他任務(wù)比如檢測(cè)是存在一定gap的,最好的方式并不一定是微調(diào),而可能是改變網(wǎng)絡(luò)架構(gòu)。
1. 背景 2. NAS介紹 3. 早期NAS的特征 3.1 全局搜索 3.2 從頭搜索 4. 優(yōu)化策略 4.1 模塊搜索策略 4.2 連續(xù)的搜索空間 4.3 網(wǎng)絡(luò)架構(gòu)重復(fù)利用 4.4 不完全訓(xùn)練 5. 性能對(duì)比 6. 未來(lái)的方向 7. 結(jié)語(yǔ) 8. 參考文獻(xiàn)
1. 背景
早期NAS算法的特點(diǎn)。 總結(jié)早期NAS算法中存在的問(wèn)題。 給出隨后的NAS算法對(duì)以上問(wèn)題提出的解決方案。 對(duì)以上算法繼續(xù)分析、對(duì)比、總結(jié)。 給出NAS未來(lái)可能的發(fā)展方向。
2. NAS介紹
identity 卷積層(3x3、5x5、7x7) 深度可分離卷積 空洞卷積 組卷積 池化層 Global Average Pooling 其他
search space 如何定義搜索空間 search strategy 搜索的策略 evaluation strategy 評(píng)估的策略
3. 早期NAS的特征
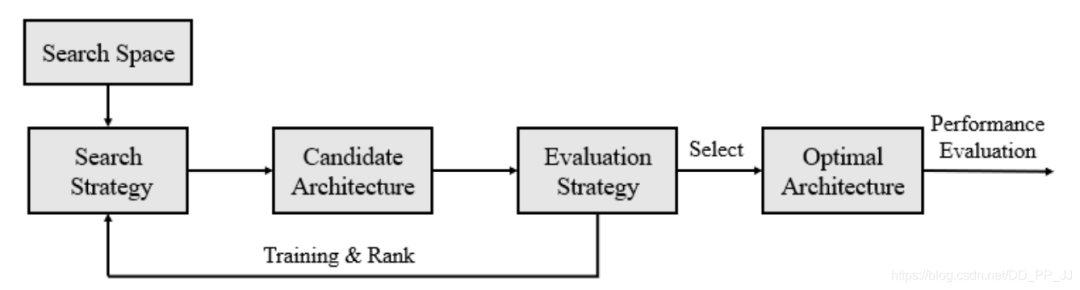
找一些預(yù)定義的操作集合(eg 卷積、池化等)這些集合構(gòu)成了Search Space搜索空間。 采用一定的搜索策略來(lái)獲取大量的候選網(wǎng)絡(luò)結(jié)構(gòu)。 在訓(xùn)練集訓(xùn)練這些網(wǎng)絡(luò),并且在驗(yàn)證集測(cè)試得到這些候選網(wǎng)絡(luò)的準(zhǔn)確率。 這些候選網(wǎng)絡(luò)的準(zhǔn)確率會(huì)對(duì)搜索策略進(jìn)行反饋,從而可以調(diào)整搜索策略來(lái)獲得新一輪的候選網(wǎng)絡(luò)。重復(fù)這個(gè)過(guò)程。 當(dāng)終止條件達(dá)到(eg:準(zhǔn)確率達(dá)到某個(gè)閾值),搜索就會(huì)停下來(lái),這樣就可以找到準(zhǔn)確率最高對(duì)應(yīng)的網(wǎng)絡(luò)架構(gòu)。 在測(cè)試集上測(cè)試最好的網(wǎng)絡(luò)架構(gòu)的準(zhǔn)確率。
全局搜索策略:早期NAS采用的策略是搜索整個(gè)網(wǎng)絡(luò)的全局,這就意味著NAS需要在非常大的搜索空間中搜索出一個(gè)最優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu)。搜索空間越大,計(jì)算的代價(jià)也就越大。 離散的搜索空間:早期NAS的搜索空間都是離散的,不管是用變長(zhǎng)字符串也好,還是用二進(jìn)制串來(lái)表示,他們的搜索空間都是離散的,如果無(wú)法連續(xù),那就意味著無(wú)法計(jì)算梯度,也無(wú)法利用梯度策略來(lái)調(diào)整網(wǎng)絡(luò)模型架構(gòu)。 從頭開(kāi)始搜索:每個(gè)模型都是從頭訓(xùn)練的,這樣將無(wú)法充分利用現(xiàn)存的網(wǎng)絡(luò)模型的結(jié)構(gòu)和已經(jīng)訓(xùn)練得到的參數(shù)。
3.1 全局搜索
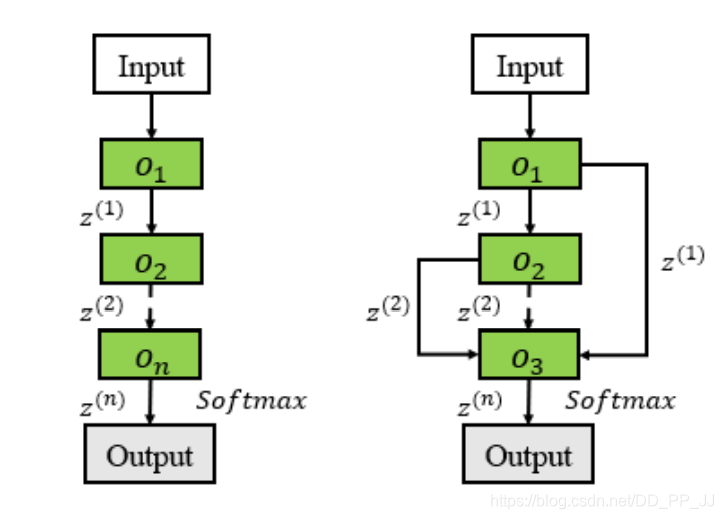
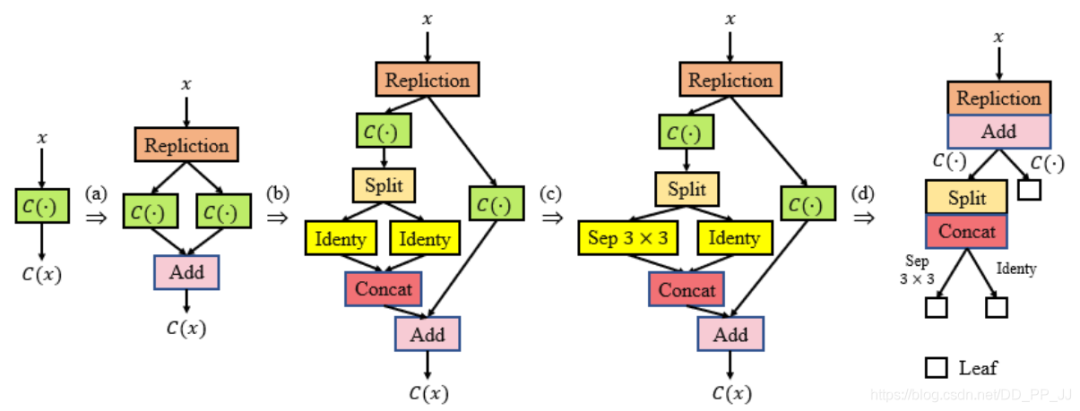
“注記:跳轉(zhuǎn)連接往往可以采用多種方式進(jìn)行特征融合,常見(jiàn)的有add, concate等。作者在文中提到了實(shí)驗(yàn)證明,add操作要比concate操作更加有效(原文:the sum operation is better than the merge operation)所以在NAS中,通常采用Add的方法進(jìn)行特征融合操作。
3.2 從頭搜索
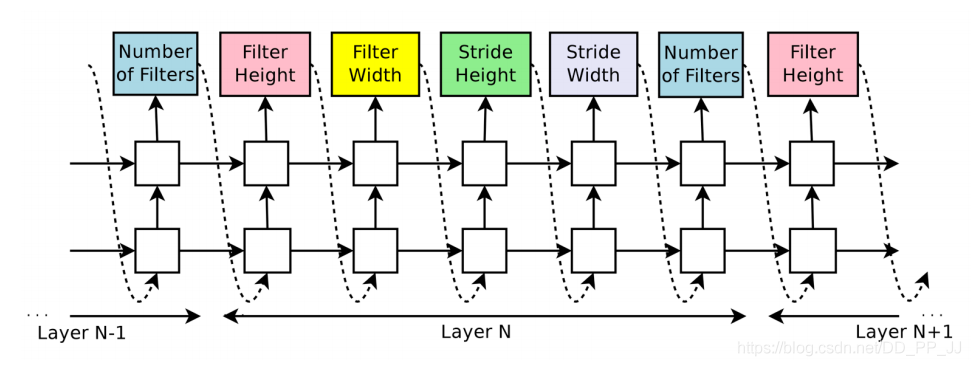
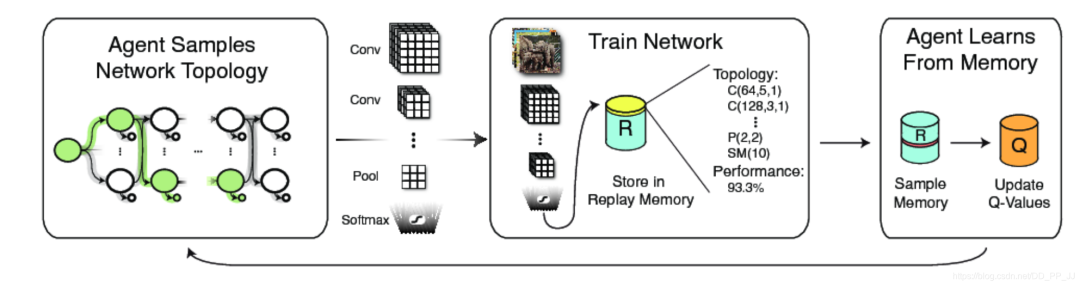
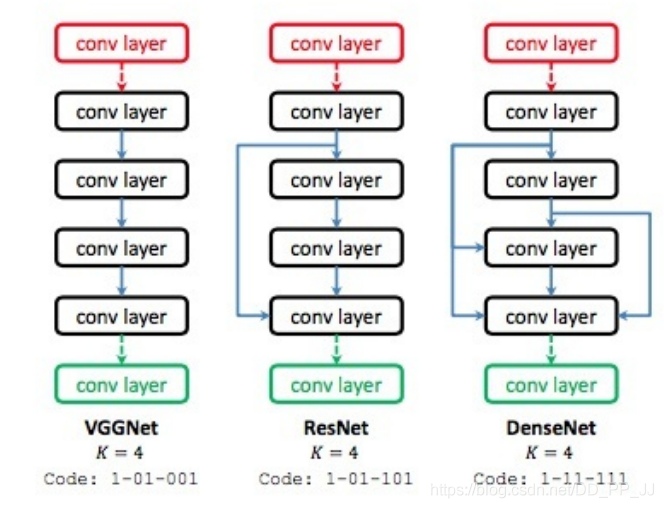
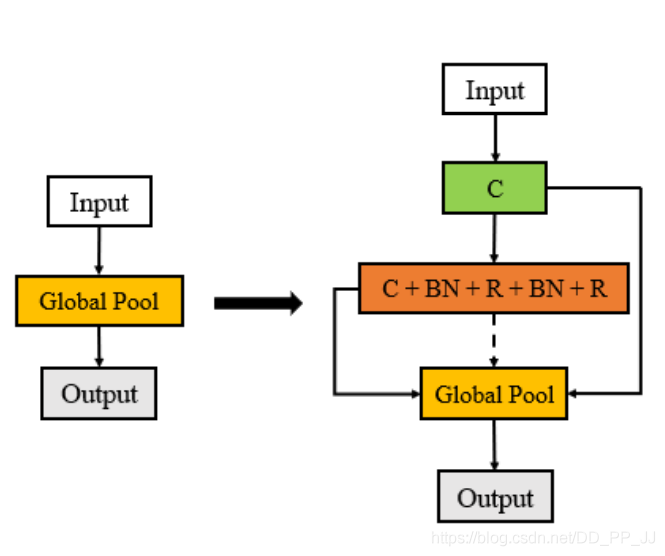
4. 優(yōu)化策略
4.1 模塊搜索策略
Normal Cell也就是正常模塊,用于提取特征,但是這個(gè)單元不能改變特征圖的空間分辨率。 Reduction Cell和池化層類似,用于減少特征圖的空間分辨率。
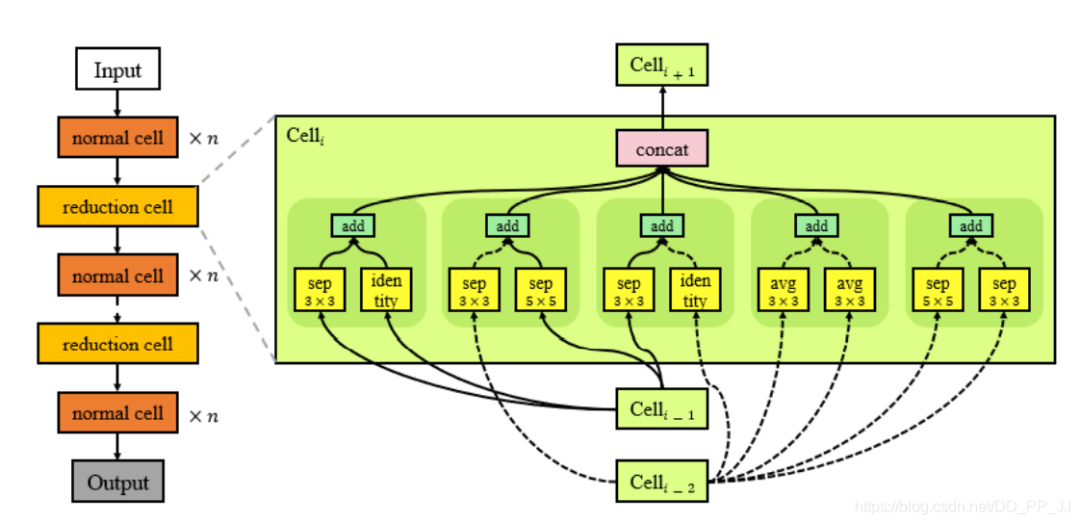
使用單元操作來(lái)取代reduction cell(reduction cell往往比較簡(jiǎn)單,沒(méi)有必要搜索,采用下采樣的單元操作即可,如下圖Dpp-Net的結(jié)構(gòu))下圖Dpp-Net中采用了密集連接。
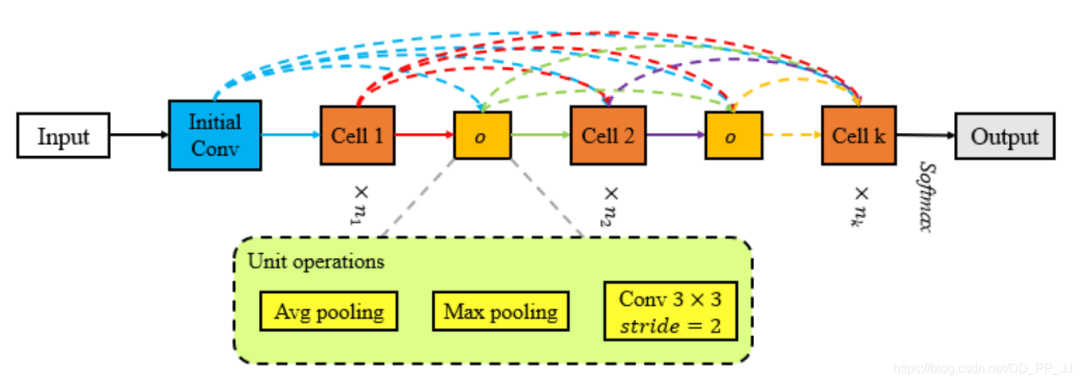
Block-QNN中直接采用池化操作來(lái)取代Reduction cell Hierarchical-EAS中使用了3x3的kernel size, 以2為stride的卷積來(lái)替代Reduction Cell。 Dpp-Net采用平均池化操作取代Reduction Cell。同時(shí)采取了Dense連接+考慮了多目標(biāo)優(yōu)化問(wèn)題。 在視頻任務(wù):SNAS使用了Lx3x3,stride=1,2,2的maxpooling取代Reduction Cell。 在分割任務(wù):AutoDispNet提出了一個(gè)自動(dòng)化的架構(gòu)搜索技術(shù)來(lái)優(yōu)化大規(guī)模U-Net類似的encoder-decoder的架構(gòu)。所以需要搜索三種:normal、reduction、upsampling。
“注記:通過(guò)研究這些搜索得到的單元模塊,可以得到以下他們的共性:由于現(xiàn)存的連接模式,寬而淺的單元(采用channel個(gè)數(shù)多,但層數(shù)不多)在訓(xùn)練過(guò)程中更容易收斂,并且更容易搜索,但是缺點(diǎn)是泛化性能很差。
4.2 連續(xù)的搜索空間
中間節(jié)點(diǎn)代表潛在的特征表達(dá),并且和每個(gè)之前的節(jié)點(diǎn)都通過(guò)一個(gè)有向邊操作。對(duì)一個(gè)離散的空間來(lái)說(shuō),每個(gè)中繼節(jié)點(diǎn)可以這樣表達(dá):
在DARTS中,通過(guò)一個(gè)類似softmax來(lái)松弛所有可能的操作,這樣就將離散搜索空間轉(zhuǎn)化為連續(xù)的搜索空間問(wèn)題。
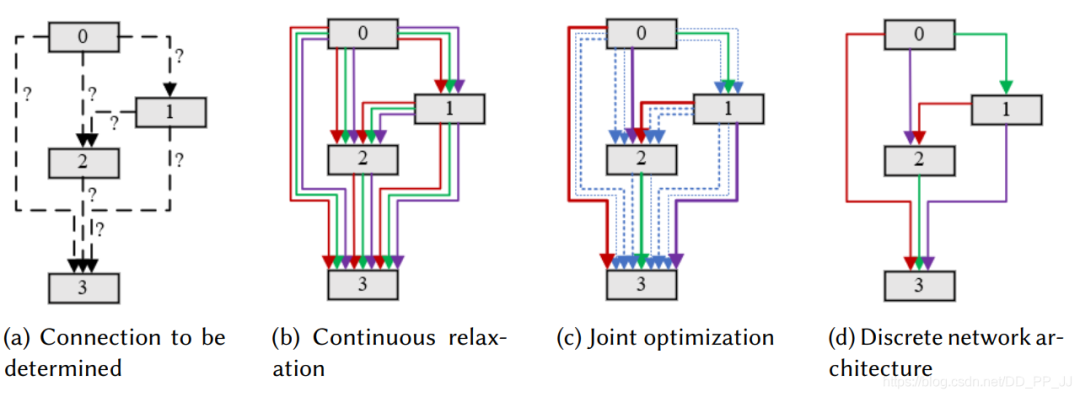
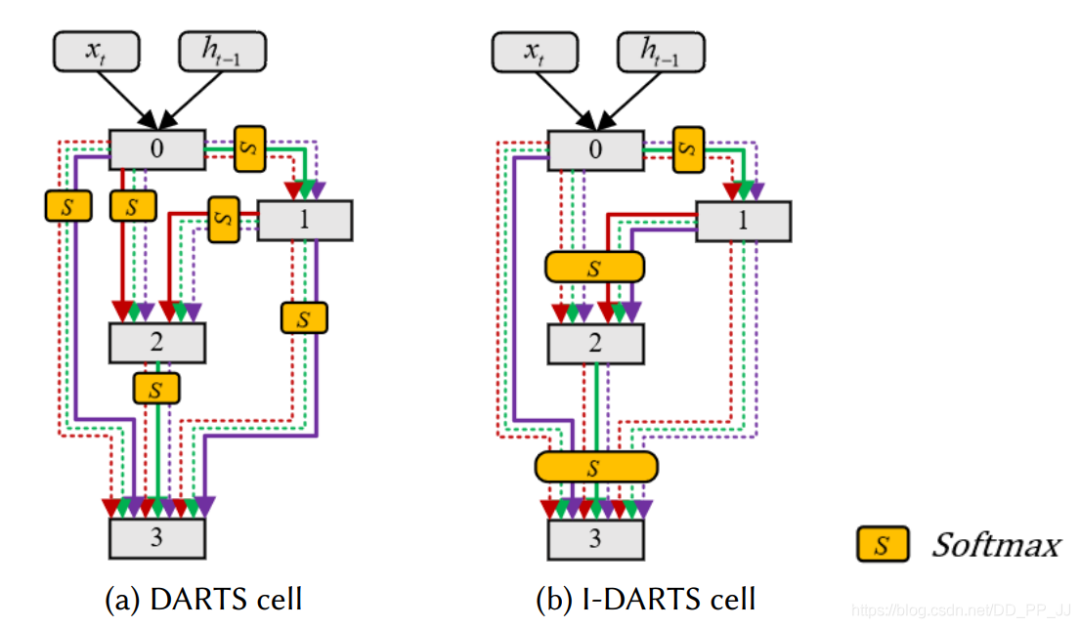
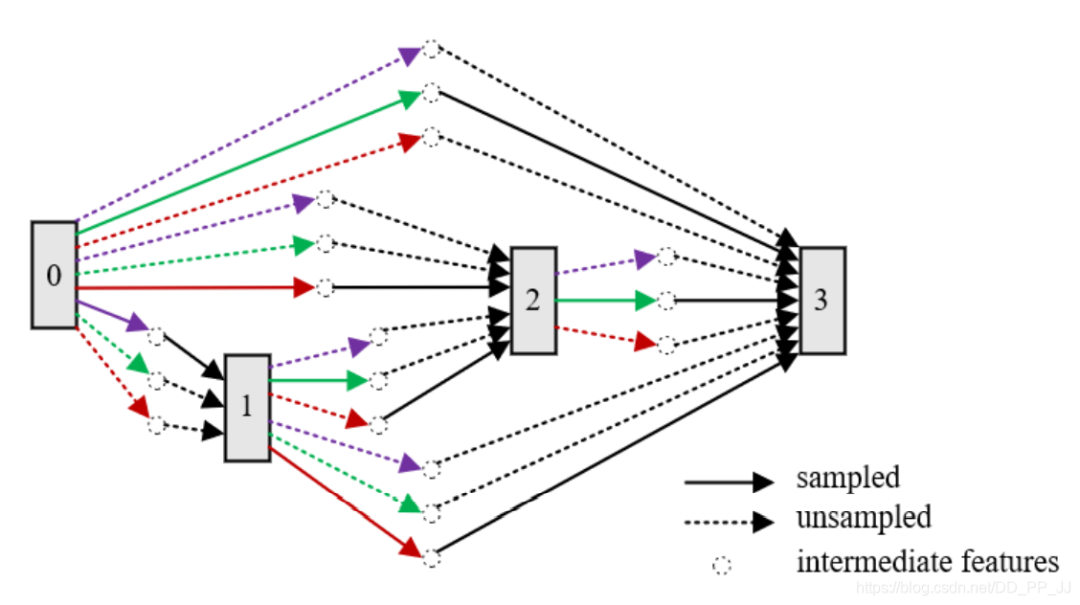
4.3 網(wǎng)絡(luò)架構(gòu)重復(fù)利用
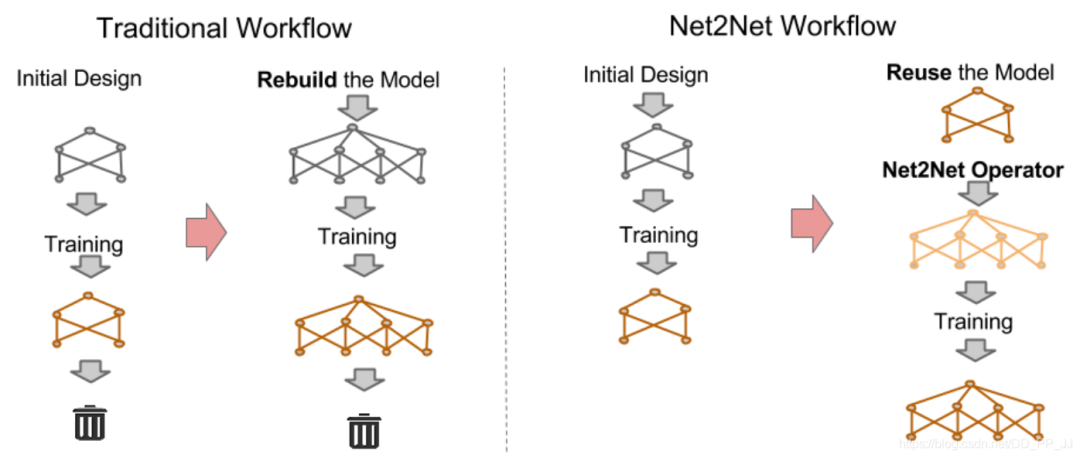
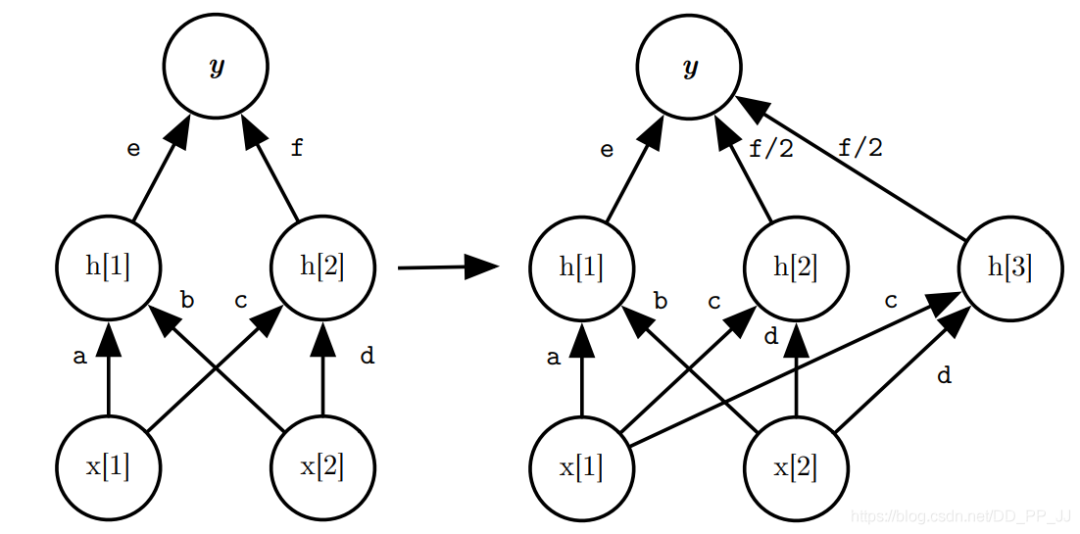

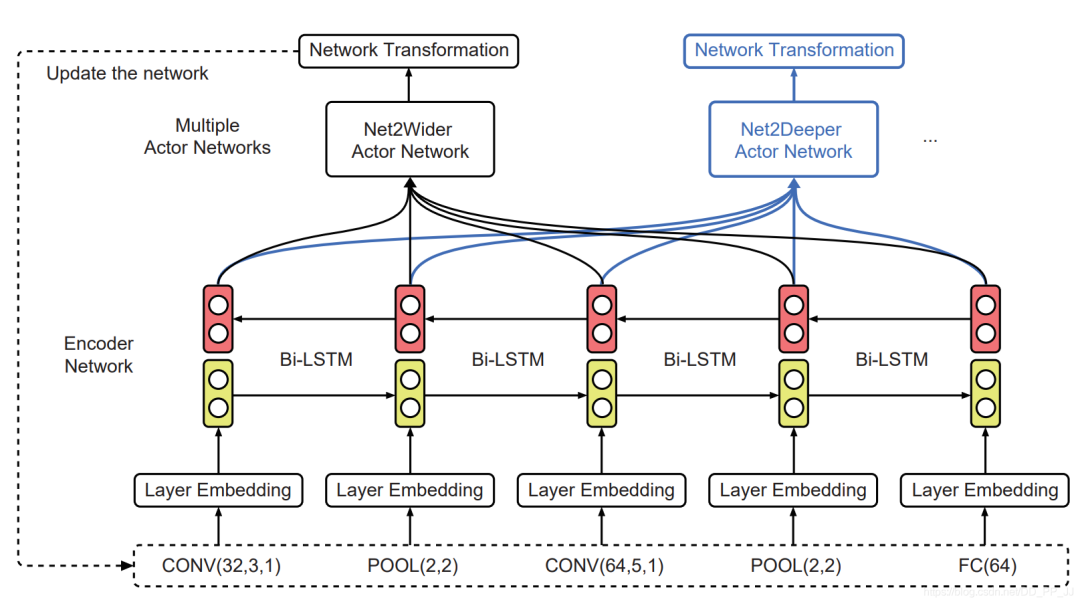
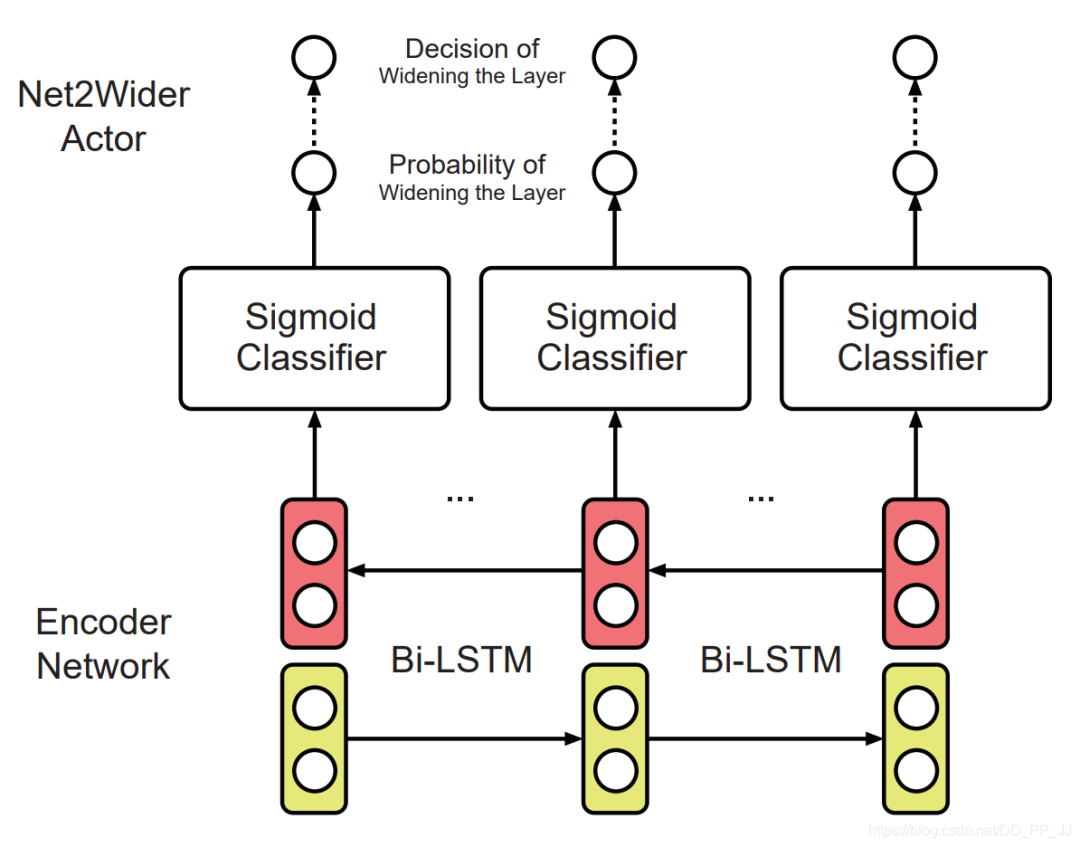
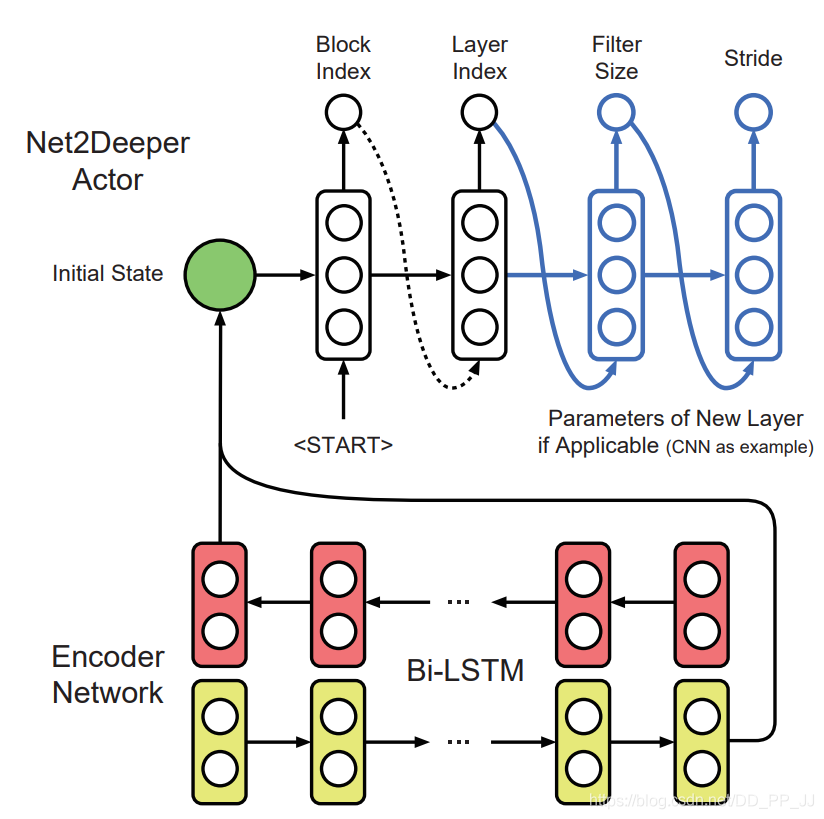
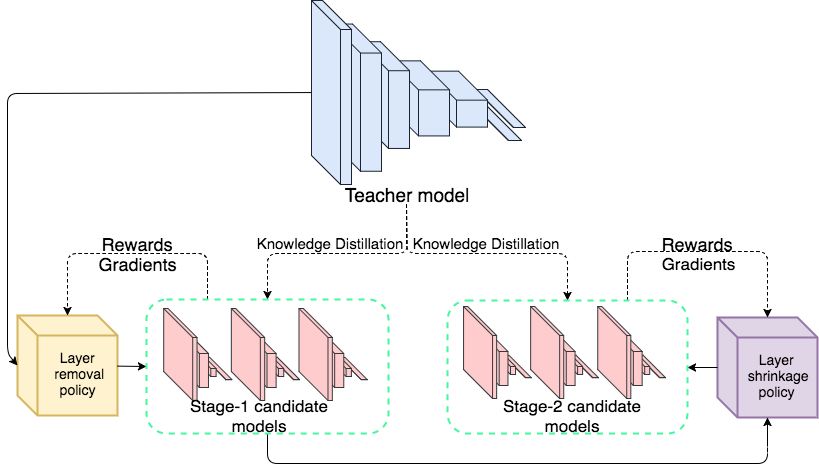
首先使用layer removal操作 然后使用layer shrinkage操作 使用強(qiáng)化學(xué)習(xí)來(lái)探索搜索空間 使用知識(shí)蒸餾的方法訓(xùn)練每個(gè)生成得到的網(wǎng)絡(luò)架構(gòu)。 最終得到一個(gè)局部最優(yōu)的學(xué)生網(wǎng)絡(luò)。
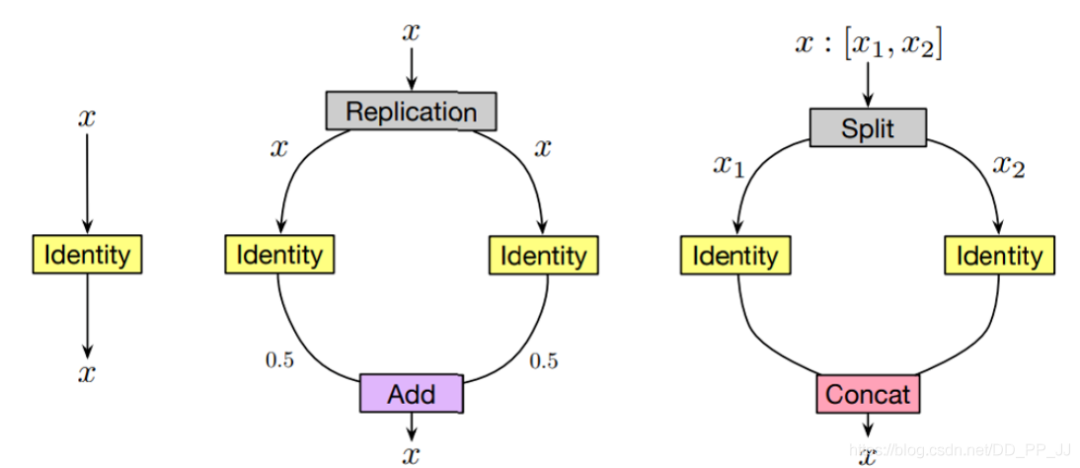
Replication就是將輸入x復(fù)制兩份,分別操作以后將得到的結(jié)果除以2再相加得到輸出。 Split就是將x按照維度切成兩份,分別操作以后,將得到的結(jié)果concate到一起。
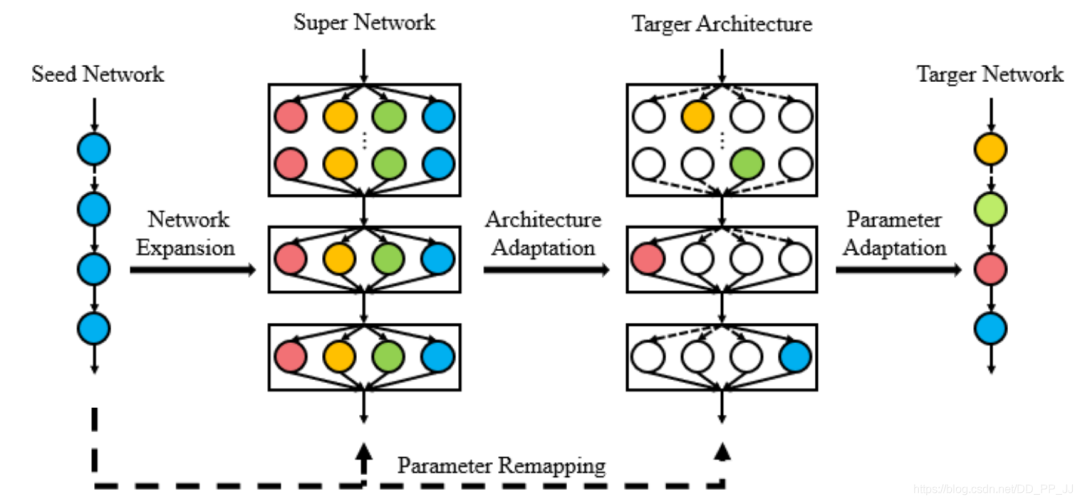
“ps: 分類backbone和其他任務(wù)是有一定gap的,FNA認(rèn)為通過(guò)微調(diào)神經(jīng)網(wǎng)絡(luò)帶來(lái)的收益不如調(diào)整網(wǎng)絡(luò)結(jié)構(gòu)帶來(lái)的收益)
4.4 不完全訓(xùn)練
NAS-RL采用了并行和異步的方法來(lái)加速候選網(wǎng)絡(luò)的訓(xùn)練 MetaQNN在第一個(gè)epoch訓(xùn)練完成以后就使用預(yù)測(cè)器來(lái)決定是否需要減少learning rate并重新訓(xùn)練。 Large-scale Evolution方法讓突變的子網(wǎng)絡(luò)盡可能繼承父代網(wǎng)絡(luò),對(duì)于突變的結(jié)構(gòu)變化較大的子網(wǎng)絡(luò)來(lái)說(shuō),就很難繼承父代的參數(shù),就需要強(qiáng)制重新訓(xùn)練。
4.4.1 權(quán)重共享
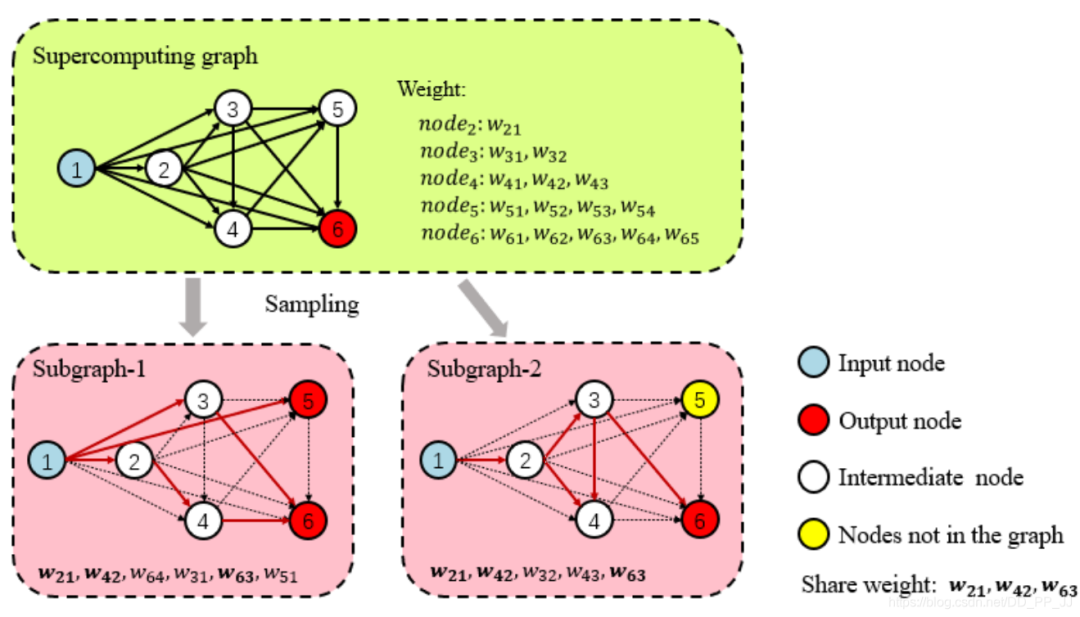
4.4.2 訓(xùn)練至收斂
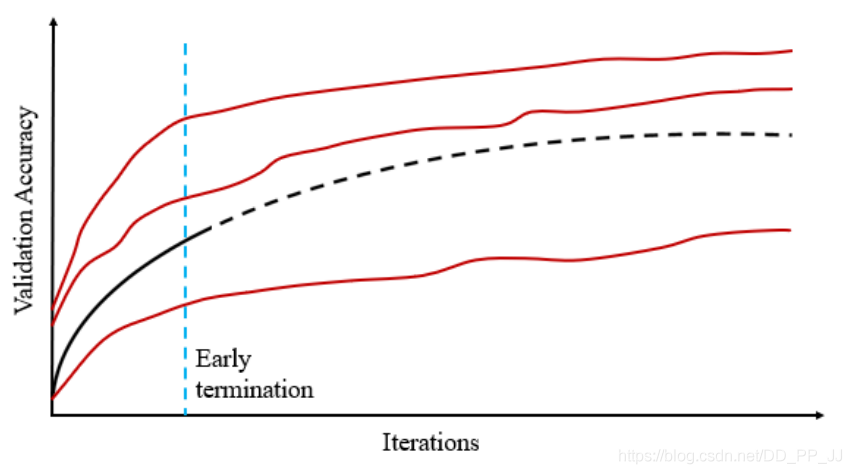
5. 性能對(duì)比
reinforcement learning(RL) evolutionary algorithm(EA) gradient optimization(GO) random search(RS) sequential model-based optimization(SMBO)
缺少baseline(通常隨機(jī)搜索策略會(huì)被認(rèn)為是一個(gè)強(qiáng)有力的baseline) 預(yù)處理、超參數(shù)、搜索空間、trick等不盡相同
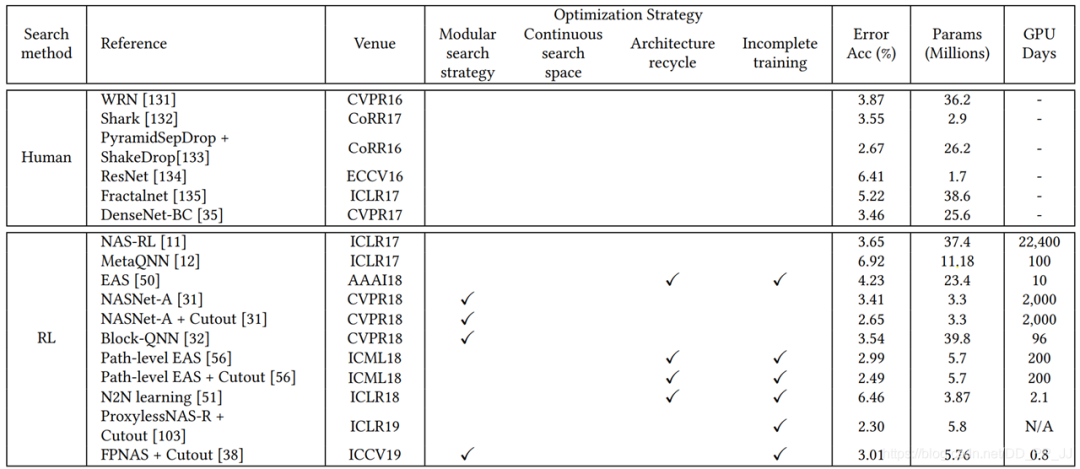
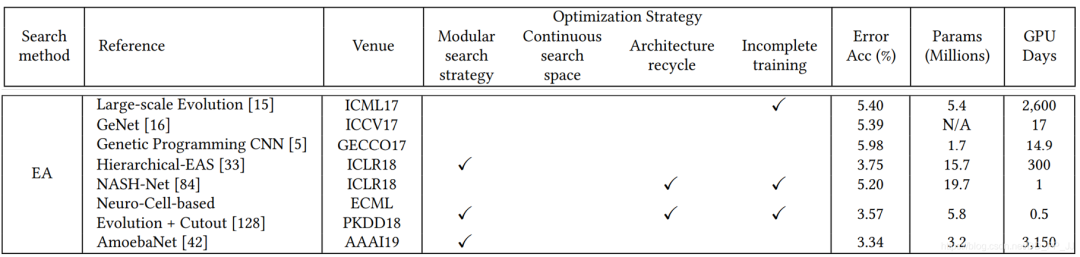
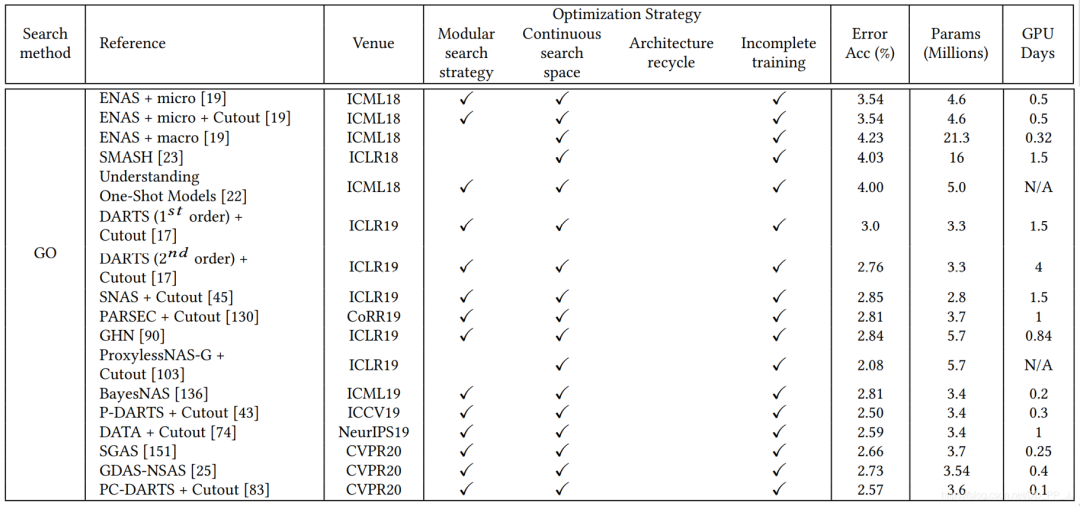
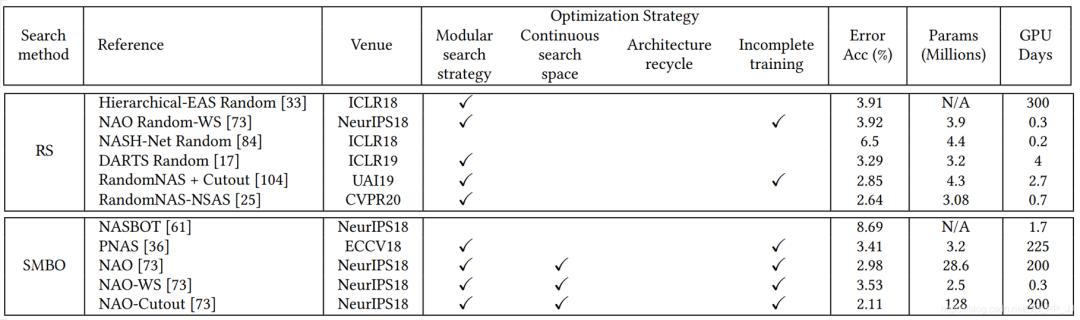
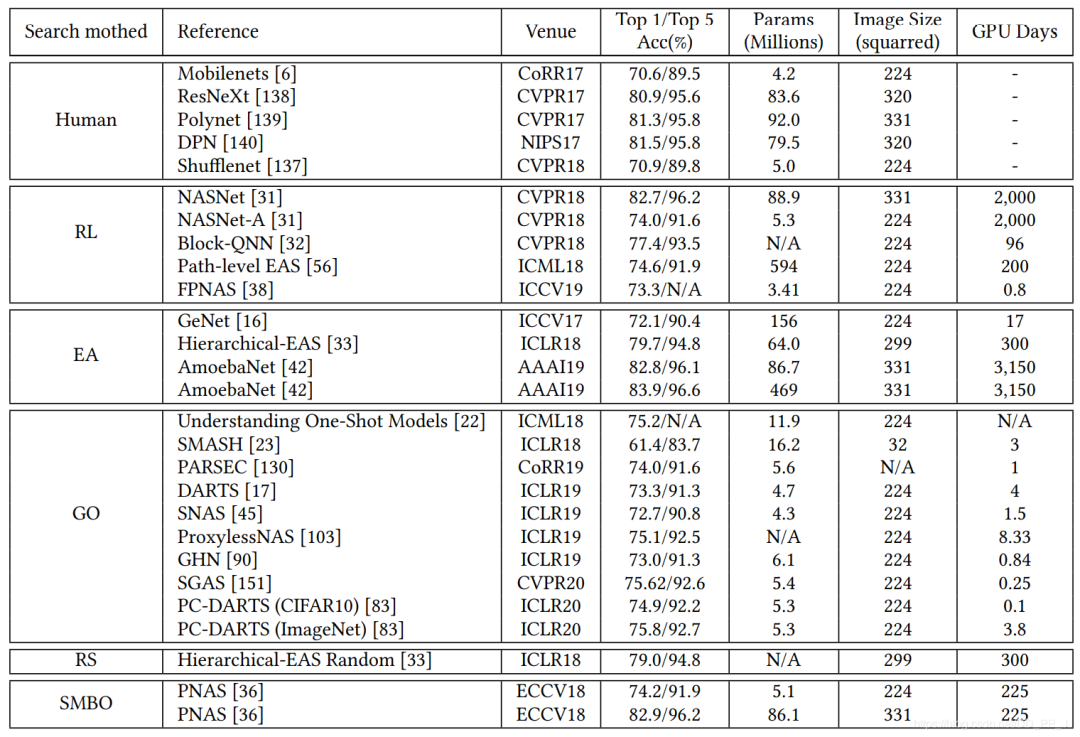
模塊化搜索策略應(yīng)用非常廣泛,因?yàn)榭梢詼p低搜索空間的復(fù)雜度, 但是并沒(méi)有證據(jù)表明模塊化搜索就一定要比全局搜索最終性能要好。 不完全訓(xùn)練策略也是用很多,讓候選網(wǎng)絡(luò)rank的過(guò)程變得非常有效率。 基于梯度的優(yōu)化方法(如DARTS)與其他策略相比,可以減少搜索的代價(jià),有很多工作都是基于DARTS進(jìn)行研究的。 隨機(jī)搜索策略也達(dá)成了非常有競(jìng)爭(zhēng)力的表現(xiàn),但是相對(duì)而言這方面工作比較少。 遷移學(xué)習(xí)的技術(shù)在這里應(yīng)用比較廣泛,先在小數(shù)據(jù)集進(jìn)行搜索(被稱為代理任務(wù)),然后在大的數(shù)據(jù)集上遷移。 ProxyLessNas也研究了如何直接在大型數(shù)據(jù)集上直接進(jìn)行搜索的方法。
6. 未來(lái)的方向
7. 結(jié)語(yǔ)
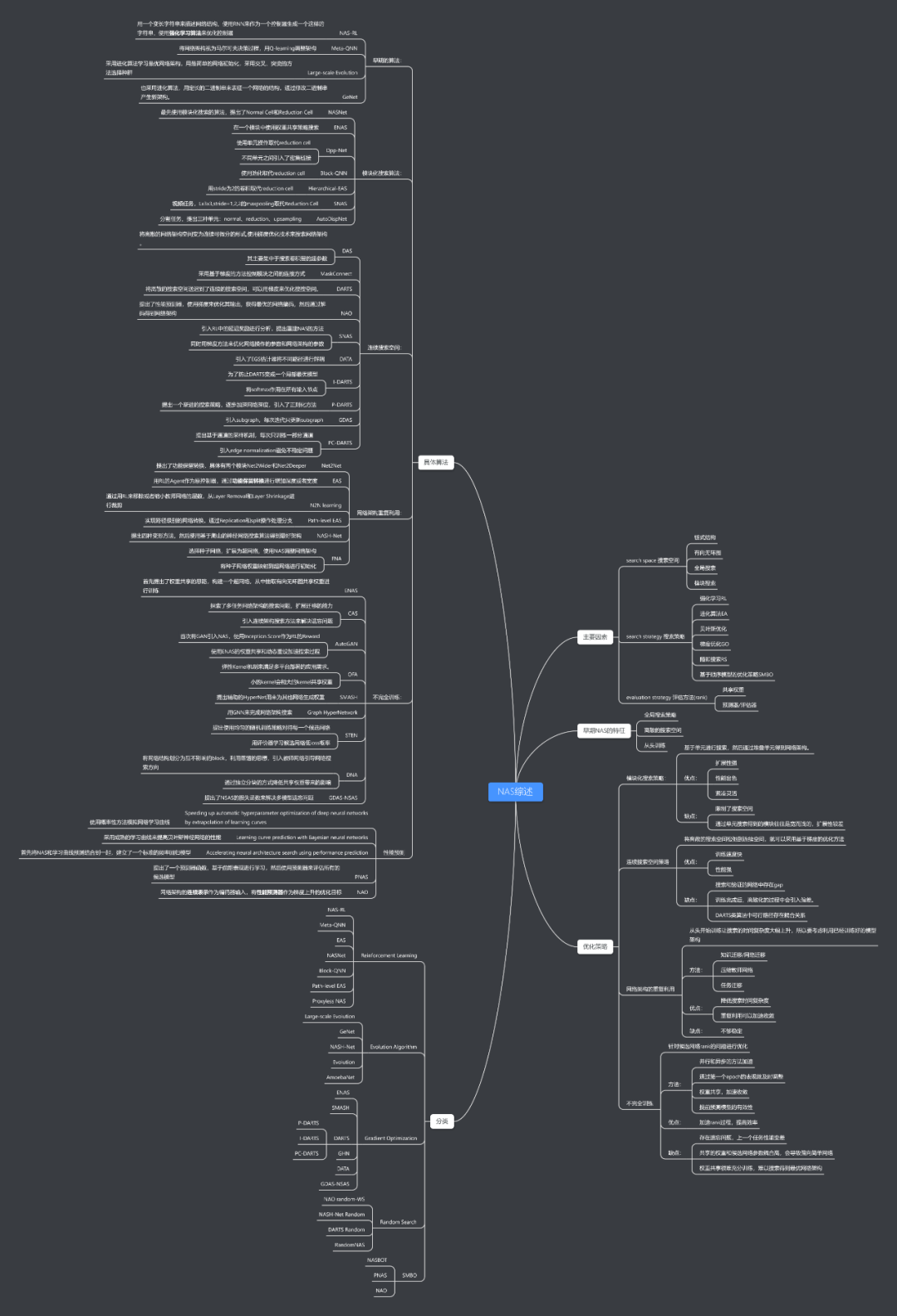
8. 參考文獻(xiàn)
推薦閱讀
NAS: One-Shot方法總結(jié) NAS在目標(biāo)檢測(cè)中的應(yīng)用:6篇相關(guān)論文對(duì)比解讀 神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索(NAS)中的milestones

評(píng)論
圖片
表情