
Iceberg 實(shí)踐 | B站基于 Iceberg 的湖倉一體架構(gòu)實(shí)踐
背景
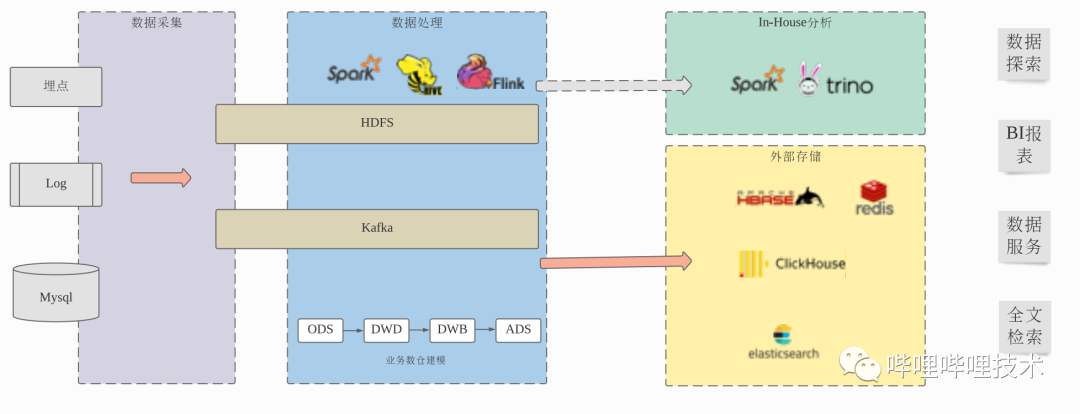
為了提升查詢效率,從Hive表出倉到ClickHouse、HBase、Redis、ElasticSearch、Mysql等外部系統(tǒng)中,需要額外的數(shù)據(jù)開發(fā)工作,額外的存儲(chǔ)冗余,但同時(shí)擁有了更少的數(shù)據(jù)靈活性,復(fù)雜的組件支持增加了數(shù)據(jù)服務(wù)開發(fā)的成本,更長的數(shù)據(jù)處理流程也降低了穩(wěn)定性和可靠性。 對于未出倉的數(shù)據(jù),用戶無論是進(jìn)行數(shù)據(jù)探索還是使用BI報(bào)表,都還受SQL on Hadoop本身性能所限,和用戶期望的交互式響應(yīng)有很大差距。
為什么需要湖倉一體
使用統(tǒng)一的分布式存儲(chǔ)系統(tǒng),可假設(shè)為無限容量。 有統(tǒng)一的元數(shù)據(jù)管理系統(tǒng)。 使用開放的數(shù)據(jù)存儲(chǔ)格式。 使用開放的數(shù)據(jù)處理引擎對數(shù)據(jù)進(jìn)行加工和分析。
自定義的數(shù)據(jù)存儲(chǔ)格式。 自己管理數(shù)據(jù)的組織方式。 強(qiáng)Schema數(shù)據(jù),對外提供標(biāo)準(zhǔn)的SQL接口。 具有高效的計(jì)算存儲(chǔ)一體設(shè)計(jì)和豐富的查詢加速特性。

B站的湖倉一體架構(gòu)
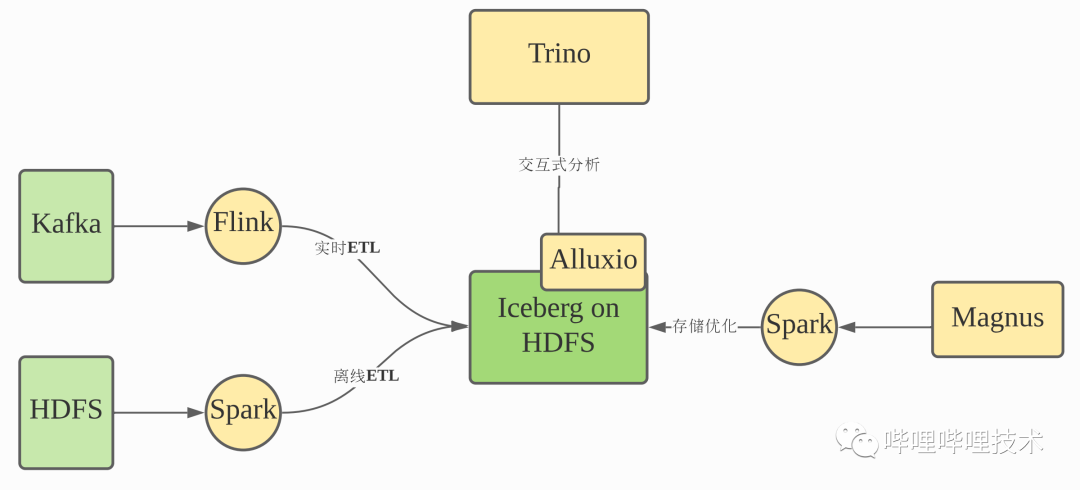
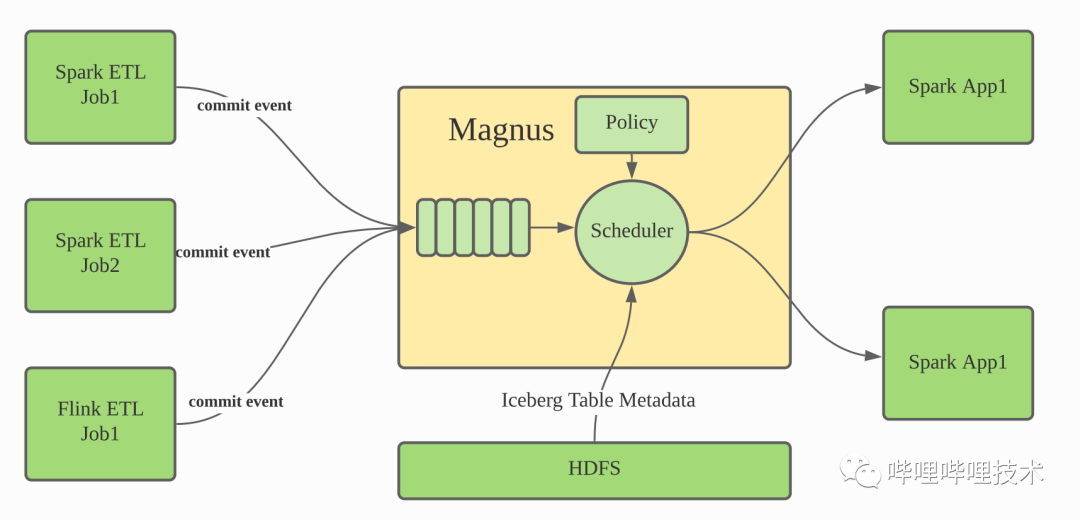
索引
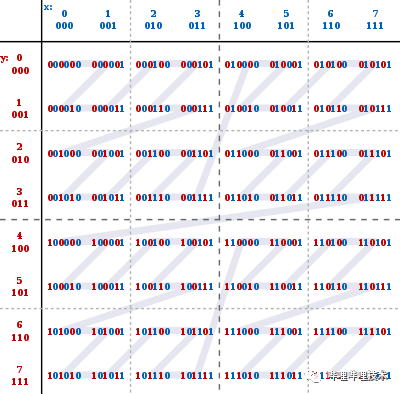
需要存儲(chǔ)字段基數(shù)對應(yīng)個(gè)BitMap,存儲(chǔ)代價(jià)太大。
在Range過濾時(shí),使用BitMap判斷是否可以Skip文件時(shí),需要訪問大量BitMap,讀取代價(jià)太大。
為了解決以上問題,我們引入了Bit-sliced Encoded Bitmap實(shí)現(xiàn)。具體詳情可查詢參考文獻(xiàn)[2](通過索引加速湖倉一體分析)。
總結(jié)和展望
星型模型的數(shù)據(jù)分布組織,支持按照維度表字段對事實(shí)表數(shù)據(jù)進(jìn)行排序組織和索引。 預(yù)計(jì)算,通過預(yù)計(jì)算對固定查詢模式進(jìn)行加速。 智能化,自動(dòng)采集用戶查詢歷史,分析查詢模式,自適應(yīng)調(diào)整數(shù)據(jù)的排序組織和索引等。
評(píng)論
圖片
表情