
Spark SQL知識點與實戰(zhàn)
本文目錄
Spark SQL概述
1、什么是Spark SQL
2、Spark SQL的特點
3、什么的DataFrame
4、什么是DataSet
Spark SQL編程
1、Spark Session新的起始點
2、DataFrame
3、DataSet
4、DataFrame與DataSet的互操作
Spark SQL數(shù)據(jù)的加載與保存
1、通用的加載與保存方式
2、JSON文件
3、MySQL
4、Hive
Spark SQL實戰(zhàn)
1、數(shù)據(jù)準備
2、需求
知識星球
1、什么是Spark SQL
Spark SQL是Spark用于結構化數(shù)據(jù)(structured data)處理的Spark模塊。
與基本的Spark RDD API不同,Spark SQL的抽象數(shù)據(jù)類型為Spark提供了關于數(shù)據(jù)結構和正在執(zhí)行的計算的更多信息。
在內部,Spark SQL使用這些額外的信息去做一些額外的優(yōu)化,有多種方式與Spark SQL進行交互,比如: SQL和DatasetAPI。
當計算結果的時候,使用的是相同的執(zhí)行引擎,不依賴你正在使用哪種API或者語言。這種統(tǒng)一也就意味著開發(fā)者可以很容易在不同的API之間進行切換,這些API提供了最自然的方式來表達給定的轉換。
Hive是將Hive SQL轉換成 MapReduce然后提交到集群上執(zhí)行,大大簡化了編寫MapReduce的程序的復雜性,由于MapReduce這種計算模型執(zhí)行效率比較慢。所以Spark SQL的應運而生,它是將Spark SQL轉換成RDD,然后提交到集群執(zhí)行,執(zhí)行效率非常快!
Spark SQL它提供了2個編程抽象,類似Spark Core中的RDD
(1)DataFrame
(2)Dataset
2、Spark SQL的特點
1)易整合
無縫的整合了SQL查詢和Spark編程
2)統(tǒng)一的數(shù)據(jù)訪問方式
使用相同的方式連接不同的數(shù)據(jù)源
3)兼容Hive
在已有的倉庫上直接運行SQL或者HiveQL
4)標準的數(shù)據(jù)連接
通過JDBC或者ODBC來連接
3、什么的DataFrame
在Spark中,DataFrame是一種以RDD為基礎的分布式數(shù)據(jù)集,類似于傳統(tǒng)數(shù)據(jù)庫中的二維表格。DataFrame與RDD的主要區(qū)別在于,前者帶有schema元信息,即DataFrame所表示的二維表數(shù)據(jù)集的每一列都帶有名稱和類型。這使得Spark SQL得以洞察更多的結構信息,從而對藏于DataFrame背后的數(shù)據(jù)源以及作用于DataFrame之上的變換進行了針對性的優(yōu)化,最終達到大幅提升運行時效率的目標。反觀RDD,由于無從得知所存數(shù)據(jù)元素的具體內部結構,Spark Core只能在stage層面進行簡單、通用的流水線優(yōu)化。
同時,與Hive類似,DataFrame也支持嵌套數(shù)據(jù)類型(struct、array和map)。從API易用性的角度上看,DataFrame API提供的是一套高層的關系操作,比函數(shù)式的RDD API要更加友好,門檻更低。
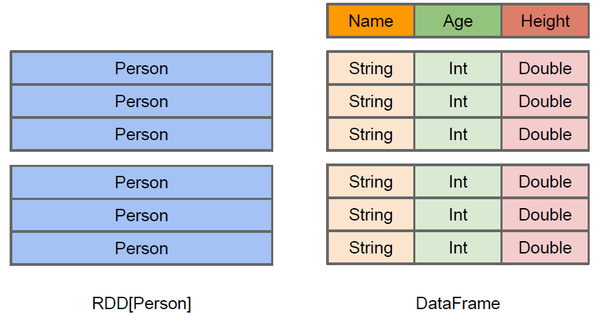
上圖直觀地體現(xiàn)了DataFrame和RDD的區(qū)別。
左側的RDD[Person]雖然以Person為類型參數(shù),但Spark框架本身不了解Person類的內部結構。而右側的DataFrame卻提供了詳細的結構信息,使得 Spark SQL 可以清楚地知道該數(shù)據(jù)集中包含哪些列,每列的名稱和類型各是什么。
DataFrame是為數(shù)據(jù)提供了Schema的視圖。可以把它當做數(shù)據(jù)庫中的一張表來對待,DataFrame也是懶執(zhí)行的,但性能上比RDD要高,主要原因:優(yōu)化的執(zhí)行計劃,即查詢計劃通過Spark catalyst optimiser進行優(yōu)化。比如下面一個例子:
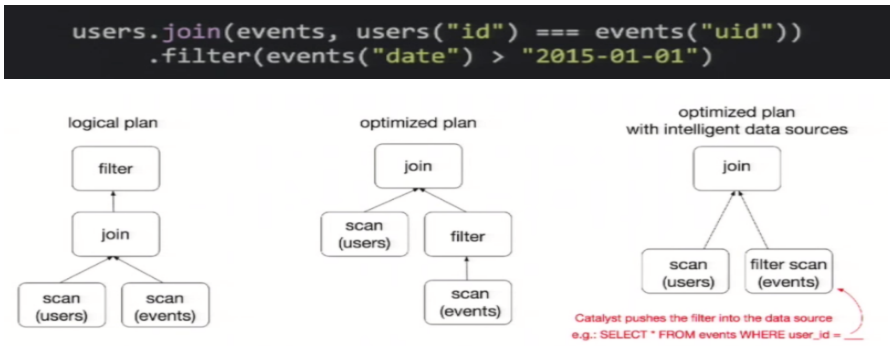
為了說明查詢優(yōu)化,我們來看上圖展示的人口數(shù)據(jù)分析的示例。圖中構造了兩個DataFrame,將它們join之后又做了一次filter操作。
如果原封不動地執(zhí)行這個執(zhí)行計劃,最終的執(zhí)行效率是不高的。因為join是一個代價較大的操作,也可能會產(chǎn)生一個較大的數(shù)據(jù)集。如果我們能將filter下推到 join下方,先對DataFrame進行過濾,再join過濾后的較小的結果集,便可以有效縮短執(zhí)行時間。而Spark SQL的查詢優(yōu)化器正是這樣做的。簡而言之,邏輯查詢計劃優(yōu)化就是一個利用基于關系代數(shù)的等價變換,將高成本的操作替換為低成本操作的過程。
4、什么是DataSet
DataSet是分布式數(shù)據(jù)集合。DataSet是Spark 1.6中添加的一個新抽象,是DataFrame的一個擴展。它提供了RDD的優(yōu)勢(強類型,使用強大的lambda函數(shù)的能力)以及Spark SQL優(yōu)化執(zhí)行引擎的優(yōu)點。DataSet也可以使用功能性的轉換(操作map,flatMap,filter等等)。
1)是DataFrame API的一個擴展,是SparkSQL最新的數(shù)據(jù)抽象;
2)用戶友好的API風格,既具有類型安全檢查也具有DataFrame的查詢優(yōu)化特性;
3)用樣例類來定義DataSet中數(shù)據(jù)的結構信息,樣例類中每個屬性的名稱直接映射到DataSet中的字段名稱;
4)DataSet是強類型的。比如可以有DataSet[Car],DataSet[Person]。
5)DataFrame是DataSet的特列,DataFrame=DataSet[Row]?,所以可以通過as方法將DataFrame轉換為DataSet。Row是一個類型,跟Car、Person這些的類型一樣,所有的表結構信息都用Row來表示。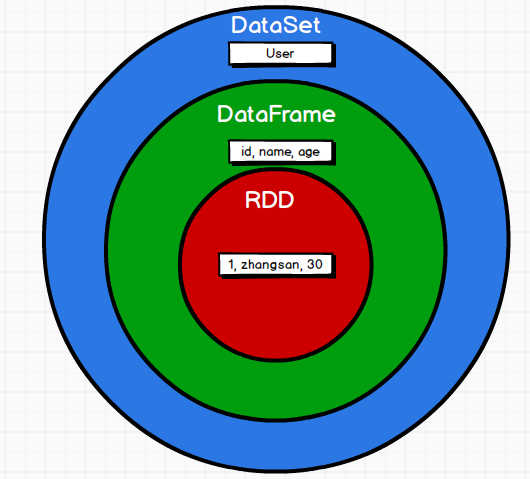
Spark SQL編程
1、Spark Session新的起始點
在老的版本中,SparkSQL提供兩種SQL查詢起始點:一個叫SQLContext,用于Spark自己提供的SQL查詢;一個叫HiveContext,用于連接Hive的查詢。
SparkSession是Spark最新的SQL查詢起始點,實質上是SQLContext和HiveContext的組合,所以在SQLContex和HiveContext上可用的API在SparkSession上同樣是可以使用的。SparkSession內部封裝了sparkContext,所以計算實際上是由sparkContext完成的。當我們使用 spark-shell 的時候, spark 會自動的創(chuàng)建一個叫做spark的SparkSession, 就像我們以前可以自動獲取到一個sc來表示SparkContext
2、DataFrame
Spark SQL的DataFrame API 允許我們使用 DataFrame 而不用必須去注冊臨時表或者生成SQL表達式。DataFrame API 既有transformation操作也有action操作,DataFrame的轉換從本質上來說更具有關系, 而 DataSet API 提供了更加函數(shù)式的 API。
2.1 創(chuàng)建DataFrame
在Spark SQL中SparkSession是創(chuàng)建DataFrame和執(zhí)行SQL的入口,創(chuàng)建DataFrame有三種方式:通過Spark的數(shù)據(jù)源進行創(chuàng)建;從一個存在的RDD進行轉換;還可以從Hive Table進行查詢返回。
2.2 SQL風格語法
SQL語法風格是指我們查詢數(shù)據(jù)的時候使用SQL語句來查詢,這種風格的查詢必須要有臨時視圖或者全局視圖來輔助
1)創(chuàng)建一個DataFrame
scala>?val?df?=?spark.read.json("/opt/module/spark-local/people.json")
df:?org.apache.spark.sql.DataFrame?=?[age:?bigint,?name:?string]
2)對DataFrame創(chuàng)建一個臨時表
scala>?df.createOrReplaceTempView("people")
3)通過SQL語句實現(xiàn)查詢全表
scala>?val?sqlDF?=?spark.sql("SELECT?*?FROM?people")
sqlDF:?org.apache.spark.sql.DataFrame?=?[age:?bigint,?name:?string]
4)結果展示
scala>?sqlDF.show
+---+--------+
|age|????name|
+---+--------+
|?18|qiaofeng|
|?19|??duanyu|
|?20|???xuzhu|
+---+--------+
?注意:普通臨時表是Session范圍內的,如果想應用范圍內有效,可以使用全局臨時表。使用全局臨時表時需要全路徑訪問,如:global_temp.people
5)對于DataFrame創(chuàng)建一個全局表
scala>?df.createGlobalTempView("people")
6)通過SQL語句實現(xiàn)查詢全表
scala>?spark.sql("SELECT?*?FROM?global_temp.people").show()
+---+--------+
|age|????name|
+---+--------+
|?18|qiaofeng|
|?19|??duanyu|
|?20|???xuzhu|
+---+--------+
scala>?spark.newSession().sql("SELECT?*?FROM?global_temp.people").show()
+---+--------+
|age|????name|
+---+--------+
|?18|qiaofeng|
|?19|??duanyu|
|?20|???xuzhu|
+---+--------+
2.3 DSL風格語法
DataFrame提供一個特定領域語言(domain-specific language, DSL)去管理結構化的數(shù)據(jù),可以在Scala, Java, Python和R中使用DSL,使用DSL語法風格不必去創(chuàng)建臨時視圖了。
1)創(chuàng)建一個DataFrame
scala>?val?df?=?spark.read.json("/opt/module/spark-local?/people.json")
df:?org.apache.spark.sql.DataFrame?=?[age:?bigint,?name:?string]
2)查看DataFrame的Schema信息
scala>?df.printSchema
root
?|--?age:?Long?(nullable?=?true)
?|--?name:?string?(nullable?=?true)
3)只查看”name”列數(shù)據(jù)
scala>?df.select("name").show()
+--------+
|????name|
+--------+
|qiaofeng|
|??duanyu|
|???xuzhu|
+--------+
4)查看所有列
scala>?df.select("*").show
+--------+---------+
|????name?|age|
+--------+---------+
|qiaofeng|???????18|
|??duanyu|???????19|
|???xuzhu|???????20|
+--------+---------+
5)查看”name”列數(shù)據(jù)以及”age+1”數(shù)據(jù)
注意:涉及到運算的時候, 每列都必須使用$
scala>?df.select($"name",$"age"?+?1).show
+--------+---------+
|????name|(age?+?1)|
+--------+---------+
|qiaofeng|???????19|
|??duanyu|???????20|
|???xuzhu|???????21|
+--------+---------+
6)查看”age”大于”19”的數(shù)據(jù)
scala>?df.filter($"age">19).show
+---+-----+
|age|?name|
+---+-----+
|?20|xuzhu|
+---+-----+
7)按照”age”分組,查看數(shù)據(jù)條數(shù)
scala>?df.groupBy("age").count.show
+---+-----+
|age|count|
+---+-----+
|?19|????1|
|?18|????1|
|?20|????1|
+---+-----+
2.4 RDD轉換為DataFrame
在 IDEA 中開發(fā)程序時,如果需要RDD 與DF 或者DS 之間互相操作,那么需要引入import spark.implicits._。
這里的spark不是Scala中的包名,而是創(chuàng)建的sparkSession 對象的變量名稱,所以必須先創(chuàng)建 SparkSession 對象再導入。這里的 spark 對象不能使用var 聲明,因為 Scala 只支持val 修飾的對象的引入。
spark-shell 中無需導入,自動完成此操作。
scala>?val?idRDD?=?sc.textFile("data/id.txt")?scala>?idRDD.toDF("id").show
+---+
|?id|
+---+
|?1|
|?2|
|?3|
|?4|
+---+
實際開發(fā)中,一般通過樣例類將RDD轉換為DataFrame。
scala>?case?class?User(name:String,?age:Int)?defined?class?User
scala>?sc.makeRDD(List(("zhangsan",30),?("lisi",40))).map(t=>User(t._1,?t._2)).toDF.show
+--------+---+
|?name|age|
+--------+---+
2.5 DataFrame轉換為RDD
DataFrame其實就是對RDD的封裝,所以可以直接獲取內部的RDD
scala>?val?df?=?sc.makeRDD(List(("zhangsan",30),?("lisi",40))).map(t=>User(t._1,?t._2)).toDF
df:?org.apache.spark.sql.DataFrame?=?[name:?string,?age:?int]
scala>?val?rdd?=?df.rdd
rdd:?org.apache.spark.rdd.RDD[org.apache.spark.sql.Row]?=?MapPartitionsRDD[46]?at?rdd?at?:25
scala>?val?array?=?rdd.collect
array:?Array[org.apache.spark.sql.Row]?=?Array([zhangsan,30],?[lisi,40])
注意:此時得到的RDD存儲類型為Row
scala>?array(0)
res28:?org.apache.spark.sql.Row?=?[zhangsan,30]?scala>?array(0)(0)
res29:?Any?=?zhangsan
scala>?array(0).getAs[String]("name")?res30:?String?=?zhangsan
3、DataSet
DataSet是具有強類型的數(shù)據(jù)集合,需要提供對應的類型信息。
3.1 創(chuàng)建DataSet
1)使用樣例類序列創(chuàng)建DataSet
scala>?case?class?Person(name:?String,?age:?Long)
defined?class?Person
scala>?val?caseClassDS?=?Seq(Person("wangyuyan",2)).toDS()
caseClassDS:?org.apache.spark.sql.Dataset[Person]?=?[name:?string,?age:?Long]
scala>?caseClassDS.show
+---------+---+
|?????name|age|
+---------+---+
|wangyuyan|??2|
+---------+---+
2)使用基本類型的序列創(chuàng)建DataSet
scala>?val?ds?=?Seq(1,2,3,4,5,6).toDS
ds:?org.apache.spark.sql.Dataset[Int]?=?[value:?int]
scala>?ds.show
+-----+
|value|
+-----+
|????1|
|????2|
|????3|
|????4|
|????5|
|????6|
+-----+
注意:在實際使用的時候,很少用到把序列轉換成DataSet,更多是通過RDD來得到DataSet。
3.2 RDD轉換為DataSet
SparkSQL能夠自動將包含有樣例類的RDD轉換成DataSet,樣例類定義了table的結構,樣例類屬性通過反射變成了表的列名。樣例類可以包含諸如Seq或者Array等復雜的結構。
1)創(chuàng)建一個RDD
scala>?val?peopleRDD?=?sc.textFile("/opt/module/spark-local/people.txt")
peopleRDD:?org.apache.spark.rdd.RDD[String]?=?/opt/module/spark-local/people.txt?MapPartitionsRDD[19]?at?textFile?at?:24
2)創(chuàng)建一個樣例類
scala>?case?class?Person(name:String,age:Int)
defined?class?Person
3)將RDD轉化為DataSet??
scala>?peopleRDD.map(line?=>?{val?fields?=?line.split(",");Person(fields(0),fields(1).?toInt)}).toDS
res0:?org.apache.spark.sql.Dataset[Person]?=?[name:?string,?age:?Long]
3.3DataSet轉換為RDD
調用rdd方法即可。
1)創(chuàng)建一個DataSet
scala>?val?DS?=?Seq(Person("zhangcuishan",?32)).toDS()
DS:?org.apache.spark.sql.Dataset[Person]?=?[name:?string,?age:?Long]
2)將DataSet轉換為RDD
scala>?DS.rdd
res1:?org.apache.spark.rdd.RDD[Person]?=?MapPartitionsRDD[6]?at?rdd?at?:28
4、DataFrame與DataSet的互操作
4.1 DataFrame轉為DataSet
1)創(chuàng)建一個DateFrame
scala>?val?df?=?spark.read.json("/opt/module/spark-local/people.json")
df:?org.apache.spark.sql.DataFrame?=?[age:?bigint,?name:?string]
2)創(chuàng)建一個樣例類
scala>?case?class?Person(name:?String,age:?Long)
defined?class?Person
3)將DataFrame轉化為DataSet
scala>?df.as[Person]
res5:?org.apache.spark.sql.Dataset[Person]?=?[age:?bigint,?name:?string]
這種方法就是在給出每一列的類型后,使用as方法,轉成Dataset,這在數(shù)據(jù)類型是DataFrame又需要針對各個字段處理時極為方便。在使用一些特殊的操作時,一定要加上 import spark.implicits._?不然toDF、toDS無法使用。
4.2Dataset轉為DataFrame
1)創(chuàng)建一個樣例類
scala>?case?class?Person(name:?String,age:?Long)
defined?class?Person
2)創(chuàng)建DataSet
scala>?val?ds?=?Seq(Person("zhangwuji",32)).toDS()
ds:?org.apache.spark.sql.Dataset[Person]?=?[name:?string,?age:?bigint]
3)將DataSet轉化為DataFrame
scala>?var?df?=?ds.toDF
df:?org.apache.spark.sql.DataFrame?=?[name:?string,?age:?bigint]
4)展示
scala>?df.show
+---------+---+
|?????name|age|
+---------+---+
|zhangwuji|?32|
+---------+---+
5、IDEA實踐
1)Maven工程添加依賴
<dependency>
?<groupId>org.apache.sparkgroupId>
?<artifactId>spark-sql_2.11artifactId>
?<version>2.1.1version>
dependency>
2)代碼實現(xiàn)
object?SparkSQL01_Demo?{
??def?main(args:?Array[String]):?Unit?=?{
????//創(chuàng)建上下文環(huán)境配置對象
????val?conf:?SparkConf?=?new?SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
????//創(chuàng)建SparkSession對象
????val?spark:?SparkSession?=?SparkSession.builder().config(conf).getOrCreate()
????//RDD=>DataFrame=>DataSet轉換需要引入隱式轉換規(guī)則,否則無法轉換
????//spark不是包名,是上下文環(huán)境對象名
????import?spark.implicits._
????//讀取json文件?創(chuàng)建DataFrame??{"username":?"lisi","age":?18}
????val?df:?DataFrame?=?spark.read.json("D:\\dev\\workspace\\spark-bak\\spark-bak-00\\input\\test.json")
????//df.show()
????//SQL風格語法
????df.createOrReplaceTempView("user")
????//spark.sql("select?avg(age)?from?user").show
????//DSL風格語法
????//df.select("username","age").show()
????//*****RDD=>DataFrame=>DataSet*****
????//RDD
????val?rdd1:?RDD[(Int,?String,?Int)]?=?spark.sparkContext.makeRDD(List((1,"qiaofeng",30),(2,"xuzhu",28),(3,"duanyu",20)))
????//DataFrame
????val?df1:?DataFrame?=?rdd1.toDF("id","name","age")
????//df1.show()
????//DateSet
????val?ds1:?Dataset[User]?=?df1.as[User]
????//ds1.show()
????//*****DataSet=>DataFrame=>RDD*****
????//DataFrame
????val?df2:?DataFrame?=?ds1.toDF()
????//RDD??返回的RDD類型為Row,里面提供的getXXX方法可以獲取字段值,類似jdbc處理結果集,但是索引從0開始
????val?rdd2:?RDD[Row]?=?df2.rdd
????//rdd2.foreach(a=>println(a.getString(1)))
????//*****RDD=>DataSe*****
????rdd1.map{
??????case?(id,name,age)=>User(id,name,age)
????}.toDS()
????//*****DataSet=>=>RDD*****
????ds1.rdd
????//釋放資源
????spark.stop()
??}
}
case?class?User(id:Int,name:String,age:Int)
Spark SQL數(shù)據(jù)的加載與保存
1、通用的加載與保存方式
1)spark.read.load是加載數(shù)據(jù)的通用方法
2)df.write.save 是保存數(shù)據(jù)的通用方法
1.1 數(shù)據(jù)加載
1)read直接加載數(shù)據(jù)
scala>?spark.read.
csv???format???jdbc???json???load???option???options???orc???parquet???schema???table???text???textFile
注意:加載數(shù)據(jù)的相關參數(shù)需寫到上述方法中,如:textFile需傳入加載數(shù)據(jù)的路徑,jdbc需傳入JDBC相關參數(shù)。
例如:直接加載Json數(shù)據(jù)
scala>?spark.read.json("/opt/module/spark-local/people.json").show
+---+--------+
|age|????name|
+---+--------+
|?18|qiaofeng|
|?19|??duanyu|
|?20|???xuzhu|
2)format指定加載數(shù)據(jù)類型
scala>?spark.read.format("…")[.option("…")].load("…")
用法詳解:
(1)format("…"):指定加載的數(shù)據(jù)類型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"
(2)load("…"):在"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"格式下需要傳入加載數(shù)據(jù)的路徑
(3)option("…"):在"jdbc"格式下需要傳入JDBC相應參數(shù),url、user、password和dbtable
例如:使用format指定加載Json類型數(shù)據(jù)
scala>?spark.read.format("json").load?("/opt/module/spark-local/people.json").show
+---+--------+
|age|????name|
+---+--------+
|?18|qiaofeng|
|?19|??duanyu|
|?20|???xuzhu|
3)在文件上直接運行SQL
前面的是使用read API先把文件加載到DataFrame然后再查詢,也可以直接在文件上進行查詢。
scala>??spark.sql("select?*?from?json.`/opt/module/spark-local/people.json`").show
+---+--------+
|age|????name|
+---+--------+
|?18|qiaofeng|
|?19|??duanyu|
|?20|???xuzhu|
+---+--------+|
說明:json表示文件的格式. 后面的文件具體路徑需要用反引號括起來。
1.2 保存數(shù)據(jù)
1)write直接保存數(shù)據(jù)
scala>?df.write.
csv??jdbc???json??orc???parquet?textFile…?…
注意:保存數(shù)據(jù)的相關參數(shù)需寫到上述方法中。如:textFile需傳入加載數(shù)據(jù)的路徑,jdbc需傳入JDBC相關參數(shù)。
例如:直接將df中數(shù)據(jù)保存到指定目錄
//默認保存格式為parquet
scala>?df.write.save("/opt/module/spark-local/output")
//可以指定為保存格式,直接保存,不需要再調用save了
scala>?df.write.json("/opt/module/spark-local/output")
2)format指定保存數(shù)據(jù)類型
scala>?df.write.format("…")[.option("…")].save("…")
用法詳解:
(1)format("…"):指定保存的數(shù)據(jù)類型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"。
(2)save ("…"):在"csv"、"orc"、"parquet"和"textFile"格式下需要傳入保存數(shù)據(jù)的路徑。
(3)option("…"):在"jdbc"格式下需要傳入JDBC相應參數(shù),url、user、password和dbtable
3)文件保存選項
保存操作可以使用 SaveMode, 用來指明如何處理數(shù)據(jù),使用mode()方法來設置。有一點很重要: 這些 SaveMode 都是沒有加鎖的, 也不是原子操作。
SaveMode是一個枚舉類,其中的常量包括:
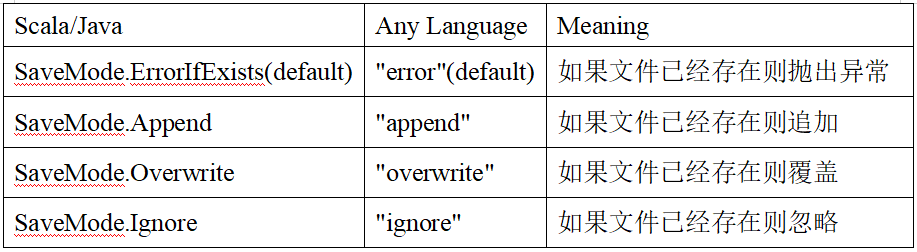
例如:使用指定format指定保存類型進行保存
df.write.mode("append").json("/opt/module/spark-local/output")??
1.3 默認數(shù)據(jù)源
Spark SQL的默認數(shù)據(jù)源為Parquet格式。數(shù)據(jù)源為Parquet文件時,Spark SQL可以方便的執(zhí)行所有的操作,不需要使用format。修改配置項spark.sql.sources.default,可修改默認數(shù)據(jù)源格式。
1)加載數(shù)據(jù)
val?df?=?spark.read.load("/opt/module/spark-local/examples/src/main/resources/users.parquet").show
+------+--------------+----------------+
|??name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa|??????????null|??[3,?9,?15,?20]|
|???Ben|???????????red|??????????????[]|
+------+--------------+----------------+
df:?Unit?=?()
2)保存數(shù)據(jù)
scala>?var?df?=?spark.read.json("/opt/module/spark-local/people.json")
//保存為parquet格式
scala>?df.write.mode("append").save("/opt/module/spark-local/output")
2、JSON文件
Spark SQL能夠自動推測JSON數(shù)據(jù)集的結構,并將它加載為一個Dataset[Row]。可以通過SparkSession.read.json()去加載一個一個JSON文件。
注意:這個JSON文件不是一個傳統(tǒng)的JSON文件,每一行都得是一個JSON串。格式如下:
{"name":"Michael"}
{"name":"Andy","age":30}
{"name":"Justin","age":19}
1)導入隱式轉換
import?spark.implicits._
2)加載JSON文件
val?path?=?"/opt/module/spark-local/people.json"
val?peopleDF?=?spark.read.json(path)
3)創(chuàng)建臨時表
peopleDF.createOrReplaceTempView("people")
4)數(shù)據(jù)查詢
val?teenagerNamesDF?=?spark.sql("SELECT?name?FROM?people?WHERE?age?BETWEEN?13?AND?19")
teenagerNamesDF.show()
+------+
|??name|
+------+
|Justin|
+------+
3、MySQL
Spark SQL可以通過JDBC從關系型數(shù)據(jù)庫中讀取數(shù)據(jù)的方式創(chuàng)建DataFrame,通過對DataFrame一系列的計算后,還可以將數(shù)據(jù)再寫回關系型數(shù)據(jù)庫中。
**如果使用spark-shell操作,可在啟動shell時指定相關的數(shù)據(jù)庫驅動路徑或者將相關的數(shù)據(jù)庫驅動放到spark的類路徑下。**
bin/spark-shell?
--jars?mysql-connector-java-5.1.27-bin.jar
這里演示在Idea中通過JDBC對Mysql進行操作
3.1 導入依賴
<dependency>
????<groupId>mysqlgroupId>
????<artifactId>mysql-connector-javaartifactId>
????<version>5.1.27version>
dependency>
3.2 從JDBC讀數(shù)據(jù)
object?SparkSQL02_Datasource?{
??def?main(args:?Array[String]):?Unit?=?{
????//創(chuàng)建上下文環(huán)境配置對象
????val?conf:?SparkConf?=?new?SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
????//創(chuàng)建SparkSession對象
????val?spark:?SparkSession?=?SparkSession.builder().config(conf).getOrCreate()
????import?spark.implicits._
????//方式1:通用的load方法讀取
????spark.read.format("jdbc")
??????.option("url",?"jdbc:mysql://hadoop202:3306/test")
??????.option("driver",?"com.mysql.jdbc.Driver")
??????.option("user",?"root")
??????.option("password",?"123456")
??????.option("dbtable",?"user")
??????.load().show
????
????//方式2:通用的load方法讀取?參數(shù)另一種形式
????spark.read.format("jdbc")
??????.options(Map("url"->"jdbc:mysql://hadoop202:3306/test?user=root&password=123456",
????????"dbtable"->"user","driver"->"com.mysql.jdbc.Driver")).load().show
????//方式3:使用jdbc方法讀取
????val?props:?Properties?=?new?Properties()
????props.setProperty("user",?"root")
????props.setProperty("password",?"123456")
????val?df:?DataFrame?=?spark.read.jdbc("jdbc:mysql://hadoop202:3306/test",?"user",?props)
????df.show
????//釋放資源
????spark.stop()
??}
}
3.3 向JDBC寫數(shù)據(jù)
object?SparkSQL03_Datasource?{
??def?main(args:?Array[String]):?Unit?=?{
????//創(chuàng)建上下文環(huán)境配置對象
????val?conf:?SparkConf?=?new?SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
????//創(chuàng)建SparkSession對象
????val?spark:?SparkSession?=?SparkSession.builder().config(conf).getOrCreate()
????import?spark.implicits._
????val?rdd:?RDD[User2]?=?spark.sparkContext.makeRDD(List(User2("lisi",?20),?User2("zs",?30)))
????val?ds:?Dataset[User2]?=?rdd.toDS
????//方式1:通用的方式? format指定寫出類型
????ds.write
??????.format("jdbc")
??????.option("url",?"jdbc:mysql://hadoop202:3306/test")
??????.option("user",?"root")
??????.option("password",?"123456")
??????.option("dbtable",?"user")
??????.mode(SaveMode.Append)
??????.save()
????//方式2:通過jdbc方法
????val?props:?Properties?=?new?Properties()
????props.setProperty("user",?"root")
????props.setProperty("password",?"123456")
????ds.write.mode(SaveMode.Append).jdbc("jdbc:mysql://hadoop202:3306/test",?"user",?props)
????//釋放資源
????spark.stop()
??}
}
case?class?User2(name:?String,?age:?Long)
4、Hive
Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL編譯時可以包含 Hive 支持,也可以不包含。
包含 Hive 支持的 Spark SQL 可以支持 Hive 表訪問、UDF (用戶自定義函數(shù))以及 Hive 查詢語言(HiveQL/HQL)等。需要強調的一點是,如果要在 Spark SQL 中包含Hive 的庫,并不需要事先安裝 Hive。一般來說,最好還是在編譯Spark SQL時引入Hive支持,這樣就可以使用這些特性了。如果你下載的是二進制版本的 Spark,它應該已經(jīng)在編譯時添加了 Hive 支持。
若要把 Spark SQL 連接到一個部署好的 Hive 上,你必須把 hive-site.xml 復制到 Spark的配置文件目錄中($SPARK_HOME/conf)。即使沒有部署好 Hive,Spark SQL 也可以運行,需要注意的是,如果你沒有部署好Hive,Spark SQL 會在當前的工作目錄中創(chuàng)建出自己的 Hive 元數(shù)據(jù)倉庫,叫作 metastore_db。此外,對于使用部署好的Hive,如果你嘗試使用 HiveQL 中的 CREATE TABLE (并非 CREATE EXTERNAL TABLE)語句來創(chuàng)建表,這些表會被放在你默認的文件系統(tǒng)中的 /user/hive/warehouse 目錄中(如果你的 classpath 中有配好的 hdfs-site.xml,默認的文件系統(tǒng)就是 HDFS,否則就是本地文件系統(tǒng))。
spark-shell默認是Hive支持的;代碼中是默認不支持的,需要手動指定(加一個參數(shù)即可)。
4.1 使用內嵌Hive
如果使用 Spark 內嵌的 Hive, 則什么都不用做, 直接使用即可。
Hive 的元數(shù)據(jù)存儲在 derby 中, 倉庫地址:$SPARK_HOME/spark-warehouse。
scala>?spark.sql("show?tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
+--------+---------+-----------+
scala>?spark.sql("create?table?aa(id?int)")
19/02/09?18:36:10?WARN?HiveMetaStore:?Location:?file:/opt/module/spark-local/spark-warehouse/aa?specified?for?non-external?table:aa
res2:?org.apache.spark.sql.DataFrame?=?[]
scala>?spark.sql("show?tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
|?default|???????aa|??????false|
+--------+---------+-----------+
向表中加載本地數(shù)據(jù)數(shù)據(jù)
scala>?spark.sql("load?data?local?inpath?'./ids.txt'?into?table?aa")
res8:?org.apache.spark.sql.DataFrame?=?[]
scala>?spark.sql("select?*?from?aa").show
+---+
|?id|
+---+
|100|
|101|
|102|
|103|
|104|
|105|
|106|
+---+
在實際使用中, 幾乎沒有任何人會使用內置的 Hive。
4.2 外部Hive應用
如果Spark要接管Hive外部已經(jīng)部署好的Hive,需要通過以下幾個步驟。
(1)確定原有Hive是正常工作的
(2)需要把hive-site.xml拷貝到spark的conf/目錄下
(3)如果以前hive-site.xml文件中,配置過Tez相關信息,注釋掉
(4)把Mysql的驅動copy到Spark的jars/目錄下
(5)需要提前啟動hive服務,hive/bin/hiveservices.sh start
(6)如果訪問不到hdfs,則需把core-site.xml和hdfs-site.xml拷貝到conf/目錄
啟動 spark-shell
scala>?spark.sql("show?tables").show
+--------+---------+-----------+
|database|tableName|isTemporary|
+--------+---------+-----------+
|?default|??????emp|??????false|
+--------+---------+-----------+
scala>?spark.sql("select?*?from?emp").show
19/02/09?19:40:28?WARN?LazyStruct:?Extra?bytes?detected?at?the?end?of?the?row!?Ignoring?similar?problems.
+-----+-------+---------+----+----------+------+------+------+
|empno|??ename|??????job|?mgr|??hiredate|???sal|??comm|deptno|
+-----+-------+---------+----+----------+------+------+------+
|?7369|??SMITH|????CLERK|7902|1980-12-17|?800.0|??null|????20|
|?7499|??ALLEN|?SALESMAN|7698|?1981-2-20|1600.0|?300.0|????30|
|?7521|???WARD|?SALESMAN|7698|?1981-2-22|1250.0|?500.0|????30|
|?7566|??JONES|??MANAGER|7839|??1981-4-2|2975.0|??null|????20|
|?7654|?MARTIN|?SALESMAN|7698|?1981-9-28|1250.0|1400.0|????30|
|?7698|??BLAKE|??MANAGER|7839|??1981-5-1|2850.0|??null|????30|
|?7782|??CLARK|??MANAGER|7839|??1981-6-9|2450.0|??null|????10|
|?7788|??SCOTT|??ANALYST|7566|?1987-4-19|3000.0|??null|????20|
|?7839|???KING|PRESIDENT|null|1981-11-17|5000.0|??null|????10|
|?7844|?TURNER|?SALESMAN|7698|??1981-9-8|1500.0|???0.0|????30|
|?7876|??ADAMS|????CLERK|7788|?1987-5-23|1100.0|??null|????20|
|?7900|??JAMES|????CLERK|7698|?1981-12-3|?950.0|??null|????30|
|?7902|???FORD|??ANALYST|7566|?1981-12-3|3000.0|??null|????20|
|?7934|?MILLER|????CLERK|7782|?1982-1-23|1300.0|??null|????10|
|?7944|zhiling|????CLERK|7782|?1982-1-23|1300.0|??null|????50|
+-----+-------+---------+----+----------+------+------+------+
4.3 運行Spark SQL CLI
Spark SQLCLI可以很方便的在本地運行Hive元數(shù)據(jù)服務以及從命令行執(zhí)行查詢任務。在Spark目錄下執(zhí)行如下命令啟動Spark SQ LCLI,直接執(zhí)行SQL語句,類似Hive窗口。
bin/spark-sql
4.4 代碼中操作Hive
1)添加依賴
<dependency>
????<groupId>org.apache.sparkgroupId>
????<artifactId>spark-hive_2.11artifactId>
????<version>2.1.1version>
dependency>
<dependency>
????<groupId>org.apache.hivegroupId>
????<artifactId>hive-execartifactId>
????<version>1.2.1version>
dependency>
2)拷貝hive-site.xml到resources目錄
3)代碼實現(xiàn)
object?SparkSQL08_Hive{
?def?main(args:?Array[String]):?Unit?=?{
????//創(chuàng)建上下文環(huán)境配置對象
????val?conf:?SparkConf?=?new?SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
????val?spark:?SparkSession?=?SparkSession
??????.builder()
??????.enableHiveSupport()
??????.master("local[*]")
??????.appName("SQLTest")
??????.getOrCreate()
????spark.sql("show?tables").show()
????//釋放資源
????spark.stop()
??}
}
Spark SQL實戰(zhàn)
1、數(shù)據(jù)準備
Spark-sql操作所有的數(shù)據(jù)均來自Hive,首先在Hive中創(chuàng)建表,并導入數(shù)據(jù)。一共有3張表:1張用戶行為表,1張城市表,1張產(chǎn)品表。
CREATE?TABLE?`user_visit_action`(
??`date`?string,
??`user_id`?bigint,
??`session_id`?string,
??`page_id`?bigint,
??`action_time`?string,
??`search_keyword`?string,
??`click_category_id`?bigint,
??`click_product_id`?bigint,
??`order_category_ids`?string,
??`order_product_ids`?string,
??`pay_category_ids`?string,
??`pay_product_ids`?string,
??`city_id`?bigint)
row?format?delimited?fields?terminated?by?'\t';
load?data?local?inpath?'/opt/module/data/user_visit_action.txt'?into?table?sparkpractice.user_visit_action;
CREATE?TABLE?`product_info`(
??`product_id`?bigint,
??`product_name`?string,
??`extend_info`?string)
row?format?delimited?fields?terminated?by?'\t';
load?data?local?inpath?'/opt/module/data/product_info.txt'?into?table?sparkpractice.product_info;
CREATE?TABLE?`city_info`(
??`city_id`?bigint,
??`city_name`?string,
??`area`?string)
row?format?delimited?fields?terminated?by?'\t';
load?data?local?inpath?'/opt/module/data/city_info.txt'?into?table?sparkpractice.city_info;
2、需求
2.1 需求簡介
這里的熱門商品是從點擊量的維度來看的,計算各個區(qū)域前三大熱門商品,并備注上每個商品在主要城市中的分布比例,超過兩個城市用其他顯示。
例如:
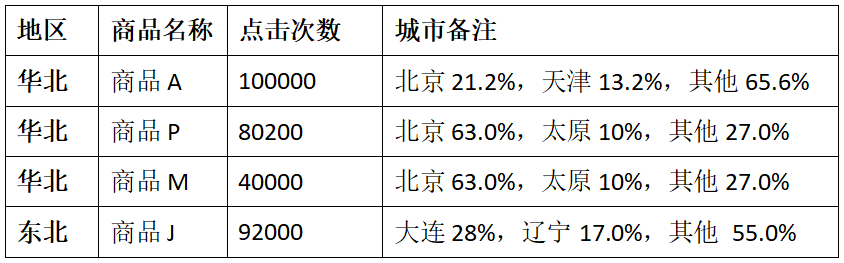
2.2 思路分析
1)使用sql來完成,碰到復雜的需求,可以使用udf或udaf
2)查詢出來所有的點擊記錄,并與city_info表連接,得到每個城市所在的地區(qū),與Product_info表連接得到產(chǎn)品名稱
3)按照地區(qū)和商品名稱分組,統(tǒng)計出每個商品在每個地區(qū)的總點擊次數(shù)
4)每個地區(qū)內按照點擊次數(shù)降序排列
5)只取前三名,并把結果保存在數(shù)據(jù)庫中
6)城市備注需要自定義UDAF函數(shù)
2.3 代碼實現(xiàn)
1)UDAF函數(shù)定義
class?AreaClickUDAF?extends?UserDefinedAggregateFunction?{
??//?輸入數(shù)據(jù)的類型:??北京??String
??override?def?inputSchema:?StructType?=?{
????StructType(StructField("city_name",?StringType)?::?Nil)
????//????????StructType(Array(StructField("city_name",?StringType)))
??}
??//?緩存的數(shù)據(jù)的類型:?北京->1000,?天津->5000??Map,??總的點擊量??1000/?
??override?def?bufferSchema:?StructType?=?{
????//?MapType(StringType,?LongType)?還需要標注?map的key的類型和value的類型
????StructType(StructField("city_count",?MapType(StringType,?LongType))?::?StructField("total_count",?LongType)?::?Nil)
??}
??//?輸出的數(shù)據(jù)類型??"北京21.2%,天津13.2%,其他65.6%"??String
??override?def?dataType:?DataType?=?StringType
??//?相同的輸入是否應用有相同的輸出.
??override?def?deterministic:?Boolean?=?true
??//?給存儲數(shù)據(jù)初始化
??override?def?initialize(buffer:?MutableAggregationBuffer):?Unit?=?{
????//初始化map緩存
????buffer(0)?=?Map[String,?Long]()
????//?初始化總的點擊量
????buffer(1)?=?0L
??}
??//?分區(qū)內合并?Map[城市名,?點擊量]
??override?def?update(buffer:?MutableAggregationBuffer,?input:?Row):?Unit?=?{
????//?首先拿到城市名,?然后把城市名作為key去查看map中是否存在,?如果存在就把對應的值?+1,?如果不存在,?則直接0+1
????val?cityName?=?input.getString(0)
????//????????val?map:?collection.Map[String,?Long]?=?buffer.getMap[String,?Long](0)
????val?map:?Map[String,?Long]?=?buffer.getAs[Map[String,?Long]](0)
????buffer(0)?=?map?+?(cityName?->?(map.getOrElse(cityName,?0L)?+?1L))
????//?碰到一個城市,?則總的點擊量要+1
????buffer(1)?=?buffer.getLong(1)?+?1L
??}
??//?分區(qū)間的合并
??override?def?merge(buffer1:?MutableAggregationBuffer,?buffer2:?Row):?Unit?=?{
????val?map1?=?buffer1.getAs[Map[String,?Long]](0)
????val?map2?=?buffer2.getAs[Map[String,?Long]](0)
????//?把map1的鍵值對與map2中的累積,?最后賦值給buffer1
????buffer1(0)?=?map1.foldLeft(map2)?{
??????case?(map,?(k,?v))?=>
????????map?+?(k?->?(map.getOrElse(k,?0L)?+?v))
????}
????buffer1(1)?=?buffer1.getLong(1)?+?buffer2.getLong(1)
??}
??//?最終的輸出.?"北京21.2%,天津13.2%,其他65.6%"
??override?def?evaluate(buffer:?Row):?Any?=?{
????val?cityCountMap?=?buffer.getAs[Map[String,?Long]](0)
????val?totalCount?=?buffer.getLong(1)
????var?citysRatio:?List[CityRemark]?=?cityCountMap.toList.sortBy(-_._2).take(2).map?{
??????case?(cityName,?count)?=>?{
????????CityRemark(cityName,?count.toDouble?/?totalCount)
??????}
????}
????//?如果城市的個數(shù)超過2才顯示其他
????if?(cityCountMap.size?>?2)?{
??????citysRatio?=?citysRatio?:+?CityRemark("其他",?citysRatio.foldLeft(1D)(_?-?_.cityRatio))
????}
????citysRatio.mkString(",?")
??}
}
case?class?CityRemark(cityName:?String,?cityRatio:?Double)?{
??val?formatter?=?new?DecimalFormat("0.00%")
??override?def?toString:?String?=?s"$cityName:${formatter.format(cityRatio)}"
}
2)具體實現(xiàn)
object?SparkSQL04_TopN?{
??def?main(args:?Array[String]):?Unit?=?{
????val?spark:?SparkSession?=?SparkSession
??????.builder()
??????.master("local[2]")
??????.appName("AreaClickApp")
??????.enableHiveSupport()
??????.getOrCreate()
????spark.sql("use?sparkpractice")
????//?0?注冊自定義聚合函數(shù)
????spark.udf.register("city_remark",?new?AreaClickUDAF)
????//?1.?查詢出所有的點擊記錄,并和城市表產(chǎn)品表做內連接
????spark.sql(
??????"""
????????|select
????????|????c.*,
????????|????v.click_product_id,
????????|????p.product_name
????????|from?user_visit_action?v?join?city_info?c?join?product_info?p?on?v.city_id=c.city_id?and?v.click_product_id=p.product_id
????????|where?click_product_id>-1
??????""".stripMargin).createOrReplaceTempView("t1")
????//?2.?計算每個區(qū)域,?每個產(chǎn)品的點擊量
????spark.sql(
??????"""
????????|select
????????|????t1.area,
????????|????t1.product_name,
????????|????count(*)?click_count,
????????|????city_remark(t1.city_name)
????????|from?t1
????????|group?by?t1.area,?t1.product_name
??????""".stripMargin).createOrReplaceTempView("t2")
????//?3.?對每個區(qū)域內產(chǎn)品的點擊量進行倒序排列
????spark.sql(
??????"""
????????|select
????????|????*,
????????|????rank()?over(partition?by?t2.area?order?by?t2.click_count?desc)?rank
????????|from?t2
??????""".stripMargin).createOrReplaceTempView("t3")
????//?4.?每個區(qū)域取top3
????spark.sql(
??????"""
????????|select
????????|????*
????????|from?t3
????????|where?rank<=3
??????""".stripMargin).show
????//釋放資源
????spark.stop()
??}
}
知識星球
歡迎加入我的知識星球,提供技術答疑,資料分享,模擬面試等服務。識別下方二維碼或者點擊閱讀原文,都可以加入。
猜你喜歡
Hive計算最大連續(xù)登陸天數(shù)
Hadoop 數(shù)據(jù)遷移用法詳解
Hbase修復工具Hbck
數(shù)倉建模分層理論
一文搞懂Hive的數(shù)據(jù)存儲與壓縮
大數(shù)據(jù)組件重點學習這幾個