
使用 Python 開發(fā)一個 Python 解釋器

原文地址:https://python.plainenglish.io/introduction-to-creating-interpreter-using-python-c2a9a6820aa0
原文作者:Umangshrestha
譯文出自:掘金翻譯計劃
本文永久鏈接:https://github.com/xitu/gold-miner/blob/master/article/2021/introduction-to-creating-interpreter-using-python.md
譯者:jaredliw
計算機只能理解機器碼。歸根結底,編程語言只是一串文字,目的是為了讓人類更容易編寫他們想讓計算機做的事情。真正的魔法是由編譯器和解釋器完成,它們彌合了兩者之間的差距。解釋器逐行讀取代碼并將其轉換為機器碼。
在本文中,我們將設計一個可以執(zhí)行算術運算的解釋器。
我們不會重新造輪子。文章將使用由 David M. Beazley 開發(fā)的詞法解析器 —— PLY(Python Lex-Yacc(https://github.com/dabeaz/ply))。
PLY 可以通過以下方式下載:
$?pip?install?ply
我們將粗略地瀏覽一下創(chuàng)建解釋器所需的基礎知識。欲了解更多,請參閱這個 GitHub 倉庫(https://github.com/dabeaz/ply)。
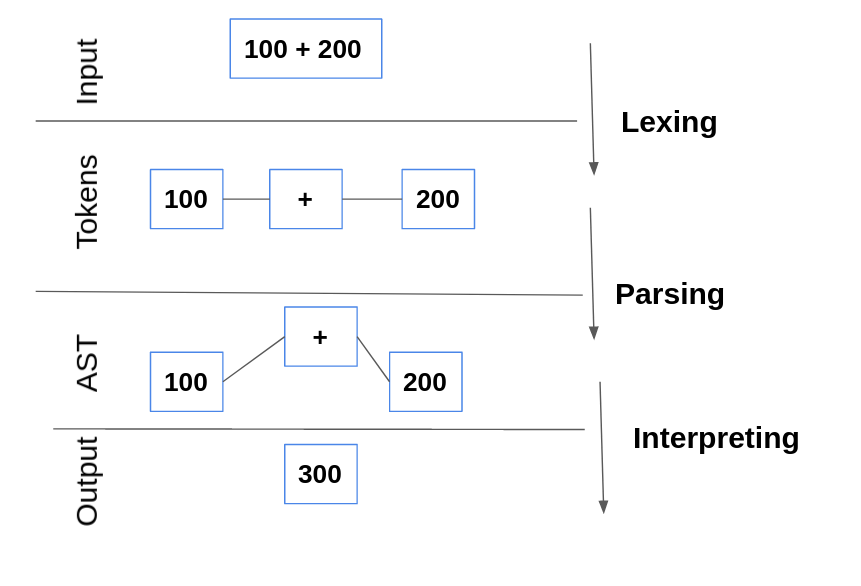
標記(Token)
標記是為解釋器提供有意義信息的最小字符單位。標記包含一對名稱和屬性值。
讓我們從創(chuàng)建標記名稱列表開始。這是一個必要的步驟。
tokens?=?(
????#?數(shù)據(jù)類型
????"NUM",
????"FLOAT",
????#?算術運算
????"PLUS",
????"MINUS",
????"MUL",
????"DIV",
????#?括號
????"LPAREN",
????"RPAREN",
)
詞法分析器(Lexer)
將語句轉換為標記的過程稱為標記化或詞法分析。執(zhí)行詞法分析的程序是詞法分析器。
#?標記的正則表達
t_PLUS???=?r"\+"
t_MINUS??=?r"\-"
t_MUL????=?r"\*"
t_DIV????=?r"/"
t_LPAREN?=?r"\("
t_RPAREN?=?r"\)"
t_POW????=?r"\^"
#?忽略空格和制表符
t_ignore?=?"?\t"
#?為每個規(guī)則添加動作
def?t_FLOAT(t):
????r"""\d+\.\d+"""
????t.value?=?float(t.value)
????return?t
def?t_NUM(t):
????r"""\d+"""
????t.value?=?int(t.value)
????return?t
#?未定義規(guī)則字符的錯誤處理
def?t_error(t):
????#?此處的?t.value?包含未標記的其余輸入
????print(f"keyword?not?found:?{t.value[0]}\nline?{t.lineno}")
????t.lexer.skip(1)
#?如果遇到?\n?則將其設為新的一行
def?t_newline(t):
????r"""\n+"""
????t.lexer.lineno?+=?t.value.count("\n")
為導入詞法分析器,我們將使用:
import ply.lex as lex
t_ 是一個特殊的前綴,表示定義標記的規(guī)則。每條詞法規(guī)則都是用正則表達式制作的,與 Python 中的 re 模塊兼容。正則表達式能夠根據(jù)規(guī)則掃描輸入并搜索符合的符號串。正則表達式定義的文法稱為正則文法。正則文法定義的語言則稱為正則語言。
定義好了規(guī)則,我們將構建詞法分析器。
data?=?'a?=?2?+(10?-8)/1.0'
lexer?=?lex.lex()
lexer.input(data)
while?tok?:=?lexer.token():
????print(tok)
為了傳遞輸入字符串,我們使用 lexer.input(data)。lexer.token() 將返回下一個 LexToken 實例,最后返回 None。根據(jù)上述規(guī)則,代碼 2 + ( 10 -8)/1.0 的標記將是:

紫色字符代表的是標記的名稱,其后是標記的具體內容。
巴科斯-諾爾范式(Backus-Naur Form,BNF)
大多數(shù)編程語言都可以用上下文無關文法來編寫。它比常規(guī)語言更復雜。對于上下文無關文法,我們用上下文無關語法,它是描述語言中所有可能語法的規(guī)則集。BNF 是一種定義語法的方式,它描述了編程語言的語法。讓我們看看例子:
symbol : alternative1 | alternative2 …
根據(jù)產生式,: 的左側被替換為右側的其中一個值替換。右側的值由 | 分隔(可理解為 symbol 定義為 alternative1 或 alternative2或…… 等等)。對于我們的這個算術解釋器,語法規(guī)格如下:
expression?:?expression?'+'?expression
???????????|?expression?'-'?expression
???????????|?expression?'/'?expression
???????????|?expression?'*'?expression
???????????|?expression?'^'?expression
???????????|?+expression
???????????|?-expression
???????????|?(?expression?)
???????????|?NUM
???????????|?FLOAT
輸入的標記是諸如 NUM、FLOAT、+、-、*、/ 之類的符號,稱作終端(無法繼續(xù)分解或產生其他符號的字符)。一個表達式由終端和規(guī)則集組成,例如 expression 則稱為非終端。有關 BNF 的更多信息,請參閱此處(https://isaaccomputerscience.org/concepts/dsa_toc_bnf)。
解析器(Parser)
我們將使用 YACC(Yet Another Compiler Compiler) 作為解析器生成器。導入模塊:import ply.yacc as yacc。
from?operator?import?(add,?sub,?mul,?truediv,?pow)
#?我們的解釋器支持的運算符列表
ops?=?{
????"+":?add,
????"-":?sub,
????"*":?mul,
????"/":?truediv,
????"^":?pow,
}
def?p_expression(p):
????"""expression?:?expression?PLUS?expression
??????????????????|?expression?MINUS?expression
??????????????????|?expression?DIV?expression
??????????????????|?expression?MUL?expression
??????????????????|?expression?POW?expression"""
????if?(p[2],?p[3])?==?("/",?0):
????????#?如果除以?0,則將“INF”(無限)作為值
????????p[0]?=?float("INF")
????else:
????????p[0]?=?ops[p[2]](p[1],?p[3])
def?p_expression_uplus_or_expr(p):
????"""expression?:?PLUS?expression?%prec?UPLUS
??????????????????|?LPAREN?expression?RPAREN"""
????p[0]?=?p[2]
def?p_expression_uminus(p):
????"""expression?:?MINUS?expression?%prec?UMINUS"""
????p[0]?=?-p[2]
def?p_expression_num(p):
????"""expression?:?NUM
??????????????????|?FLOAT"""
????p[0]?=?p[1]
#?語法錯誤時的規(guī)則
def?p_error(p):
????print(f"Syntax?error?in?{p.value}")
在文檔字符串中,我們將添加適當?shù)恼Z法規(guī)范。p 列表中的的元素與語法符號一一對應,如下所示:
expression?:?expression?PLUS?expression
p[0]?????????p[1]???????p[2]?p[3]
在上文中,%prec UPLUS 和 %prec UMINUS 是用來表示自定義運算的。%prec 即是 precedence 的縮寫。在符號中本來沒有 UPLUS 和 UMINUS 這個說法(在本文中這兩個自定義運算表示一元正號和符號,其實 UPLUS 和 UMINUS 只是個名字,想取什么就取什么)。之后,我們可以添加基于表達式的規(guī)則。YACC 允許為每個令牌分配優(yōu)先級。我們可以使用以下方法設置它:
precedence?=?(
????("left",?"PLUS",?"MINUS"),
????("left",?"MUL",?"DIV"),
????("left",?"POW"),
????("right",?"UPLUS",?"UMINUS")
)
在優(yōu)先級聲明中,標記按優(yōu)先級從低到高的順序排列。PLUS 和 MINUS 優(yōu)先級相同并且具有左結合性(運算從左至右執(zhí)行)。MUL 和 DIV 的優(yōu)先級高于 PLUS 和 MINUS,也具有左結合性。POW 亦是如此,不過優(yōu)先級更高。UPLUS 和 UMINUS 則是具有右結合性(運算從右至左執(zhí)行)。
要解析輸入我們將使用:
parser?=?yacc.yacc()
result?=?parser.parse(data)
print(result)
完整代碼如下:
#####################################
#?引入模塊???????????????????????????#
#####################################
from?logging?import?(basicConfig,?INFO,?getLogger)
from?operator?import?(add,?sub,?mul,?truediv,?pow)
import?ply.lex?as?lex
import?ply.yacc?as?yacc
#?我們的解釋器支持的運算符列表
ops?=?{
????"+":?add,
????"-":?sub,
????"*":?mul,
????"/":?truediv,
????"^":?pow,
}
#####################################
#?標記集?????????????????????????????#
#####################################
tokens?=?(
????#?數(shù)據(jù)類型
????"NUM",
????"FLOAT",
????#?算術運算
????"PLUS",
????"MINUS",
????"MUL",
????"DIV",
????"POW",
????#?括號
????"LPAREN",
????"RPAREN",
)
#####################################
#?標記的正則表達式????????????????????#
#####################################
t_PLUS???=?r"\+"
t_MINUS??=?r"\-"
t_MUL????=?r"\*"
t_DIV????=?r"/"
t_LPAREN?=?r"\("
t_RPAREN?=?r"\)"
t_POW????=?r"\^"
#?忽略空格和制表符
t_ignore?=?"?\t"
#?為每個規(guī)則添加動作
def?t_FLOAT(t):
????r"""\d+\.\d+"""
????t.value?=?float(t.value)
????return?t
def?t_NUM(t):
????r"""\d+"""
????t.value?=?int(t.value)
????return?t
#?未定義規(guī)則字符的錯誤處理
def?t_error(t):
????#?此處的?t.value?包含未標記的其余輸入
????print(f"keyword?not?found:?{t.value[0]}\nline?{t.lineno}")
????t.lexer.skip(1)
#?如果看到?\n?則將其設為新的一行
def?t_newline(t):
????r"""\n+"""
????t.lexer.lineno?+=?t.value.count("\n")
#####################################
#?設置符號優(yōu)先級??????????????????????#
#####################################
precedence?=?(
????("left",?"PLUS",?"MINUS"),
????("left",?"MUL",?"DIV"),
????("left",?"POW"),
????("right",?"UPLUS",?"UMINUS")
)
#####################################
#?書寫?BNF?規(guī)則??????????????????????#
#####################################
def?p_expression(p):
????"""expression?:?expression?PLUS?expression
??????????????????|?expression?MINUS?expression
??????????????????|?expression?DIV?expression
??????????????????|?expression?MUL?expression
??????????????????|?expression?POW?expression"""
????if?(p[2],?p[3])?==?("/",?0):
????????#?如果除以?0,則將“INF”(無限)作為值
????????p[0]?=?float("INF")
????else:
????????p[0]?=?ops[p[2]](p[1],?p[3])
def?p_expression_uplus_or_expr(p):
????"""expression?:?PLUS?expression?%prec?UPLUS
??????????????????|?LPAREN?expression?RPAREN"""
????p[0]?=?p[2]
def?p_expression_uminus(p):
????"""expression?:?MINUS?expression?%prec?UMINUS"""
????p[0]?=?-p[2]
def?p_expression_num(p):
????"""expression?:?NUM
??????????????????|?FLOAT"""
????p[0]?=?p[1]
#?語法錯誤時的規(guī)則
def?p_error(p):
????print(f"Syntax?error?in?{p.value}")
#####################################
#?主程式?????????????????????????????#
#####################################
if?__name__?==?"__main__":
????basicConfig(level=INFO,?filename="logs.txt")
????lexer?=?lex.lex()
????parser?=?yacc.yacc()
????while?True:
????????try:
????????????result?=?parser.parse(
????????????????input(">>>"),
????????????????debug=getLogger())
????????????print(result)
????????except?AttributeError:
????????????print("invalid?syntax")
結論
由于這個話題的體積龐大,這篇文章并不能將事物完全的解釋清楚,但我希望你能很好地理解文中涵蓋的表層知識。我很快會發(fā)布關于這個話題的其他文章。謝謝你,祝你有個美好的一天。

還不過癮?試試它們