
oppo后端16連問(wèn)
前言
大家好,我是程序員田螺。最近有位讀者去面試了oppo,給大家整理了面試真題的答案。希望對(duì)大家有幫助哈,一起學(xué)習(xí),一起進(jìn)步。
聊聊你印象最深刻的項(xiàng)目,或者做了什么優(yōu)化。 你項(xiàng)目提到分布式鎖,你們是怎么使用分布式鎖的? 常見(jiàn)分布式事務(wù)解決方案 你們的接口冪等是如何保證的? 你們的MySQL架構(gòu)是怎樣的? 常見(jiàn)的索引結(jié)構(gòu)有?哈希表結(jié)構(gòu)屬于哪種場(chǎng)景? 給你ab,ac,abc字段,你是如何加索引的? 數(shù)據(jù)庫(kù)隔離級(jí)別是否了解?你們的數(shù)據(jù)庫(kù)默認(rèn)隔離級(jí)別是?為什么選它? RR隔離級(jí)別實(shí)現(xiàn)原理,它是如何解決不可重復(fù)讀的? 你們項(xiàng)目使用了RocketMQ對(duì)吧?那你知道如何保證消息不丟失嗎? 事務(wù)消息是否了解?場(chǎng)景題:比如下單清空購(gòu)物車(chē),你是如何設(shè)計(jì)的? 如何快速判斷一個(gè)數(shù)是奇數(shù)還是偶數(shù),除開(kāi)對(duì)2取余呢。 Spring聲明式事務(wù)原理?哪些場(chǎng)景事務(wù)會(huì)失效? 你們是微服務(wù)架構(gòu)嘛?如果你來(lái)設(shè)計(jì)一個(gè)類(lèi)似淘寶的系統(tǒng),你怎么劃分微服務(wù)? 你們是怎么分庫(kù)分表的?分布式ID如何生成? 所有異常的共同祖先是?運(yùn)行時(shí)異常有哪幾個(gè)?
1. 聊聊你印象最深刻的項(xiàng)目,或者做了什么優(yōu)化。
大家平時(shí)做的項(xiàng)目,如果很多知識(shí)點(diǎn)跟面試八股文相關(guān)的話(huà),就可以相對(duì)條理清晰地寫(xiě)到簡(jiǎn)歷去。
比如緩存數(shù)據(jù)庫(kù)相關(guān)的,查詢(xún)?yōu)榭眨阍O(shè)置了一個(gè)
-1到緩存,代表數(shù)據(jù)庫(kù)沒(méi)記錄。下次判斷-1,就不查庫(kù)了,以解決緩存穿透問(wèn)題。又比如你設(shè)置緩存過(guò)期時(shí)間比較分散,解決緩存擊穿問(wèn)題,都可以條理清晰寫(xiě)到簡(jiǎn)歷去,這樣面試官很可能會(huì)問(wèn)你相關(guān)的問(wèn)題,這時(shí)候就對(duì)答如流啦。
還有平時(shí)你做的項(xiàng)目,有一些比較好的設(shè)計(jì),都可以說(shuō)一下哈,比如你是如何保證數(shù)據(jù)一致性的,怎么優(yōu)化接口性能的。
如果是講優(yōu)化接口這一塊的話(huà),你可以看下我這篇文章哈:記一次接口性能優(yōu)化實(shí)踐總結(jié):優(yōu)化接口性能的八個(gè)建議,結(jié)合來(lái)一起講。其實(shí)就是緩存、分批、并發(fā)調(diào)用、異步等那幾個(gè)關(guān)鍵知識(shí)點(diǎn)。
如果是代碼優(yōu)化細(xì)節(jié),可以結(jié)合我這篇:工作四年,分享50個(gè)讓你代碼更好的小建議。你可以挑個(gè)簡(jiǎn)單的來(lái)講,比如復(fù)雜的if邏輯條件,可以調(diào)整順序,讓程序更高效,這樣會(huì)讓面試官眼前一亮哦。
如果是慢SQL優(yōu)化這一塊,可以看下我之前MySQL專(zhuān)欄系列文章,理解透之后,還是挺穩(wěn)的:
看一遍就理解:order by詳解 看一遍就理解:group by詳解 實(shí)戰(zhàn)!聊聊如何解決MySQL深分頁(yè)問(wèn)題 后端程序員必備:書(shū)寫(xiě)高質(zhì)量SQL的30條建議 阿里一面,給了幾條SQL,問(wèn)需要執(zhí)行幾次樹(shù)搜索操作? 生產(chǎn)問(wèn)題分析!delete in子查詢(xún)不走索引?! 面試官問(wèn)如何優(yōu)化慢SQL?
2. 你項(xiàng)目提到分布式鎖,你們是怎么使用分布式鎖的?
一般你講述你做的項(xiàng)目時(shí),面試官會(huì)根據(jù)你項(xiàng)目涉及的一些面試點(diǎn),然后抽他感興趣的一兩個(gè)來(lái)問(wèn)。所以大家對(duì)哪些知識(shí)點(diǎn)熟悉,講述項(xiàng)目時(shí),就說(shuō)你用該知識(shí)點(diǎn),解決了什么問(wèn)題。
比如,你看了田螺哥的 《七種方案!探討Redis分布式鎖的正確使用姿勢(shì)》,很熟悉,就可以說(shuō)用分布式鎖解決了超賣(mài)問(wèn)題什么的。 如果你看了田螺哥的《美團(tuán)二面:Redis與MySQL雙寫(xiě)一致性如何保證?》,你就可以說(shuō)你是用什么方案保證緩存和數(shù)據(jù)庫(kù)一致性的。
3. 常見(jiàn)分布式事務(wù)解決方案
分布式事務(wù):就是指事務(wù)的參與者、支持事務(wù)的服務(wù)器、資源服務(wù)器以及事務(wù)管理器分別位于不同的分布式系統(tǒng)的不同節(jié)點(diǎn)之上。簡(jiǎn)單來(lái)說(shuō),分布式事務(wù)指的就是分布式系統(tǒng)中的事務(wù),它的存在就是為了保證不同數(shù)據(jù)庫(kù)節(jié)點(diǎn)的數(shù)據(jù)一致性。
聊到分布式事務(wù),大家記得這兩個(gè)理論哈:CAP理論 和 BASE 理論
分布式事務(wù)的幾種解決方案:
2PC(二階段提交)方案、3PC TCC(Try、Confirm、Cancel) 本地消息表 最大努力通知 seata
2PC(二階段提交)方案
2PC,即兩階段提交,它將分布式事務(wù)的提交拆分為2個(gè)階段:prepare和commit/rollback,即準(zhǔn)備階段和提交執(zhí)行階段。在prepare準(zhǔn)備階段需要等待所有參與子事務(wù)的反饋,因此可能造成數(shù)據(jù)庫(kù)資源鎖定時(shí)間過(guò)長(zhǎng),不適合并發(fā)高以及子事務(wù)生命周長(zhǎng)較長(zhǎng)的業(yè)務(wù)場(chǎng)景。并且協(xié)調(diào)者宕機(jī)的話(huà),所有的參與者都收不到提交或回滾指令。
3PC
兩階段提交分別是:CanCommit,PreCommit 和 doCommit,這里不再詳述。3PC 利用超時(shí)機(jī)制解決了 2PC 的同步阻塞問(wèn)題,避免資源被永久鎖定,進(jìn)一步加強(qiáng)了整個(gè)事務(wù)過(guò)程的可靠性。但是 3PC 同樣無(wú)法應(yīng)對(duì)類(lèi)似的宕機(jī)問(wèn)題,只不過(guò)出現(xiàn)多數(shù)據(jù)源中數(shù)據(jù)不一致問(wèn)題的概率更小。
TCC
TCC 采用了補(bǔ)償機(jī)制,其核心思想是:針對(duì)每個(gè)操作,都要注冊(cè)一個(gè)與其對(duì)應(yīng)的確認(rèn)和補(bǔ)償(撤銷(xiāo))操作。它分為三個(gè)階段:Try-Confirm-Cancel
try階段:嘗試去執(zhí)行,完成所有業(yè)務(wù)的一致性檢查,預(yù)留必須的業(yè)務(wù)資源。 Confirm階段:該階段對(duì)業(yè)務(wù)進(jìn)行確認(rèn)提交,不做任何檢查,因?yàn)閠ry階段已經(jīng)檢查過(guò)了,默認(rèn)Confirm階段是不會(huì)出錯(cuò)的。 Cancel 階段:若業(yè)務(wù)執(zhí)行失敗,則進(jìn)入該階段,它會(huì)釋放try階段占用的所有業(yè)務(wù)資源,并回滾Confirm階段執(zhí)行的所有操作。
TCC方案讓?xiě)?yīng)用可以自定義數(shù)據(jù)庫(kù)操作的粒度,降低了鎖沖突,可以提升性能。但是應(yīng)用侵入性強(qiáng),try、confirm、cancel三個(gè)階段都需要業(yè)務(wù)邏輯實(shí)現(xiàn)。
本地消息表
ebay最初提出本地消息表這個(gè)方案,來(lái)解決分布式事務(wù)問(wèn)題。業(yè)界目前使用這種方案是比較多的,它的核心思想就是將分布式事務(wù)拆分成本地事務(wù)進(jìn)行處理。可以看一下基本的實(shí)現(xiàn)流程圖:
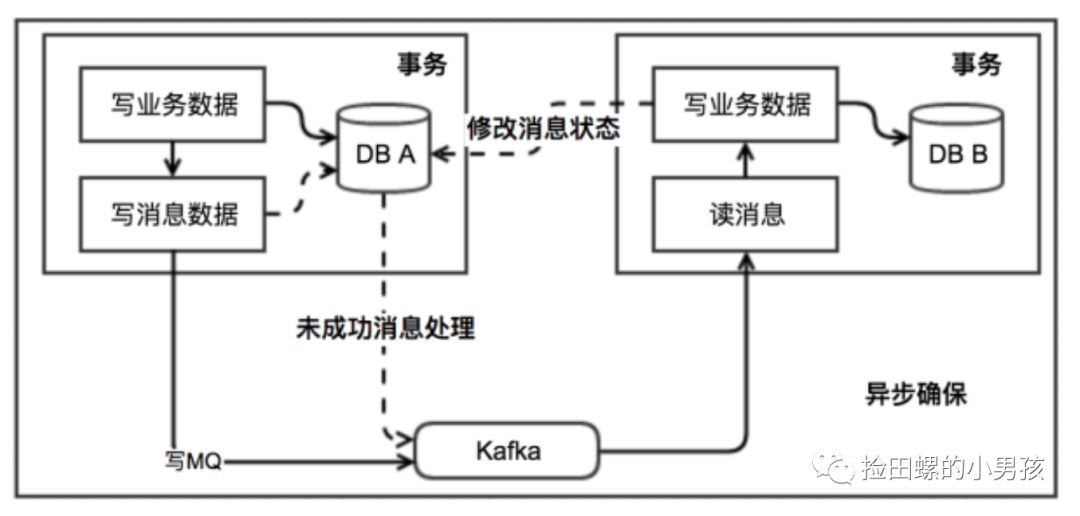
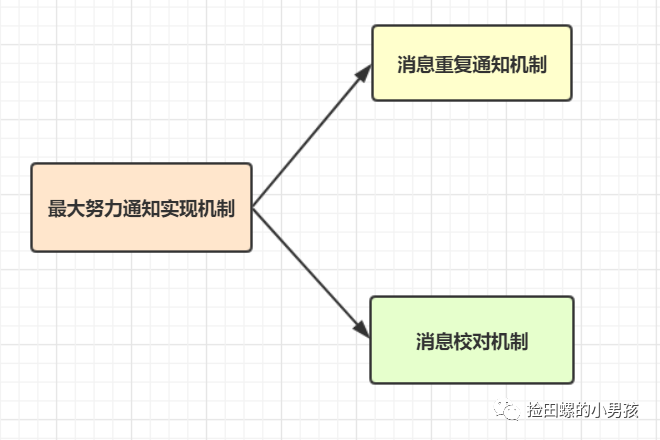
最大努力通知
最大努力通知方案的目標(biāo),就是發(fā)起通知方通過(guò)一定的機(jī)制,最大努力將業(yè)務(wù)處理結(jié)果通知到接收方。
seata
Saga 模式是 Seata 提供的長(zhǎng)事務(wù)解決方案。核心思想是將長(zhǎng)事務(wù)拆分為多個(gè)本地短事務(wù),由Saga事務(wù)協(xié)調(diào)器協(xié)調(diào),如果正常結(jié)束那就正常完成,如果某個(gè)步驟失敗,則根據(jù)相反順序一次調(diào)用補(bǔ)償操作。
Saga的并發(fā)度高,但是一致性弱,對(duì)于轉(zhuǎn)賬,可能發(fā)生用戶(hù)已扣款,最后轉(zhuǎn)賬又失敗的情況。
整理了這幾篇分布式事務(wù)文章,大家可以看看哈:
4. 你們的接口冪等是如何保證的?
如果你調(diào)用下游接口超時(shí)了,是不是考慮重試?如果重試,下游接口就需要支持冪等啦。
實(shí)現(xiàn)冪等一般有這8種方案:
select+insert+主鍵/唯一索引沖突 直接insert + 主鍵/唯一索引沖突 狀態(tài)機(jī)冪等 抽取防重表 token令牌 悲觀鎖(如select for update,很少用) 樂(lè)觀鎖 分布式鎖
大家平時(shí)是用哪個(gè)方案解決冪等的,最后結(jié)合工作實(shí)際講講哈。可以看下我之前這篇文章: 聊聊冪等設(shè)計(jì)
5. 你們的mySQL架構(gòu)是怎樣的?
大家可以結(jié)合自己公司的MySQL架構(gòu)聊聊。如果不是很清楚的話(huà),可以結(jié)合我之前寫(xiě)的來(lái)看看哈:面試必備:聊聊MySQL的主從
數(shù)據(jù)的庫(kù)高可用方案
雙機(jī)主備 一主一從 一主多從 MariaDB同步多主機(jī) 數(shù)據(jù)庫(kù)中間件
5.1 雙機(jī)主備
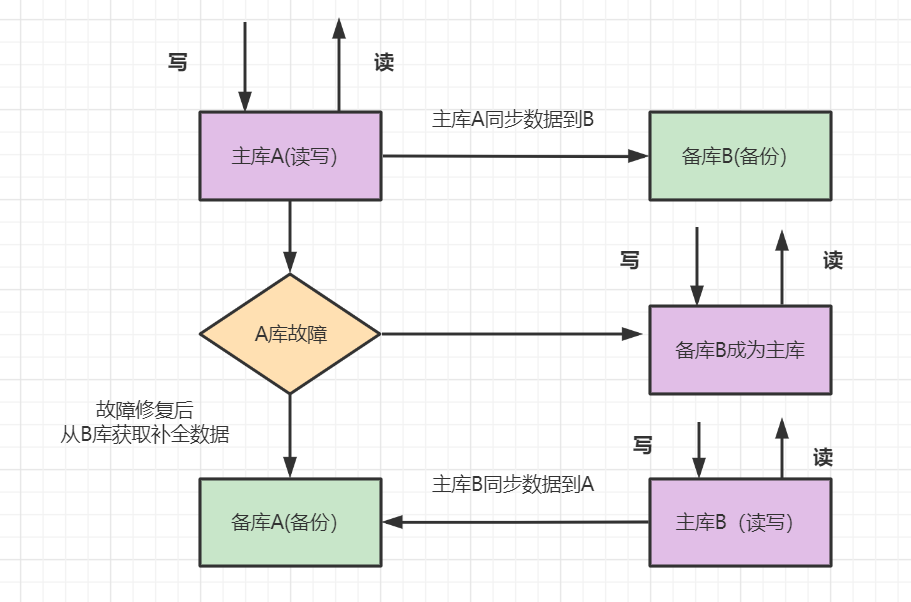
優(yōu)點(diǎn):一個(gè)機(jī)器故障了可以自動(dòng)切換,操作比較簡(jiǎn)單。 缺點(diǎn):只有一個(gè)庫(kù)在工作,讀寫(xiě)壓力大,未能實(shí)現(xiàn)讀寫(xiě)分離,并發(fā)也有一定限制
5.2 一主一從
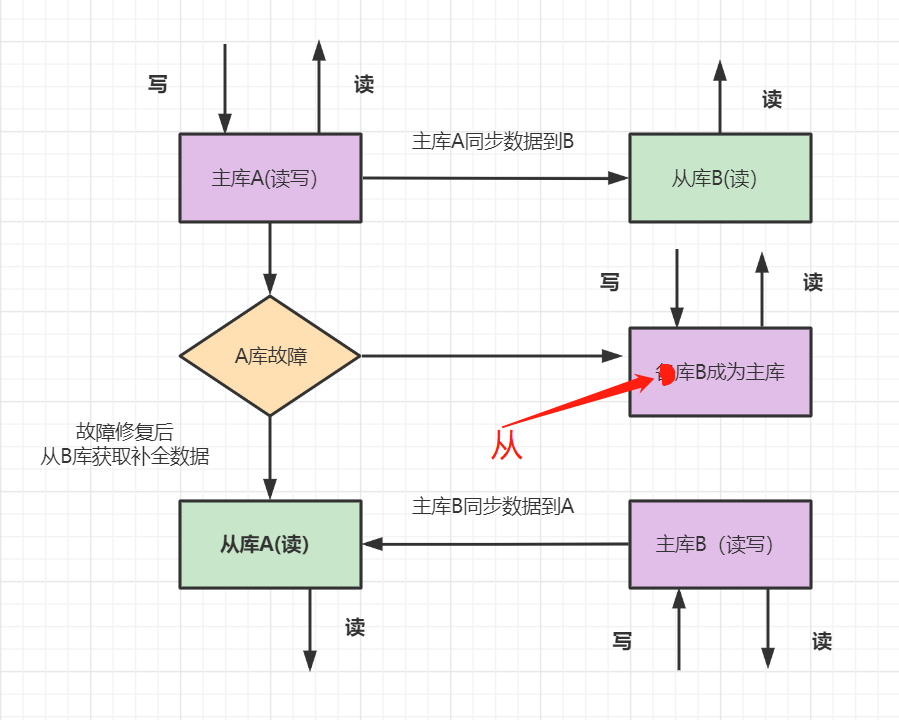
優(yōu)點(diǎn):從庫(kù)支持讀,分擔(dān)了主庫(kù)的壓力,提升了并發(fā)度。一個(gè)機(jī)器故障了可以自動(dòng)切換,操作比較簡(jiǎn)單。 缺點(diǎn):一臺(tái)從庫(kù),并發(fā)支持還是不夠,并且一共兩臺(tái)機(jī)器,還是存在同時(shí)故障的機(jī)率,不夠高可用。
5.3 一主多從

優(yōu)點(diǎn):多個(gè)從庫(kù)支持讀,分擔(dān)了主庫(kù)的壓力,明顯提升了讀的并發(fā)度。 缺點(diǎn):只有一臺(tái)主機(jī)寫(xiě),因此寫(xiě)的并發(fā)度不高
5.4 MariaDB同步多主機(jī)集群
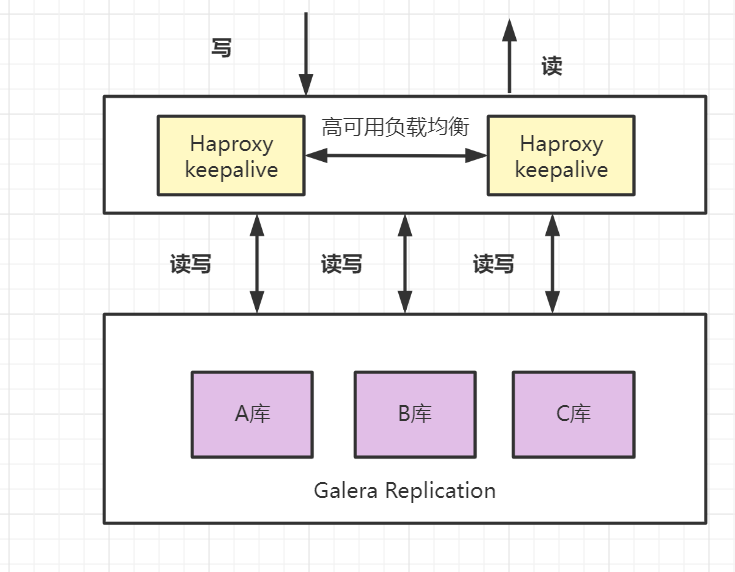
有代理層實(shí)現(xiàn)負(fù)載均衡,多個(gè)數(shù)據(jù)庫(kù)可以同時(shí)進(jìn)行讀寫(xiě)操作;各個(gè)數(shù)據(jù)庫(kù)之間可以通過(guò)Galera Replication方法進(jìn)行數(shù)據(jù)同步,每個(gè)庫(kù)理論上數(shù)據(jù)是完全一致的。 優(yōu)點(diǎn):讀寫(xiě)的并發(fā)度都明顯提升,可以任意節(jié)點(diǎn)讀寫(xiě),可以自動(dòng)剔除故障節(jié)點(diǎn),具有較高的可靠性。 缺點(diǎn):數(shù)據(jù)量不支持特別大。要避免大事務(wù)卡死,如果集群節(jié)點(diǎn)一個(gè)變慢,其他節(jié)點(diǎn)也會(huì)跟著變慢。
5.5 數(shù)據(jù)庫(kù)中間件

mycat分片存儲(chǔ),每個(gè)分片配置一主多從的集群。 優(yōu)點(diǎn):解決高并發(fā)高數(shù)據(jù)量的高可用方案 缺點(diǎn):維護(hù)成本比較大。
大家有興趣可以看看我這篇文章哈:面試必備:聊聊MySQL的主從
6. 常見(jiàn)的索引結(jié)構(gòu)有?哈希表結(jié)構(gòu)屬于哪種場(chǎng)景?
哈希表、有序數(shù)組和搜索樹(shù)。
哈希表這種結(jié)構(gòu)適用于只有等值查詢(xún)的場(chǎng)景 有序數(shù)組適合范圍查詢(xún),用二分法快速得到,時(shí)間復(fù)雜度為 O(log(N))。查詢(xún)還好,如果是插入,就得挪動(dòng)后面所有的記錄,成本太高。因此它一般只適用靜態(tài)存儲(chǔ)引擎,比如保存2018年某個(gè)城市的所有人口信息。 B+樹(shù)適合范圍查詢(xún),我們一般建的索引結(jié)構(gòu)都是B+樹(shù)。
7.給你ab,ac,abc字段,你是如何加索引的?
這主要考察聯(lián)合索引的最左前綴原則知識(shí)點(diǎn)。
這個(gè)最左前綴可以是聯(lián)合索引的最左 N個(gè)字段。比如組合索引(a,b,c)可以相當(dāng)于建了(a),(a,b),(a,b,c)三個(gè)索引,大大提高了索引復(fù)用能力。最左前綴也可以是字符串索引的最左 M個(gè)字符。
因此給你ab,ac,abc字段,你可以直接加abc聯(lián)合索引和ac聯(lián)合索引即可。
8. 數(shù)據(jù)庫(kù)隔離級(jí)別是否了解?你們的數(shù)據(jù)庫(kù)默認(rèn)隔離級(jí)別是?為什么選它?
四大數(shù)據(jù)庫(kù)隔離級(jí)別,分別是讀未提交,讀已提交,可重復(fù)讀,串行化(Serializable)。
讀未提交:事務(wù)即使未提交,卻可以被別的事務(wù)讀取到的,這級(jí)別的事務(wù)隔離有臟讀、重復(fù)讀、幻讀的問(wèn)題。 讀已提交:當(dāng)前事務(wù)只能讀取到其他事務(wù)提交的數(shù)據(jù),這種事務(wù)的隔離級(jí)別解決了臟讀問(wèn)題,但還是會(huì)存在不可重復(fù)讀、幻讀問(wèn)題; 可重復(fù)讀:限制了讀取數(shù)據(jù)的時(shí)候,不可以進(jìn)行修改,所以解決了不可重復(fù)讀的問(wèn)題,但是讀取范圍數(shù)據(jù)的時(shí)候,是可以插入數(shù)據(jù),所以還會(huì)存在幻讀問(wèn)題。 串行化:事務(wù)最高的隔離級(jí)別,在該級(jí)別下,所有事務(wù)都是進(jìn)行串行化順序執(zhí)行的。可以避免臟讀、不可重復(fù)讀與幻讀所有并發(fā)問(wèn)題。但是這種事務(wù)隔離級(jí)別下,事務(wù)執(zhí)行很耗性能。
MySQL選擇Repeatable Read(可重復(fù)讀)作為默認(rèn)隔離級(jí)別,我們的數(shù)據(jù)庫(kù)隔離級(jí)別選的是讀已提交。
8.1 為什么MySQL的默認(rèn)隔離離別是RR?
binlog的格式也有三種:statement,row,mixed。設(shè)置為statement格式,binlog記錄的是SQL的原文。又因?yàn)镸ySQL在主從復(fù)制的過(guò)程是通過(guò)binlog進(jìn)行數(shù)據(jù)同步,如果設(shè)置為讀已提交(RC)隔離級(jí)別,當(dāng)出現(xiàn)事務(wù)亂序的時(shí)候,就會(huì)導(dǎo)致備庫(kù)在 SQL 回放之后,結(jié)果和主庫(kù)內(nèi)容不一致。
比如一個(gè)表t,表中有兩條記錄:
CREATE?TABLE?t?(??
?????a?int(11)?DEFAULT?NULL,??
?????b?int(11)?DEFAULT?NULL,??
?????PRIMARY?KEY?a?(a),
?????KEY?b(b)
???)?ENGINE=InnoDB?DEFAULT?CHARSET=latin1;??
???insert?into?t1?values(10,666),(20,233);?
兩個(gè)事務(wù)并發(fā)寫(xiě)操作,如下:
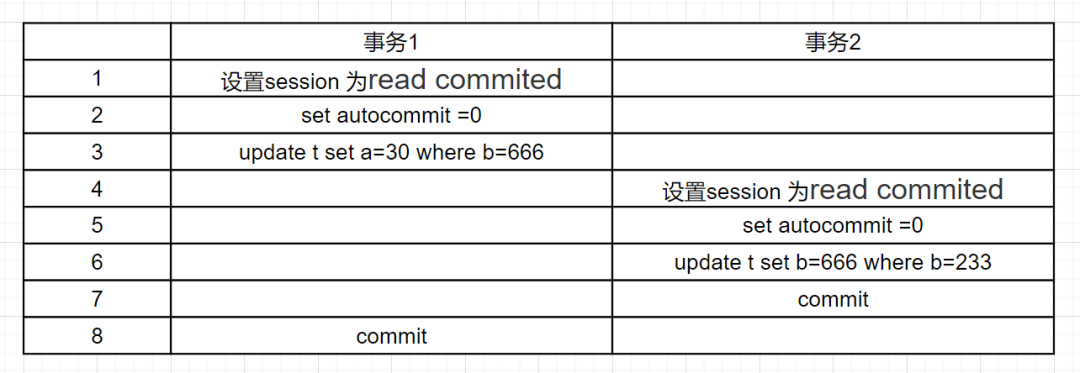
在讀已提交(RC)隔離級(jí)別下,兩個(gè)事務(wù)執(zhí)行完后,數(shù)據(jù)庫(kù)的兩條記錄就變成了(30,666)、(20,666)。這兩個(gè)事務(wù)執(zhí)行完后,binlog也就有兩條記錄,因?yàn)槭聞?wù)binlog用的是statement格式,事務(wù)2先提交,因此update t set b=666 where b=233優(yōu)先記錄,而update t set a=30 where b=666記錄在后面。
當(dāng)bin log同步到從庫(kù)后,執(zhí)行update t set b=666 where b=233和update t set a=30 where b=666記錄,數(shù)據(jù)庫(kù)的記錄就變成(30,666)、(30,666),這時(shí)候主從數(shù)據(jù)不一致啦。
因此MySQL的默認(rèn)隔離離別選擇了RR而不是RC。RR隔離級(jí)別下,更新數(shù)據(jù)的時(shí)候不僅對(duì)更新的行加行級(jí)鎖,還會(huì)加間隙鎖(gap lock)。事務(wù)2要執(zhí)行時(shí),因?yàn)槭聞?wù)1增加了間隙鎖,就會(huì)導(dǎo)致事務(wù)2執(zhí)行被卡住,只有等事務(wù)1提交或者回滾后才能繼續(xù)執(zhí)行。
并且,MySQL還禁止在使用statement格式的binlog的情況下,使用READ COMMITTED作為事務(wù)隔離級(jí)別。
我們的數(shù)據(jù)庫(kù)隔離級(jí)別最后選的是讀已提交(RC)。
那為什么MySQL官方默認(rèn)隔離級(jí)別是RR,而有些大廠選擇了RC作為默認(rèn)的隔離級(jí)別呢?
提升并發(fā)
RC 在加鎖的過(guò)程中,不需要添加Gap Lock和 Next-Key Lock 的,只對(duì)要修改的記錄添加行級(jí)鎖就行了。因此RC的支持的并發(fā)度比RR高得多,
減少死鎖
正是因?yàn)镽R隔離級(jí)別增加了Gap Lock和 Next-Key Lock 鎖,因此它相對(duì)于RC,更容易產(chǎn)生死鎖。
9. RR隔離級(jí)別實(shí)現(xiàn)原理,它是如何解決不可重復(fù)讀的?
9.1 什么是不可重復(fù)讀
先回憶下什么是不可重復(fù)讀。假設(shè)現(xiàn)在有兩個(gè)事務(wù)A和B:
事務(wù)A先查詢(xún)Jay的余額,查到結(jié)果是100 這時(shí)候事務(wù)B 對(duì)Jay的賬戶(hù)余額進(jìn)行扣減,扣去10后,提交事務(wù) 事務(wù)A再去查詢(xún)Jay的賬戶(hù)余額發(fā)現(xiàn)變成了90

事務(wù)A被事務(wù)B干擾到了!在事務(wù)A范圍內(nèi),兩個(gè)相同的查詢(xún),讀取同一條記錄,卻返回了不同的數(shù)據(jù),這就是不可重復(fù)讀。
9.2 undo log版本鏈 + Read View可見(jiàn)性規(guī)則
RR隔離級(jí)別實(shí)現(xiàn)原理,就是MVCC多版本并發(fā)控制,而MVCC是是通過(guò)Read View+ Undo Log實(shí)現(xiàn)的,Undo Log 保存了歷史快照,Read View可見(jiàn)性規(guī)則幫助判斷當(dāng)前版本的數(shù)據(jù)是否可見(jiàn)。
Undo Log版本鏈長(zhǎng)這樣:
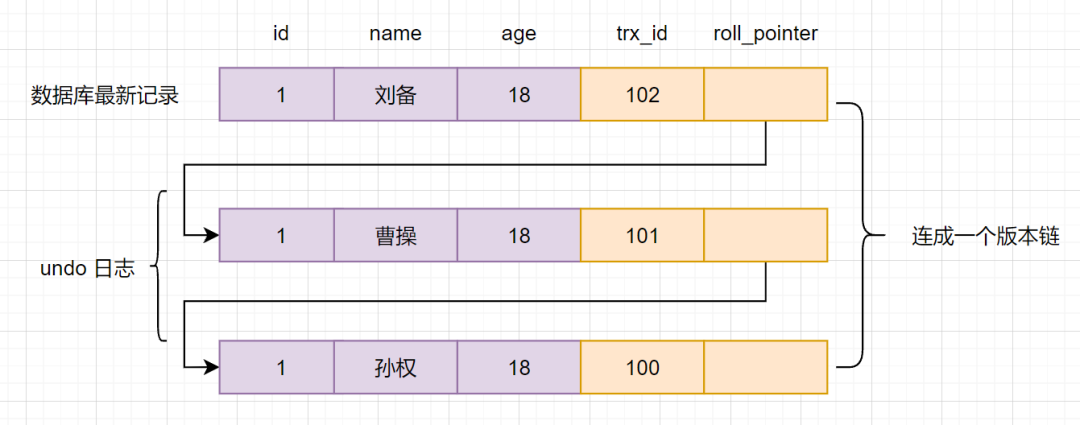
Read view 的幾個(gè)重要屬性
m_ids:當(dāng)前系統(tǒng)中那些活躍(未提交)的讀寫(xiě)事務(wù)ID, 它數(shù)據(jù)結(jié)構(gòu)為一個(gè)List。min_limit_id:表示在生成Read View時(shí),當(dāng)前系統(tǒng)中活躍的讀寫(xiě)事務(wù)中最小的事務(wù)id,即m_ids中的最小值。max_limit_id:表示生成Read View時(shí),系統(tǒng)中應(yīng)該分配給下一個(gè)事務(wù)的id值。creator_trx_id: 創(chuàng)建當(dāng)前Read View的事務(wù)ID
Read view 可見(jiàn)性規(guī)則如下:
如果數(shù)據(jù)事務(wù)ID trx_id < min_limit_id,表明生成該版本的事務(wù)在生成Read View前,已經(jīng)提交(因?yàn)槭聞?wù)ID是遞增的),所以該版本可以被當(dāng)前事務(wù)訪(fǎng)問(wèn)。如果 trx_id>= max_limit_id,表明生成該版本的事務(wù)在生成Read View后才生成,所以該版本不可以被當(dāng)前事務(wù)訪(fǎng)問(wèn)。如果 min_limit_id =
3.1 如果 m_ids包含trx_id,則代表Read View生成時(shí)刻,這個(gè)事務(wù)還未提交,但是如果數(shù)據(jù)的trx_id等于creator_trx_id的話(huà),表明數(shù)據(jù)是自己生成的,因此是可見(jiàn)的。3.2 如果 m_ids包含trx_id,并且trx_id不等于creator_trx_id,則Read View生成時(shí),事務(wù)未提交,并且不是自己生產(chǎn)的,所以當(dāng)前事務(wù)也是看不見(jiàn)的;3.3 如果 m_ids不包含trx_id,則說(shuō)明你這個(gè)事務(wù)在Read View生成之前就已經(jīng)提交了,修改的結(jié)果,當(dāng)前事務(wù)是能看見(jiàn)的。
9.3 RR 如何解決不可重復(fù)讀
查詢(xún)一條記錄,基于MVCC,是怎樣的流程
獲取事務(wù)自己的版本號(hào),即事務(wù)ID 獲取Read View 查詢(xún)得到的數(shù)據(jù),然后Read View中的事務(wù)版本號(hào)進(jìn)行比較。 如果不符合Read View的可見(jiàn)性規(guī)則, 即就需要Undo log中歷史快照; 最后返回符合規(guī)則的數(shù)據(jù)
假設(shè)存在事務(wù)A和B,SQL執(zhí)行流程如下
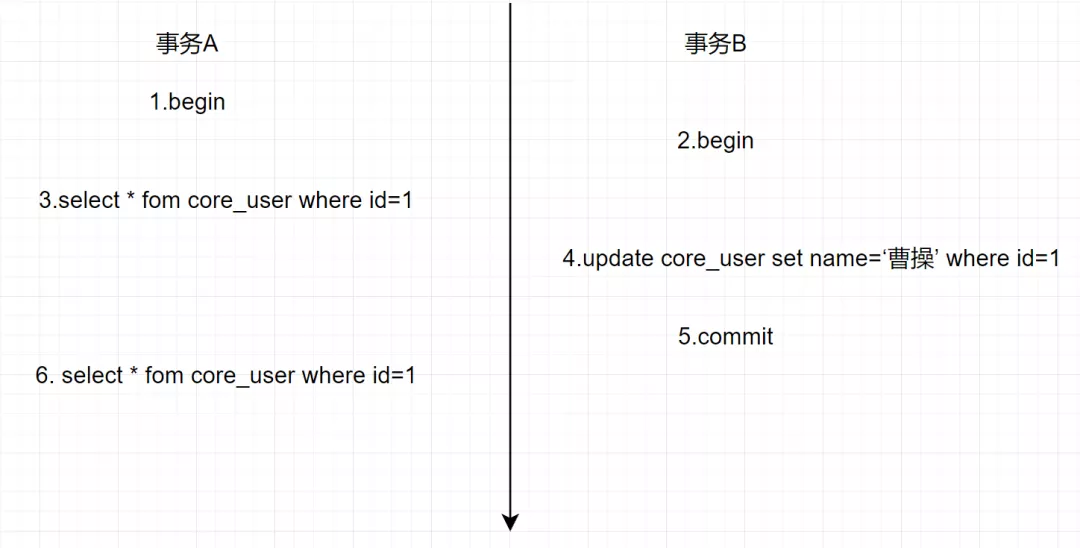
在可重復(fù)讀(RR)隔離級(jí)別下,一個(gè)事務(wù)里只會(huì)獲取一次Read View,都是副本共用的,從而保證每次查詢(xún)的數(shù)據(jù)都是一樣的。
假設(shè)當(dāng)前有一張core_user表,插入一條初始化數(shù)據(jù),如下:
 基于MVCC,我們來(lái)看看執(zhí)行流程
基于MVCC,我們來(lái)看看執(zhí)行流程
A開(kāi)啟事務(wù),首先得到一個(gè)事務(wù)ID為100 B開(kāi)啟事務(wù),得到事務(wù)ID為101 事務(wù)A生成一個(gè)Read View,read view對(duì)應(yīng)的值如下
| 變量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后回到版本鏈:開(kāi)始從版本鏈中挑選可見(jiàn)的記錄:
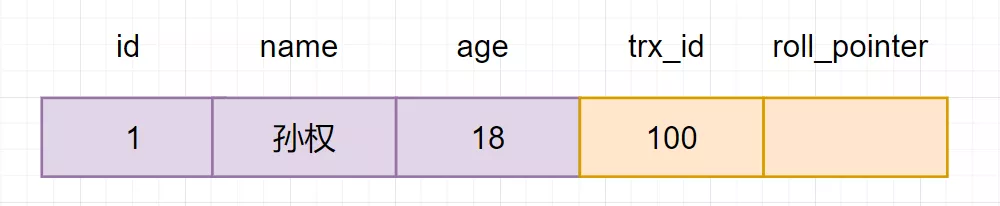
由圖可以看出,最新版本的列name的內(nèi)容是孫權(quán),該版本的trx_id值為100。開(kāi)始執(zhí)行read view可見(jiàn)性規(guī)則校驗(yàn):
min_limit_id(100)=creator_trx_id?=?trx_id?=100;
由此可得,trx_id=100的這個(gè)記錄,當(dāng)前事務(wù)是可見(jiàn)的。所以查到是name為孫權(quán)的記錄。
事務(wù)B進(jìn)行修改操作,把名字改為曹操。把原數(shù)據(jù)拷貝到undo log,然后對(duì)數(shù)據(jù)進(jìn)行修改,標(biāo)記事務(wù)ID和上一個(gè)數(shù)據(jù)版本在undo log的地址。
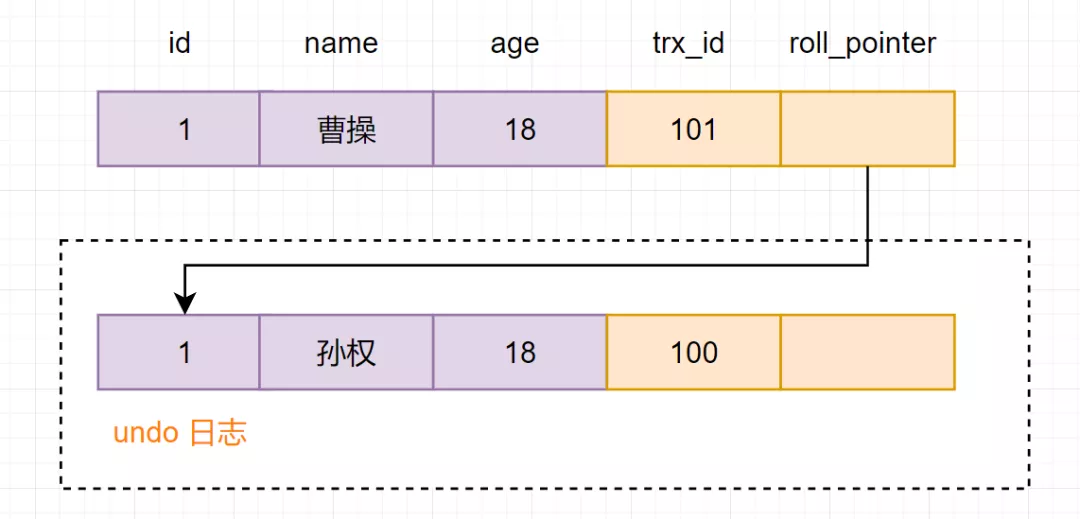
事務(wù)B提交事務(wù)
事務(wù)A再次執(zhí)行查詢(xún)操作,因?yàn)槭荝R(可重復(fù)讀)隔離級(jí)別,因此會(huì)復(fù)用老的Read View副本,Read View對(duì)應(yīng)的值如下
| 變量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本鏈:從版本鏈中挑選可見(jiàn)的記錄:
從圖可得,最新版本的列name的內(nèi)容是曹操,該版本的trx_id值為101。開(kāi)始執(zhí)行read view可見(jiàn)性規(guī)則校驗(yàn):
min_limit_id(100)=因?yàn)閙_ids{100,101}包含trx_id(101),
并且creator_trx_id?(100)?不等于trx_id(101)
所以,trx_id=101這個(gè)記錄,對(duì)于當(dāng)前事務(wù)是不可見(jiàn)的。這時(shí)候呢,版本鏈roll_pointer跳到下一個(gè)版本,trx_id=100這個(gè)記錄,再次校驗(yàn)是否可見(jiàn):
min_limit_id(100)=因?yàn)閙_ids{100,101}包含trx_id(100),
并且creator_trx_id?(100)?等于trx_id(100)
所以,trx_id=100這個(gè)記錄,對(duì)于當(dāng)前事務(wù)是可見(jiàn)的,所以?xún)纱尾樵?xún)結(jié)果,都是name=孫權(quán)的那個(gè)記錄。即在可重復(fù)讀(RR)隔離級(jí)別下,復(fù)用老的Read View副本,解決了不可重復(fù)讀的問(wèn)題。
大家可以回頭多看幾遍我這篇文章哈:看一遍就理解:MVCC原理詳解
10. 你們項(xiàng)目使用了RocketMQ對(duì)吧?那你知道如何保證消息不丟失嗎?
一個(gè)消息從生產(chǎn)者產(chǎn)生,到被消費(fèi)者消費(fèi),主要經(jīng)過(guò)這3個(gè)過(guò)程:
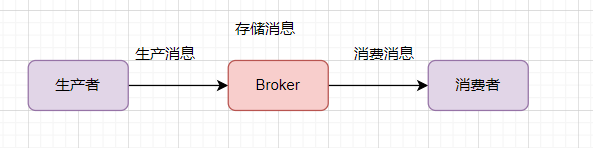
生產(chǎn)者產(chǎn)生消息 消息發(fā)送到存儲(chǔ)端,保存下來(lái) 消息推送到消費(fèi)者,消費(fèi)者消費(fèi)完,ack應(yīng)答。
因此如何保證MQ不丟失消息,可以從這三個(gè)階段闡述:
生產(chǎn)者保證不丟消息 存儲(chǔ)端不丟消息 消費(fèi)者不丟消息
10.1 生產(chǎn)者保證不丟消息
生產(chǎn)端如何保證不丟消息呢?確保生產(chǎn)的消息能順利到達(dá)存儲(chǔ)端。
如果是RocketMQ消息中間件的話(huà),Producer生產(chǎn)者提供了三種發(fā)送消息的方式,分別是:
同步發(fā)送 異步發(fā)送 單向發(fā)送
生產(chǎn)者要想發(fā)消息時(shí)保證消息不丟失,可以:
采用同步方式發(fā)送,send消息方法返回成功狀態(tài),即消息正常到達(dá)了存儲(chǔ)端 Broker。如果 send消息異常或者返回非成功狀態(tài),可以發(fā)起重試。可以使用事務(wù)消息, RocketMQ的事務(wù)消息機(jī)制就是為了保證零丟失來(lái)設(shè)計(jì)的
10.2 存儲(chǔ)端不丟消息
如何保證存儲(chǔ)端的消息不丟失呢?確保消息持久化到磁盤(pán),那就是刷盤(pán)機(jī)制嘛。
刷盤(pán)機(jī)制分同步刷盤(pán)和異步刷盤(pán):
同步刷盤(pán):生產(chǎn)者消息發(fā)過(guò)來(lái)時(shí),只有持久化到磁盤(pán), RocketMQ的存儲(chǔ)端Broker才返回一個(gè)成功的ACK響應(yīng)。它保證消息不丟失,但是影響了性能。異步刷盤(pán):只要消息寫(xiě)入 PageCache緩存,就返回一個(gè)成功的ACK響應(yīng)。這樣提高了MQ的性能,但是如果這時(shí)候機(jī)器斷電了,就會(huì)丟失消息。
除了同步刷盤(pán)機(jī)制,還有一個(gè)維度需要考慮。Broker一般是集群部署的,有主節(jié)點(diǎn)和從節(jié)點(diǎn)。消息到Broker存儲(chǔ)端,只有主節(jié)點(diǎn)和從節(jié)點(diǎn)都寫(xiě)入成功,才反饋成功的ack給生產(chǎn)者。這就是同步復(fù)制,它保證了消息不丟失,但是降低了系統(tǒng)的吞吐量。與之對(duì)應(yīng)即是異步復(fù)制,只要消息寫(xiě)入主節(jié)點(diǎn)成功,就返回成功的ack,它速度快,但是會(huì)有性能問(wèn)題。
10.3 消費(fèi)階段不丟消息
消費(fèi)者執(zhí)行完業(yè)務(wù)邏輯,再反饋會(huì)Broker說(shuō)消費(fèi)成功,這樣才可以保證消費(fèi)階段不丟消息。
11. 事務(wù)消息是否了解?場(chǎng)景題:比如下單清空購(gòu)物車(chē),你是如何設(shè)計(jì)的?
事務(wù)消息主要用來(lái)解決消息生產(chǎn)者和消息消費(fèi)者的數(shù)據(jù)一致性問(wèn)題。我們先來(lái)回憶一下:一條普通的消息隊(duì)列消息,從產(chǎn)生到被消費(fèi),經(jīng)歷的流程:
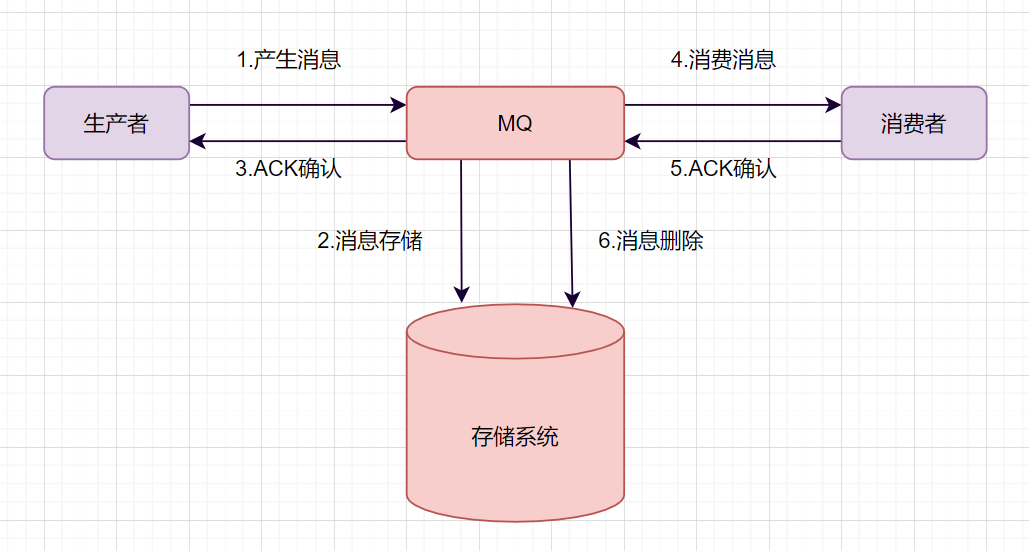
生產(chǎn)者產(chǎn)生消息,發(fā)送到MQ服務(wù)器 MQ收到消息后,將消息持久化到存儲(chǔ)系統(tǒng)。 MQ服務(wù)器返回ACk到生產(chǎn)者。 MQ服務(wù)器把消息push給消費(fèi)者 消費(fèi)者消費(fèi)完消息,響應(yīng)ACK MQ服務(wù)器收到ACK,認(rèn)為消息消費(fèi)成功,即在存儲(chǔ)中刪除消息。
消息隊(duì)列的事務(wù)消息流程是怎樣的呢?
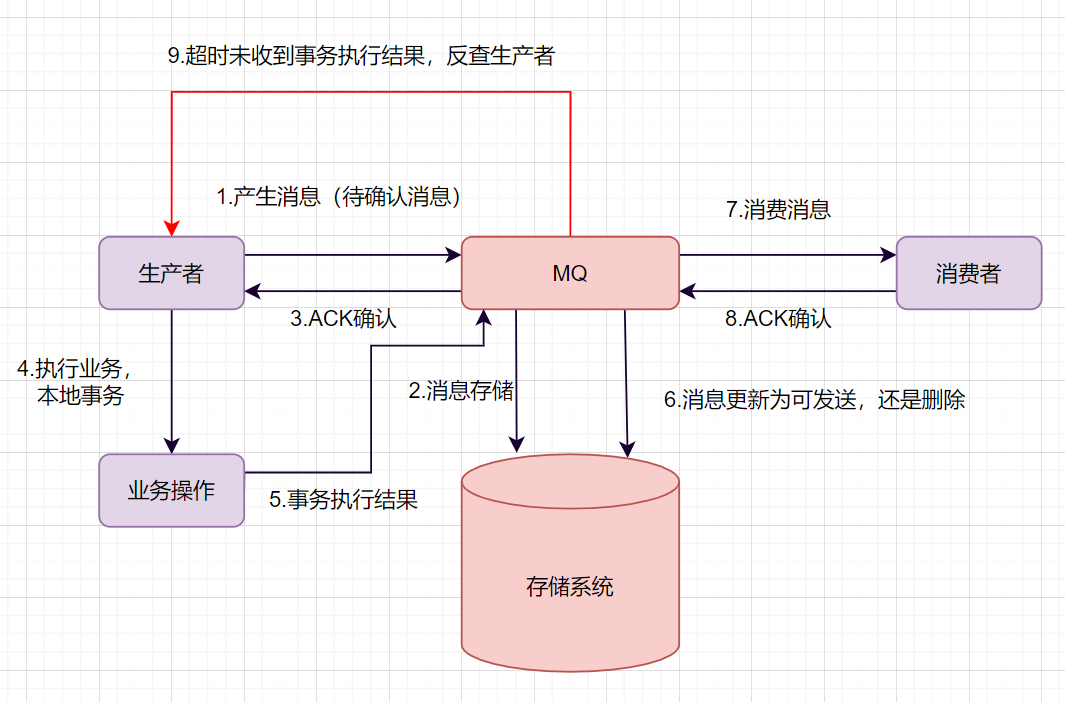
生產(chǎn)者產(chǎn)生消息,發(fā)送一條半事務(wù)消息到MQ服務(wù)器 MQ收到消息后,將消息持久化到存儲(chǔ)系統(tǒng),這條消息的狀態(tài)是待發(fā)送狀態(tài)。 MQ服務(wù)器返回ACK確認(rèn)到生產(chǎn)者,此時(shí)MQ不會(huì)觸發(fā)消息推送事件 生產(chǎn)者執(zhí)行本地事務(wù) 如果本地事務(wù)執(zhí)行成功,即commit執(zhí)行結(jié)果到MQ服務(wù)器;如果執(zhí)行失敗,發(fā)送rollback。 如果是正常的commit,MQ服務(wù)器更新消息狀態(tài)為可發(fā)送;如果是rollback,即刪除消息。 如果消息狀態(tài)更新為可發(fā)送,則MQ服務(wù)器會(huì)push消息給消費(fèi)者。消費(fèi)者消費(fèi)完就回ACK。 如果MQ服務(wù)器長(zhǎng)時(shí)間沒(méi)有收到生產(chǎn)者的commit或者rollback,它會(huì)反查生產(chǎn)者,然后根據(jù)查詢(xún)到的結(jié)果執(zhí)行最終狀態(tài)。
我們舉個(gè)下訂單清空購(gòu)物車(chē)的例子吧。訂單系統(tǒng)創(chuàng)建完訂單后,然后發(fā)消息給下游系統(tǒng)購(gòu)物車(chē)系統(tǒng),清空購(gòu)物車(chē)。
生產(chǎn)者(訂單系統(tǒng))產(chǎn)生消息,發(fā)送一條半事務(wù)消息到MQ服務(wù)器 MQ收到消息后,將消息持久化到存儲(chǔ)系統(tǒng),這條消息的狀態(tài)是待發(fā)送狀態(tài)。 MQ服務(wù)器返回ACK確認(rèn)到生產(chǎn)者,此時(shí)MQ不會(huì)觸發(fā)消息推送事件 生產(chǎn)者執(zhí)行本地事務(wù)(訂單創(chuàng)建成功,提交事務(wù)消息) 如果本地事務(wù)執(zhí)行成功,即commit執(zhí)行結(jié)果到MQ服務(wù)器;如果執(zhí)行失敗,發(fā)送rollback。 如果是commit正常提交,MQ服務(wù)器更新消息狀態(tài)為可發(fā)送;如果是rollback,即刪除消息。 如果消息狀態(tài)更新為可發(fā)送,則MQ服務(wù)器會(huì)push消息給消費(fèi)者(購(gòu)物車(chē)系統(tǒng))。消費(fèi)者消費(fèi)完(即拿到訂單消息,清空購(gòu)物車(chē)成功)就應(yīng)答ACK。 如果MQ服務(wù)器長(zhǎng)時(shí)間沒(méi)有收到生產(chǎn)者的commit或者rollback,它會(huì)反查生產(chǎn)者,然后根據(jù)查詢(xún)到的結(jié)果(回滾操作或者重新發(fā)送消息)執(zhí)行最終狀態(tài)。
有些伙伴可能有疑惑,如果消費(fèi)者消費(fèi)失敗怎么辦呢?那數(shù)據(jù)是不是不一致啦?所以就需要消費(fèi)者消費(fèi)成功,執(zhí)行業(yè)務(wù)邏輯成功,再反饋ack嘛。如果消費(fèi)者消費(fèi)失敗,那就自動(dòng)重試嘛,接口支持冪等即可。
12. 如何快速判斷一個(gè)數(shù)是奇數(shù)還是偶數(shù),除開(kāi)對(duì)2取余呢。
判斷一個(gè)數(shù)是奇數(shù)還是偶數(shù),我們最容易想到的就是對(duì)2取余。
if(?x?%?2?)
//?奇數(shù)
else
//?偶數(shù)
還有一種方法,就是與1相與( &1),具體實(shí)現(xiàn)如下:
if(?x?&?1?)
//?奇數(shù)
else
//?偶數(shù)
13. Spring聲明式事務(wù)原理?哪些場(chǎng)景事務(wù)會(huì)失效?
13.1 聲明式事務(wù)原理
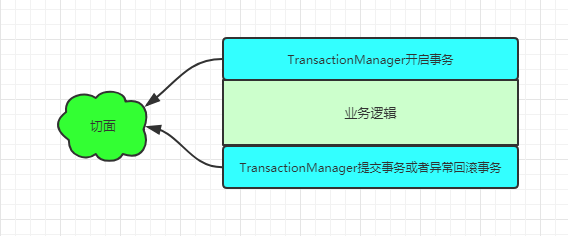
spring聲明式事務(wù),即@Transactional,它可以幫助我們把事務(wù)開(kāi)啟、提交或者回滾的操作,通過(guò)Aop的方式進(jìn)行管理。
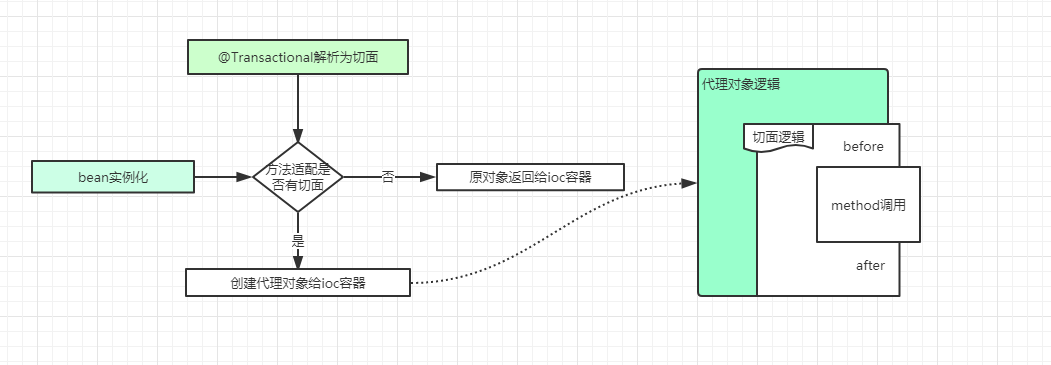
在spring的bean的初始化過(guò)程中,就需要對(duì)實(shí)例化的bean進(jìn)行代理,并且生成代理對(duì)象。生成代理對(duì)象的代理邏輯中,進(jìn)行方法調(diào)用時(shí),需要先獲取切面邏輯,@Transactional注解的切面邏輯類(lèi)似于@Around,在spring中是實(shí)現(xiàn)一種類(lèi)似代理邏輯。
詳解可以看下這篇文章哈:Spring中的@Transactional實(shí)現(xiàn)原理
13.2 spring聲明式事務(wù)哪些場(chǎng)景會(huì)失效
方法的訪(fǎng)問(wèn)權(quán)限必須是public,其他private等權(quán)限,事務(wù)失效 方法被定義成了final的,這樣會(huì)導(dǎo)致事務(wù)失效。 在同一個(gè)類(lèi)中的方法直接內(nèi)部調(diào)用,會(huì)導(dǎo)致事務(wù)失效。 一個(gè)方法如果沒(méi)交給spring管理,就不會(huì)生成spring事務(wù)。 多線(xiàn)程調(diào)用,兩個(gè)方法不在同一個(gè)線(xiàn)程中,獲取到的數(shù)據(jù)庫(kù)連接不一樣的。 表的存儲(chǔ)引擎不支持事務(wù) 如果自己try...catch誤吞了異常,事務(wù)失效。 錯(cuò)誤的傳播
詳解大家可以看下這篇文章:聊聊spring事務(wù)失效的12種場(chǎng)景,太坑了
14. 你們是微服務(wù)架構(gòu)嘛?如果你來(lái)設(shè)計(jì)一個(gè)類(lèi)似淘寶的系統(tǒng),你怎么劃分微服務(wù)?
可以按業(yè)務(wù)領(lǐng)域、功能、重要程度進(jìn)行劃分。
可以按業(yè)務(wù)領(lǐng)域,把用戶(hù)、社區(qū)、商品信息、消息等模塊等劃分。 單一功能職責(zé),按功能拆分,比如訂單、支付、物流、權(quán)限。 按重要程度劃分,區(qū)分核心和非核心功能,比如支付、訂單就是核心功能。
15. 你們是怎么分庫(kù)分表的?分布式ID如何生成?
如果是我們公司的話(huà),使用了水平分庫(kù)的方式,就是一個(gè)用戶(hù)注冊(cè)時(shí),就劃分了屬于哪個(gè)數(shù)據(jù)庫(kù),然后具體的表結(jié)構(gòu)是一樣的。
業(yè)界還有垂直分庫(kù),就是按照不同的系統(tǒng)中的不同業(yè)務(wù)進(jìn)行拆分,比如拆分成用戶(hù)庫(kù)、訂單庫(kù)、積分庫(kù)、商品庫(kù),把它們部署在不同的數(shù)據(jù)庫(kù)服務(wù)器。
分表的話(huà)也有水平分表和垂直分表,垂直分表就是將一些不常用的、數(shù)據(jù)較大或者長(zhǎng)度較長(zhǎng)的列拆分到另外一張表,水平分表就是可以按照某種規(guī)則(如hash取模、range),把數(shù)據(jù)切分到多張表去。一張訂單表,按時(shí)間range拆分如下:
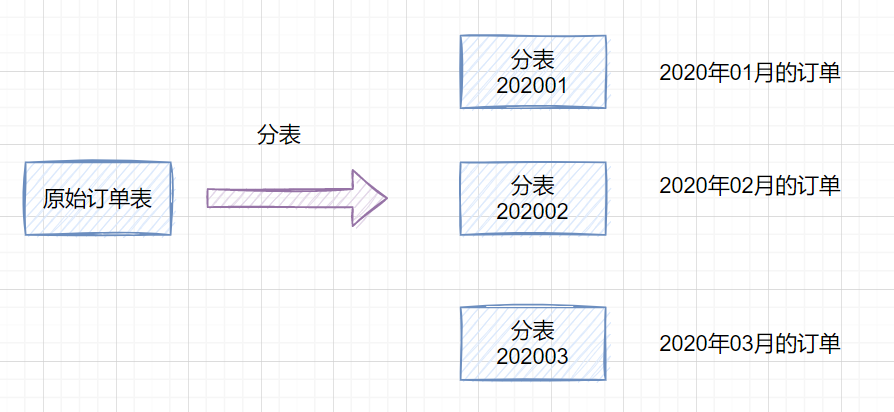
range劃分利于數(shù)據(jù)遷移,但是存在數(shù)據(jù)熱點(diǎn)問(wèn)題。hash取模劃分,不會(huì)存在明顯的熱點(diǎn)問(wèn)題,但是不利于擴(kuò)容。可以range+hash取模結(jié)合使用。
分布式ID可以使用雪花算法生成
雪花算法是一種生成分布式全局唯一ID的算法,生成的ID稱(chēng)為Snowflake IDs。這種算法由Twitter創(chuàng)建,并用于推文的ID。
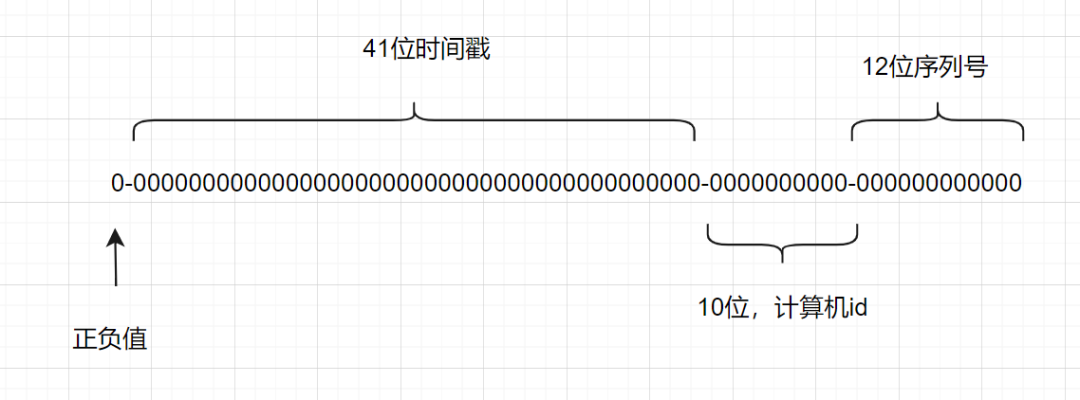
一個(gè)Snowflake ID有64位。
第1位:Java中l(wèi)ong的最高位是符號(hào)位代表正負(fù),正數(shù)是0,負(fù)數(shù)是1,一般生成ID都為正數(shù),所以默認(rèn)為0。 接下來(lái)前41位是時(shí)間戳,表示了自選定的時(shí)期以來(lái)的毫秒數(shù)。 接下來(lái)的10位代表計(jì)算機(jī)ID,防止沖突。 其余12位代表每臺(tái)機(jī)器上生成ID的序列號(hào),這允許在同一毫秒內(nèi)創(chuàng)建多個(gè)Snowflake ID。
16. 所有異常的共同的祖先是?運(yùn)行時(shí)異常有哪幾個(gè)?

Java 異常的頂層父類(lèi)是Throwable,它生了兩個(gè)兒子,大兒子叫Error,二兒子叫Exception。
Error:是程序?法處理的錯(cuò)誤,一般表示系統(tǒng)錯(cuò)誤,例如虛擬機(jī)相關(guān)的錯(cuò)誤 OutOfMemoryErrorException:程序本身可以處理的異常。它可以分為RuntimeException(運(yùn)行時(shí)異常)和CheckedException(可檢查的異常)。
什么是RuntimeException(運(yùn)行時(shí)異常)?
運(yùn)行時(shí)異常是不檢查異常,程序中可以選擇捕獲處理,也可以不處理。這些異常一般是由程序邏輯錯(cuò)誤引起的,程序應(yīng)該從邏輯角度盡可能避免這類(lèi)異常的發(fā)生。
常見(jiàn)的RuntimeException異常:
NullPointerException:空指針異常
ArithmeticException:出現(xiàn)異常的運(yùn)算條件時(shí),拋出此異常
IndexOutOfBoundsException:數(shù)組索引越界異常
ClassNotFoundException:找不到類(lèi)異常
IllegalArgumentException(非法參數(shù)異常)
什么是CheckedException(可檢查的異常)?
從程序語(yǔ)法角度講是必須進(jìn)行處理的異常,如果不處理,程序就不能編譯通過(guò)。如IOException、SQLException等。
常見(jiàn)的 Checked Exception 異常:
IOException:(操作輸入流和輸出流時(shí)可能出現(xiàn)的異常) SQLException
最后(求關(guān)注,別白嫖我)
如果這篇文章對(duì)您有所幫助,或者有所啟發(fā)的話(huà),求一鍵三連:點(diǎn)贊、轉(zhuǎn)發(fā)、在看,您的支持是我堅(jiān)持寫(xiě)作最大的動(dòng)力。
參考感謝
推薦閱讀:
【萬(wàn)字長(zhǎng)文】創(chuàng)業(yè)公司就應(yīng)該技術(shù)選型 Spring Cloud Alibaba
Redis 使用 List 實(shí)現(xiàn)消息隊(duì)列的利與弊
阿里一面:講一講各個(gè)Spring框架之間的關(guān)系
歡迎關(guān)注微信公眾號(hào):互聯(lián)網(wǎng)全棧架構(gòu),收取更多有價(jià)值的信息。