
一文帶你看懂Python數(shù)據(jù)分析利器——Pandas的前世今生

本文將從Python生態(tài)、Pandas歷史背景、Pandas核心語(yǔ)法、Pandas學(xué)習(xí)資源四個(gè)方面去聊一聊Pandas,期望能帶給大家一點(diǎn)啟發(fā)。

一、Python生態(tài)里的Pandas
五月份TIOBE編程語(yǔ)言排行榜,Python追上Java又回到第二的位置。Python如此受歡迎一方面得益于它崇尚簡(jiǎn)潔的編程哲學(xué),另一方面是因?yàn)閺?qiáng)大的第三方庫(kù)生態(tài)。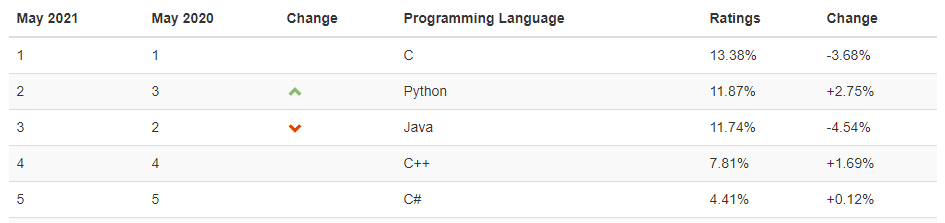
要說(shuō)殺手級(jí)的庫(kù),很難排出個(gè)先后順序,因?yàn)閜ython的明星庫(kù)非常多,在各個(gè)領(lǐng)域都算得上出類拔萃。
比如web框架-Django、深度學(xué)習(xí)框架-TensorFlow、自然語(yǔ)言處理框架-NLTK、圖像處理庫(kù)-PIL、爬蟲(chóng)庫(kù)-requests、圖形界面框架-PyQt、可視化庫(kù)-Matplotlib、科學(xué)計(jì)算庫(kù)-Numpy、數(shù)據(jù)分析庫(kù)-Pandas......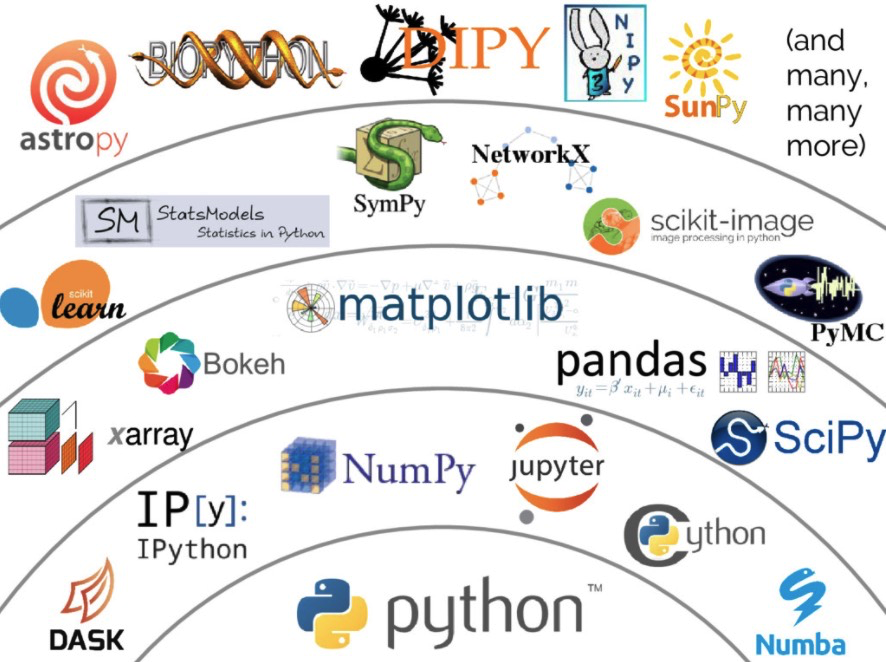
上面大部分庫(kù)我都用過(guò),用的最多也最順手的是Pandas,可以說(shuō)這是一個(gè)生態(tài)上最完整、功能上最強(qiáng)大、體驗(yàn)上最便捷的數(shù)據(jù)分析庫(kù),稱為編程界的Excel也不為過(guò)。
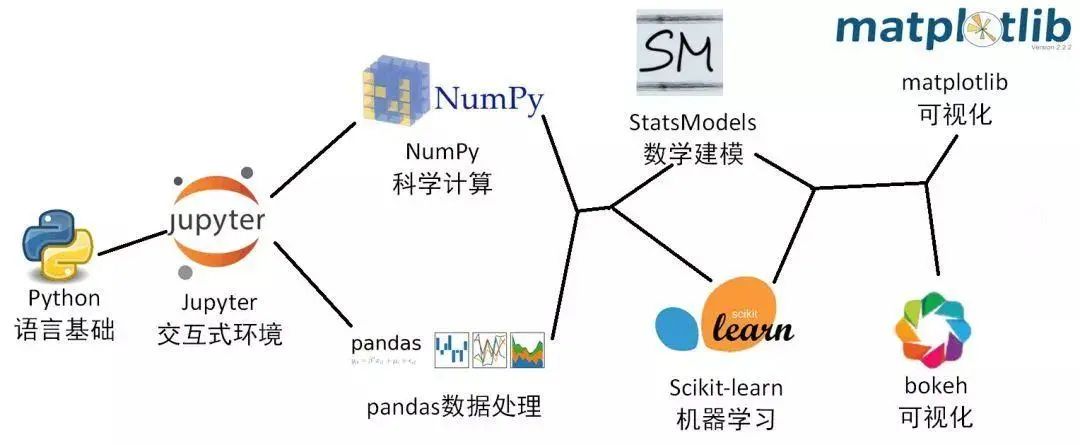
Pandas在Python數(shù)據(jù)科學(xué)鏈條中起著關(guān)鍵作用,處理數(shù)據(jù)十分方便,且連接Python與其它核心庫(kù)。
二、十項(xiàng)全能的Pandas
Pandas誕生于2008年,它的開(kāi)發(fā)者是Wes McKinney,一個(gè)量化金融分析工程師。

因?yàn)槠S趹?yīng)付繁雜的財(cái)務(wù)數(shù)據(jù),Wes McKinney便自學(xué)Python,并開(kāi)發(fā)了Pandas。
大神就是這么任性,沒(méi)有,就創(chuàng)造。
為什么叫作Pandas,其實(shí)這是“Python data analysis”的簡(jiǎn)寫(xiě),同時(shí)也衍生自計(jì)量經(jīng)濟(jì)學(xué)術(shù)語(yǔ)“panel data”(面板數(shù)據(jù))。
所以說(shuō)Pandas的誕生是為了分析金融財(cái)務(wù)數(shù)據(jù),當(dāng)然現(xiàn)在它已經(jīng)應(yīng)用在各個(gè)領(lǐng)域了。
?2008: Pandas正式開(kāi)發(fā)并發(fā)布
2009:Pandas成為開(kāi)源項(xiàng)目
2012: 《利用Python進(jìn)行數(shù)據(jù)分析》出版
2015: Pandas 成為 NumFOCUS 贊助的項(xiàng)目
?
Pandas能做什么呢?
它可以幫助你任意探索數(shù)據(jù),對(duì)數(shù)據(jù)進(jìn)行讀取、導(dǎo)入、導(dǎo)出、連接、合并、分組、插入、拆分、透視、索引、切分、轉(zhuǎn)換等,以及可視化展示、復(fù)雜統(tǒng)計(jì)、數(shù)據(jù)庫(kù)交互、web爬取等。
同時(shí)Pandas還可以使用復(fù)雜的自定義函數(shù)處理數(shù)據(jù),并與numpy、matplotlib、sklearn、pyspark、sklearn等眾多科學(xué)計(jì)算庫(kù)交互。

Pandas有一個(gè)偉大的目標(biāo),即成為任何語(yǔ)言中可用的最強(qiáng)大、最靈活的開(kāi)源數(shù)據(jù)分析工具。
讓我們期待下。
三、Pandas核心語(yǔ)法
1. 數(shù)據(jù)類型
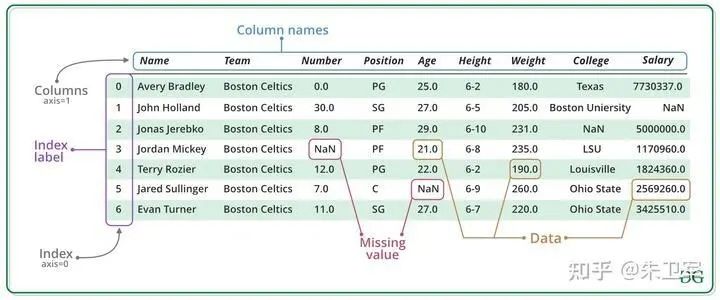
Pandas的基本數(shù)據(jù)類型是dataframe和series兩種,也就是行和列的形式,dataframe是多行多列,series是單列多行。
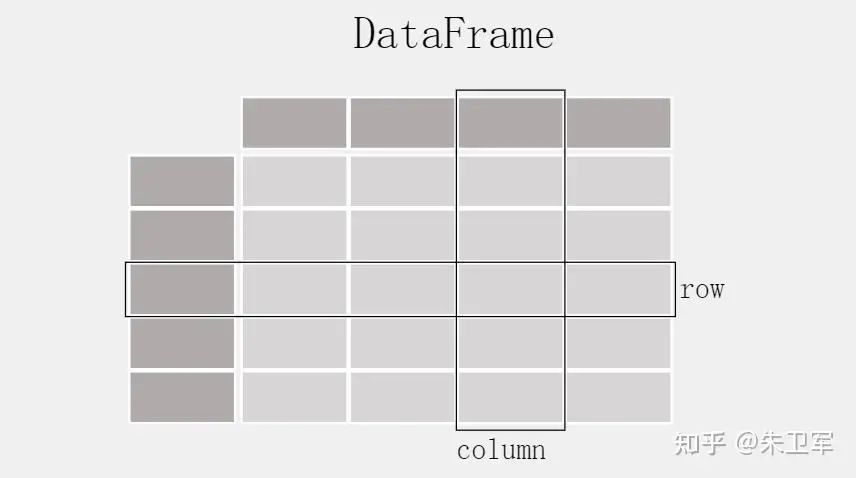
如果在jupyter notebook里面使用pandas,那么數(shù)據(jù)展示的形式像excel表一樣,有行字段和列字段,還有值。
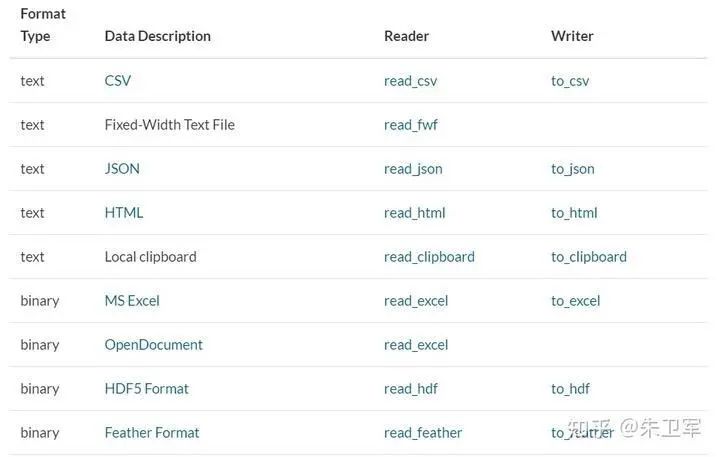
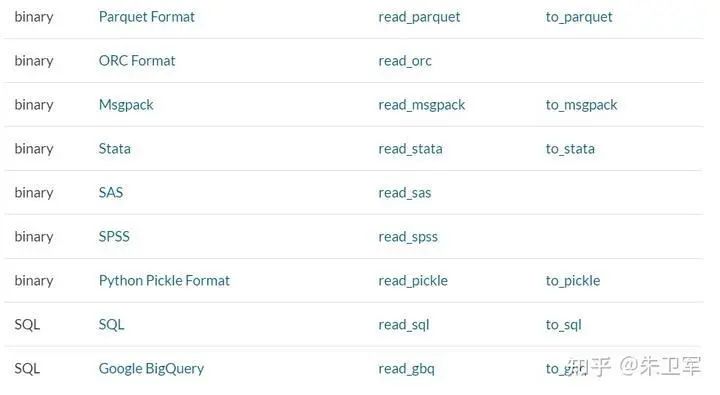
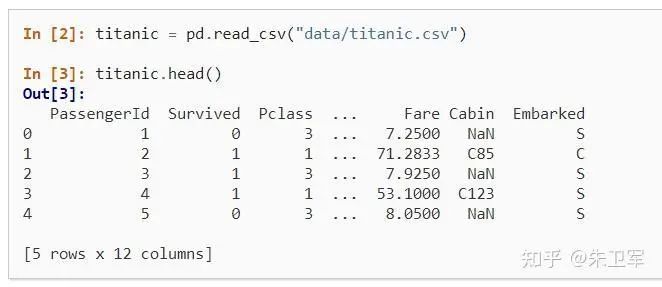
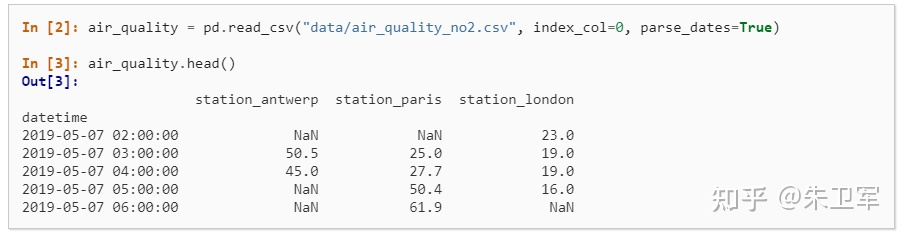
2. 讀取數(shù)據(jù)
pandas支持讀取和輸出多種數(shù)據(jù)類型,包括但不限于csv、txt、xlsx、json、html、sql、parquet、sas、spss、stata、hdf5
讀取一般通過(guò)read_*函數(shù)實(shí)現(xiàn),輸出通過(guò)to_*函數(shù)實(shí)現(xiàn)。

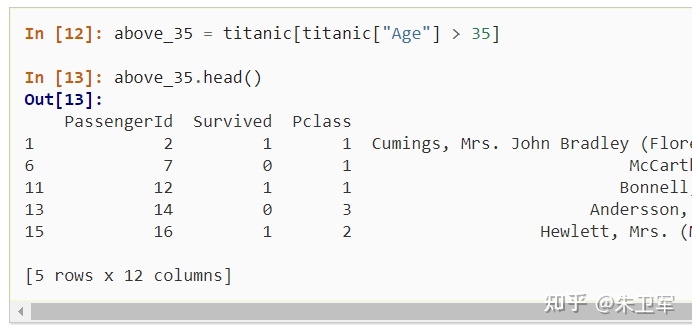
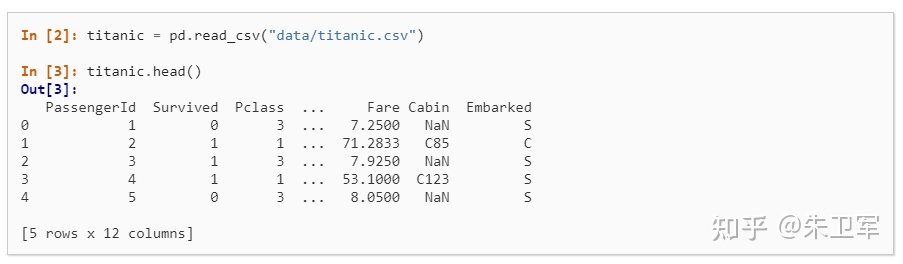
3. 選擇數(shù)據(jù)子集
導(dǎo)入數(shù)據(jù)后,一般要對(duì)數(shù)據(jù)進(jìn)行清洗,我們會(huì)選擇部分?jǐn)?shù)據(jù)使用,也就是子集。
在pandas中選擇數(shù)據(jù)子集非常簡(jiǎn)單,通過(guò)篩選行和列字段的值實(shí)現(xiàn)。
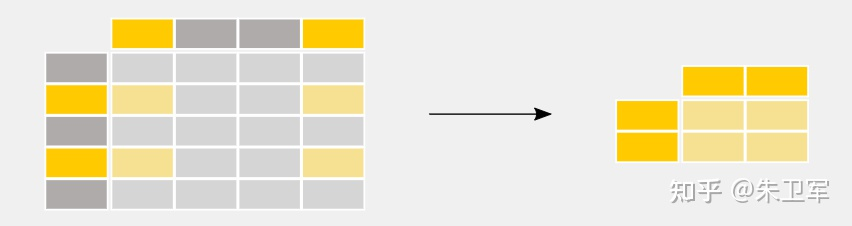
具體實(shí)現(xiàn)如下:
4. 數(shù)據(jù)可視化
不要以為pandas只是個(gè)數(shù)據(jù)處理工具,它還可以幫助你做可視化圖表,而且能高度集成matplotlib。
你可以用pandas的plot方法繪制散點(diǎn)圖、柱狀圖、折線圖等各種主流圖表。
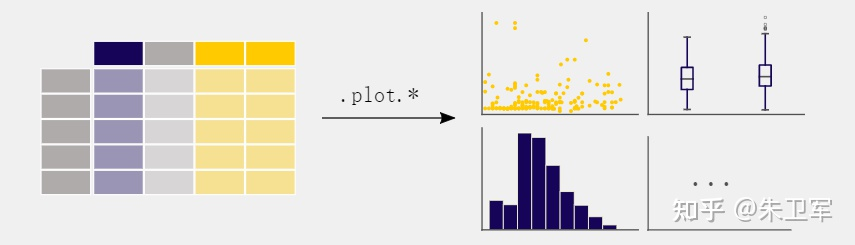
5. 創(chuàng)建新列
有時(shí)需要通過(guò)函數(shù)轉(zhuǎn)化舊列創(chuàng)建一個(gè)新的字段列,pandas也能輕而易舉的實(shí)現(xiàn)
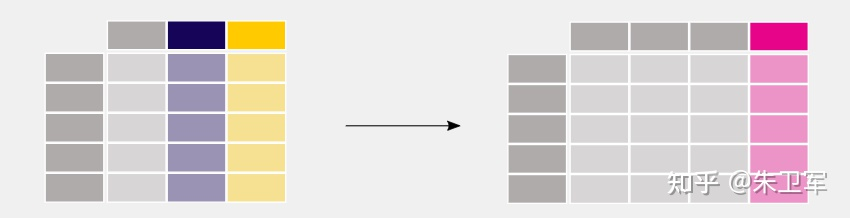
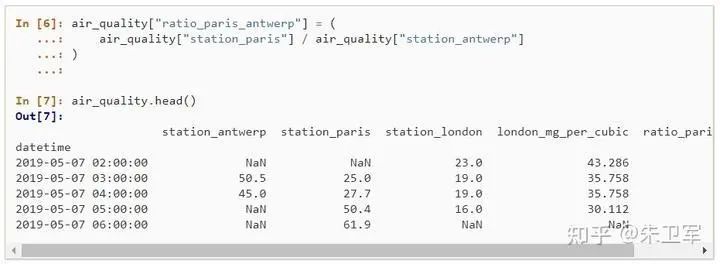
6. 分組計(jì)算
在sql中會(huì)用到group by這個(gè)方法,用來(lái)對(duì)某個(gè)或多個(gè)列進(jìn)行分組,計(jì)算其他列的統(tǒng)計(jì)值。
pandas也有這樣的功能,而且和sql的用法類似。


7. 數(shù)據(jù)合并
數(shù)據(jù)處理中經(jīng)常會(huì)遇到將多個(gè)表合并成一個(gè)表的情況,很多人會(huì)打開(kāi)多個(gè)excel表,然后手動(dòng)復(fù)制粘貼,這樣就很低效。
pandas提供了merge、join、concat等方法用來(lái)合并或連接多張表。

小結(jié)
pandas還有數(shù)以千計(jì)的強(qiáng)大函數(shù),能實(shí)現(xiàn)各種騷操作。
python也還有數(shù)不勝數(shù)的寶藏庫(kù),等著大家去探索
