
Flink + Iceberg 在去哪兒的實(shí)時(shí)數(shù)倉(cāng)實(shí)踐
背景及痛點(diǎn)
Iceberg 架構(gòu)
痛點(diǎn)一:Kafka 數(shù)據(jù)丟失
痛點(diǎn)二:近實(shí)時(shí) Hive 壓力大
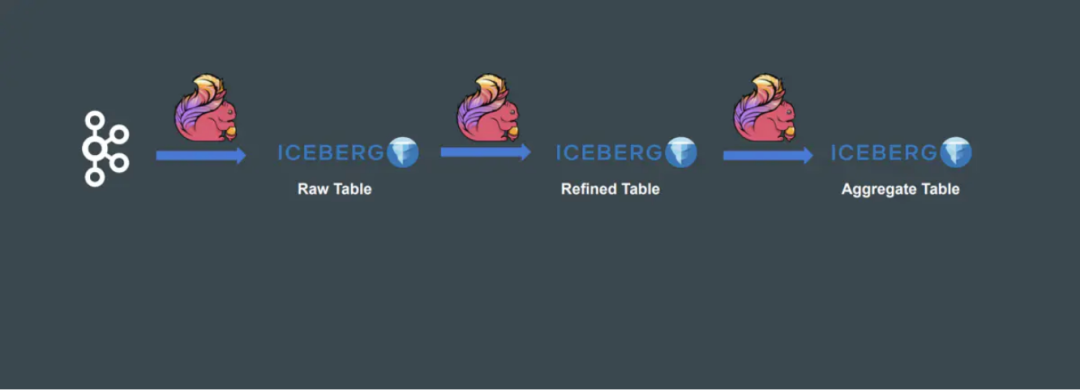
Iceberg 優(yōu)化實(shí)踐
總結(jié)
 GitHub 地址
GitHub 地址 一、背景及痛點(diǎn)
1. 背景
2. 原架構(gòu)方案
3. 痛點(diǎn)
Kafka 存儲(chǔ)成本高且數(shù)據(jù)量大。Kafka 由于壓力大將數(shù)據(jù)過(guò)期時(shí)間設(shè)置的比較短,當(dāng)數(shù)據(jù)產(chǎn)生反壓,積壓等情況時(shí),如果在一定的時(shí)間內(nèi)沒(méi)消費(fèi)數(shù)據(jù)導(dǎo)致數(shù)據(jù)過(guò)期,會(huì)造成數(shù)據(jù)丟失。
Flink 在 Hive 上做了近實(shí)時(shí)的讀寫支持。為了分擔(dān) Kafka 壓力,將一些實(shí)時(shí)性不太高的數(shù)據(jù)放入 Hive,讓 Hive 做分鐘級(jí)的分區(qū)。但是隨著元數(shù)據(jù)不斷增加,Hive metadata 的壓力日益顯著,查詢也變得更慢,且存儲(chǔ) Hive 元數(shù)據(jù)的數(shù)據(jù)庫(kù)壓力也變大。
二、Iceberg 架構(gòu)
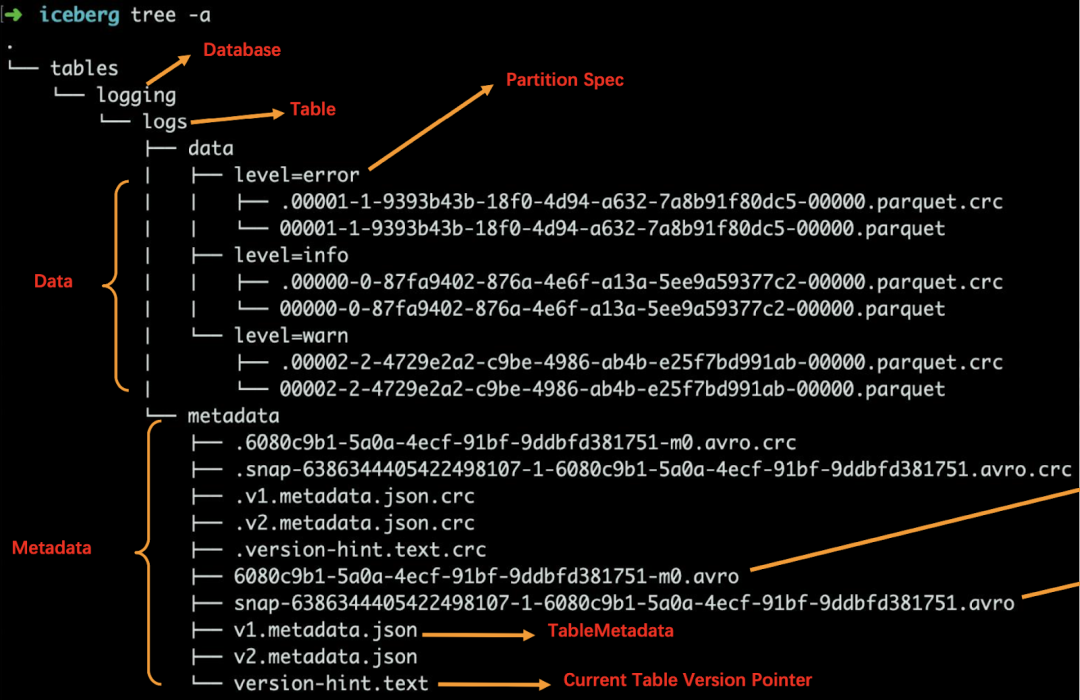
1. Iceberg 架構(gòu)解析

數(shù)據(jù)文件(data files)
Iceberg 表真實(shí)存儲(chǔ)數(shù)據(jù)的文件,一般存儲(chǔ)在 data 目錄下,以 “.parquet” 結(jié)尾。
清單文件(Manifest file)
每行都是每個(gè)數(shù)據(jù)文件的詳細(xì)描述,包括數(shù)據(jù)文件的狀態(tài)、文件路徑、分區(qū)信息、列級(jí)別的統(tǒng)計(jì)信息(比如每列的最大最小值、空值數(shù)等)。通過(guò)該文件,可過(guò)濾掉無(wú)關(guān)數(shù)據(jù),提高檢索速度。
快照(Snapshot)
快照代表一張表在某個(gè)時(shí)刻的狀態(tài)。每個(gè)快照版本包含某個(gè)時(shí)刻的所有數(shù)據(jù)文件列表。Data files 存儲(chǔ)在不同的 manifest files 里面, manifest files 存儲(chǔ)在一個(gè) Manifest list 文件里面,而一個(gè) Manifest list 文件代表一個(gè)快照。
2. Iceberg 查詢計(jì)劃
元數(shù)據(jù)過(guò)濾
清單文件包括分區(qū)數(shù)據(jù)元組和每個(gè)數(shù)據(jù)文件的列級(jí)統(tǒng)計(jì)信息。在計(jì)劃期間,查詢謂詞會(huì)自動(dòng)轉(zhuǎn)換為分區(qū)數(shù)據(jù)上的謂詞,并首先應(yīng)用于過(guò)濾數(shù)據(jù)文件。接下來(lái),使用列級(jí)值計(jì)數(shù),空計(jì)數(shù),下限和上限來(lái)消除與查詢謂詞不匹配的文件。
Snapshot ID
每個(gè) Snapshot ID 會(huì)關(guān)聯(lián)到一組 manifest files,而每一組 manifest files 包含很多 manifest file。
manifest files 文件列表
每個(gè) manifest files 又記錄了當(dāng)前 data 數(shù)據(jù)塊的元數(shù)據(jù)信息,其中就包含了文件列的最大值和最小值,然后根據(jù)這個(gè)元數(shù)據(jù)信息,索引到具體的文件塊,從而更快的查詢到數(shù)據(jù)。
三、痛點(diǎn)一:Kafka 數(shù)據(jù)丟失
1. 痛點(diǎn)介紹
2. 解決方案
3 .為什么 Iceberg 只能做近實(shí)時(shí)入湖?
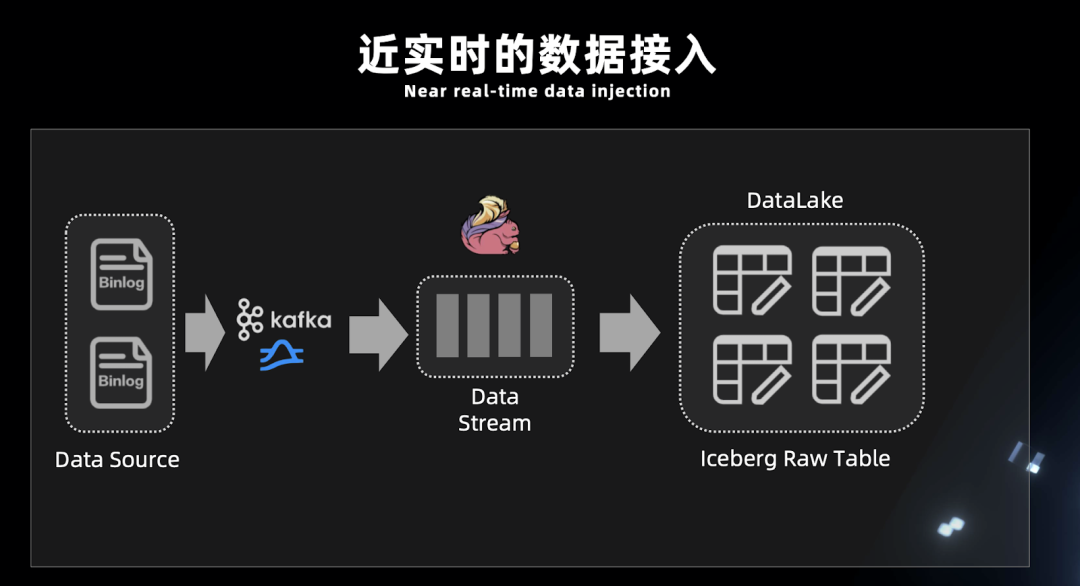
Iceberg 提交 Transaction 時(shí)是以文件粒度來(lái)提交。這就沒(méi)法以秒為單位提交 Transaction,否則會(huì)造成文件數(shù)量膨脹;
沒(méi)有在線服務(wù)節(jié)點(diǎn)。對(duì)于實(shí)時(shí)的高吞吐低延遲寫入,無(wú)法得到純實(shí)時(shí)的響應(yīng);
Flink 寫入以 checkpoint 為單位,物理數(shù)據(jù)寫入 Iceberg 后并不能直接查詢,當(dāng)觸發(fā)了 checkpoint 才會(huì)寫 metadata 文件,這時(shí)數(shù)據(jù)由不可見(jiàn)變?yōu)榭梢?jiàn)。checkpoint 每次執(zhí)行都會(huì)有一定時(shí)間。
4. Flink 入湖分析
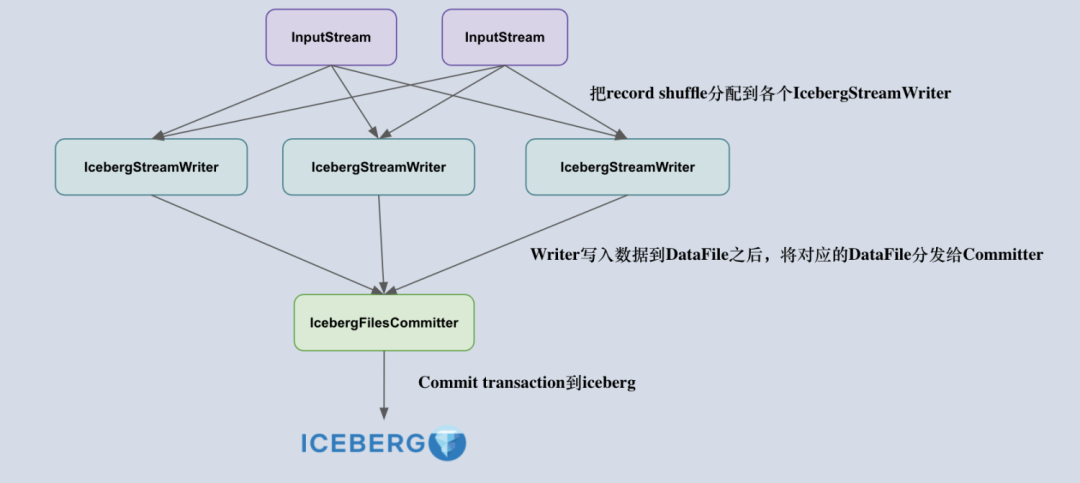
IcebergStreamWriter
主要用來(lái)寫入記錄到對(duì)應(yīng)的 avro、parquet、orc 文件,生成一個(gè)對(duì)應(yīng)的 Iceberg DataFile,并發(fā)送給下游算子。
IcebergFilesCommitter
為每個(gè) checkpointId 維護(hù)了一個(gè) DataFile 文件列表,即 map<Long, List<DataFile>>,這樣即使中間有某個(gè) checkpoint 的 transaction 提交失敗了,它的 DataFile 文件仍然維護(hù)在 State 中,依然可以通過(guò)后續(xù)的 checkpoint 來(lái)提交數(shù)據(jù)到 Iceberg 表中。
5. Flink SQL Demo
■ 5.1 前期工作
開(kāi)啟實(shí)時(shí)讀寫功能
開(kāi)啟 table sql hint 功能來(lái)使用 OPTIONS 屬性
注冊(cè) Iceberg catalog 用于操作 Iceberg 表
CREATE CATALOG Iceberg_catalog WITH (\n" +" 'type'='Iceberg',\n" +" 'catalog-type'='Hive'," +" 'uri'='thrift://localhost:9083'" +");
Kafka 實(shí)時(shí)數(shù)據(jù)入湖
insert into Iceberg_catalog.Iceberg_db.tbl1 \nselect * from Kafka_tbl;
數(shù)據(jù)湖之間實(shí)時(shí)流轉(zhuǎn) tbl1 -> tbl2
insert into Iceberg_catalog.Iceberg_db.tbl2select * from Iceberg_catalog.Iceberg_db.tbl1/*+ OPTIONS('streaming'='true','monitor-interval'='10s',snapshot-id'='3821550127947089987')*/
■ 5.2 參數(shù)解釋
monitor-interval
start-snapshot-id
6. 踩坑記錄
7. 數(shù)據(jù)樣例
一秒前的數(shù)據(jù)

一秒后刷新的數(shù)據(jù)

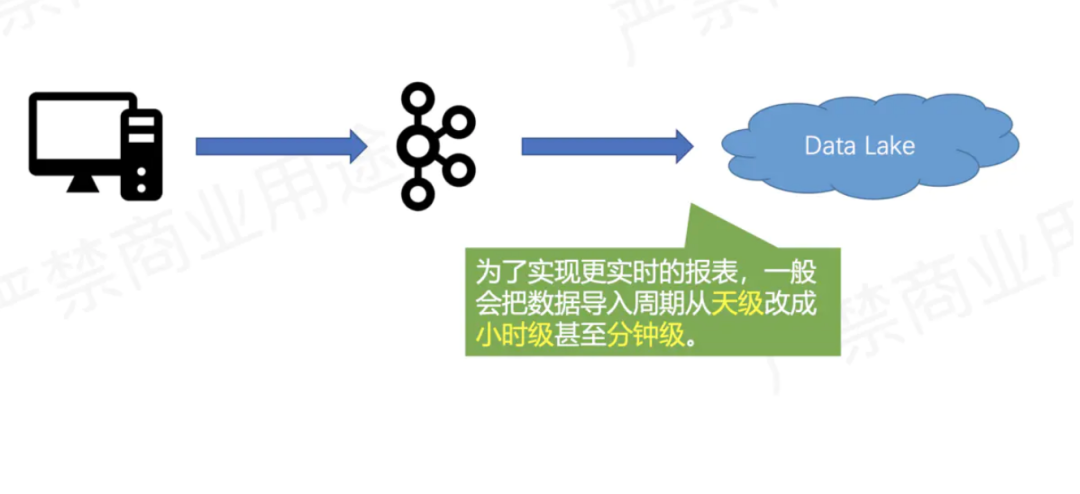
四、痛點(diǎn)二:
Flink 結(jié)合 Hive 的近實(shí)時(shí)越來(lái)越慢
1. 痛點(diǎn)介紹
選用 Flink + Hive 的近實(shí)時(shí)架構(gòu)雖然支持了實(shí)時(shí)讀寫,但是這種架構(gòu)帶來(lái)的問(wèn)題是隨著表和分區(qū)增多,將會(huì)面臨以下問(wèn)題:
元數(shù)據(jù)過(guò)多
Hive 將分區(qū)改為小時(shí) / 分鐘級(jí),雖然提高了數(shù)據(jù)的準(zhǔn)實(shí)時(shí)性,但是 metestore 的壓力也是顯而易見(jiàn)的,元數(shù)據(jù)過(guò)多導(dǎo)致生成查詢計(jì)劃變慢,而且還會(huì)影響線上其他業(yè)務(wù)穩(wěn)定。
數(shù)據(jù)庫(kù)壓力變大
隨著元數(shù)據(jù)增加,存儲(chǔ) Hive 元數(shù)據(jù)的數(shù)據(jù)庫(kù)壓力也會(huì)增加,一段時(shí)間后,還需要對(duì)該庫(kù)進(jìn)行擴(kuò)容,比如存儲(chǔ)空間。

2. 解決方案
將原先的 Hive 近實(shí)時(shí)遷移到 Iceberg。為什么 Iceberg 可以處理元數(shù)據(jù)量大的問(wèn)題,而 Hive 在元數(shù)據(jù)大的時(shí)候卻容易形成瓶頸?
Iceberg 是把 metadata 維護(hù)在可拓展的分布式文件系統(tǒng)上,不存在中心化的元數(shù)據(jù)系統(tǒng);
Hive 則是把 partition 之上的元數(shù)據(jù)維護(hù)在 metastore 里面(partition 過(guò)多則給 mysql 造成巨大壓力),而 partition 內(nèi)的元數(shù)據(jù)其實(shí)是維護(hù)在文件內(nèi)的(啟動(dòng)作業(yè)需要列舉大量文件才能確定文件是否需要被掃描,整個(gè)過(guò)程非常耗時(shí))。
五、優(yōu)化實(shí)踐
1. 小文件處理
Iceberg 0.11 以前,通過(guò)定時(shí)觸發(fā) batch api 進(jìn)行小文件合并,這樣雖然能合并,但是需要維護(hù)一套 Actions 代碼,而且也不是實(shí)時(shí)合并的。
Table table = findTable(options, conf);Actions.forTable(table).rewriteDataFiles().targetSizeInBytes(10 * 1024) // 10KB.execute();
Iceberg 0.11 新特性,支持了流式小文件合并。
CREATE TABLE city_table (province BIGINT,city STRING) PARTITIONED BY (province, city) WITH ('write.distribution-mode'='hash');
2. Iceberg 0.11 排序
■ 2.1 排序介紹

■ 2.2 排序 demo
insert into Iceberg_table select days from Kafka_tbl order by days, province_id;3. Iceberg 排序后 manifest 詳解
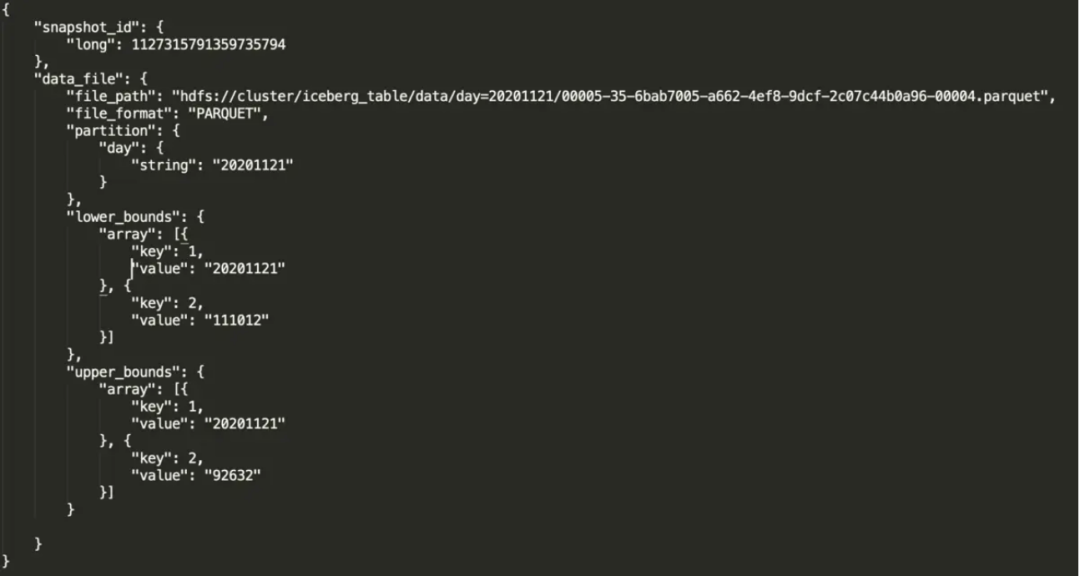
file_path:物理文件位置。
partition:文件所對(duì)應(yīng)的分區(qū)。
lower_bounds:該文件中,多個(gè)排序字段的最小值,下圖是我的 days 和 province_id 最小值。
upper_bounds:該文件中,多個(gè)排序字段的最大值,下圖是我的 days 和 province_id 最大值。
六、總結(jié)
相較于之前的版本來(lái)說(shuō),Iceberg 0.11 新增了許多實(shí)用的功能,對(duì)比了之前使用的舊版本,做以下總結(jié):
Flink + Iceberg 排序功能
實(shí)時(shí)讀取數(shù)據(jù)
實(shí)時(shí)合并小文件