
高性能短鏈設(shè)計(jì)

源?/?? ? ? ??文/
前言
今天,我們來談?wù)勅绾卧O(shè)計(jì)一個(gè)高性能短鏈系統(tǒng),短鏈系統(tǒng)設(shè)計(jì)看起來很簡(jiǎn)單,但每個(gè)點(diǎn)都能展開很多知識(shí)點(diǎn),也是在面試中非常適合考察侯選人的一道設(shè)計(jì)題,本文將會(huì)結(jié)合我們生產(chǎn)上穩(wěn)定運(yùn)行兩年之久的高性能短鏈系統(tǒng)給大家簡(jiǎn)單介紹下設(shè)計(jì)這套系統(tǒng)所涉及的一些思路,希望對(duì)大家能有一些幫助。
本文將會(huì)從以下幾個(gè)方面來講解,每個(gè)點(diǎn)包含的信息量都不少,相信大家看完肯定有收獲
短鏈有啥好處,用長(zhǎng)鏈不香嗎 短鏈跳轉(zhuǎn)的基本原理 短鏈生成的幾種方法 高性能短鏈的架構(gòu)設(shè)計(jì)
注:里面涉及到不少布隆過濾器,snowflake 等技術(shù),由于不是本文重點(diǎn),所以建議大家看完后再自己去深入了解,不然展開講篇幅會(huì)很長(zhǎng)
短鏈有啥好處,用長(zhǎng)鏈不香嗎
來看下以下公司發(fā)我的營銷短信,點(diǎn)擊下方藍(lán)色的鏈接(短鏈)

瀏覽器的地址欄上最終會(huì)顯示一條如下的長(zhǎng)鏈。

那么為啥要用短鏈表示,直接用長(zhǎng)鏈不行嗎,用短鏈的話有如下好外
1、鏈接變短,在對(duì)內(nèi)容長(zhǎng)度有限制的平臺(tái)發(fā)文,可編輯的文字就變多了
最典型的就是微博,限定了只能發(fā) 140 個(gè)字,如果一串長(zhǎng)鏈直接懟上去,其他可編輯的內(nèi)容就所剩無幾了,用短鏈的話,鏈接長(zhǎng)度大大減少,自然可編輯的文字多了不少。
再比如一般短信發(fā)文有長(zhǎng)度限度,如果用長(zhǎng)鏈,一條短信很可能要拆分成兩三條發(fā),本來一條一毛的短信費(fèi)變成了兩三毛,何苦呢。另外用短鏈在內(nèi)容排版上也更美觀。
2、我們經(jīng)常需要將鏈接轉(zhuǎn)成二維碼的形式分享給他人,如果是長(zhǎng)鏈的話二維碼密集難識(shí)別,短鏈就不存在這個(gè)問題了,如圖示
3、鏈接太長(zhǎng)在有些平臺(tái)上無法自動(dòng)識(shí)別為超鏈接
如圖示,在釘釘上,就無法識(shí)別如下長(zhǎng)鏈接,只能識(shí)別部分,用短地址無此問題

短鏈跳轉(zhuǎn)的基本原理
從上文可知,短鏈好處多多,那么它是如何工作的呢。我們?cè)跒g覽器抓下包看看
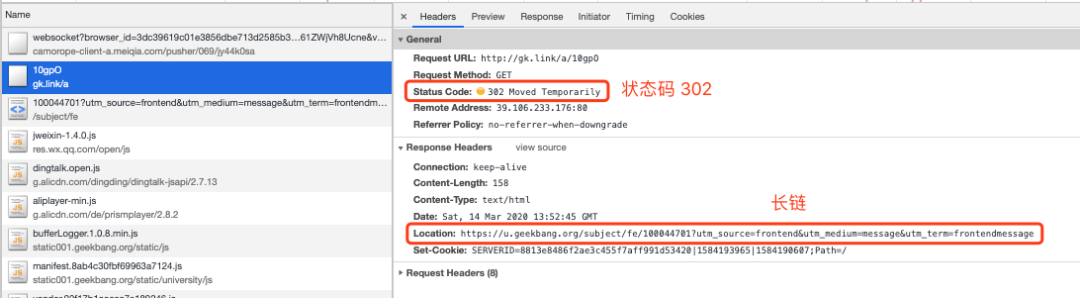
可以看到請(qǐng)求后,返回了狀態(tài)碼 302(重定向)與 location 值為長(zhǎng)鏈的響應(yīng),然后瀏覽器會(huì)再請(qǐng)求這個(gè)長(zhǎng)鏈以得到最終的響應(yīng),整個(gè)交互流程圖如下
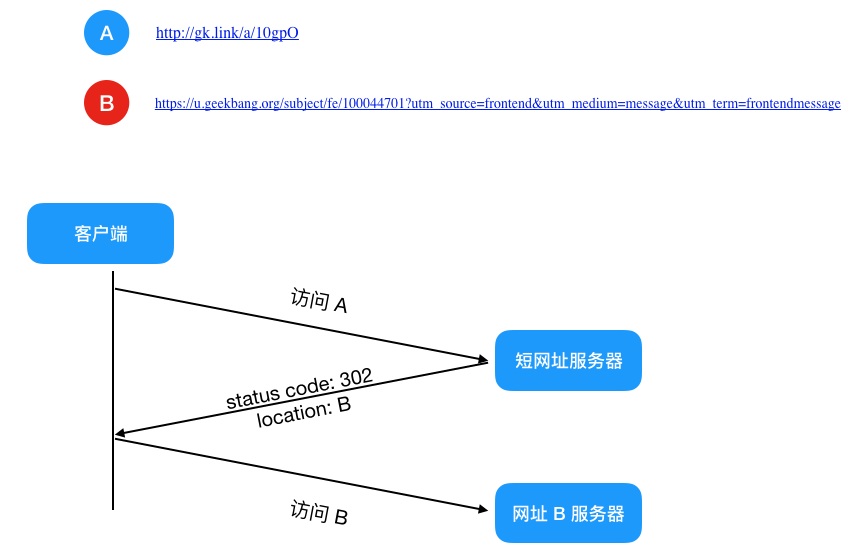
主要步驟就是訪問短網(wǎng)址后重定向訪問 B,那么問題來了,301 和 302 都是重定向,到底該用哪個(gè),這里需要注意一下 301 和 302 的區(qū)別
301,代表?永久重定向,也就是說第一次請(qǐng)求拿到長(zhǎng)鏈接后,下次瀏覽器再去請(qǐng)求短鏈的話,不會(huì)向短網(wǎng)址服務(wù)器請(qǐng)求了,而是直接從瀏覽器的緩存里拿,這樣在 server 層面就無法獲取到短網(wǎng)址的點(diǎn)擊數(shù)了,如果這個(gè)鏈接剛好是某個(gè)活動(dòng)的鏈接,也就無法分析此活動(dòng)的效果。所以我們一般不采用 301。 302,代表?臨時(shí)重定向,也就是說每次去請(qǐng)求短鏈都會(huì)去請(qǐng)求短網(wǎng)址服務(wù)器(除非響應(yīng)中用 Cache-Control 或 Expired 暗示瀏覽器緩存),這樣就便于 server 統(tǒng)計(jì)點(diǎn)擊數(shù),所以雖然用 302 會(huì)給 server 增加一點(diǎn)壓力,但在數(shù)據(jù)異常重要的今天,這點(diǎn)代碼是值得的,所以推薦使用 302!
短鏈生成的幾種方法
1、哈希算法
怎樣才能生成短鏈,仔細(xì)觀察上例中的短鏈,顯然它是由固定短鏈域名 + 長(zhǎng)鏈映射成的一串字母組成,那么長(zhǎng)鏈怎么才能映射成一串字母呢,哈希函數(shù)不就用來干這事的嗎,于是我們有了以下設(shè)計(jì)思路
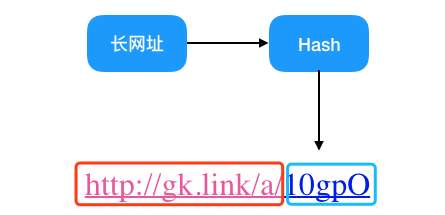
那么這個(gè)哈希函數(shù)該怎么取呢,相信肯定有很多人說用 MD5,SHA 等算法,其實(shí)這樣做有點(diǎn)殺雞用牛刀了,而且既然是加密就意味著性能上會(huì)有損失,我們其實(shí)不關(guān)心反向解密的難度,反而更關(guān)心的是哈希的運(yùn)算速度和沖突概率。
能夠滿足這樣的哈希算法有很多,這里推薦 Google 出品的 MurmurHash 算法,MurmurHash 是一種非加密型哈希函數(shù),適用于一般的哈希檢索操作。與其它流行的哈希函數(shù)相比,對(duì)于規(guī)律性較強(qiáng)的 key,MurmurHash 的隨機(jī)分布特征表現(xiàn)更良好。非加密意味著著相比 MD5,SHA 這些函數(shù)它的性能肯定更高(實(shí)際上性能是 MD5 等加密算法的十倍以上),也正是由于它的這些優(yōu)點(diǎn),所以雖然它出現(xiàn)于 2008,但目前已經(jīng)廣泛應(yīng)用到 Redis、MemCache、Cassandra、HBase、Lucene 等眾多著名的軟件中。
畫外音:這里有個(gè)小插曲,MurmurHash 成名后,作者拿到了 Google 的 offer,所以多做些開源的項(xiàng)目,說不定成名后你也能不經(jīng)意間收到 Google 的 offer ^_^。
MurmurHash 提供了兩種長(zhǎng)度的哈希值,32 bit,128 bit,為了讓網(wǎng)址盡可通地短,我們選擇 32 bit 的哈希值,32 bit 能表示的最大值近 43 億,對(duì)于中小型公司的業(yè)務(wù)而言綽綽有余。對(duì)上文提到的極客長(zhǎng)鏈做 MurmurHash 計(jì)算,得到的哈希值為 3002604296,于是我們現(xiàn)在得到的短鏈為 固定短鏈域名+哈希值 = http://gk.link/a/3002604296
如何縮短域名?
有人說人這個(gè)域名還是有點(diǎn)長(zhǎng),還有一招,3002604296 得到的這個(gè)哈希值是十進(jìn)制的,那我們把它轉(zhuǎn)為 62 進(jìn)制可縮短它的長(zhǎng)度,10 進(jìn)制轉(zhuǎn) 62 進(jìn)制如下:
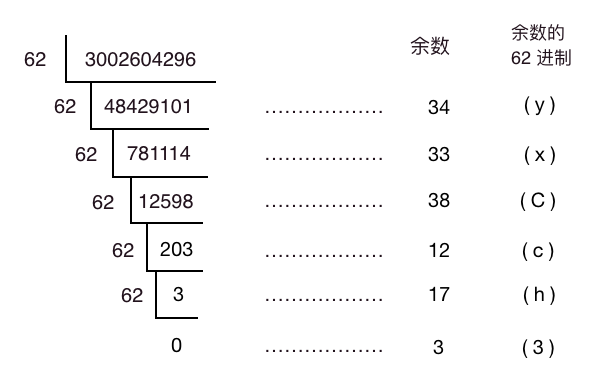
于是我們有 (3002604296)10?= (3hcCxy)10,一下從 10 位縮短到了 6 位!于是現(xiàn)在得到了我們的短鏈為 http://gk.link/a/3hcCxy
畫外音:6 位 62 進(jìn)制數(shù)可表示 568 億的數(shù),應(yīng)付長(zhǎng)鏈轉(zhuǎn)換綽綽有余
如何解決哈希沖突的問題?
既然是哈希函數(shù),不可避免地會(huì)產(chǎn)生哈希沖突(盡管概率很低),該怎么解決呢。
我們知道既然訪問訪問短鏈能跳轉(zhuǎn)到長(zhǎng)鏈,那么兩者之前這種映射關(guān)系一定是要保存起來的,可以用 Redis 或 Mysql 等,這里我們選擇用 Mysql 來存儲(chǔ)。表結(jié)構(gòu)應(yīng)該如下所示
CREATE TABLE `short_url_map` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`lurl` varchar(160) DEFAULT NULL COMMENT '長(zhǎng)地址',
`surl` varchar(10) DEFAULT NULL COMMENT '短地址',
`gmt_create` int(11) DEFAULT NULL COMMENT '創(chuàng)建時(shí)間',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
于是我們有了以下設(shè)計(jì)思路。
將長(zhǎng)鏈(lurl)經(jīng)過 MurmurHash 后得到短鏈。 再根據(jù)短鏈去 short_url_map 表中查找看是否存在相關(guān)記錄,如果不存在,將長(zhǎng)鏈與短鏈對(duì)應(yīng)關(guān)系插入數(shù)據(jù)庫中,存儲(chǔ)。 如果存在,說明已經(jīng)有相關(guān)記錄了,此時(shí)在長(zhǎng)串上拼接一個(gè)自定義好的字段,比如「DUPLICATE」,然后再對(duì)接接的字段串「lurl + DUPLICATE」做第一步操作,如果最后還是重復(fù)呢,再拼一個(gè)字段串啊,只要到時(shí)根據(jù)短鏈取出長(zhǎng)鏈的時(shí)候把這些自定義好的字符串移除即是原來的長(zhǎng)鏈。
以上步驟顯然是要優(yōu)化的,插入一條記錄居然要經(jīng)過兩次 sql 查詢(根據(jù)短鏈查記錄,將長(zhǎng)短鏈對(duì)應(yīng)關(guān)系插入數(shù)據(jù)庫中),如果在高并發(fā)下,顯然會(huì)成為瓶頸。
畫外音:一般數(shù)據(jù)庫和應(yīng)用服務(wù)(只做計(jì)算不做存儲(chǔ))會(huì)部署在兩臺(tái)不同的 server 上,執(zhí)行兩條 sql 就需要兩次網(wǎng)絡(luò)通信,這兩次網(wǎng)絡(luò)通信與兩次 sql 執(zhí)行是整個(gè)短鏈系統(tǒng)的性能瓶頸所在!
所以該怎么優(yōu)化呢
首先我們需要給短鏈字段 surl 加上唯一索引 當(dāng)長(zhǎng)鏈經(jīng)過 MurmurHash 得到短鏈后,直接將長(zhǎng)短鏈對(duì)應(yīng)關(guān)系插入 db 中,如果 db 里不含有此短鏈的記錄,則插入,如果包含了,說明違反了唯一性索引,此時(shí)只要給長(zhǎng)鏈再加上我們上文說的自定義字段「DUPLICATE」,重新 hash 再插入即可,看起來在違反唯一性索引的情況下是多執(zhí)行了步驟,但我們要知道 MurmurHash 發(fā)生沖突的概率是非常低的,基本上不太可能發(fā)生,所以這種方案是可以接受的。
當(dāng)然如果在數(shù)據(jù)量很大的情況下,沖突的概率會(huì)增大,此時(shí)我們可以加布隆過濾器來進(jìn)行優(yōu)化。
用所有生成的短網(wǎng)址構(gòu)建布隆過濾器,當(dāng)一個(gè)新的長(zhǎng)鏈生成短鏈后,先將此短鏈在布隆過濾器中進(jìn)行查找,如果不存在,說明 db 里不存在此短網(wǎng)址,可以插入!
畫外音:布隆過濾器是一種非常省內(nèi)存的數(shù)據(jù)結(jié)構(gòu),長(zhǎng)度為 10 億的布隆過濾器,只需要 125 M 的內(nèi)存空間。
綜上,如果用哈希函數(shù)來設(shè)計(jì),總體的設(shè)計(jì)思路如下
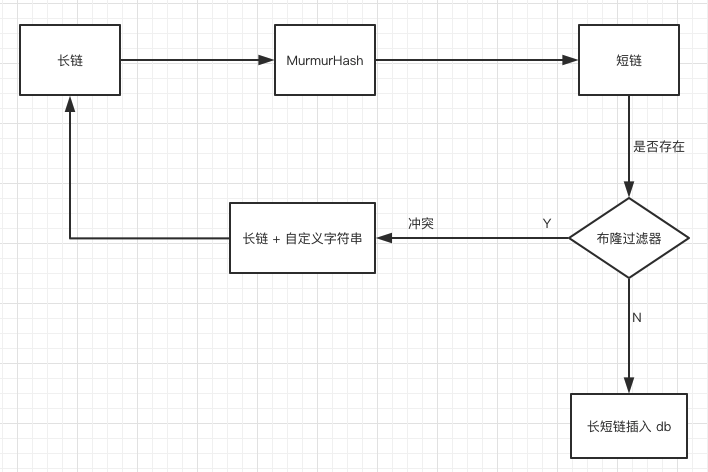
用哈希算法生成的短鏈其實(shí)已經(jīng)能滿足我們的業(yè)務(wù)需求,接下來我們?cè)賮砜纯慈绾斡米栽鲂蛄械姆绞絹砩啥替?/p>
2、自增序列算法
我們可以維護(hù)一個(gè) ID 自增生成器,比如 1,2,3 這樣的整數(shù)遞增 ID,當(dāng)收到一個(gè)長(zhǎng)鏈轉(zhuǎn)短鏈的請(qǐng)求時(shí),ID 生成器為其分配一個(gè) ID,再將其轉(zhuǎn)化為 62 進(jìn)制,拼接到短鏈域名后面就得到了最終的短網(wǎng)址,那么這樣的 ID 自增生成器該如何設(shè)計(jì)呢。如果在低峰期發(fā)號(hào)還好,高并發(fā)下,ID 自增生成器的的 ID 生成可能會(huì)系統(tǒng)瓶頸,所以它的設(shè)計(jì)就顯得尤為重要。
主要有以下四種獲取 id 的方法
1、類 uuid
簡(jiǎn)單地說就是用?UUID uuid = UUID.randomUUID();?這種方式生成的 UUID,UUID(Universally Unique Identifier)全局唯一標(biāo)識(shí)符,是指在一臺(tái)機(jī)器上生成的數(shù)字,它保證對(duì)在同一時(shí)空中的所有機(jī)器都是唯一的,但這種方式生成的 id 比較長(zhǎng),且無序,在插入 db 時(shí)可能會(huì)頻繁導(dǎo)致頁分裂,影響插入性能。
2、Redis
用 Redis 是個(gè)不錯(cuò)的選擇,性能好,單機(jī)可支撐 10 w+ 請(qǐng)求,足以應(yīng)付大部分的業(yè)務(wù)場(chǎng)景,但有人說如果一臺(tái)機(jī)器扛不住呢,可以設(shè)置多臺(tái)嘛,比如我布置 10 臺(tái)機(jī)器,每臺(tái)機(jī)器分別只生成尾號(hào)0,1,2,... 9 的 ID, 每次加 10 即可,只要設(shè)置一個(gè) ID 生成器代理隨機(jī)分配給發(fā)號(hào)器生成 ?ID 就行了。
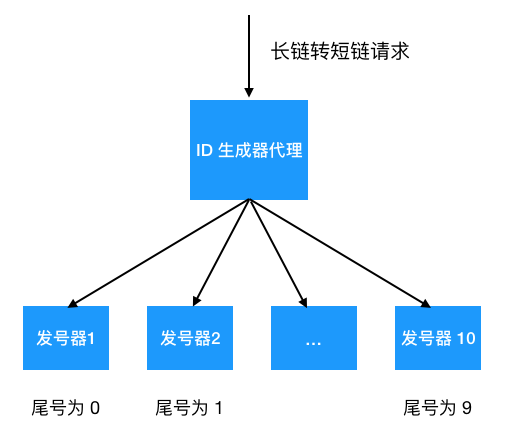
不過用 Redis 這種方案,需要考慮持久化(短鏈 ID 總不能一樣吧),災(zāi)備,成本有點(diǎn)高。
3、Snowflake
用 Snowflake 也是個(gè)不錯(cuò)的選擇,不過 Snowflake 依賴于系統(tǒng)時(shí)鐘的一致性。如果某臺(tái)機(jī)器的系統(tǒng)時(shí)鐘回?fù)埽锌赡茉斐?ID 沖突,或者 ID 亂序。
4、Mysql 自增主鍵
這種方式使用簡(jiǎn)單,擴(kuò)展方便,所以我們使用 Mysql 的自增主鍵來作為短鏈的 id。簡(jiǎn)單總結(jié)如下:
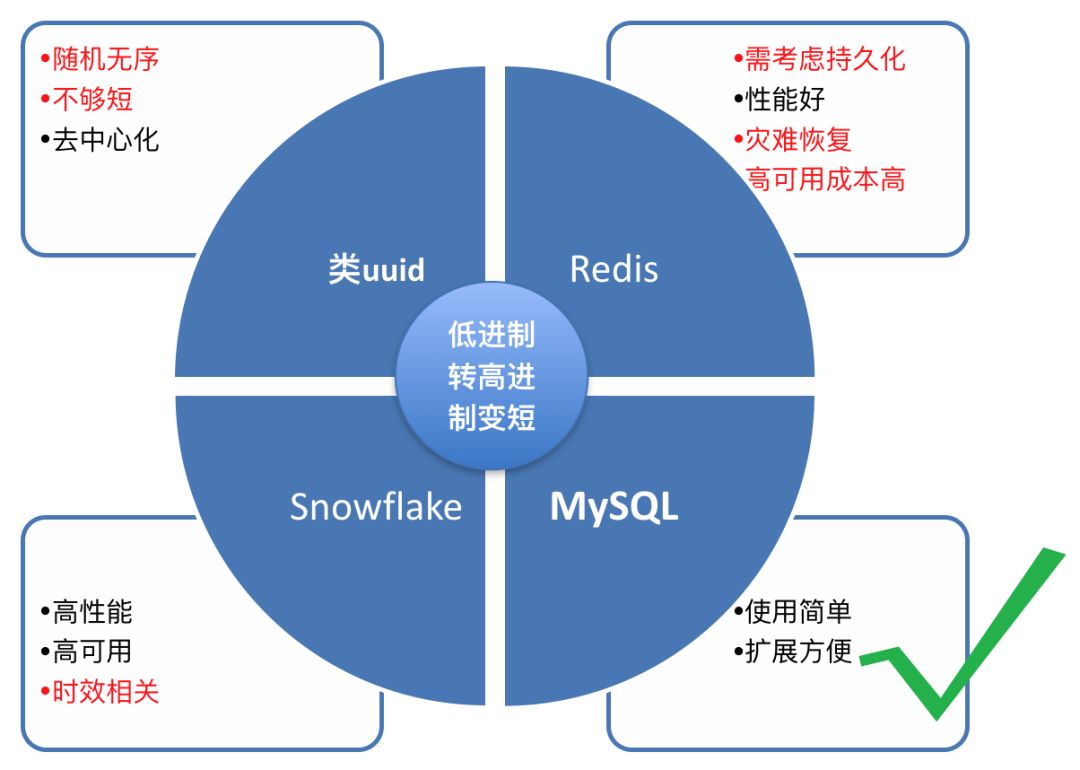
那么問題來了,如果用 Mysql 自增 id 作為短鏈 ID,在高并發(fā)下,db 的寫壓力會(huì)很大,這種情況該怎么辦呢。
考慮一下,一定要在用到的時(shí)候去生成 id 嗎,是否可以提前生成這些自增 id ?
方案如下:
設(shè)計(jì)一個(gè)專門的發(fā)號(hào)表,每插入一條記錄,為短鏈 id 預(yù)留 ?(主鍵 id * 1000 - 999) 到 ?(主鍵 id ?* 1000) 的號(hào)段,如下
發(fā)號(hào)表:url_sender_num
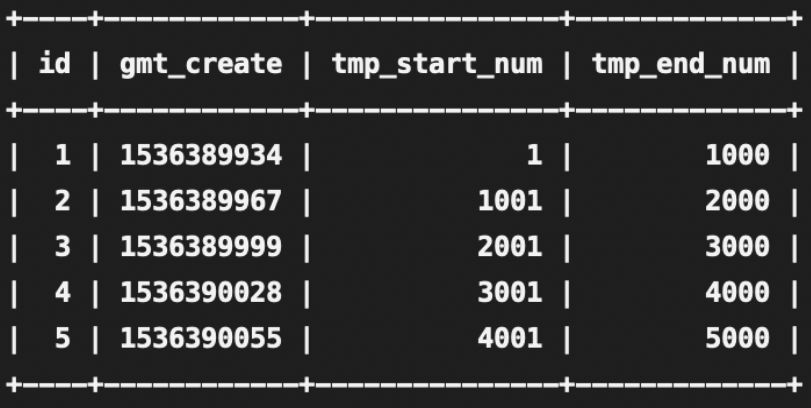
如圖示:tmp_start_num 代表短鏈的起始 id,tmp_end_num 代表短鏈的終止 id。
當(dāng)長(zhǎng)鏈轉(zhuǎn)短鏈的請(qǐng)求打到某臺(tái)機(jī)器時(shí),先看這臺(tái)機(jī)器是否分配了短鏈號(hào)段,未分配就往發(fā)號(hào)表插入一條記錄,則這臺(tái)機(jī)器將為短鏈分配范圍在 tmp_start_num 到 tmp_end_num 之間的 id。從 tmp_start_num 開始分配,一直分配到 tmp_end_num,如果發(fā)號(hào) id 達(dá)到了 tmp_end_num,說明這個(gè)區(qū)間段的 id 已經(jīng)分配完了,則再往發(fā)號(hào)表插入一條記錄就又獲取了一個(gè)發(fā)號(hào) id 區(qū)間。
畫外音:思考一下這個(gè)自增短鏈 id 在機(jī)器上該怎么實(shí)現(xiàn)呢, 可以用 redis, 不過更簡(jiǎn)單的方案是用 AtomicLong,單機(jī)上性能不錯(cuò),也保證了并發(fā)的安全性,當(dāng)然如果并發(fā)量很大,AtomicLong 的表現(xiàn)就不太行了,可以考慮用 LongAdder,在高并發(fā)下表現(xiàn)更加優(yōu)秀。
整體設(shè)計(jì)圖如下
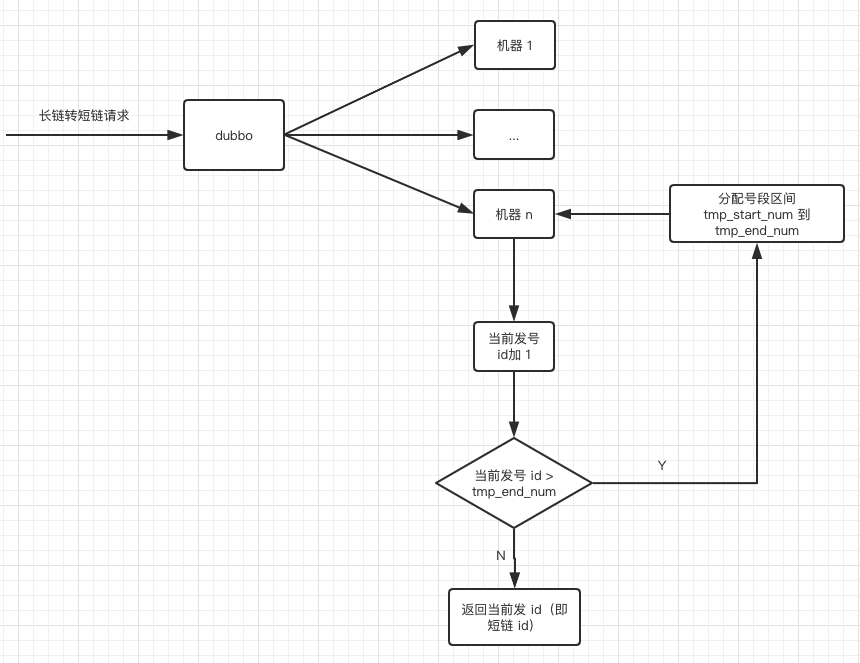
解決了發(fā)號(hào)器問題,接下來就簡(jiǎn)單了,從發(fā)號(hào)器拿過來的 id ,即為短鏈 id,接下來我們?cè)賱?chuàng)建一個(gè)長(zhǎng)短鏈的映射表即可, 短鏈 id 即為主鍵,不過這里有個(gè)需要注意的地方,我們可能需要防止多次相同的長(zhǎng)鏈生成不同的短鏈 id 這種情況,這就需要每次先根據(jù)長(zhǎng)鏈來查找 db 看是否存在相關(guān)記錄,一般的做法是給長(zhǎng)鏈加索引,但這樣的話索引的空間會(huì)很大,所以我們可以對(duì)長(zhǎng)鏈適當(dāng)?shù)膲嚎s,比如 md5,再對(duì)長(zhǎng)鏈的 md5 字段做索引,索引就會(huì)小很多。這樣只要根據(jù)長(zhǎng)鏈的 md5 去表里查是否存在相同的記錄即可。所以我們?cè)O(shè)計(jì)的表如下
CREATE TABLE `short_url_map` (
`id`int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT'短鏈 id',
`lurl`varchar(10) DEFAULT NULL COMMENT'長(zhǎng)鏈',
`md5`char(32) DEFAULT NULL COMMENT'長(zhǎng)鏈md5',
`gmt_create`int(11) DEFAULT NULL COMMENT'創(chuàng)建時(shí)間',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
當(dāng)然了,數(shù)據(jù)量如果很大的話,后期就需要分區(qū)或分庫分表了。
高性能短鏈的架構(gòu)設(shè)計(jì)
在電商公司,經(jīng)常有很多活動(dòng),秒殺,搶紅包等等,在某個(gè)時(shí)間點(diǎn)的 QPS 會(huì)很高,考慮到這種情況,我們引入了 openResty,它是一個(gè)基于 Nginx 與 Lua 的高性能 Web 平臺(tái),由于 Nginx 的非阻塞 IO 模型,使用 openResty 可以輕松支持 100 w + 的并發(fā)數(shù),一般情況下你只要部署一臺(tái)即可,不過為了避免單點(diǎn)故障,兩臺(tái)為宜,同時(shí) openResty 也自帶了緩存機(jī)制,集成了 redis 這些緩存模塊,也可以直接連 mysql。不需要再通過業(yè)務(wù)層連這些中間件,性能自然會(huì)高不少
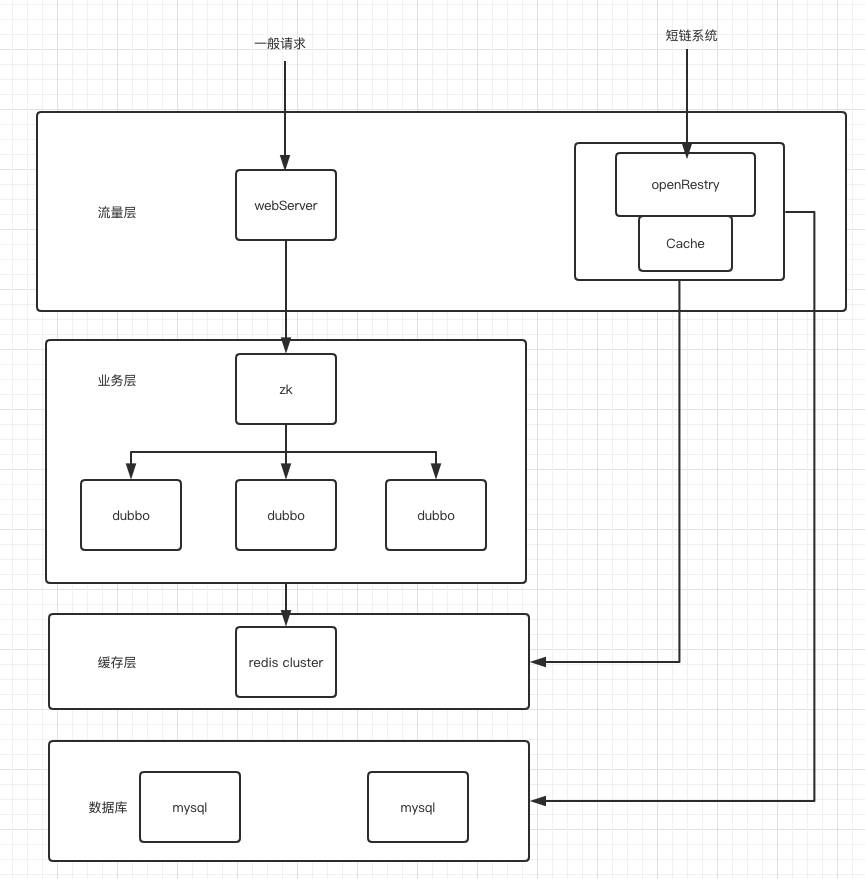
如圖示,使用 openResty 省去了業(yè)務(wù)層這一步,直達(dá)緩存層與數(shù)據(jù)庫層,也提升了不少性能。
總結(jié)
本文對(duì)短鏈設(shè)計(jì)方案作了詳細(xì)地剖析,旨在給大家提供幾種不同的短鏈設(shè)計(jì)思路,文中涉及到挺多像布隆過濾器,openResty 等技術(shù),文中沒有展開講,建議大家回頭可以再詳細(xì)了解一下。再比如文中提到的 Mysql 頁分裂也需要對(duì)底層使用的 B+ tree 數(shù)據(jù)結(jié)構(gòu),操作系統(tǒng)按頁獲取等知識(shí)有比較詳細(xì)地了解,相信大家各個(gè)知識(shí)點(diǎn)都吃透后會(huì)收獲不小。
巨人的肩膀
https://www.cnblogs.com/rjzheng/p/11827426.html
https://time.geekbang.org/column/article/80850
END


頂級(jí)程序員:topcoding
做最好的程序員社區(qū):Java后端開發(fā)、Python、大數(shù)據(jù)、AI
一鍵三連「分享」、「點(diǎn)贊」和「在看」