
字節(jié)三面:如何設(shè)計(jì)一個(gè)高性能短鏈系統(tǒng)?
什么是短鏈?為什么要用短鏈?
-
鏈接變短,在對(duì)內(nèi)容長(zhǎng)度有限制的平臺(tái)發(fā)文,可編輯的文字就變多了。比如微博限定了只能發(fā) 140 個(gè)字,如果一串長(zhǎng)鏈直接復(fù)制上去就沒地方再寫其他文字了 -
大家接受各種短信的時(shí)候,能發(fā)現(xiàn)大部分鏈接都是短鏈形式,因?yàn)橐话愣绦虐l(fā)文有長(zhǎng)度限度,如果用長(zhǎng)鏈,一條短信很可能要拆分成兩三條發(fā),相應(yīng)的成本也就增加了 -
使用短鏈在排版上更加美觀
短鏈跳轉(zhuǎn)的基本原理

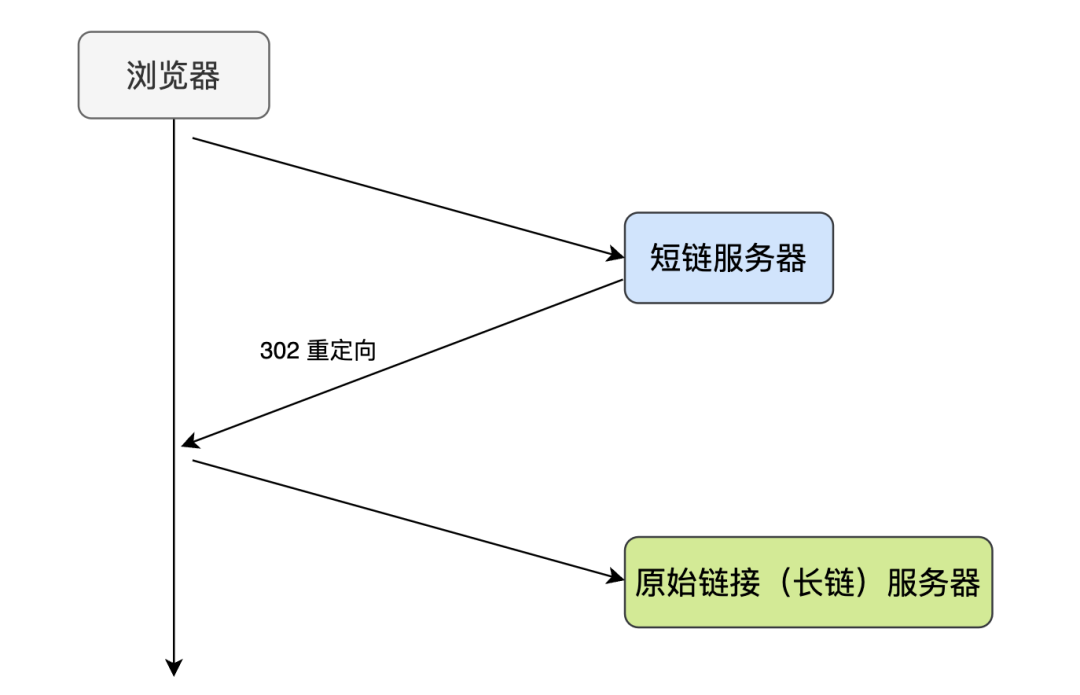
-
301,代表 永久重定向:第一次請(qǐng)求拿到長(zhǎng)鏈接后,下次瀏覽器再去請(qǐng)求短鏈的話,不會(huì)向短鏈服務(wù)器請(qǐng)求了,而是直接從瀏覽器的緩存里拿,這樣的話短鏈服務(wù)器就無法獲取到短鏈的點(diǎn)擊數(shù)了,不利于數(shù)據(jù)分析,所以我們一般不采用 301 -
302,代表 臨時(shí)重定向:每次去請(qǐng)求短鏈都會(huì)去請(qǐng)求短鏈服務(wù)器(除非響應(yīng)中用 Cache-Control 或 Expired 暗示瀏覽器緩存),這樣便于短鏈服務(wù)器統(tǒng)計(jì)點(diǎn)擊數(shù)
生成短鏈的兩種方法
方法 1:哈希算法
如何讓短鏈更短
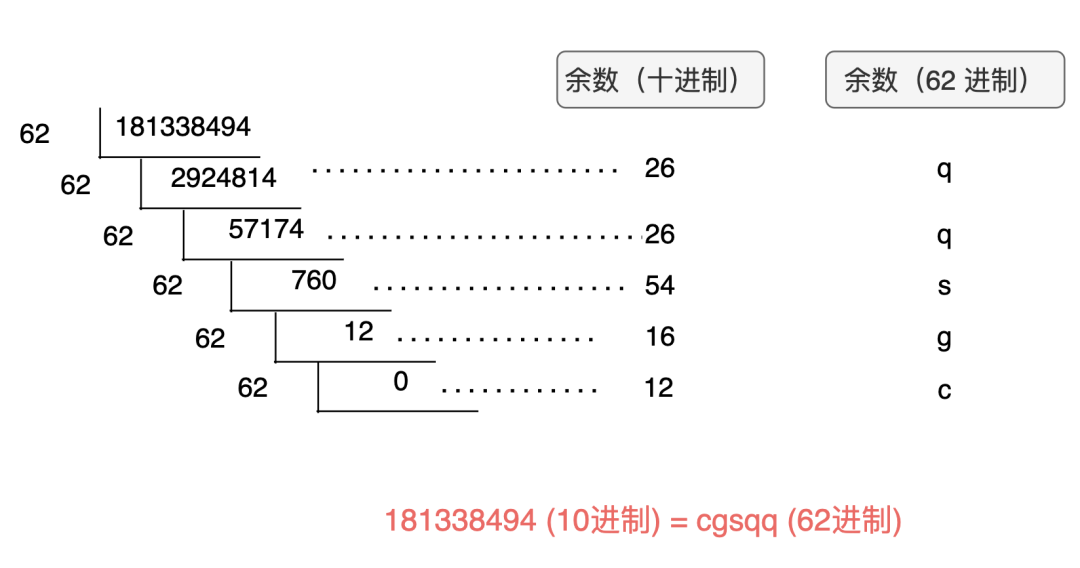
如何解決哈希沖突
-
如果沒有找到相同的短鏈,這就表明這個(gè)新生成的短鏈沒有沖突。于是我們就將這個(gè)短鏈返回給用戶,然后將這個(gè)短鏈與原始網(wǎng)址之間的對(duì)應(yīng)關(guān)系,存儲(chǔ)到 MySQL 數(shù)據(jù)庫中
-
如果在數(shù)據(jù)庫中找到了相同的短鏈,那也并不一定說明就沖突了。我們先從數(shù)據(jù)庫中將這個(gè)短鏈對(duì)應(yīng)的原始網(wǎng)址取出來:
-
如果數(shù)據(jù)庫中的原始網(wǎng)址,跟我們現(xiàn)在正在處理的原始網(wǎng)址是一樣的,這就說明已經(jīng)有人請(qǐng)求過這個(gè)原始網(wǎng)址的短鏈了。我們就可以拿這個(gè)短鏈直接用。
-
如果數(shù)據(jù)庫中記錄的原始網(wǎng)址,跟我們正在處理的原始網(wǎng)址不一樣,那就說明哈希算法發(fā)生了沖突。不同的原始網(wǎng)址,經(jīng)過計(jì)算,得到的短鏈重復(fù)了。這個(gè)時(shí)候,我們可以給原始網(wǎng)址拼接一串特殊字符,比如
DUPLICATED,然后再重新計(jì)算哈希值,兩次哈希計(jì)算都沖突的概率,顯然是非常低的。假設(shè)出現(xiàn)非常極端的情況,又發(fā)生沖突了,我們可以再換一個(gè)拼接字符串,比如OHMYGOD,再計(jì)算哈希值。然后把計(jì)算得到的哈希值,跟原始網(wǎng)址拼接了特殊字符串之后的文本,一并存儲(chǔ)在 MySQL 數(shù)據(jù)庫中。當(dāng)用戶訪問短鏈的時(shí)候,短鏈服務(wù)先通過短鏈,在數(shù)據(jù)庫中查找到對(duì)應(yīng)的原始網(wǎng)址。如果原始網(wǎng)址有拼接特殊字符(這個(gè)很容易通過字符串匹配算法找到),就先將特殊字符去掉,然后再將不包含特殊字符的原始網(wǎng)址返回給瀏覽器。
如何優(yōu)化性能
-
第一個(gè) SQL 語句是通過短鏈查詢短鏈與原始網(wǎng)址的對(duì)應(yīng)關(guān)系 -
第二個(gè) SQL 語句是將新生成的短鏈和原始網(wǎng)址之間的對(duì)應(yīng)關(guān)系存儲(chǔ)到數(shù)據(jù)庫
方法二:ID 生成器
相同的原始網(wǎng)址可能會(huì)對(duì)應(yīng)不同的短鏈
-
第一種處理思路是不做處理。聽起來有點(diǎn)匪夷所依,但實(shí)際上,相同的原始網(wǎng)址對(duì)應(yīng)不同的短鏈,這個(gè)用戶是完全可以接受的。在大部分短鏈的應(yīng)用場(chǎng)景里,用戶只關(guān)心短鏈能否正確地跳轉(zhuǎn)到原始網(wǎng)址。至于短鏈長(zhǎng)什么樣子,他其實(shí)根本就不關(guān)心。
-
第二種處理思路是拿原始網(wǎng)址在數(shù)據(jù)庫中查找,看數(shù)據(jù)庫中是否已經(jīng)存在相同的原始網(wǎng)址了。如果數(shù)據(jù)庫中存在,那我們就取出對(duì)應(yīng)的短鏈,直接返回給用戶。
不過,這種處理思路有個(gè)問題,我們需要給數(shù)據(jù)庫中的短鏈和原始網(wǎng)址這兩個(gè)字段,都添加索引。短鏈上加索引是為了提高用戶查詢短鏈對(duì)應(yīng)的原始網(wǎng)頁的速度,原始網(wǎng)址上加索引是為了加快剛剛講的通過原始網(wǎng)址查詢短鏈的速度。這種解決思路雖然能滿足 “相同原始網(wǎng)址對(duì)應(yīng)相同短鏈” 這樣一個(gè)需求,但是是有代價(jià)的:一方面兩個(gè)索引會(huì)占用更多的存儲(chǔ)空間,另一方面索引還會(huì)導(dǎo)致插入、刪除等操作性能的下降。
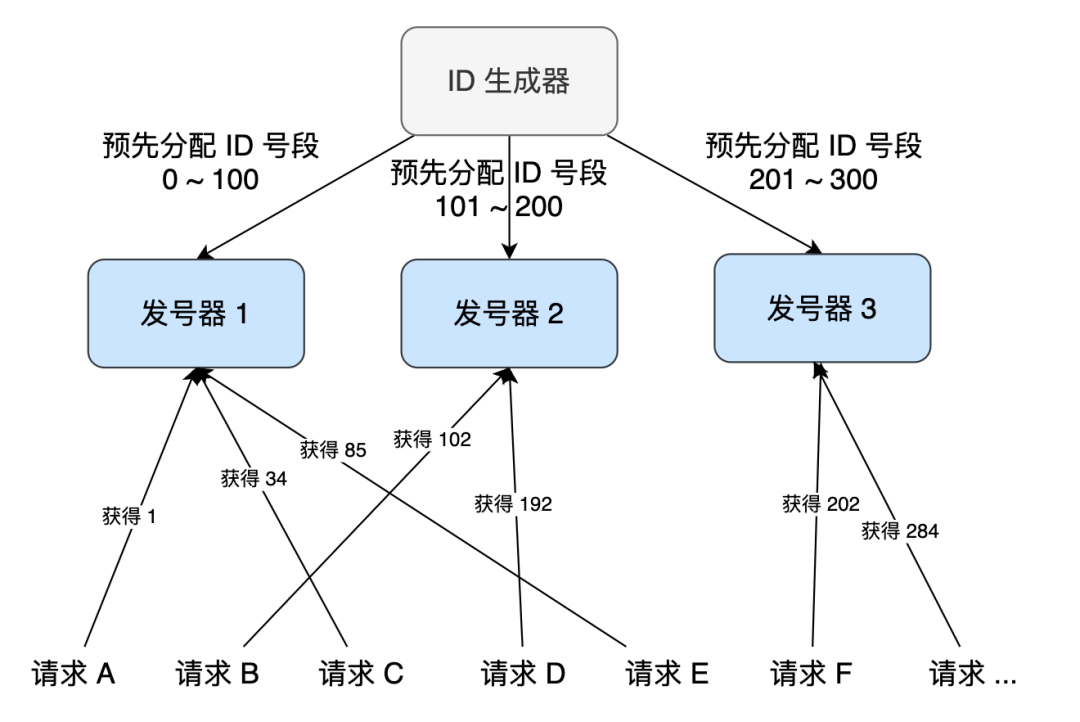
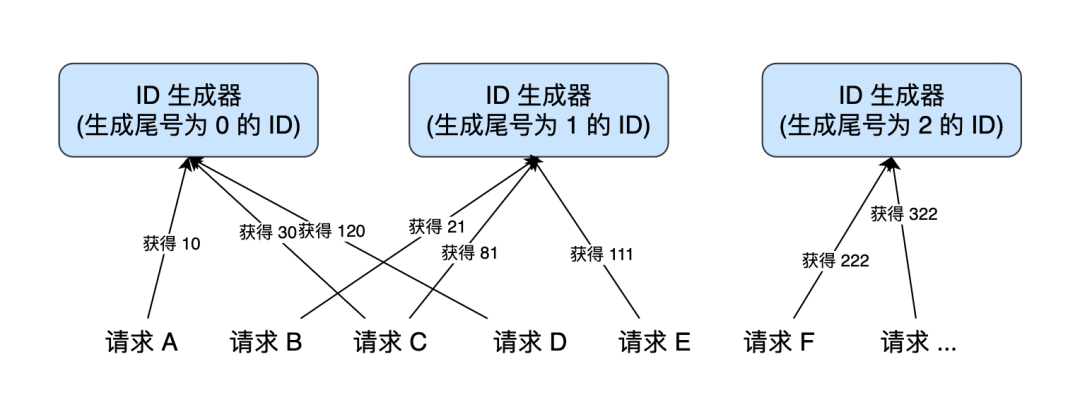
如何實(shí)現(xiàn)高性能的 ID 生成器
可能不是很好理解,這里類比下 “無鎖的并發(fā)生產(chǎn)者 - 消費(fèi)者模型”: 對(duì)于生產(chǎn)者來說,它往隊(duì)列中添加數(shù)據(jù)之前,先申請(qǐng)可用空閑存儲(chǔ)單元,并且是批量地申請(qǐng)連續(xù)的 n 個(gè)(n≥1)存儲(chǔ)單元。當(dāng)申請(qǐng)到這組連續(xù)的存儲(chǔ)單元之后,后續(xù)往隊(duì)列中添加元素,就可以不用加鎖了,因?yàn)檫@組存儲(chǔ)單元是這個(gè)線程獨(dú)享的。不過,申請(qǐng)存儲(chǔ)單元的過程還是需要加鎖的。 對(duì)于消費(fèi)者來說,處理的過程跟生產(chǎn)者是類似的。它先去申請(qǐng)一批連續(xù)可讀的存儲(chǔ)單元(這個(gè)申請(qǐng)的過程也是需要加鎖的),當(dāng)申請(qǐng)到這批存儲(chǔ)單元之后,后續(xù)的讀取操作就可以不用加鎖了。
往期推薦