
Ansor論文閱讀筆記&&論文翻譯
這篇文章介紹了Auto-Scheduler的一種方法Ansor,這種方法已經(jīng)被繼承到TVM中和AutoTVM一起來自動生成高性能的張量化程序。
論文鏈接:https://arxiv.org/abs/2006.06762 OSDI 2020 前置知識: 需要了解scheduler,推薦一篇文章:https://zhuanlan.zhihu.com/p/94846767 。 在Ansor論文中主要使用了parallel,cache_read,reorder,unroll,vectorize這些scheduler來描述整個算法,但在Ansor的TVM開源代碼實現(xiàn)中不僅限于這些scheduler,在看Ansor論文之前建議先了解一下。 在AutoTVM和Ansor之前,要生成高性能的張量化程序需要手動指定模板,這些模板不僅需要指定high-level的scheduler,還需要包含low-level的計算邏輯,因為CPU/GPU/ASIC等等芯片底層對張量的計算方式不同。推薦陳天奇的一個對TVM的報告:https://www.bilibili.com/video/BV1vW411R7Zb?from=search&seid=5300327607655608948 。 個人理解 Ansor具體是怎么做到自動生成張量化程序的呢?首先是要做子圖切分,子圖切分的規(guī)則和TVM的算符融合一致,對于每一個子圖主要是通過草圖和注釋來生成對應的程序。 草圖,就是基于上面介紹的那些scheduler和一些推導規(guī)則來做的,推導規(guī)則是什么?比如對于卷積和矩陣乘法這種計算密集型算子,在CPU上Ansor就給它定義了一個tile規(guī)則叫“SSRSRS”,對于矩陣乘法來說"SSRSRS" tile規(guī)則就是將原始的三重for循環(huán)擴展為。這就是論文中Figure5里面的第一個示例。除了這個tile規(guī)則還有還有數(shù)據(jù)復用算子和簡單算子融合,無數(shù)據(jù)復用的簡單算子inline優(yōu)化,數(shù)據(jù)復用算子其輸入需要做計算分窗和輸入的 Cache Read,Cache Write,rfactor等等多種規(guī)則。由于GPU和CPU架構不同,所以定義的規(guī)則也不完全相同,比如矩陣乘法的多級tiling結構就會從“SSRSRS”改為“SSSRRSRS”以匹配 GPU 的架構。tiling中的前三個空間循環(huán)分別綁定到 BlockIdx、虛擬線程(用于減少 bank 沖突)和 ThreadIdx。另外用戶也可以自定義規(guī)則。 注釋,就是在草圖的基礎上,隨機確定GPU thread bind,for 循環(huán)的 unroll、vectorize、parallize,Split 的 factor等等生成完成的代碼。(并行外循環(huán),矢量化和展開內(nèi)循環(huán),這個就對應了GEMM優(yōu)化中的優(yōu)化的關鍵思路)雖然生成了完整的代碼,但這個代碼的性能是由 Evolutionary Search 來保證的。另外,用戶也可以自定義注釋。 然后如何更有效的遍歷搜索空間以及剪枝掉一些無用的搜索空間可以看下原論文的相關介紹。 優(yōu)缺點 由于Ansor具有超大的搜索空間,在一些主流DNN模型和硬件上都能搜索到性能較好的程序。GPU上可以超越TensorRT,CPU上可以超越TensorflowLite,AutoTVM等。 但Ansor的搜索時間相比于TVM的提升并不是非常大,要將ResNet50搜索到超越TensorRT的性能需要多個小時。 可優(yōu)化之處思考 搜索時間如何減少? 子圖劃分的粒度比較細,子圖太多會不會使得優(yōu)化算法陷入局部最優(yōu)? NC4HW4,Winograd等是否可以添加到推導規(guī)則? 論文翻譯 為了更好的理解Ansor,我翻譯了一下論文,歡迎大家勘誤。
Ansor: Generating High-Performance Tensor Programs for Deep Learning
摘要
高性能的張量化程序對于保證深度神經(jīng)網(wǎng)絡的高效執(zhí)行是至關重要的。然而,在各種硬件平臺上為不同的算子都獲得高效的張量化程序是一件充滿挑戰(zhàn)的事。目前深度學習系統(tǒng)依賴硬件廠商提供的內(nèi)核庫或者各種搜索策略來獲得高性能的張量化程序。這些方法要么需要大量的工程工作來開發(fā)特定于平臺的優(yōu)化代碼,要么由于搜索空間受限和無效的探索策略而無法找到高性能的程序。
我們提出了Ansor,一個用于深度學習應用的張量化程序生成框架。與現(xiàn)有的搜索策略相比,Ansor通過從搜索空間的分層表示中采樣程序來探索更多的優(yōu)化組合。然后Ansor使用進化搜索和一個可學習的代價模型對采樣程序進行微調(diào),以確定最佳程序。Ansor可以找到現(xiàn)有SOTA方法的搜索空間之外的高性能程序。此外,Ansor利用scheduler同時優(yōu)化深度神經(jīng)網(wǎng)絡中的多個子圖。實驗表明,相對于Intel CPU,ARM CPU,NVIDIA GPU,Ansor分別將神經(jīng)網(wǎng)絡的執(zhí)行性能提高了3.8倍,2.6倍,和1.7倍。
1. 介紹
深度神經(jīng)網(wǎng)絡(DNN)的低延遲推理在自動駕駛[14],增強現(xiàn)實[3],語言翻譯[15]和其它的AI應用中發(fā)揮著關鍵作用。DNN可以表示為有向無環(huán)圖(DAG),其中節(jié)點表示算子(例如Conv,Matmul),有向邊表示算子之間的依賴關系。現(xiàn)有的深度學習框架(例如TensorFlow,Pytorch,MxNet)將DNN中的算子基于硬件廠商提供的一些高性能內(nèi)核庫(例如,cuDNN,MKL-DNN)來實現(xiàn)以獲得高性能。然而,這些內(nèi)核庫需要大量的工程工作來為每個硬件平臺和每種算子進行手工調(diào)整。為每個目標加速器生成高效的算子實現(xiàn)所需的大量手動工作限制了新算子[7]和專用加速的開發(fā)和創(chuàng)新[35]。
鑒于DNN性能的重要性,研究人員和行業(yè)從業(yè)者已轉向基于搜索的編譯技術[2, 11, 32, 49, 59]來自動生成張量程序,即張量算子的low-level的實現(xiàn)。對于一個算子或者多個算子組成的子圖,用戶使用high-level的聲明性語言定義計算,然后編譯器針對不同的硬件平臺搜索定制的程序。
為了找到高性能的張量化程序,基于搜索的方法有必要探索足夠大的搜索空間來覆蓋所有的張量化程序優(yōu)化策略。然后現(xiàn)有的方法無法捕獲需要有效的優(yōu)化組合,因為它們依賴預定義的手寫模板(例如TVM[12],F(xiàn)lexTensor[59])或者通過評估不完整的程序(例如Halide auto-scheduler)來進行調(diào)整,這會組阻止它們覆蓋全面的搜索空間。它們用來構建搜索空間的規(guī)則也是有限的。
在本文中,我們探索了一種用于生成高性能張量化程序的新搜索策略。它可以自動生成一個大的搜索空間,全面覆蓋各種優(yōu)化策略。因此,它能夠找到現(xiàn)有方法遺漏的高性能程序。
實現(xiàn)這一目標面臨多種調(diào)整。首先,它需要自動構建一個大的搜索空間,以針對給定的計算定義覆蓋盡可能多的張量化程序。其次,我們需要更有效地搜索,而無需在大型的搜索空間中比較不完整的程序,這些程序可能比現(xiàn)有的模板所能覆蓋的范圍大幾個數(shù)量級。最后,在優(yōu)化具有許多子圖的整個 DNN 時,我們應該識別和優(yōu)先考慮對端到端性能至關重要的子圖。
為此,我們設計并實現(xiàn)了Ansor,這是一個自動生成張量化程序的框架。Ansor利用分層表示來覆蓋大的搜索空間。這種表示將high-level的結構和low-level的細節(jié)解耦,從而實現(xiàn)high-level結構的靈活枚舉和low-level細節(jié)的有效采樣。空間是在給定了計算定義后自動構建的,然后Ansor從搜索空間中采樣完整的程序,并使用進化搜索和一個可學習的代價模型對采樣程序進行微調(diào)。為了優(yōu)化具有多個子圖的 DNN 的性能,Ansor 動態(tài)優(yōu)先的處理 DNN 中更有可能提高端到端性能的子圖。
我們在標準的深度學習Benchmark以及基于搜索調(diào)優(yōu)的框架給出的Benchmark上進行了評估。實驗結果表明,Ansor將DNN 在 Intel CPU、ARM CPU 和 NVIDIA GPU 上的執(zhí)行性能分別提高了3.8 倍、2.6倍和1.7倍。對于大多數(shù)計算定義,Ansor找到的最佳程序在現(xiàn)有基于搜索的方法的搜索空間之外。結果還表明,與現(xiàn)有的基于搜索的方法相比,Ansor 搜索更有效,在更短的時間內(nèi)生成了更高性能的程序,盡管它的搜索空間更大。Ansor可以在降低一個數(shù)量級的時間內(nèi)獲得目前SOTA框架(指的應該是類似TVM的可以自動調(diào)優(yōu)的框架)相當?shù)男阅堋4送釧nsor可以自動擴展到新運算符,只需要這個運算符的數(shù)學定義,無需手動編寫模板。
總結一下,這篇論文做出了以下貢獻:
一種為計算圖生成張量程序的大型空間分層搜索機制。 一種基于可學習的代價模型的進化策略,用來微調(diào)張量化程序的性能。 一種基于梯度下降的調(diào)度算法,在優(yōu)化 DNN 的端到端性能時對重要子圖進行優(yōu)先排序。 Ansor 系統(tǒng)的實現(xiàn)和綜合評估表明,上述技術在各種 DNN 和硬件平臺上都優(yōu)于最先進的系統(tǒng)。
2. 背景
深度學習生態(tài)系統(tǒng)正在擁抱快速增長的硬件平臺多樣性,包括CPU,GPU,F(xiàn)PGA和ASICs。為了在這些平臺上部署DNN,DNN使用的算子需要高性能的張量化程序。所需的算子通常包含標準算子(例如matmul,conv2d)和機器學習研究人員發(fā)明的新算子(例如capsule conv2d[23],dilated conv2d[57])的混合。
為了在各種硬件平臺上部署這些算子時都保持良好的性能已經(jīng)引入了多種編譯器技術(例如TVM[11],Halied[41],Tensor Comprehensions[49])。用戶使用high-level的聲明式語言以類似于數(shù)學表示式的形式定義計算,編譯器根據(jù)定義生成優(yōu)化的張量程序。Figure1展示了TVM 張量表達式語言中矩陣乘法的定義,用戶主要需要定義張量的形狀以及如何計算輸出張量中的每個元素。

然而,從high-level定義中自動生成高性能張量程序是極其困難的。根據(jù)目標平臺的架構,編譯器需要在包含各種優(yōu)化方式(例如tile,向量化,并行等等)的極其復雜和龐大的空間中進行搜索。尋找高性能程序需要搜索策略覆蓋一個全面的空間并有效的搜索,我們在本節(jié)中描述了兩種最新且有效的方法,并在第8節(jié)中描述了其他相關工作。
Template-guided search 在模板引導的搜索中,搜索空間由手工模板指定。如Figure2 a所示,編譯器(例如 TVM)要求用戶手動編寫用于計算定義的模板。該模板使用一些可調(diào)參數(shù)(例如,tile size和unrolling factor)定義了張量化程序的結構。然后編譯器為特定的輸入形狀設置和特定的硬件目標搜索這些參數(shù)的最佳值。這種方法在常見的深度學習算子上取得了良好的性能。然而,開發(fā)模板需要大量的工程努力。例如,TVM代碼庫中包含手工模板的代碼已經(jīng)超過了15000行。隨著新算子和新硬件平臺的出現(xiàn),這個數(shù)字還在繼續(xù)增長。此外,開發(fā)高質量的模板需要張量運算符和硬件方面的專業(yè)知識。開發(fā)高質量的模板也需要大量的研究工作 [32, 55, 59]。盡管模板設計很復雜,但手動指定的模板也僅能涵蓋有限的程序結構,因為手動枚舉所有算子的所有優(yōu)化選擇是令人望而卻步的。這種方法通常需要為每個運算符定義一個模板。Flex-Tensor [59] 提出了一個覆蓋多個算子的通用模板,但它的模板仍然是為單算子設計的,它沒有包括涉及多個算子的優(yōu)化(例如,算子融合)。優(yōu)化具有多個算子的計算圖的搜索空間應該包含不同的組合這些算子的方式。基于模板的方法無法實現(xiàn)這一點,因為它無法在搜索過程中分解固定的模板并重新組合它們。
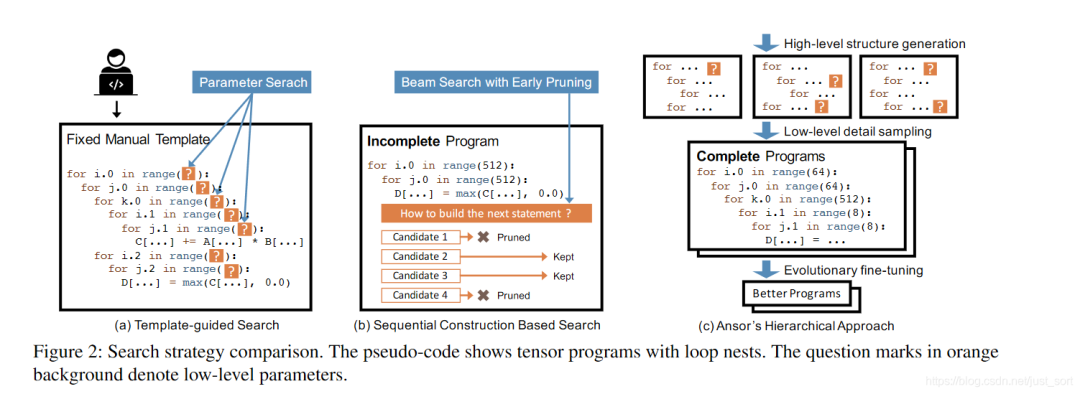
Sequential construction based search. 這種方法通過將程序構造分解為固定的決策序列來定義搜索空間。然后編譯器使用諸如波束搜索 [34] 之類的算法來搜索好的決策(例如,Halide auto-scheduler [2])。在這種方法中,編譯器通過依次unfold計算圖中的所有節(jié)點來構造張量化程序。對于每個節(jié)點,編譯器就如何將其轉換為low-level張量化程序做出一些決策(即決策 computation location、storage location、tile size等)。當所有節(jié)點都unfold后,就構建了一個完整的張量化程序。這種方法對每個節(jié)點使用一組通unfold規(guī)則,因此它可以自動搜索而無需手動模板。由于每個決策的可能選擇數(shù)量很大,為了使sequential過程可行,這種方法在每個決策后只保留前 k 個候選程序。編譯器基于一個可學習的代價模型評估并比較候選程序的性能以選擇前k個候選程序,而其他候選程序被丟棄。在搜索過程中,候選程序是不完整的,因為只有部分計算圖被展開或只做出了一些決策。Figure2 b 顯示了這個過程。
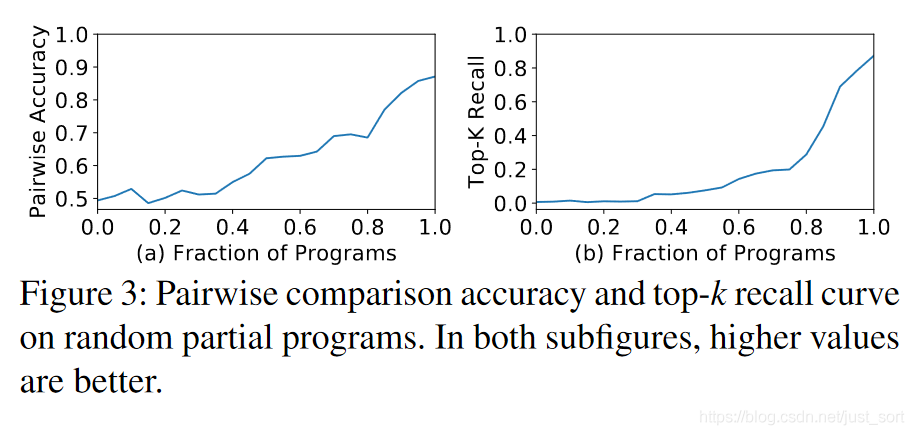
然而,評估不完整程序的最終性能有幾個方面的困難:(1)在完整程序上訓練的代價模型不能準確預測不完整程序的最終性能。代價模型只能在完整的程序上訓練,因為我們需要編譯程序并測量它們的執(zhí)行時間以獲得訓練標簽。直接使用該模型來評估不完整程序的最終性能會導致準確性較差。我們在來自搜索空間的 20,000個隨機完整程序上訓練我們的代價模型作為案例研究(第 5.2 節(jié)),并使用該模型來預測不完整程序的最終性能。不完整的程序是通過只應用完整程序的一小部分循環(huán)變換得到的。我們使用兩個評價指標進行評估:成對比較的準確性和top-k 程序的recall分數(shù)(k=10)。如Figure 3 所示,兩條曲線分別從50%和0% 開始,這意味著零信息的隨機猜測給出了50%的成對比較準確度和0%的top-k召回率。兩條曲線隨著程序的完整度增加而迅速增加,這意味著代價模型對于完整程序的性能非常好,但無法準確預測不完整程序的最終性能。(2) 順序決策的固定順序限制了搜索空間的設計。例如,某些優(yōu)化需要向計算圖中添加新節(jié)點(例如,添加緩存節(jié)點,使用 rfactor[46])。不同程序的決策數(shù)量變得不同。很難將不完整的程序對齊以進行公平比較。(3) 基于sequential構建的搜索不具有可擴展性。擴大搜索空間需要添加更多的序列構建步驟,但這會導致更嚴重的累積誤差。
Ansor’s hierarchical approach 如Figure2-c所示,Ansor基于分層搜索空間構建,該空間將high-level結構和low-level的細節(jié)解耦。Ansor自動構建計算圖的搜索空間空間,不需要手動開發(fā)模板。然后Ansor從空間中采樣完整的程序并對完整的程序進行微調(diào),避免對非完整程序的不準確估計。Figure2展示了Ansor方法與現(xiàn)有方法之間的主要區(qū)別。
3. 設計概述
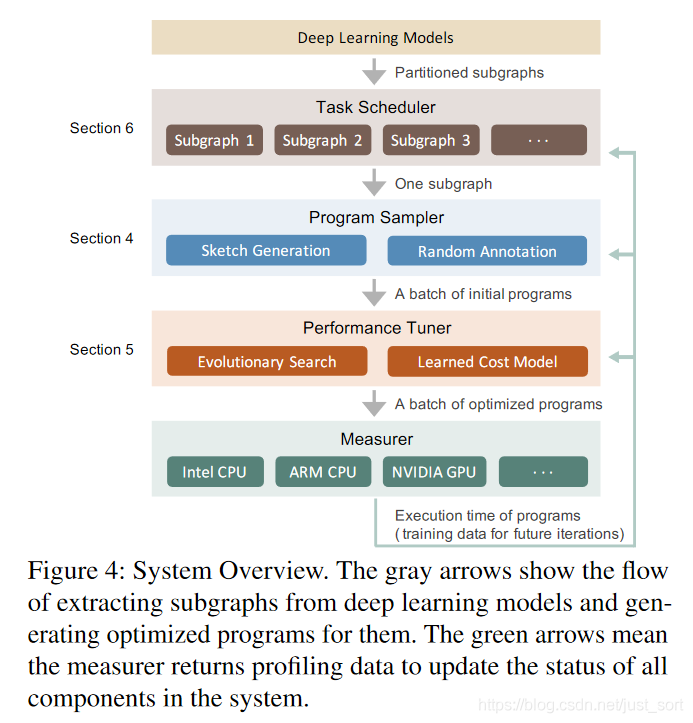
Ansor是一個自動的張量化程序生成框架。Figure 4展示了Ansor的整體架構。Ansor的輸入是一組待優(yōu)化的DNN。Ansor使用Relay[42]的算符融合算法將DNN從流行的模型格式(例如ONNX,TensorFlow PB)轉換為小的子圖,然后Ansor為這些子圖產(chǎn)生張量化程序。Ansor具有三個重要的組件:(1)一個程序采樣器,它構建一個大的搜索空間并從中采樣不同的程序。(2)微調(diào)采樣程序性能的性能調(diào)試器。(3)一個任務調(diào)度器,用于分配時間資源以優(yōu)化 DNN 中的多個子圖。
Program sampler. Ansor 必須解決的一個關鍵挑戰(zhàn)是為給定的計算圖生成一個大的搜索空間。為了覆蓋具有各種high-level結構和low-level細節(jié)的各種張量化程序,Ansor利用具有兩個級別的搜索空間的分層表示:草圖和注釋(第 4 節(jié))。Ansor 將程序的high-level結構定義為草圖,并將數(shù)十億個low-level選擇(例如,tile size、parallel、unroll annotations)作為注釋。這種表示允許Ansor靈活地枚舉high-level結構并有效地采樣low-level細節(jié)。Ansor包含一個程序采樣器,它從空間中隨機采樣程序以提供對搜索空間的全面覆蓋。
Performance tuner. 隨機采樣程序的性能不一定好。下一個挑戰(zhàn)是對它進行微調(diào)、Ansor使用進化搜索和一個可學習的代價模型迭代式微調(diào)(第5節(jié))。在每次迭代中,Ansor使用重新采樣的新程序以及來自先前迭代的性能還不錯的程序作為初始種群執(zhí)行進化搜索。進化搜索通過變異和交叉對程序進行微調(diào),執(zhí)行亂序重寫并解決順序構造的局限性。查詢學習到的代價模型比實際測試快幾個數(shù)量級,因此我們可以在幾秒鐘內(nèi)評估數(shù)千個程序。
Task scheduler. 使用程序采樣器和性能調(diào)試器允許 Ansor 為計算圖找到高性能的張量化程序。直觀地說,將整個DNN視為單個計算圖并為其生成完整的張量化程序可能會實現(xiàn)最佳性能。然而,這是低效的,因為它必須處理搜索空間不必要的指數(shù)爆炸。通常,編譯器將DNN的大型計算圖劃分為幾個小的子圖 [11, 42]。由于 DNN 的逐層構造特性,該劃分對性能的影響可以忽略不計。這帶來了Ansor最終的挑戰(zhàn):在為多個子圖生成程序時如何分配時間資源。Ansor中的任務調(diào)度器(第 6 節(jié))使用基于梯度下降的調(diào)度算法將資源分配給更可能提高端到端DNN性能的子圖。
4. 程序采樣器
算法搜索的搜索空間決定了它可以提找到的最佳程序。現(xiàn)有方法中考慮的搜索空間受以下因素限制:(1)手動計數(shù)(例如TVM)。通過模板手動枚舉所有可能的選擇是不切實際的,因此現(xiàn)有的手工模板只能啟發(fā)式地覆蓋有限的搜索空間。(2)貪心的早期剪枝(例如,Halide Auto-scheduler)。基于評估不完整程序來貪心的剪枝,避免算法搜索空間中的某些區(qū)域。
在本節(jié)中,我們介紹了通過解決上述限制來推動所考慮的搜索空間邊界的技術。為了解決(1),我們遞歸應用一組靈活的推導規(guī)則來自動擴展搜索空間。為了避免(2),我們在搜索空間中隨機采樣完整程序。由于隨機采樣為每個要采樣的點提供了均等的機會,因此我們的搜索算法可以潛在地探索所考慮空間中的每個程序。我們不依賴隨機抽樣來找到最佳程序,因為每個采樣程序后來都經(jīng)過了微調(diào)(第 5 節(jié))。
為了采樣可以覆蓋一個大的搜索空間的程序,我們定義了一個具有兩個級別的分層搜索空間:草圖和注釋。我們將程序的high-level結構定義為草圖,并將數(shù)十億個low-level選擇(例如,tile size、parallel、unroll annoations)作為注釋。在頂層,我們通過遞歸應用一些推導規(guī)則來生成草圖。在底層,我們隨機注釋這些草圖以獲得完整的程序。這種表示從數(shù)十億個低級選擇中總結了一些基本結構,實現(xiàn)了high-level結構的靈活枚舉和low-level細節(jié)的有效采樣。
雖然 Ansor 同時支持CPU和GPU,但我們在4.1和4.2中解釋了CPU的采樣過程作為示例。然后我們在4.3中討論了GPU的過程有何不同 。
4.1 草圖的生成
如Figure4所示,程序采樣器接受一個子圖作為輸入。圖 5 中的第一列展示了輸入的兩個示例。輸入具有三種等價形式:數(shù)學表達式、通過直接展開循環(huán)索引獲得的相應樸素程序以及相應的計算圖(有向無環(huán)圖,或 DAG)。
為了給具有多個節(jié)點的 DAG 生成草圖,我們按拓撲順序訪問所有節(jié)點并迭代構建結構。對于計算密集型且具有大量數(shù)據(jù)重用機會的計算節(jié)點(例如,conv2d、matmul),我們?yōu)樗鼈儤嫿ɑ镜膖ile和fusion結構作為草圖。對于簡單的逐元素節(jié)點(例如 ReLU、逐元素添加),我們可以安全地內(nèi)聯(lián)它們。請注意,新節(jié)點(例如,緩存節(jié)點、布局變換節(jié)點)也可能在草圖生成期間引入 DAG。
我們提出了一種基于推導的枚舉方法,通過遞歸地應用幾個基本規(guī)則來生成所有可能的草圖。這種方法將DAG作為輸入并返回一個草圖的列表。我們定義狀態(tài),其中S是當前為DAG部分生成的草圖,i是當前工作的節(jié)點的索引。DAG中的節(jié)點是從輸出到輸入按照拓撲序進行排列的。推導是從初始的naive程序和最后一個節(jié)點開始,或者說初始狀態(tài)可以寫成=(native程序,最后一個節(jié)點的索引)。然后我們嘗試將所有推導規(guī)則遞歸地應用于狀態(tài)。對于每個規(guī)則,如果當前狀態(tài)滿足應用條件,我們將規(guī)則應用到然后獲得,其中。這樣工作節(jié)點的索引i就會單調(diào)減少,當i變成0的時候狀態(tài)就是終止狀態(tài)。在枚舉過程中,可以將多個規(guī)則應用于一個狀態(tài)以生成多個后續(xù)狀態(tài)。一個規(guī)則也可以產(chǎn)生多個可能的后續(xù)狀態(tài),所以我們維護一個隊列來存儲所有中間狀態(tài)。當隊列為空時,該過程結束。在草圖生成結束時,所有處于終止狀態(tài)的的生成草圖列表。一般來說子圖生成的草圖數(shù)量會小于10。

Derivation rules. Table1列出了我們給CPU使用的推導規(guī)則。這里先聲明一些述語,比如**IsStrictInliable(S, i)**表示子圖S中的節(jié)點i是否是element-wise的OP(比如ReLU,這種OP可以被內(nèi)聯(lián)優(yōu)化,論文說的是inlined)。HasDataReuse(S, i) 表示S中的節(jié)點i是否是計算密集型算子并且是否有大量的算子內(nèi)數(shù)據(jù)重用的機會(例如卷積,矩陣乘法)。HasFusibleConsumer(S, i) 表示是否S中的節(jié)點i只有一個消費者j并且j可以被融合進節(jié)點i(例如matmul+bias_add,conv2d+relu)。HasMoreReductionParallel(S, i) 表示S中的節(jié)點i是否在空間維度上幾乎無法并行但在reduction維度上有足夠的并行機會(例如計算二維矩陣乘法,)。我們對計算定義進行靜態(tài)分析以獲得這些述語的值。分析是通過解析數(shù)學表達式中的讀寫模式自動完成的。接下來,我們介紹每個推導規(guī)則的功能。

規(guī)則1是簡單的跳過一個節(jié)點,如果它不是嚴格內(nèi)聯(lián)的。規(guī)則2是對于嚴格內(nèi)連的節(jié)點總是執(zhí)行內(nèi)聯(lián)操作。由于規(guī)則1和規(guī)則2的條件是互斥的,i>1的狀態(tài)總是可以滿足其中之一并繼續(xù)推導。
規(guī)則 3、4和5處理具有數(shù)據(jù)重用的節(jié)點的多級tiling和fusion。規(guī)則3對數(shù)據(jù)可重用節(jié)點執(zhí)行多級tiling。對于 CPU,我們使用“SSRSRS”tile結構,其中“S”代表空間循環(huán)的一個tile級別,“R”代表reduction循環(huán)的一個tile級別。(關于tile這種scheduler可以看一下我之前的介紹:【從零開始學深度學習編譯器】二,TVM中的scheduler) 。例如對于Figure5中的Example Input1來講,i和j都是空間循環(huán),而k是reduction循環(huán)。對于矩陣乘法來說"SSRSRS" tile結構講原始的三重for循環(huán)擴展為。雖然我們不置換循環(huán)的順序,但這種多級tiling也可以涵蓋一些reorder(上面篇文章也講了reorder)的情況。例如上面的10級循環(huán)可以通過將其它循環(huán)的長度設為1來專門用于簡單的reorder。“SSRSRS” tile結構對于計算密集型OP是通用的(例如, matmul, conv2d, conv3d) 在深度學習中,因為它們都由空間循環(huán)和reduce循環(huán)組成。
規(guī)則 4 執(zhí)行多級tiling并融合可融合的消費者。例如,我們將element-wise節(jié)點(例如 ReLU、bias add)融合到tiling節(jié)點(例如 conv2d、mat-mul)中。如果當前數(shù)據(jù)可重用節(jié)點沒有可融合的消費者,則規(guī)則5將添加一個緩存節(jié)點。例如,DAG 中的最終輸出節(jié)點沒有任何消費者,因此默認情況下它直接將結果寫入主內(nèi)存,并且由于內(nèi)存訪問的高延遲而導致效率低下。通過添加緩存節(jié)點,我們在 DAG 中引入了一個新的可融合的消費者節(jié)點,然后可以應用規(guī)則4將這個新添加的緩存節(jié)點融合到最終的輸出節(jié)點中。緩存節(jié)點融合后,現(xiàn)在最終輸出節(jié)點將其結果寫入緩存塊,當塊中的所有數(shù)據(jù)計算完畢后,緩存塊中的結果將立即寫入主內(nèi)存。
規(guī)則6可以使用 factor[46] 將reduction循環(huán)分解為空間循環(huán)以帶來更多并行性。
Examples Figure5展示了三個產(chǎn)生草圖的例子。草圖與 TVM 中的手工模板不同,因為手工模板指定了high-level的結構和low-level的細節(jié),而草圖僅定義了高級結構。對于示例輸入 1,DAG 中四個節(jié)點的排序順序是 (A,B,C,D)。為了導出 DAG 的草圖,我們從輸出節(jié)點 D(i=4) 開始,并將規(guī)則一一應用于節(jié)點。具體來說,生成的草圖1的推導規(guī)則是:
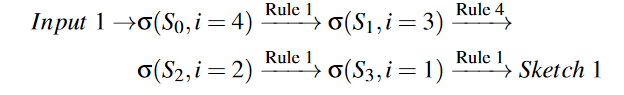
對于示例輸入2,五個節(jié)點的排序順序是 (A,B,C,D,E)。類似地,我們從輸出節(jié)點 E(i=5) 開始并遞歸地應用規(guī)則。生成的草圖 2 如下:
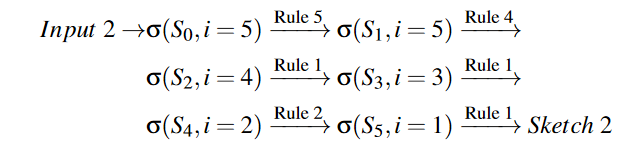
類似地,生成草圖三是由以下規(guī)則順序應用:
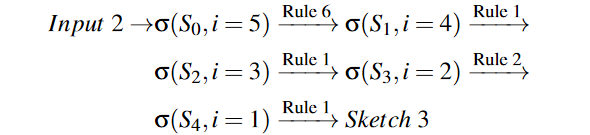
Customization 雖然提出的規(guī)則足夠實用,可以涵蓋大部分算子的結構,但總有例外。例如一些特殊的算法(例如Winograd卷積[30])和加速器內(nèi)部函數(shù)(例如TensorCore[37])需要特殊的tiling結構才會有效。雖然模板推導的搜索方法(TVM)可以為每一個新的案例制作一個新的模板,但它需要大量的設計工作。另一方面,Ansor中基于推導的草圖生成足夠靈活,可以為新興算法和硬件生成所需的結構,因為我們允許用戶注冊新的推導規(guī)則并將它們與現(xiàn)有規(guī)則無縫集成。
4.2 隨機注釋
上一節(jié)生成的草圖是不完整的程序,因為它們只有tiling結構,沒有特定的tiling尺寸和循環(huán)注釋。例如并行,unroll和矢量化。在本節(jié)中,我們對草圖進行注釋,使它們成為用于微調(diào)和評估的完整程序。給定生成的草圖列表,我們隨機選擇一個草圖,隨機填充tile尺寸,并行一些外循環(huán),矢量化一些內(nèi)循環(huán),并unroll一些內(nèi)循環(huán)。我們還隨機改變了程序中一些節(jié)點的計算位置,對tile結構進行了微調(diào)。本小節(jié)中提到的的所有“隨機”表示所有有效值的均勻分布。如果某些算法需要自定義注釋才會有效(例如特殊的unroling),我們允許用戶在計算定義中給出簡單的提示以調(diào)整注釋策略。最后,由于更改常量張量的布局可以在編譯時完成,并且不會帶來運行時開銷,因此我們根據(jù)多級tile結構重寫常量張量的布局使其盡可能的緩存友好。這種優(yōu)化是有效的,因為卷積或者全連接層的權重張量是靜態(tài)張量。
隨機抽樣的例子如Figure5所示,抽樣程序的循環(huán)次數(shù)可能比草圖少,因為長度為1的循環(huán)被簡化了。
4.3 GPU 支持
對于GPU,我們將多級tiling結構從“SSRSRS”改為“SSSRRSRS”以匹配 GPU 的架構。tiling中的前三個空間循環(huán)分別綁定到 BlockIdx、虛擬線程(用于減少 bank 沖突)和 ThreadIdx。我們添加了兩個草圖推導規(guī)則,一個用于通過插入緩存節(jié)點來利用共享內(nèi)存(類似于規(guī)則 5),另一個用于跨線程reduction(類似于規(guī)則 6)。
5. 性能微調(diào)
程序采樣器采樣的程序具有良好的搜索空間覆蓋率,但質量沒有保證。這是因為優(yōu)化選擇,如tiling結構和loop注釋,都是隨機采樣的。在本節(jié)中,我們將介紹通過進化搜索和可學習的代價模型微調(diào)采樣程序性能的性能調(diào)優(yōu)器。
微調(diào)是迭代執(zhí)行的。在每次迭代中,我們首先使用進化搜索根據(jù)學習到的成本模型找到一小批性能還不錯的程序。然后我們在硬件上測量這些程序以獲得實際的執(zhí)行時間花費。最后,從中獲得的分析數(shù)據(jù)用于重新訓練成本模型,使其更加準確。
進化搜索使用隨機抽樣的程序以及上次評估中的高質量程序作為初始種群,并應用變異和交叉來生成下一代。可學習的代價模型用于預測每個程序的性能,在我們的例子中是一個程序的吞吐量。我們執(zhí)行固定數(shù)量的進化搜索,并選擇在搜索過程中的最佳程序。我們利用可學習得代價模型,因為代價模型可以給出相對準確的程序性能估計,同時比實際預測快幾個數(shù)量級,它使我們能夠在幾秒鐘內(nèi)比較搜索空間鐘數(shù)以萬計的程序,并挑選出還不錯的程序進行實際評估。
5.1 進化搜索
進化搜索 [54] 是一種受生物進化啟發(fā)的通用元啟發(fā)式算法。通過對高質量程序進行迭代變異,我們可以生成具有潛在更高質量的新程序。進化從采樣的初始代開始。為了產(chǎn)生下一代,我們首先根據(jù)一定的概率從當前一代中選擇一些程序。選擇程序的概率與可學習的代價模型(第 5.2 節(jié))預測的適應度成正比,這意味著具有更高性能的程序被選擇的概率更高。對于選定的程序,我們隨機應用其中一個進化操作來生成一個新程序。 基本上,對于我們在采樣過程中做出的決策(§4.2),我們都設計了相應的進化操作來重寫和微調(diào)它們。
Tile size mutation 此操作掃描程序并隨機選擇一個tiled循環(huán)。對于這個tiled循環(huán),它將隨機選擇一個循環(huán)將其長度隨機除以一個數(shù),并將這個數(shù)乘到另外一個循環(huán)上。由于此操作使tile 尺寸的乘積等于原始循環(huán)長度,因此變異程序始終有效。
Parallel mutation. 此操作掃描程序并隨機選擇一個已用并行注釋的循環(huán)。對于此循環(huán),此操作通過融合其相鄰循環(huán)或者通過一個factor分解此循環(huán)來改變并行的粒度。
Pragma mutation. 程序中的某些優(yōu)化由特定于編譯器的編譯pragma指定。此操作掃描程序并隨機選擇一個編譯pragma。對于這個 pragma,這個操作會隨機將其變異為另一個有效值。例如,我們的底層代碼生成器通過提供一個auto_unroll_max_step=N pragma 來支持最大步數(shù)的自動展開。我們隨機調(diào)整數(shù)字 N。
Computation location mutation. 該操作掃描程序并隨機選擇一個不是多級tiled的靈活節(jié)點(例如,卷積層中的填充節(jié)點)。對于這個節(jié)點,操作隨機改變它的計算位置到另一個有效的節(jié)點。(這里個人理解就是Pad可以提前做,不改變Feature Map大小)
Node-based crossover. 交叉是通過組合來自兩個或多個父母的基因來產(chǎn)生新后代的操作。Ansor 中程序的基因是它的重寫步驟。Ansor 生成的每個程序都是從最初的簡單實現(xiàn)中重寫的。Ansor 在草圖生成和隨機注釋期間為每個程序保留完整的重寫歷史。我們可以將重寫步驟視為程序的基因,因為它們描述了這個程序是如何從最初的樸素程序形成的。在此基礎上,我們可以通過結合兩個現(xiàn)有程序的重寫步驟來生成一個新程序。但是,任意組合兩個程序的重寫步驟可能會破壞步驟中的依賴關系并創(chuàng)建無效程序。因此,Ansor 中交叉操作的粒度基于 DAG 中的節(jié)點,因為跨不同節(jié)點的重寫步驟通常具有較少的依賴性。Ansor 為每個節(jié)點隨機選擇一個父節(jié)點,并合并所選節(jié)點的重寫步驟。當節(jié)點之間存在依賴關系時,Ansor 會嘗試通過簡單的啟發(fā)式方法來分析和調(diào)整步驟。Ansor 進一步驗證合并的程序以保證功能的正確性。驗證很簡單,因為 Ansor 只使用了一小部分循環(huán)轉換重寫步驟,底層代碼生成器可以通過依賴分析來檢查正確性。
進化搜索利用變異和交叉來重復生成一組新的候選集,并輸出一小組具有最高分數(shù)的程序。這些程序將在目標硬件上進行編譯和測試,以獲得真實的運行時間花費。然后使用收集到的測量數(shù)據(jù)更新代價模型。通過這種方式,可學習代價模型的準確性逐漸提高以匹配目標硬件。因此,進化搜索逐漸為目標硬件平臺生成更高質量的程序。
與 TVM 和 FlexTensor 中的搜索算法只能在固定的類網(wǎng)格參數(shù)空間中工作不同,Ansor 中的進化操作是專門為張量化程序設計的。它們可以應用于一般的張量化程序,可以處理依賴復雜的搜索空間。與Halide auto-scheduler中的unfold規(guī)則不同,這些操作可以對程序進行亂序修改,解決順序限制。
5.2 可學習的代價模型
代價模型對于在搜索過程中快速估計程序的性能是必要的。我們采用類似于相關工作[2, 12]的可學習的代價模型,具有新設計的程序特征。基于可學習的代價模型的系統(tǒng)具有很大的可移植性,因為單個模型設計可以通過輸入不同的訓練數(shù)據(jù)來重用于不同的硬件后端。
由于我們的目標程序主要是數(shù)據(jù)并行張量化程序,它們由多個交錯循環(huán)嵌套構成,最里面的語句是幾個賦值語句,我們訓練代價模型來預測循環(huán)中最里面的一個非循環(huán)語句的得分。對于一個完整的程序,我們對最里面的每個非循環(huán)語句進行預測,并將這些預測值加起來作為分數(shù)。我們通過在完整程序的上下文中提取特征來為最內(nèi)層的非循環(huán)語句構建特征向量。提取的特征包括算術特征和內(nèi)存訪問特征。提取特征的詳細列表在附錄 B 中。
我們使用加權平方誤差作為損失函數(shù)。因為我們最關心的是從搜索空間中識別出性能良好的程序,所以我們更加重視運行速度更快的程序。具體來說,模型f在程序P上吞吐量為y的的損失函數(shù)為:
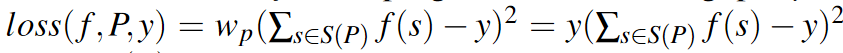
其中S(P)是P中最內(nèi)層非循環(huán)語句的集合。我們直接使用吞吐量作為權重,來訓練一個梯度提升決策樹 [9] 作為底層模型f。為所有的DAG的所有張量化程序訓練一個模型,我們將來自同一個DAG的所有程序的吞吐量歸一化到[0, 1]范圍內(nèi)。在優(yōu)化DNN時,測試的程序的數(shù)量通常少于30000。在如此小的數(shù)據(jù)集上訓練梯度提示決策樹非常快,因此我們每次都訓練一個新模型而不是進行增量更新。
6. Schedule Task
這部分OpenMMLAB的文章已經(jīng)講的比較清楚了,就不翻譯了,這里直接引用一下:
引用自OpenMMLAB https://zhuanlan.zhihu.com/p/360041136
ANSOR 首先會將計算圖切分成多個子圖并對這些子圖分別進行優(yōu)化。深度學習網(wǎng)絡的總優(yōu)化次數(shù)由 ANSOR 的使用者給定,然后由 Schedule Task 模塊來確定如何將這些優(yōu)化次數(shù)分配到不同的子圖優(yōu)化任務上。
為了保證對熱點子圖的重點優(yōu)化,ANSOR 會盡量選擇優(yōu)化效果明顯的子圖進行優(yōu)化。比如最小化一個 DNN 網(wǎng)絡的時延,我們首先給出優(yōu)化的目標函數(shù):

7. 評估
這里簡單介紹一下Ansor的表現(xiàn),基于論文中的圖表。
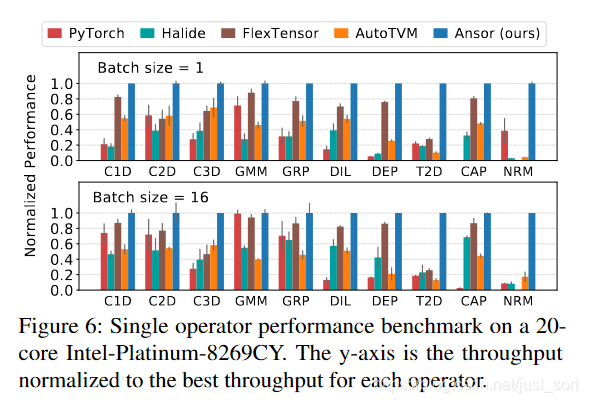
在Figure6中可以看到,在不同的算子和BatchSize設置下,Ansor均取得了最優(yōu)的性能,Ansor的搜索空間很大是取得性能提示的關鍵因素。
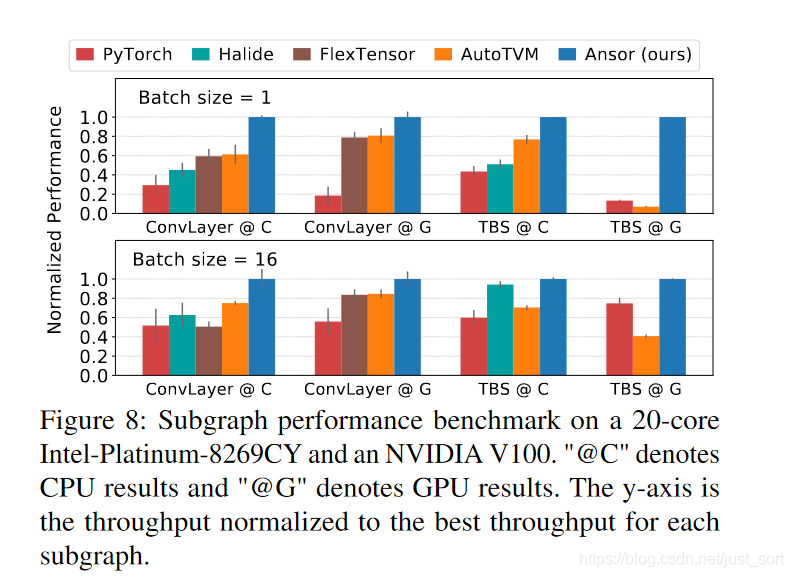
這里ConvLayer是包含Conv+BN+ReLU的子圖,而TBS是包含兩個矩陣轉置,一個Batch矩陣乘和一個Softmax的子圖。@C表示CPU的測試結果,@G表示GPU的測試結果。可以看到無論是在CPU還是GPU上,對于這些常見子圖的優(yōu)化,Ansor全面領先。
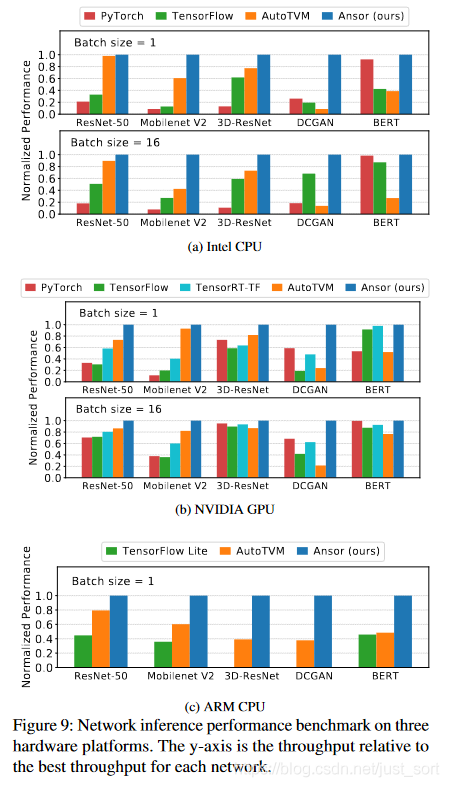
Figure9則展示了一些流行的DNN模型在Intel CPU、Arm CPU以及NVIDIA GPU上的性能測試結果,和業(yè)界的主流加速庫相比,Ansor也取得較大幅度的性能領先。
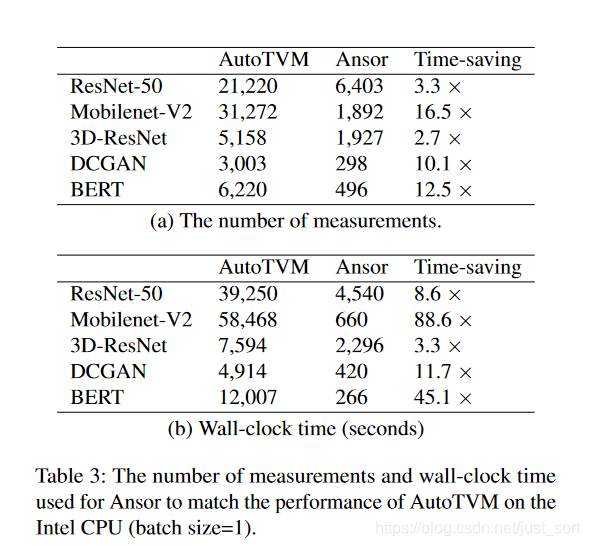
最后相信大家還比較關注的一組數(shù)據(jù)是Ansor的搜索時間。從Tabel3中可以看出在流行的DNN模型上,Ansor的搜索時間相對于Auto TVM都有提升,即使Ansor的搜索空間更大。
8. 相關工作
略,感興趣可以看下原論文。
9. 現(xiàn)在和將來的工作
略,感興趣可以看下原論文。
10. 結論
我們提出了 Ansor,這是一種自動搜索框架,可為深度神經(jīng)網(wǎng)絡生成高性能的張量化程序。通過有效探索大型搜索空間并優(yōu)先考慮性能瓶頸,Ansor 找到了現(xiàn)有方法搜索空間之外的高性能程序。Ansor 在各種神經(jīng)網(wǎng)絡和硬件平臺上的性能優(yōu)于現(xiàn)有的手工庫和基于搜索的框架高達3.8倍。通過自動搜索更好的程序,我們希望 Ansor將幫助縮小不斷增長的計算能力需求與有限的硬件性能之間的差距。Ansor已集成到 Apache TVM 開源項目中。