
所以,機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別是什么?
點(diǎn)擊上方“程序員大白”,選擇“星標(biāo)”公眾號
重磅干貨,第一時間送達(dá)


作者 | aporras
翻譯 | 郭振
轉(zhuǎn)自 | Python與算法社區(qū)(ID:alg-channel)
深度學(xué)習(xí)是機(jī)器學(xué)習(xí)算法的子類,其特殊性是有更高的復(fù)雜度。因此,深度學(xué)習(xí)屬于機(jī)器學(xué)習(xí),但它們絕對不是相反的概念。我們將淺層學(xué)習(xí)稱為不是深層的那些機(jī)器學(xué)習(xí)技術(shù)。
讓我們開始將它們放到我們的世界中:

這種高度復(fù)雜性基于什么?
在實(shí)踐中,深度學(xué)習(xí)由神經(jīng)網(wǎng)絡(luò)中的多個隱藏層組成。我們在《從神經(jīng)元到網(wǎng)絡(luò)》一文中解釋了神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)知識,然后我們已經(jīng)將深度學(xué)習(xí)介紹為一種特殊的超級網(wǎng)絡(luò):
層數(shù)的增加和網(wǎng)絡(luò)的復(fù)雜性被稱為深度學(xué)習(xí),類似于類固醇(steroids)上的常規(guī)網(wǎng)絡(luò)。
為什么這種復(fù)雜性是一個優(yōu)勢?
知識在各個層間流動。就像人類學(xué)習(xí),一個逐步學(xué)習(xí)的過程。第一層專注于學(xué)習(xí)更具體的概念,而更深的層將使用已經(jīng)學(xué)習(xí)的信息來吸收得出更多抽象的概念。這種構(gòu)造數(shù)據(jù)表示的過程稱為特征提取。
它們的復(fù)雜體系結(jié)構(gòu)為深度神經(jīng)網(wǎng)絡(luò)提供了自動執(zhí)行特征提取的能力。相反,在常規(guī)的機(jī)器學(xué)習(xí)或淺層學(xué)習(xí)中,此任務(wù)是在算法階段之外執(zhí)行的。由人員,數(shù)據(jù)科學(xué)家團(tuán)隊(duì)(而非機(jī)器)負(fù)責(zé)分析原始數(shù)據(jù)并將其更改為有價值的功能。
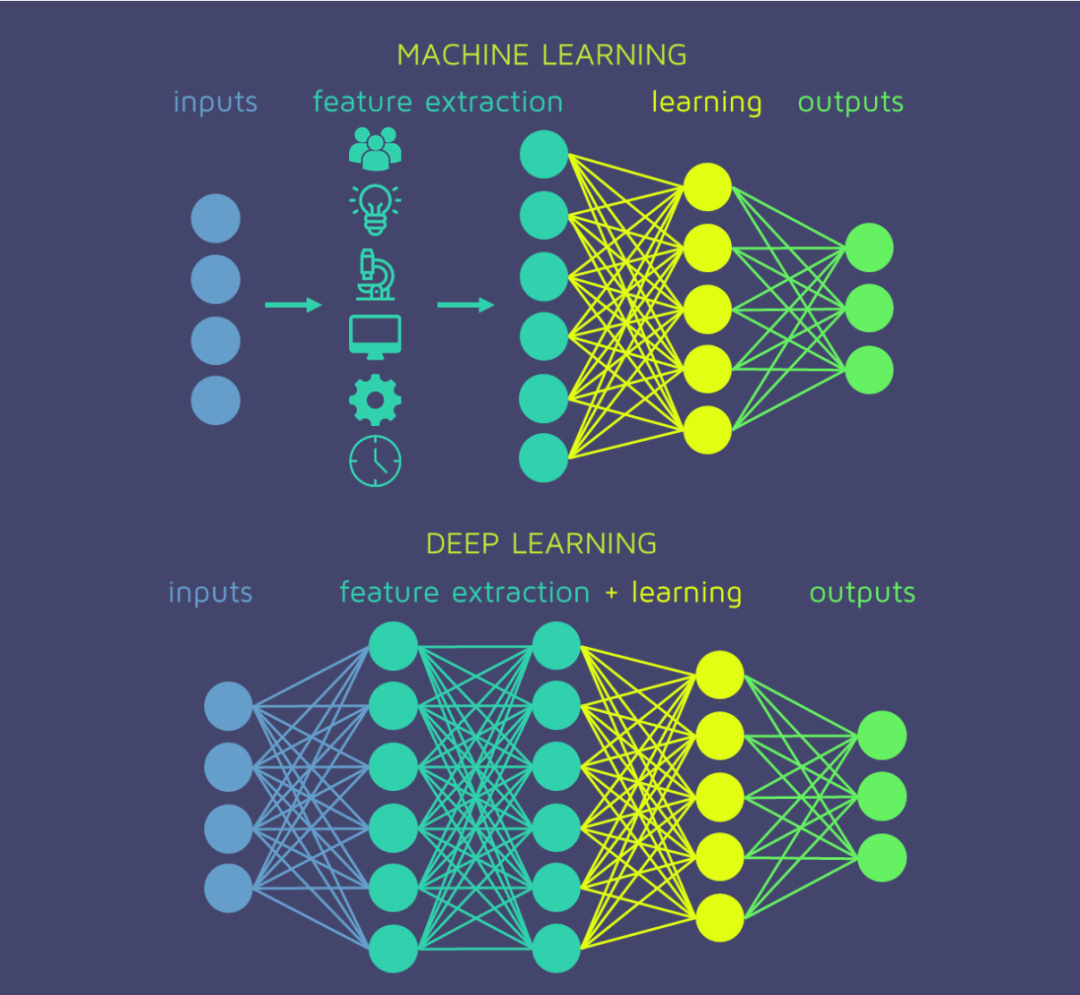
深度學(xué)習(xí)的根本優(yōu)勢在于,可以在無結(jié)構(gòu)化數(shù)據(jù)上訓(xùn)練這些算法,而無限制地訪問信息。這種強(qiáng)大的條件為他們提供了獲得更多有價值的學(xué)習(xí)的機(jī)會。
也許現(xiàn)在您在想...
從多少層開始,它被視為深度學(xué)習(xí)?關(guān)于淺層學(xué)習(xí)何時結(jié)束和深度學(xué)習(xí)何時開始尚無統(tǒng)一定義。但是,最一致的共識是,多個隱藏層意味著深度學(xué)習(xí)。換句話說,我們考慮從至少3個非線性轉(zhuǎn)換進(jìn)行深度學(xué)習(xí),即大于2個隱藏層+ 1個輸出層。
除了神經(jīng)網(wǎng)絡(luò)之外,還有其他深度學(xué)習(xí)嗎?
我也無法對此達(dá)成完全共識。然而,似乎有關(guān)深度學(xué)習(xí)的一切至少或間接地與神經(jīng)網(wǎng)絡(luò)有關(guān)。因此,我同意那些斷言沒有神經(jīng)網(wǎng)絡(luò)就不會存在深度學(xué)習(xí)的人的觀點(diǎn)。
我們什么時候需要深度學(xué)習(xí)?
通用逼近定理( Universal Approximation Theorem, UAT)聲明,只有一個有限層神經(jīng)元的隱藏層足以逼近任何尋找的函數(shù)。這是一個令人印象深刻的陳述,其原因有兩個:一方面,該定理證明了神經(jīng)網(wǎng)絡(luò)的巨大能力。但是,另一方面,這是否意味著我們永遠(yuǎn)不需要深度學(xué)習(xí)?不,深吸一口氣,并不意味著……
UAT并未指定必須包含多少個神經(jīng)元。盡管單個隱藏層足以為特定函數(shù)建模,但通過多個隱藏層網(wǎng)絡(luò)學(xué)習(xí)它可能會更加有效。此外,在訓(xùn)練網(wǎng)絡(luò)時,我們正在尋找一種函數(shù),可以最好地概括數(shù)據(jù)中的關(guān)系。即使單個隱藏網(wǎng)絡(luò)能夠表示最適合訓(xùn)練示例的函數(shù),這也不意味著它可以更好地概括訓(xùn)練集中數(shù)據(jù)的行為。
Ia Goodfellow,Yahua Bengio,Aaron Courville的《深度學(xué)習(xí)》一書對此進(jìn)行了很好的解釋:
總而言之,具有單層的前饋網(wǎng)絡(luò)足以表示任何函數(shù),但是該層可能過大而無法正確學(xué)習(xí)和概括。在許多情況下,使用更深入的模型可以減少表示函數(shù)所需的單元數(shù),并可以減少泛化誤差。
總結(jié)
深度學(xué)習(xí)基本上是機(jī)器學(xué)習(xí)的子類,它是使用多個隱藏層的神經(jīng)網(wǎng)絡(luò)。它們的復(fù)雜性允許這種類型的算法自行執(zhí)行特征提取。由于它們能夠處理原始數(shù)據(jù),因此可以訪問所有信息,因此有可能找到更好的解決方案。
原文鏈接:https://quantdare.com/what-is-the-difference-between-deep-learning-and-machine-learning/
推薦閱讀
國產(chǎn)小眾瀏覽器因屏蔽視頻廣告,被索賠100萬(后續(xù))
年輕人“不講武德”:因看黃片上癮,把網(wǎng)站和786名女主播起訴了
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學(xué),西湖大學(xué)和上海交通大學(xué)的碩士博士運(yùn)營維護(hù)的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學(xué)習(xí)進(jìn)步!