
【數(shù)據(jù)分析】Databricks入門:分析COVID-19
作者 | Renan Ferreira?
編譯 | VK?
來源 | Towards Datas Science
典型的數(shù)據(jù)科學工作流由以下步驟組成:
?確定業(yè)務需求->數(shù)據(jù)獲取->數(shù)據(jù)準備->數(shù)據(jù)分析->共享數(shù)據(jù)見解
?
每一個步驟都需要一套專業(yè)知識,這些專業(yè)知識可分為:
數(shù)據(jù)工程師:開發(fā)、構建、測試和維護數(shù)據(jù)管道
數(shù)據(jù)科學家:使用各種方法建立數(shù)據(jù)模型(機器學習模型)
數(shù)據(jù)分析師:獲取數(shù)據(jù)工程師準備的數(shù)據(jù),以圖形、圖表和儀表板的形式從中提取見解(商業(yè)智能)
平臺管理員:負責管理和支持數(shù)據(jù)基礎設施(DevOps)
Databricks是一個統(tǒng)一的平臺,它為每個作業(yè)提供了必要的工具。在本文中,我們將通過創(chuàng)建一個數(shù)據(jù)管道并指出每個團隊成員的職責來分析巴西的COVID-19數(shù)據(jù)。
準備
要完成下一步,你需要訪問Databricks帳戶。最簡單的啟動方法是在https://community.cloud.databricks.com
集群創(chuàng)建(平臺管理員)
第一步是配置集群。Databricks是一個基于Spark的平臺,是最流行的大數(shù)據(jù)分析框架之一。Spark本質(zhì)上是一個分布式系統(tǒng)。驅(qū)動程序是集群的協(xié)調(diào)器,工作節(jié)點負責繁重的工作。
平臺管理員負責根據(jù)用例、spark版本、worker節(jié)點數(shù)量和自動調(diào)整配置選擇適當?shù)奶摂M機系列。例如,ETL過程可能需要內(nèi)存優(yōu)化的設備,而繁重的機器學習訓練過程可能在gpu上運行。
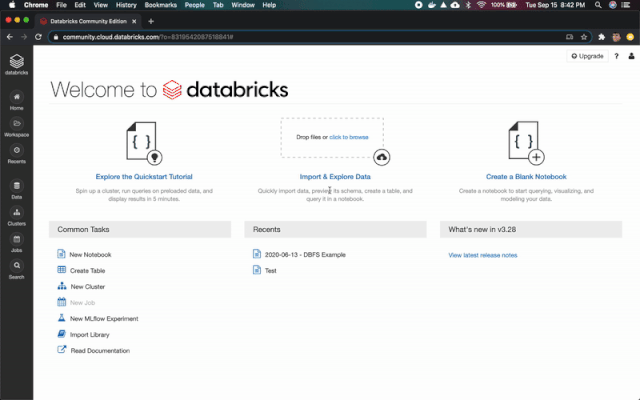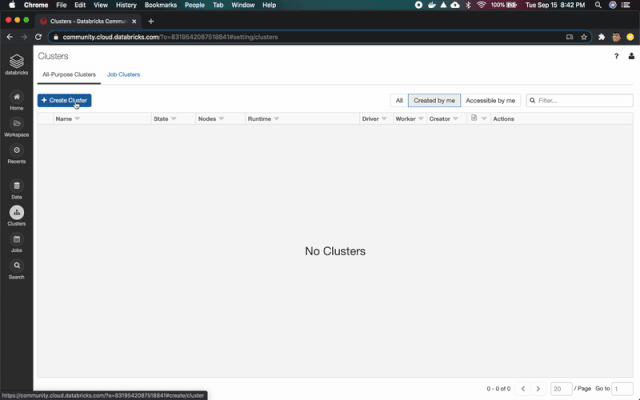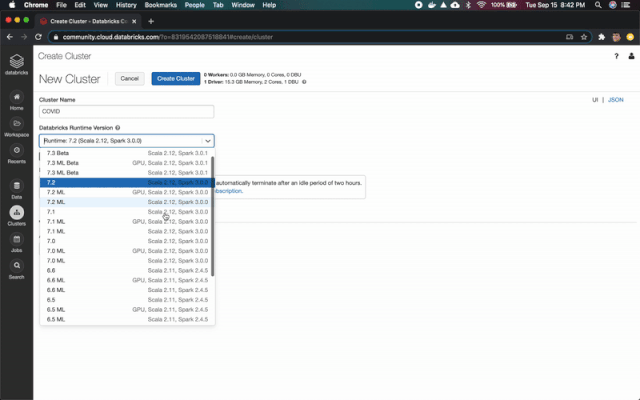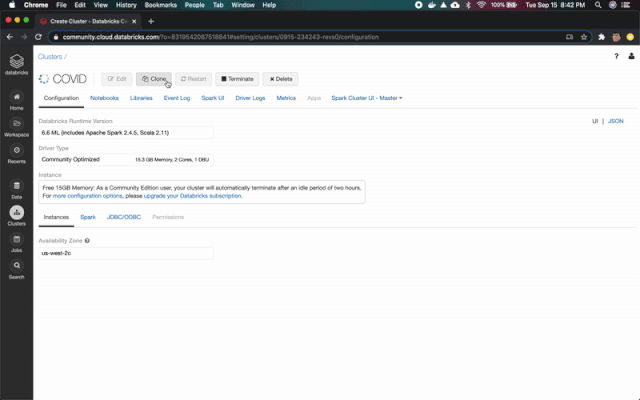
轉(zhuǎn)到Clusters頁面,使用6.6ML運行時創(chuàng)建一個新的集群。如果你使用的是 Azure Databricks或AWS,則需要選擇驅(qū)動程序和worker節(jié)點的VM系列。對于本教程,你可以選擇最便宜的。
數(shù)據(jù)獲取
數(shù)據(jù)獲取可能是一個具有挑戰(zhàn)性的領域。通常,公司將數(shù)據(jù)存儲在多個數(shù)據(jù)庫中,而現(xiàn)在數(shù)據(jù)流的使用非常普遍。幸運的是,Databricks與Spark和Delta-Lake相結(jié)合,可以幫助我們?yōu)榕幚砘蛄魇紼TL(提取、轉(zhuǎn)換和加載)提供一個簡單的接口。
在本教程中,我們將從最簡單的ETL類型開始,從CSV文件加載數(shù)據(jù)。
首先,我們需要下載數(shù)據(jù)集。訪問以下網(wǎng)址:
https://github.com/relferreira/databricks-tutorial/tree/master/covid
下載文件caso.csv.gz
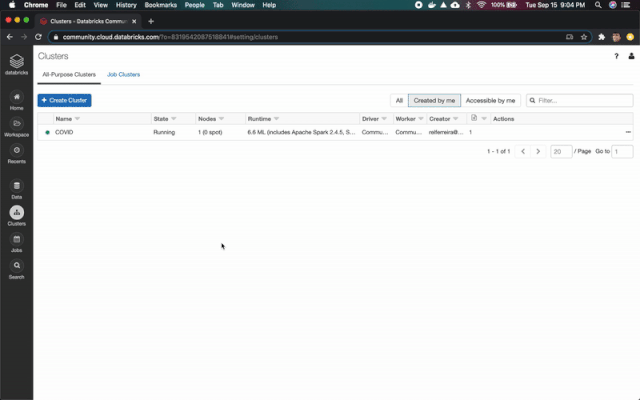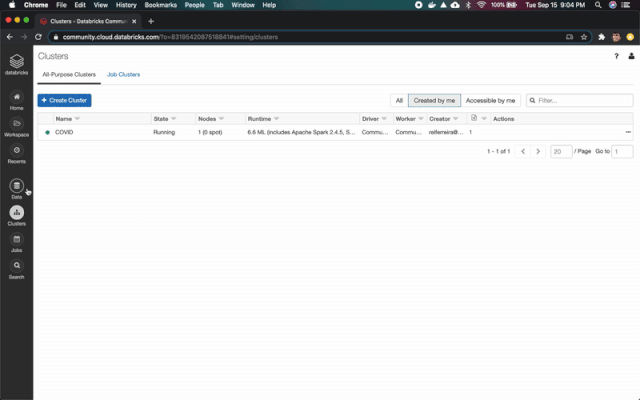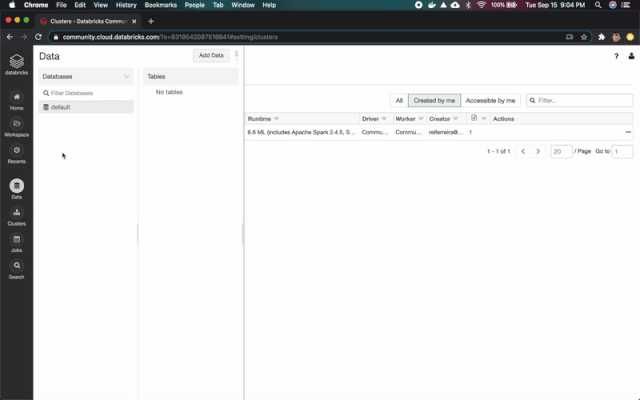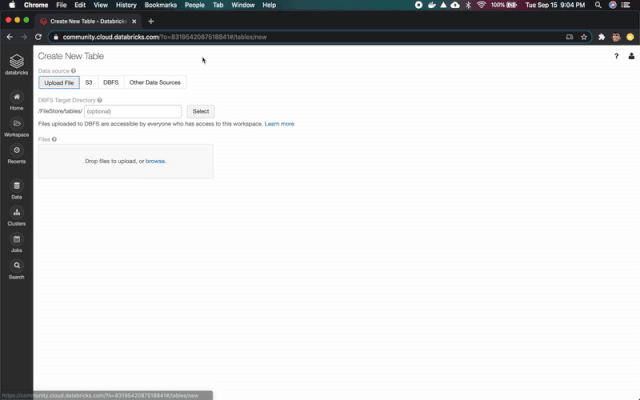
解壓縮該文件,訪問“數(shù)據(jù)”菜單,然后單擊“添加數(shù)據(jù)”按鈕。接下來,上傳先前下載的CSV文件。
上傳完成后,我們將使用數(shù)據(jù)集中顯示的信息創(chuàng)建一個新表。單擊Create Table UI,將表重命名為covid,將第一行設置為標題,最后單擊Create按鈕。
數(shù)據(jù)分析
創(chuàng)建了表之后,我們就可以開始分析數(shù)據(jù)集了。首先,我們需要創(chuàng)建一個新的python notebook。
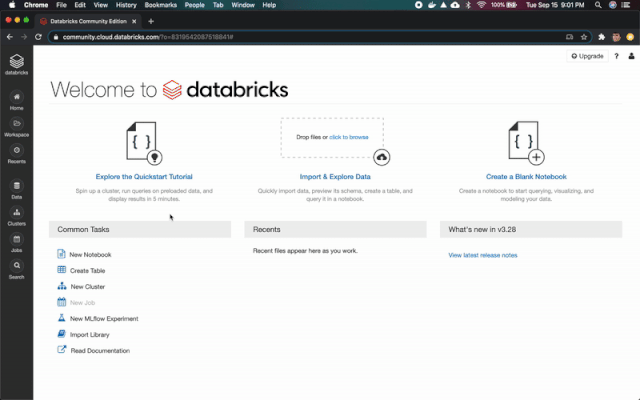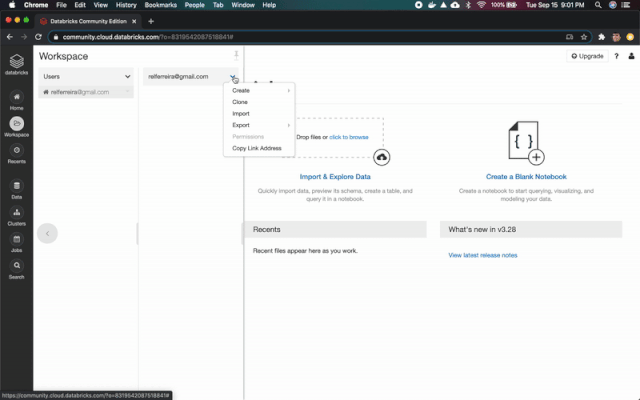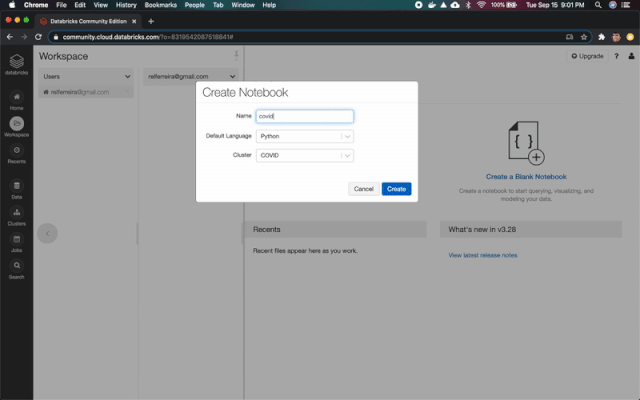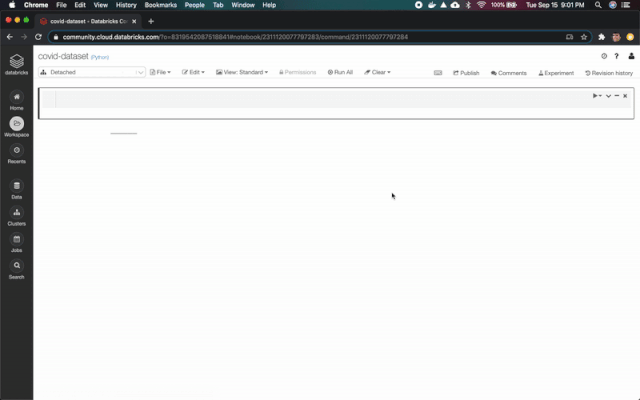
?Worspace > Users > YOUR EMAIL
?
單擊箭頭并創(chuàng)建一個新的Notebook
盡管Databricks是一個python Notebook,但它支持Notebook內(nèi)的多種語言。在我們的例子中,我們將主要使用SparkSQL。如果你熟悉SQL,SparkSQL會讓你感覺像家一樣。
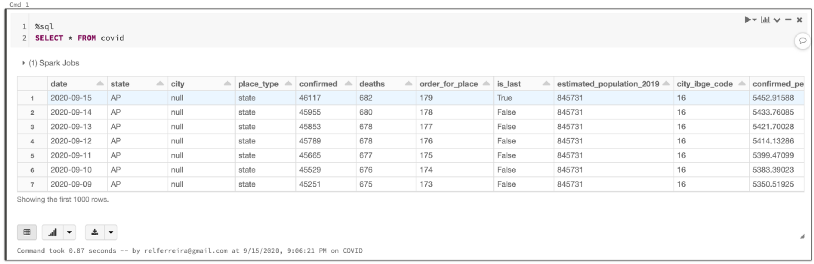
讓我們從查看新表開始:
%sql
SELECT?*?FROM?covid
你應該看到這樣的表:
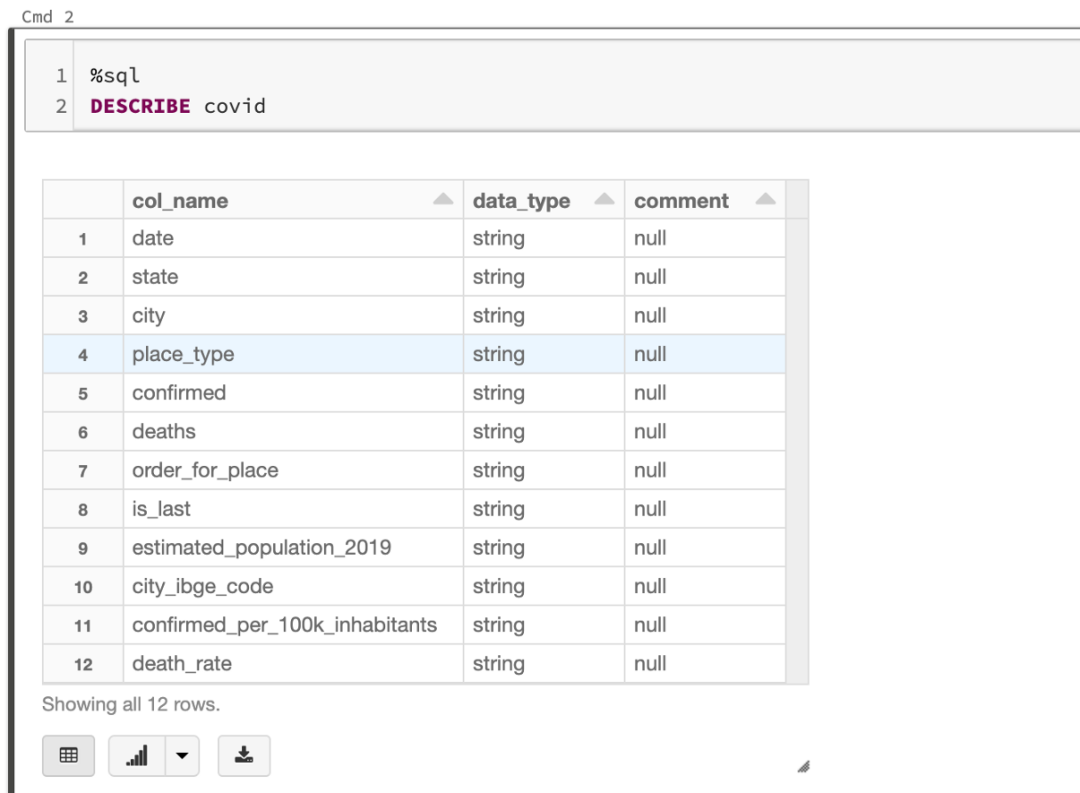
作為數(shù)據(jù)分析員,你應該能夠提取有關數(shù)據(jù)的有價值的信息。首先,我們需要理解表中每一列的含義。一種方法是使用DESCRIBE函數(shù):
%sql
DESCRIBE?covid
通過分析這兩個表,我們可以推斷出,當列place_type為state時,每一行表示該state的總數(shù)。讓我們試著畫出人口最多的三個州的死亡人數(shù)的演變:
%sql
SELECT?date,?state,?deaths?FROM?covid?WHERE?state?in?(“MG”,?“RJ”,?“SP”)?and?place_type?=?“state”
單擊Bar Chart按鈕,Plot選項,并對Line chart使用以下配置:
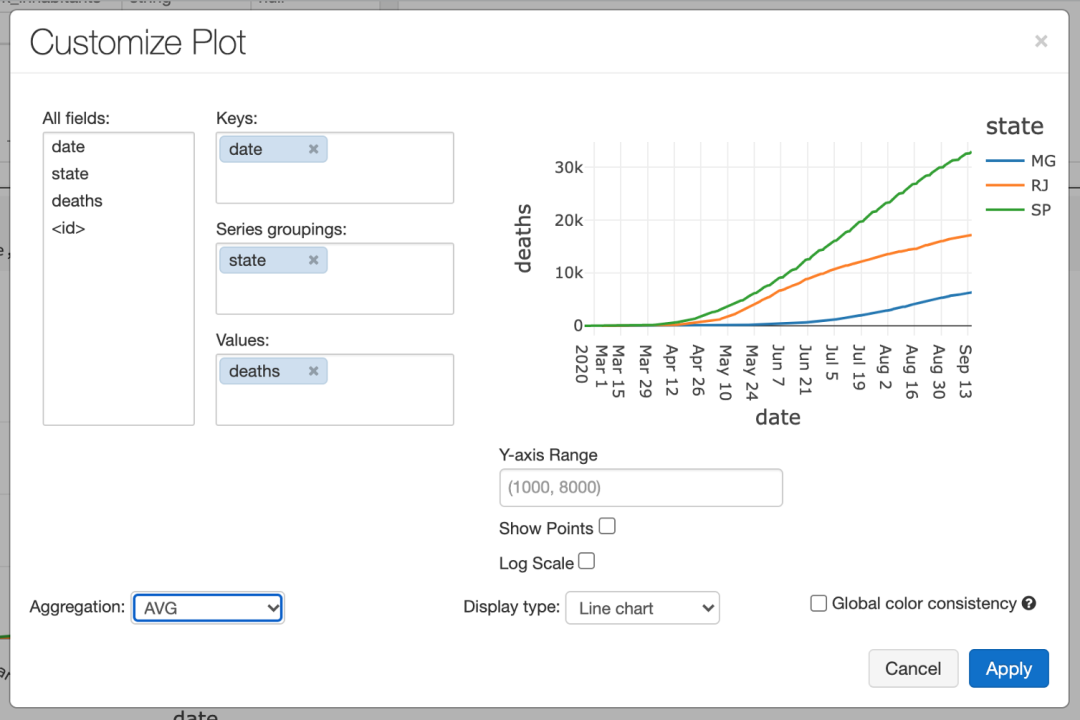
現(xiàn)在我們有了大流行期間死亡人數(shù)演變的一個很好的代表。例如,我們可以將此圖嵌入儀表板,以提醒這些州的人口。
數(shù)據(jù)科學
接下來,我們將嘗試預測先前繪制的時間序列的未來值。為此,我們將使用一個名為Prophet的Facebook庫
首先,我們需要安裝一些依賴項。
?Clusters > COVID > Libraries
?
并使用PyPI安裝以下依賴項
pandas pystan fbprophet
我們將嘗試預測Minas Gerais(MG)未來的死亡人數(shù)。所以第一步是收集我們的數(shù)據(jù)。
也許你需要清除你Notebook的狀態(tài)
import?pandas?as?pd
import?logging
logger?=?spark._jvm.org.apache.log4j
logging.getLogger("py4j").setLevel(logging.ERROR)
query?=?"""
?SELECT?string(date)?as?ds,?int(deaths)?as?y?FROM?covid?WHERE?state?=?"MG"?and?place_type?=?"state"?order?by?date
"""
df?=?spark.sql(query)
df?=?df.toPandas()
display(df)
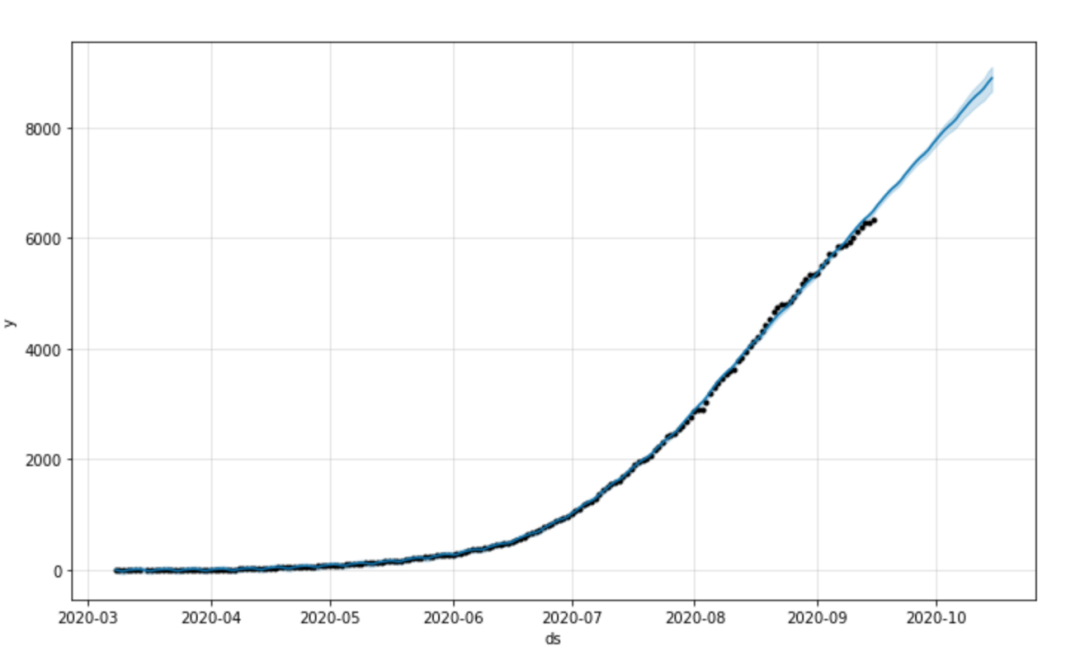
接下來,我們將使用Prophet擬合模型并最終繪制預測
from?fbprophet?import?Prophet
m?=?Prophet()
m.fit(df)
future?=?m.make_future_dataframe(periods=30)
forecast?=?m.predict(future)
fig1?=?m.plot(forecast)
你應該看到下面的圖表和預測:
結(jié)論
我們的目標是演示數(shù)據(jù)科學工作流的所有步驟。這就是為什么我們沒有描述時間序列模型是如何工作的。如果你遵循本教程,你應該對Databricks平臺有一個很好的了解。
此公共存儲庫中提供了完整的Notebook:https://github.com/relferreira/databricks-tutorial
原文鏈接:https://towardsdatascience.com/getting-started-with-databricks-analyzing-covid-19-1194d833e90f
往期精彩回顧