
深度學習建模預(yù)測全流程(Python)!
點擊下方卡片,關(guān)注“新機器視覺”公眾號
視覺/圖像重磅干貨,第一時間送達
本文詳細地梳理及實現(xiàn)了深度學習模型構(gòu)建及預(yù)測的全流程,代碼示例基于python及神經(jīng)網(wǎng)絡(luò)庫keras,通過設(shè)計一個深度神經(jīng)網(wǎng)絡(luò)模型做波士頓房價預(yù)測。主要依賴的Python庫有:keras、scikit-learn、pandas、tensorflow(建議可以安裝下anaconda包,自帶有常用的python庫)
一、基礎(chǔ)介紹
機器學習
機器學習的核心是通過模型從數(shù)據(jù)中學習并利用經(jīng)驗去決策。進一步的,機器學習一般可以概括為:從數(shù)據(jù)出發(fā),選擇某種模型,通過優(yōu)化算法更新模型的參數(shù)值,使任務(wù)的指標表現(xiàn)變好(學習目標),最終學習到“好”的模型,并運用模型對數(shù)據(jù)做預(yù)測以完成任務(wù)。由此可見,機器學習方法有四個要素:數(shù)據(jù)、模型、學習目標、優(yōu)化算法。具體可見系列文章:一篇白話機器學習概念
深度學習
深度學習是機器學習的一個分支,它是使用多個隱藏層神經(jīng)網(wǎng)絡(luò)模型,通過大量的向量計算,學習到數(shù)據(jù)內(nèi)在規(guī)律的高階表示特征,并利用這些特征決策的過程。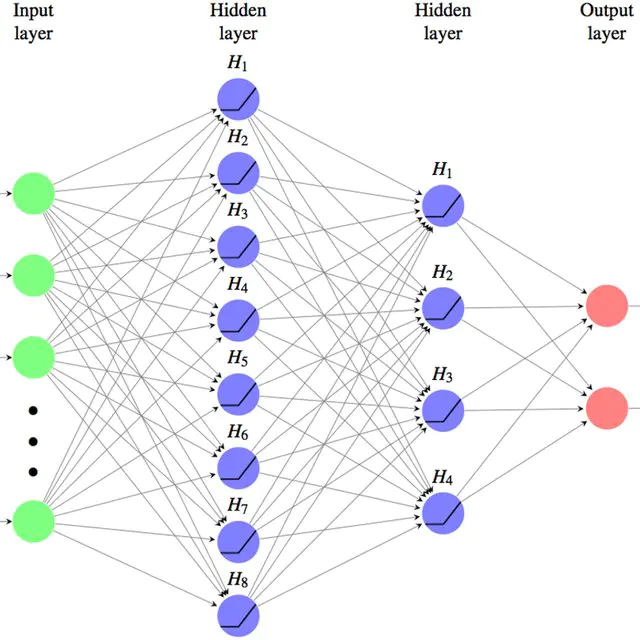
keras簡介
本文基于keras搭建神經(jīng)網(wǎng)絡(luò)模型去預(yù)測,keras是python上常用的神經(jīng)網(wǎng)絡(luò)庫。相比于tensorflow、Pytorch等庫,它對初學者很友好,開發(fā)周期較快。下圖為keras要點知識的速查表(原圖文末閱讀原文后可見):
二、建模流程
深度學習的建模預(yù)測流程,與傳統(tǒng)機器學習整體是相同的,主要區(qū)別在于深度學習是端對端學習,可以自動提取高層次特征,大大減少了傳統(tǒng)機器學習依賴的特征工程。如下詳細梳理流程的各個節(jié)點并附相應(yīng)代碼: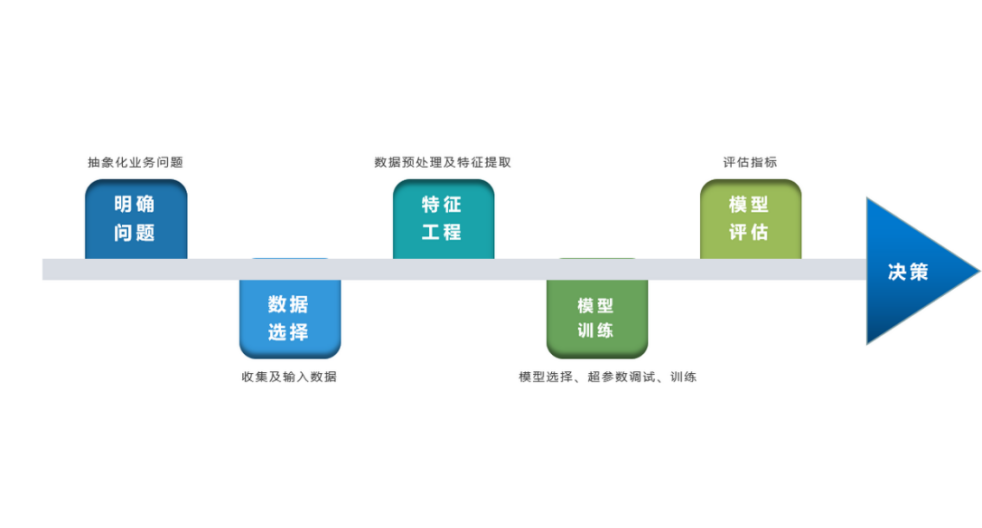
2.1 明確問題及數(shù)據(jù)選擇
2.1.1 明確問題
深度學習的建模預(yù)測,首先需要明確問題,即抽象為機器 / 深度學習的預(yù)測問題:需要學習什么樣的數(shù)據(jù)作為輸入,目標是得到什么樣的模型做決策作為輸出。
以預(yù)測房價為例,我們需要輸入:和房價有關(guān)的數(shù)據(jù)信息為特征x,對應(yīng)的房價為y作為監(jiān)督信息。再通過神經(jīng)網(wǎng)絡(luò)模型學習特征x到房價y內(nèi)在的映射關(guān)系。通過學習好的模型輸入需要預(yù)測數(shù)據(jù)的特征x,輸出模型預(yù)測Y。對于一個良好的模型,它預(yù)測房價Y應(yīng)該和實際y很接近。
2.1.2 數(shù)據(jù)選擇
深度學習是端對端學習,學習過程中會提取到高層次抽象的特征,大大弱化特征工程的依賴,正因為如此,數(shù)據(jù)選擇也顯得格外重要,其決定了模型效果的上限。如果數(shù)據(jù)質(zhì)量差,預(yù)測的結(jié)果自然也是很差的——業(yè)界一句名言“garbage in garbage out”。
數(shù)據(jù)選擇是準備機器 / 深度學習原料的關(guān)鍵,需要關(guān)注的是:
①數(shù)據(jù)樣本規(guī)模:對于深度學習等復雜模型,通常樣本量越多越好。如《Revisiting Unreasonable Effectiveness of Data in Deep Learning Era 》等研究,一定規(guī)模下,深度學習性能會隨著數(shù)據(jù)量的增加而增加。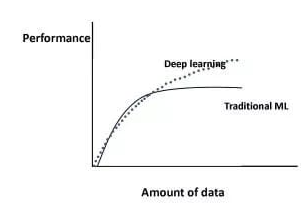 然而工程實踐中,受限于硬件支持、標注標簽成本等原因,樣本的數(shù)據(jù)量通常是比較有限的,這也是機器學習的重難點。對于模型所需最少的樣本量,其實沒有固定準則,需要要結(jié)合實際樣本特征、任務(wù)復雜度等具體情況(經(jīng)驗上,對于分類任務(wù),每個類別要上千的樣本數(shù))。當樣本數(shù)據(jù)量較少以及樣本不均衡情況,深度學習常用到數(shù)據(jù)增強的方法,具體可見系列文章:《數(shù)據(jù)增強方法的歸納》
然而工程實踐中,受限于硬件支持、標注標簽成本等原因,樣本的數(shù)據(jù)量通常是比較有限的,這也是機器學習的重難點。對于模型所需最少的樣本量,其實沒有固定準則,需要要結(jié)合實際樣本特征、任務(wù)復雜度等具體情況(經(jīng)驗上,對于分類任務(wù),每個類別要上千的樣本數(shù))。當樣本數(shù)據(jù)量較少以及樣本不均衡情況,深度學習常用到數(shù)據(jù)增強的方法,具體可見系列文章:《數(shù)據(jù)增強方法的歸納》
② 數(shù)據(jù)的代表性:數(shù)據(jù)質(zhì)量差、無代表性,會導致模型擬合效果差。需要明確與任務(wù)相關(guān)的數(shù)據(jù)表范圍,避免缺失代表性數(shù)據(jù)或引入大量無關(guān)數(shù)據(jù)作為噪音。
③ 數(shù)據(jù)時間范圍:對于監(jiān)督學習的特征變量x及標簽y,如與時間先后有關(guān),則需要劃定好數(shù)據(jù)時間窗口,否則可能會導致常見的數(shù)據(jù)泄漏問題,即存在了特征與標簽因果顛倒的情況。
以預(yù)測房價任務(wù)為例,對數(shù)據(jù)選擇進行說明:
收集房價相關(guān)的數(shù)據(jù)信息(特征維度)和對應(yīng)房價(標簽),以及盡量多的樣本數(shù)。數(shù)據(jù)信息如該區(qū)域的繁華程度、教育資源、治安等情況就和預(yù)測的房價比較相關(guān),有代表性。而諸如該區(qū)域“人均養(yǎng)的兔子數(shù)”類數(shù)據(jù)信息,對房價的預(yù)測就沒那么相關(guān),對于無代表性的數(shù)據(jù)特征的加入,主要會增加人工處理的成本、計算復雜度,還有可能引入了模型學習的噪音。
劃定好數(shù)據(jù)時間窗口。比如我們可以學習該區(qū)域歷史2010~2020年的房價,預(yù)測未來2021的房價(這是一個經(jīng)典的時間序列預(yù)測問題,常用RNN模型)。但卻不能學習了2021年或者更后面的未來房價、人口數(shù)等相關(guān)信息,反過來去預(yù)測2021年房價,這就是一個數(shù)據(jù)泄露的問題(模型都學習了與標簽相關(guān)等未知的信息,還預(yù)測個啥?)。
本節(jié)代碼
如下加載數(shù)據(jù)的代碼,使用的是keras自帶的波士頓房價數(shù)據(jù)集。一些常用的機器學習開源數(shù)據(jù)集可以到kaggle.com/datasets、archive.ics.uci.edu等網(wǎng)站下載。
from?keras.datasets?import?boston_housing?#導入波士頓房價數(shù)據(jù)集
(train_x,?train_y),?(test_x,?test_y)?=?boston_housing.load_data()
波士頓房價數(shù)據(jù)集是統(tǒng)計20世紀70年代中期波士頓郊區(qū)房價等情況,有當時城鎮(zhèn)的犯罪率、房產(chǎn)稅等共計13個指標(特征)以及對應(yīng)的房價中位數(shù)(標簽)。
2.2 特征工程
特征工程就是對原始數(shù)據(jù)分析處理,轉(zhuǎn)化為模型可用的特征。這些特征可以更好地向預(yù)測模型描述潛在規(guī)律,從而提高模型對未見數(shù)據(jù)的準確性。對于深度學習模型,特征生成等加工不多,主要是一些數(shù)據(jù)的分析、預(yù)處理,然后就可以灌入神經(jīng)網(wǎng)絡(luò)模型了。
2.2.1 ?探索性數(shù)據(jù)分析
選擇好數(shù)據(jù)后,可以先做探索性數(shù)據(jù)分析(EDA)去理解數(shù)據(jù)本身的內(nèi)部結(jié)構(gòu)及規(guī)律。如果你對數(shù)據(jù)情況不了解,也沒有相關(guān)的業(yè)務(wù)背景知識,不做相關(guān)的分析及預(yù)處理,直接將數(shù)據(jù)喂給模型往往效果不太好。通過探索性數(shù)據(jù)分析,可以了解數(shù)據(jù)分布、缺失、異常及相關(guān)性等情況。
本節(jié)代碼
我們可以通過EDA數(shù)據(jù)分析庫如pandas profiling,自動生成分析報告,可以看到這份現(xiàn)成的數(shù)據(jù)集是比較"干凈的":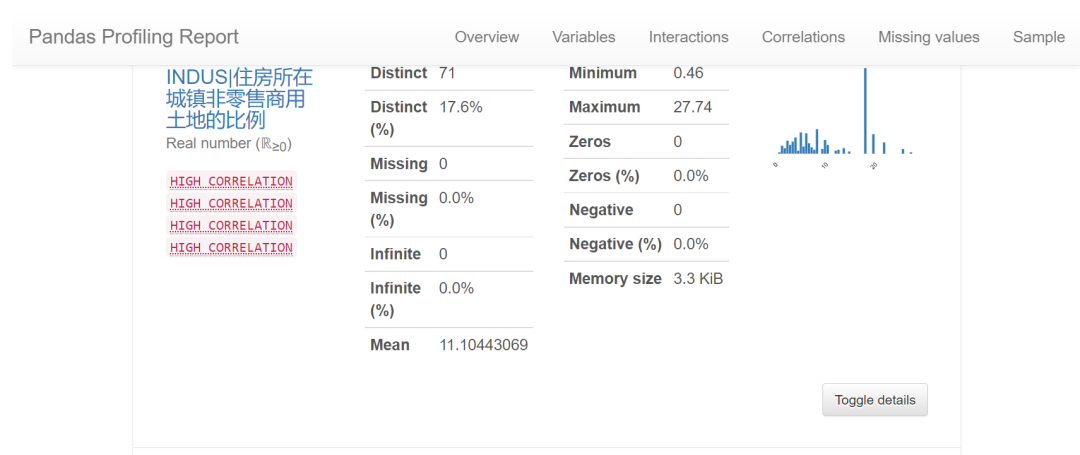
import?pandas?as?pd?
import?pandas_profiling
#??特征名稱
feature_name?=?['CRIM|住房所在城鎮(zhèn)的人均犯罪率',
?'ZN|住房用地超過?25000?平方尺的比例',
?'INDUS|住房所在城鎮(zhèn)非零售商用土地的比例',
?'CHAS|有關(guān)查理斯河的虛擬變量(如果住房位于河邊則為1,否則為0?)',
?'NOX|一氧化氮濃度',
?'RM|每處住房的平均房間數(shù)',
?'AGE|建于?1940?年之前的業(yè)主自住房比例',
?'DIS|住房距離波士頓五大中心區(qū)域的加權(quán)距離',
?'RAD|距離住房最近的公路入口編號',
?'TAX?每?10000?美元的全額財產(chǎn)稅金額',
?'PTRATIO|住房所在城鎮(zhèn)的師生比例',
?'B|1000(Bk|0.63)^2,其中?Bk?指代城鎮(zhèn)中黑人的比例',
?'LSTAT|弱勢群體人口所占比例']
train_df?=?pd.DataFrame(train_x,?columns=feature_name)??#?轉(zhuǎn)為df格式
pandas_profiling.ProfileReport(train_df)??
2.2.2 特征表示
像圖像、文本字符類的數(shù)據(jù),需要轉(zhuǎn)換為計算機能夠處理的數(shù)值形式。圖像數(shù)據(jù)(pixel image)實際上是由一個像素組成的矩陣所構(gòu)成的,而每一個像素點又是由RGB顏色通道中分別代表R、G、B的一個三維向量表示,所以圖像實際上可以用RGB三維矩陣(3-channel matrix)的表示(第一個維度:高度,第二個維度:寬度,第三個維度:RGB通道),最終再重塑為一列向量(reshaped image vector)方便輸入模型。
文本類(類別型)的數(shù)據(jù)可以用多維數(shù)組表示,包括:① ONEHOT(獨熱編碼)表示:它是用單獨一個位置的0或1來表示每個變量值,這樣就可以將每個不同的字符取值用唯一的多維數(shù)組來表示,將文字轉(zhuǎn)化為數(shù)值。如字符類的性別信息就可以轉(zhuǎn)換為“是否為男”、“是否為女”、“未知”等特征。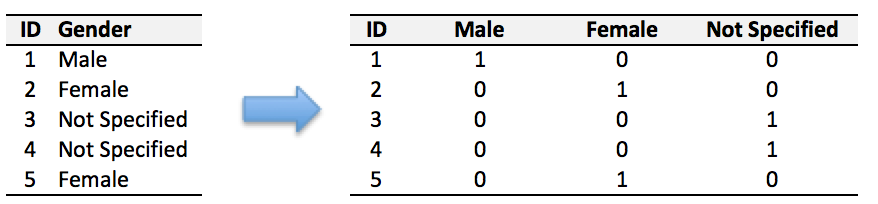
②word2vetor分布式表示:它基本的思想是通過神經(jīng)網(wǎng)絡(luò)模型學習每個單詞與鄰近詞的關(guān)系,從而將單詞表示成低維稠密向量。通過這樣的分布式表示可以學習到單詞的語義信息,直觀來看語義相似的單詞其對應(yīng)的向量距離相近。
本節(jié)代碼
數(shù)據(jù)集已是數(shù)值類數(shù)據(jù),本節(jié)不做處理。
2.2.2 特征清洗
異常值處理 收集的數(shù)據(jù)由于人為或者自然因素可能引入了異常值(噪音),這會對模型學習進行干擾。通常需要處理人為引起的異常值,通過業(yè)務(wù)及技術(shù)手段(如數(shù)據(jù)分布、3σ準則)判定異常值,再結(jié)合實際業(yè)務(wù)含義刪除或者替換掉異常值。
缺失值處理 神經(jīng)網(wǎng)絡(luò)模型缺失值的處理是必要的,數(shù)據(jù)缺失值可以通過結(jié)合業(yè)務(wù)進行填充數(shù)值或者刪除。① 缺失率較高,結(jié)合業(yè)務(wù)可以直接刪除該特征變量。經(jīng)驗上可以新增一個bool類型的變量特征記錄該字段的缺失情況,缺失記為1,非缺失記為0;② 缺失率較低,可使用一些缺失值填充手段,如結(jié)合業(yè)務(wù)fillna為0或-9999或平均值,或者訓練回歸模型預(yù)測缺失值并填充。
本節(jié)代碼
從數(shù)據(jù)分析報告可見,波士頓房價數(shù)據(jù)集無異常、缺失值情況,本節(jié)不做處理。
2.2.3 ?特征生成
特征生成作用在于彌補基礎(chǔ)特征對樣本信息的表達有限,增加特征的非線性表達能力,提升模型效果。它是根據(jù)基礎(chǔ)特征的含義進行某種處理(聚合 / 轉(zhuǎn)換之類),常用方法如人工設(shè)計、自動化特征衍生(如featuretools工具):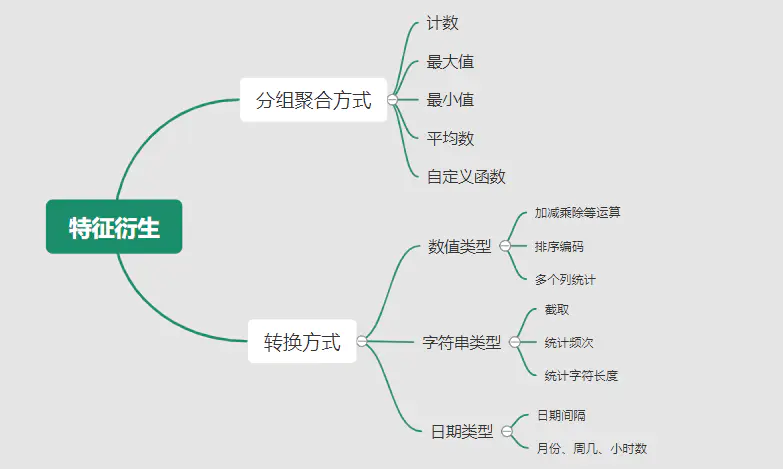 深度神經(jīng)網(wǎng)絡(luò)會自動學習到高層次特征,常見的深度學習的任務(wù),圖像類、文本類任務(wù)通常很少再做特征生成。而對于數(shù)值類的任務(wù),加工出顯著特征對加速模型的學習是有幫助的,可以做嘗試。具體可見系列文章:一文歸納Python特征生成方法(全)
深度神經(jīng)網(wǎng)絡(luò)會自動學習到高層次特征,常見的深度學習的任務(wù),圖像類、文本類任務(wù)通常很少再做特征生成。而對于數(shù)值類的任務(wù),加工出顯著特征對加速模型的學習是有幫助的,可以做嘗試。具體可見系列文章:一文歸納Python特征生成方法(全)
本節(jié)代碼
特征已經(jīng)比較全面,本節(jié)不再做處理,可自行驗證特征生成的效果。
2.2.4 ?特征選擇
特征選擇用于篩選出顯著特征、摒棄非顯著特征。這樣做主要可以減少特征(避免維度災(zāi)難),提高訓練速度,降低運算開銷;減少干擾噪聲,降低過擬合風險,提升模型效果。常用的特征選擇方法有:過濾法(如特征缺失率、單值率、相關(guān)系數(shù))、包裝法(如RFE遞歸特征消除、雙向搜索)、嵌入法(如帶L1正則項的模型、樹模型自帶特征選擇)。具體可見系列文章:Python特征選擇(全)
本節(jié)代碼
模型使用L1正則項方法,本節(jié)不再做處理,可自行驗證其他方法。
2.3 模型訓練
神經(jīng)網(wǎng)絡(luò)模型的訓練主要有3個步驟:
構(gòu)建模型結(jié)構(gòu)(主要有神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計、激活函數(shù)的選擇、模型權(quán)重如何初始化、網(wǎng)絡(luò)層是否批標準化、正則化策略的設(shè)定) 模型編譯(主要有學習目標、優(yōu)化算法的設(shè)定) 模型訓練及超參數(shù)調(diào)試(主要有劃分數(shù)據(jù)集,超參數(shù)調(diào)節(jié)及訓練)
2.3.1 模型結(jié)構(gòu)
常見的神經(jīng)網(wǎng)絡(luò)模型結(jié)構(gòu)有全連接神經(jīng)網(wǎng)絡(luò)(FCN)、RNN(常用于文本 / 時間系列任務(wù))、CNN(常用于圖像任務(wù))等等。具體可以看之前文章:一文概覽神經(jīng)網(wǎng)絡(luò)模型
神經(jīng)網(wǎng)絡(luò)由輸入層、隱藏層與輸出層構(gòu)成。不同的層數(shù)、神經(jīng)元(計算單元)數(shù)目的模型性能也會有差異。
輸入層:為數(shù)據(jù)特征輸入層,輸入數(shù)據(jù)特征維數(shù)就對應(yīng)著網(wǎng)絡(luò)的神經(jīng)元數(shù)。(注:輸入層不計入模型層數(shù)) 隱藏層:即網(wǎng)絡(luò)的中間層(可以很多層),其作用接受前一層網(wǎng)絡(luò)輸出作為當前的輸入值,并計算輸出當前結(jié)果到下一層。隱藏層的層數(shù)及神經(jīng)元個數(shù)直接影響模型的擬合能力。 輸出層:為最終結(jié)果輸出的網(wǎng)絡(luò)層。輸出層的神經(jīng)元個數(shù)代表了分類類別的個數(shù)(注:在做二分類時情況特殊一點,如果輸出層的激活函數(shù)采用sigmoid,輸出層的神經(jīng)元個數(shù)為1個;如果采用softmax,輸出層神經(jīng)元個數(shù)為2個是與分類類別個數(shù)對應(yīng)的;) 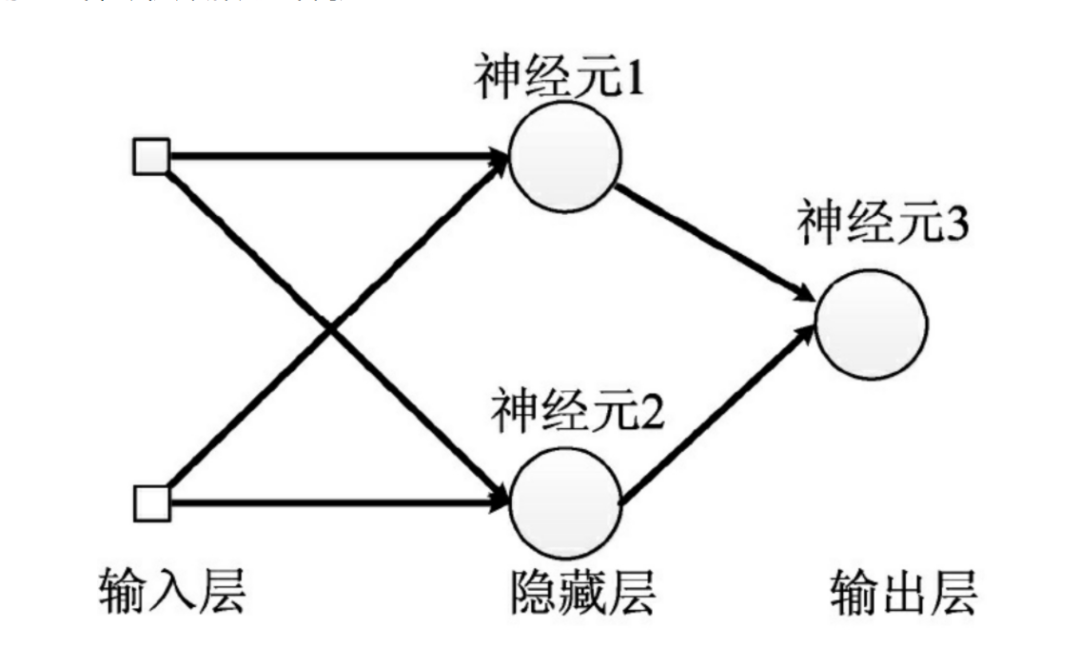
對于模型結(jié)構(gòu)的神經(jīng)元個數(shù) ,輸入層、輸出層的神經(jīng)元個數(shù)通常是確定的,主要需要考慮的是隱藏層的深度及寬度,在忽略網(wǎng)絡(luò)退化問題的前提下,通常隱藏層的神經(jīng)元的越多,模型有更多的容量(capcity)去達到更好的擬合效果(也更容易過擬合)。搜索合適的網(wǎng)絡(luò)深度及寬度,常用有人工經(jīng)驗調(diào)參、隨機 / 網(wǎng)格搜索、貝葉斯優(yōu)化等方法。經(jīng)驗上的做法,可以參照下同類任務(wù)效果良好的神經(jīng)網(wǎng)絡(luò)模型的結(jié)構(gòu),結(jié)合實際的任務(wù),再做些微調(diào)。
2.3.2 激活函數(shù)
根據(jù)萬能近似原理,簡單來說,神經(jīng)網(wǎng)絡(luò)有“夠深的網(wǎng)絡(luò)層”以及“至少一層帶激活函數(shù)的隱藏層”,既可以擬合任意的函數(shù)。可見激活函數(shù)的重要性,它起著特征空間的非線性轉(zhuǎn)換。對于激活函數(shù)選擇的經(jīng)驗性做法:
對于輸出層,二分類的輸出層的激活函數(shù)常選擇sigmoid函數(shù),多分類選擇softmax;回歸任務(wù)根據(jù)輸出值范圍來確定使不使用激活函數(shù)。 對于隱藏層的激活函數(shù)通常會選擇使用ReLU函數(shù),保證學習效率。具體可見序列文章:一文講透神經(jīng)網(wǎng)絡(luò)的激活函數(shù)
2.3.3 權(quán)重初始化
權(quán)重參數(shù)初始化可以加速模型收斂速度,影響模型結(jié)果。常用的初始化方法有:
uniform均勻分布初始化 normal高斯分布初始化 需要注意的是,權(quán)重不能初始化為0,這會導致多個隱藏神經(jīng)元的作用等同于1個神經(jīng)元,無法收斂。
2.3.4 批標準化
batch normalization(BN)批標準化,是神經(jīng)網(wǎng)絡(luò)模型常用的一種優(yōu)化方法。它的原理很簡單,即是對原來的數(shù)值進行標準化處理: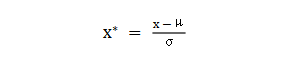 batch normalization在保留輸入信息的同時,消除了層與層間的分布差異,具有加快收斂,同時有類似引入噪聲正則化的效果。它可應(yīng)用于網(wǎng)絡(luò)的輸入層或隱藏層,當用于輸入層,就是線性模型常用的特征標準化處理。
batch normalization在保留輸入信息的同時,消除了層與層間的分布差異,具有加快收斂,同時有類似引入噪聲正則化的效果。它可應(yīng)用于網(wǎng)絡(luò)的輸入層或隱藏層,當用于輸入層,就是線性模型常用的特征標準化處理。
2.3.5 正則化
正則化是在以(可能)增加經(jīng)驗損失為代價,以降低泛化誤差為目的,抑制過擬合,提高模型泛化能力的方法。經(jīng)驗上,對于復雜任務(wù),深度學習模型偏好帶有正則化的較復雜模型,以達到較好的學習效果。常見的正則化策略有:dropout,L1、L2、earlystop方法。具體可見序列文章:一文深層解決模型過擬合
2.3.6 選擇學習目標
機器 / 深度學習通過學習到“好”的模型去決策,“好”即是機器 / 深度學習的學習目標,通常也就是預(yù)測值與目標值之間的誤差盡可能的低。衡量這種誤差的函數(shù)稱為代價函數(shù) (Cost Function)或者損失函數(shù)(Loss Function),更具體地說,機器 / 深度學習的目標是極大化降低損失函數(shù)。
對于不同的任務(wù),往往也需要用不同損失函數(shù)衡量,經(jīng)典的損失函數(shù)包括回歸任務(wù)的均方誤差損失函數(shù)及二分類任務(wù)的交叉熵損失函數(shù)等。
均方誤差損失函數(shù)
衡量模型回歸預(yù)測的誤差情況,一個簡單思路是用各個樣本i的預(yù)測值f(x;w)減去實際值y求平方后的平均值,這也就是經(jīng)典的均方誤差(Mean Squared Error)損失函數(shù)。通過極小化降低均方誤差損失函數(shù),可以使得模型預(yù)測值與實際值數(shù)值差異盡量小。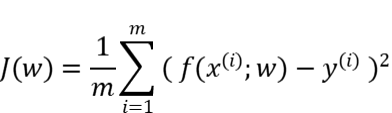
交叉熵損失函數(shù)
衡量二分類預(yù)測模型的誤差情況,常用交叉熵損失函數(shù),使得模型預(yù)測分布盡可能與實際數(shù)據(jù)經(jīng)驗分布一致(最大似然估計)。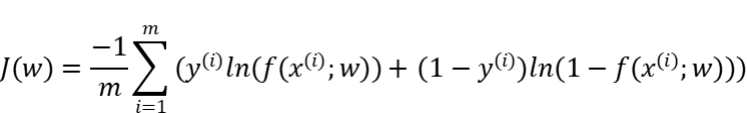 另外,還有一些針對優(yōu)化難點而設(shè)計的損失函數(shù),如Huber Loss主要用于解決回歸問題中,存在奇點數(shù)據(jù)帶偏模型訓練的問題。Focal Loss主要解決分類問題中類別不均衡導致的模型訓偏問題。
另外,還有一些針對優(yōu)化難點而設(shè)計的損失函數(shù),如Huber Loss主要用于解決回歸問題中,存在奇點數(shù)據(jù)帶偏模型訓練的問題。Focal Loss主要解決分類問題中類別不均衡導致的模型訓偏問題。
2.3.7 選擇優(yōu)化算法
當我們機器 / 深度學習的學習目標是極大化降低(某個)損失函數(shù),那么如何實現(xiàn)這個目標呢?通常機器學習模型的損失函數(shù)較復雜,很難直接求損失函數(shù)最小的公式解。幸運的是,我們可以通過優(yōu)化算法(如梯度下降、隨機梯度下降、Adam等)有限次迭代優(yōu)化模型參數(shù),以盡可能降低損失函數(shù)的值,得到較優(yōu)的參數(shù)值。具體可見系列文章:一文概覽神經(jīng)網(wǎng)絡(luò)優(yōu)化算法
對于大多數(shù)任務(wù)而言,通常可以直接先試下Adam、SGD,然后可以繼續(xù)在具體任務(wù)上驗證不同優(yōu)化器效果。
2.3.8 模型訓練及超參數(shù)調(diào)試
劃分數(shù)據(jù)集
訓練模型前,常用的HoldOut驗證法(此外還有留一法、k折交叉驗證等方法),把數(shù)據(jù)集分為訓練集和測試集,并可再對訓練集進一步細分為訓練集和驗證集,以方便評估模型的性能。① 訓練集(training set):用于運行學習算法,訓練模型。② 開發(fā)驗證集(development set)用于調(diào)整模型超參數(shù)、EarlyStopping、選擇特征等,以選擇出合適模型。③ 測試集(test set)只用于評估已選擇模型的性能,但不會據(jù)此改變學習算法或參數(shù)。
超參數(shù)調(diào)試
神經(jīng)網(wǎng)絡(luò)模型的超參數(shù)是比較多的:數(shù)據(jù)方面超參數(shù) 如驗證集比例、batch size等;模型方面 如單層神經(jīng)元數(shù)、網(wǎng)絡(luò)深度、選擇激活函數(shù)類型、dropout率等;學習目標方面 如選擇損失函數(shù)類型,正則項懲罰系數(shù)等;優(yōu)化算法方面 如選擇梯度算法類型、初始學習率等。
常用的超參調(diào)試有人工經(jīng)驗調(diào)節(jié)、網(wǎng)格搜索(grid search或for循環(huán)實現(xiàn))、隨機搜索(random search)、貝葉斯優(yōu)化(bayesian optimization)等方法,方法介紹可見系列文章:一文歸納Ai調(diào)參煉丹之法。
另外,有像Keras Tuner分布式超參數(shù)調(diào)試框架(文檔見:keras.io/keras_tuner),集成了常用調(diào)參方法,還比較實用的。
本節(jié)代碼
創(chuàng)建模型結(jié)構(gòu) 結(jié)合當前房價預(yù)測任務(wù)是一個經(jīng)典簡單表格數(shù)據(jù)的回歸預(yù)測任務(wù)。我們采用基礎(chǔ)的全連接神經(jīng)網(wǎng)絡(luò),隱藏層的深度一兩層也就差不多。通過keras.Sequential方法來創(chuàng)建一個神經(jīng)網(wǎng)絡(luò)模型,并在依次添加帶有批標準化的輸入層,一層帶有relu激活函數(shù)的k個神經(jīng)元的隱藏層,并對這層隱藏層添加dropout、L1、L2正則的功能。由于回歸預(yù)測數(shù)值實際范圍(5~50+)直接用線性輸出層,不需要加激活函數(shù)。 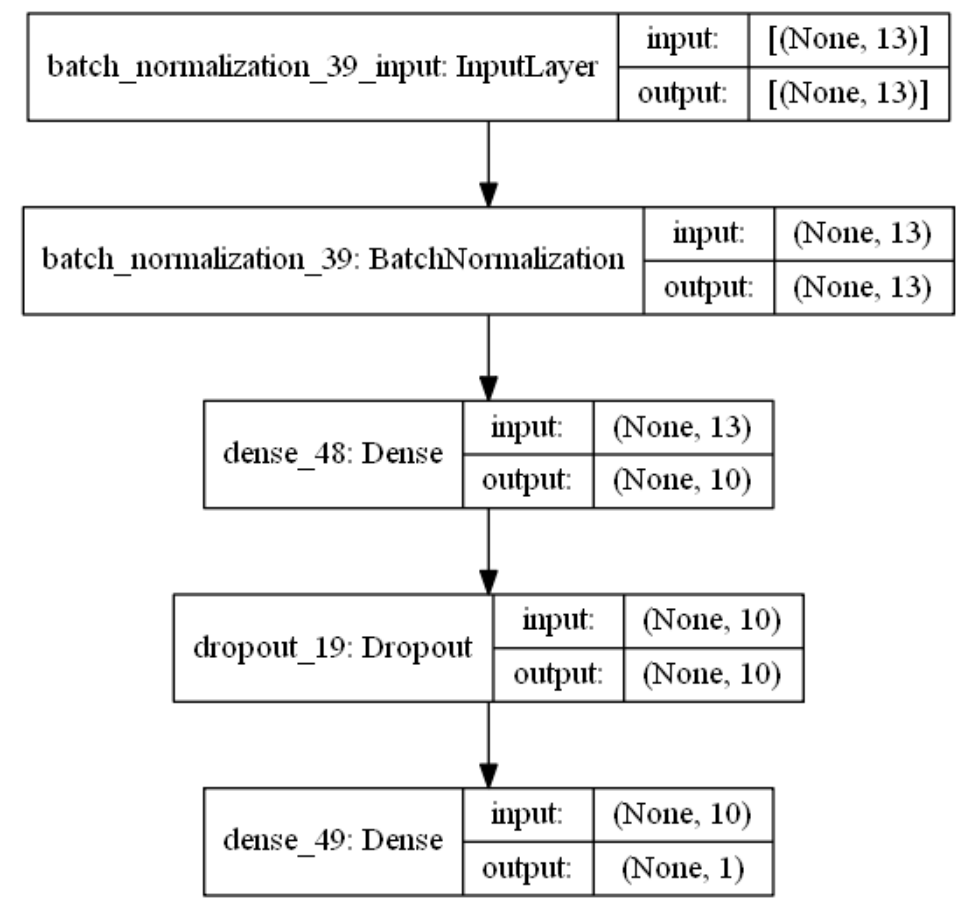
import?numpy?as?np
import??matplotlib.pyplot?as?plt
%matplotlib?inline
from?tensorflow?import?random
from?keras?import?regularizers
from?keras.layers?import?Dense,Dropout,BatchNormalization
from?keras.models?import?Sequential,?Model
from?keras.callbacks?import?EarlyStopping
from?sklearn.metrics?import??mean_squared_error
np.random.seed(1)?#?固定隨機種子,使每次運行結(jié)果固定
random.set_seed(1)
#?創(chuàng)建模型結(jié)構(gòu):輸入層的特征維數(shù)為13;1層k個神經(jīng)元的relu隱藏層;線性的輸出層;
for?k?in?[5,20,50]:??#?網(wǎng)格搜索超參數(shù):神經(jīng)元數(shù)k
????
????model?=?Sequential()
????model.add(BatchNormalization(input_dim=13))??#?輸入層?批標準化?
????model.add(Dense(k,??
????????????????????kernel_initializer='random_uniform',???#?均勻初始化
????????????????????activation='relu',?????????????????????#?relu激活函數(shù)
????????????????????kernel_regularizer=regularizers.l1_l2(l1=0.01,?l2=0.01),??#?L1及L2?正則項
????????????????????use_bias=True))???#?隱藏層
????model.add(Dropout(0.1))?#?dropout法
????model.add(Dense(1,use_bias=True))??#?輸出層
????
模型編譯 設(shè)定學習目標為(最小化)回歸預(yù)測損失mse,優(yōu)化算法為adam
????model.compile(optimizer='adam',?loss='mse')?
模型訓練 我們通過傳入訓練集x,訓練集標簽y,使用fit(擬合)方法來訓練模型,其中epochs為迭代次數(shù),并通過EarlyStopping及時停止在合適的epoch,減少過擬合;batch_size為每次epoch隨機采樣的訓練樣本數(shù)目。
#?訓練模型
????history?=?model.fit(train_x,?
????????????????????????train_y,?
????????????????????????epochs=500,??????????????#?訓練迭代次數(shù)
????????????????????????batch_size=50,???????????#?每epoch采樣的batch大小
????????????????????????validation_split=0.1,???#?從訓練集再拆分驗證集,作為早停的衡量指標
????????????????????????callbacks=[EarlyStopping(monitor='val_loss',?patience=20)],????#早停法
????????????????????????verbose=False)??#?不輸出過程??
????
????print("驗證集最優(yōu)結(jié)果:",min(history.history['val_loss']))
????model.summary()???#打印模型概述信息
????#?模型評估:擬合效果
????plt.plot(history.history['loss'],c='blue')????#?藍色線訓練集損失
????plt.plot(history.history['val_loss'],c='red')?#?紅色線驗證集損失
????plt.show()
最后,這里簡單采用for循環(huán),實現(xiàn)類似網(wǎng)格搜索調(diào)整超參數(shù),驗證了隱藏層的不同神經(jīng)元數(shù)目(超參數(shù)k)的效果。由驗證結(jié)果來看,神經(jīng)元數(shù)目為50時,損失可以達到10的較優(yōu)效果(可以繼續(xù)嘗試模型增加深度、寬度,達到過擬合的邊界應(yīng)該有更好的效果)。
注:本節(jié)使用的優(yōu)化方法較多(炫技ing),單純是為展示一遍各種深度學習的優(yōu)化tricks。模型并不是優(yōu)化方法越多越好,效果還是要實際問題具體驗證。
2.4 模型評估及優(yōu)化
機器學習學習的目標是極大化降低損失函數(shù),但這不僅僅是學習過程中對訓練數(shù)據(jù)有良好的預(yù)測能力(極低的訓練損失),根本上還在于要對新數(shù)據(jù)(測試集)能有很好的預(yù)測能力(泛化能力)。
評估模型誤差的指標
評估模型的預(yù)測誤差常用損失函數(shù)的大小來判斷,如回歸預(yù)測的均方損失。但除此之外,對于一些任務(wù),用損失函數(shù)作為評估指標并不直觀,所以像分類任務(wù)的評估還常用f1-score,可以直接展現(xiàn)各種類別正確分類情況。
查準率P:是指分類器預(yù)測為Positive的正確樣本(TP)的個數(shù)占所有預(yù)測為Positive樣本個數(shù)(TP+FP)的比例;查全率R:是指分類器預(yù)測為Positive的正確樣本(TP)的個數(shù)占所有的實際為Positive樣本個數(shù)(TP+FN)的比例。F1-score是查準率P、查全率R的調(diào)和平均:
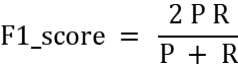
注:如分類任務(wù)的f1-score等指標只能用于評估模型最終效果,因為作為學習目標時它們無法被高效地優(yōu)化,訓練優(yōu)化時常用交叉熵作為其替代的分類損失函數(shù) (surrogate loss function)。
評估擬合效果
評估模型擬合(學習)效果,常用欠擬合、擬合良好、過擬合來表述,通常,擬合良好的模型有更好泛化能力,在未知數(shù)據(jù)(測試集)有更好的效果。
我們可以通過訓練誤差及驗證集誤差評估模型的擬合程度。從整體訓練過程來看,欠擬合時訓練誤差和驗證集誤差均較高,隨著訓練時間及模型復雜度的增加而下降。在到達一個擬合最優(yōu)的臨界點之后,訓練誤差下降,驗證集誤差上升,這個時候模型就進入了過擬合區(qū)域。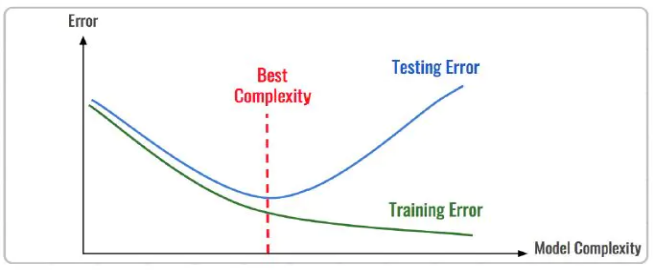
優(yōu)化擬合效果的方法
實踐中通常欠擬合不是問題,可以通過使用強特征及較復雜的模型提高學習的準確度。而解決過擬合,即如何減少泛化誤差,提高泛化能力,通常才是優(yōu)化模型效果的重點,常用的方法在于提高數(shù)據(jù)的質(zhì)量、數(shù)量以及采用適當?shù)恼齽t化策略。具體可見系列文章:一文深層解決模型過擬合
本節(jié)代碼
#?模型評估:擬合效果
import??matplotlib.pyplot?as?plt
plt.plot(history.history['loss'],c='blue')????#?藍色線訓練集損失
plt.plot(history.history['val_loss'],c='red')?#?紅色線驗證集損失
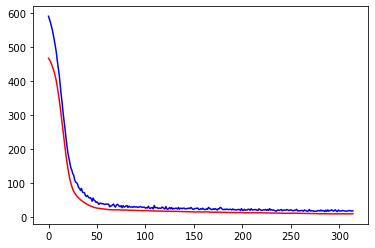 從訓練集及驗證集的損失來看,訓練集、驗證集損失都比較低,模型沒有過擬合現(xiàn)象。
從訓練集及驗證集的損失來看,訓練集、驗證集損失都比較低,模型沒有過擬合現(xiàn)象。
#?模型評估:測試集預(yù)測結(jié)果
pred_y?=?model.predict(test_x)[:,0]
print("正確標簽:",test_y)
print("模型預(yù)測:",pred_y?)
print("實際與預(yù)測值的差異:",mean_squared_error(test_y,pred_y?))
#繪圖表示
import?matplotlib.pyplot?as?plt
plt.rcParams['font.sans-serif']?=?['SimHei']
plt.rcParams['axes.unicode_minus']?=?False
#?設(shè)置圖形大小
plt.figure(figsize=(8,?4),?dpi=80)
plt.plot(range(len(test_y)),?test_y,?ls='-.',lw=2,c='r',label='真實值')
plt.plot(range(len(pred_y)),?pred_y,?ls='-',lw=2,c='b',label='預(yù)測值')
#?繪制網(wǎng)格
plt.grid(alpha=0.4,?linestyle=':')
plt.legend()
plt.xlabel('number')?#設(shè)置x軸的標簽文本
plt.ylabel('房價')?#設(shè)置y軸的標簽文本
#?展示
plt.show()
評估測試集的預(yù)測結(jié)果,其mse損失為19.7,觀察測試集的實際值與預(yù)測值兩者的數(shù)值曲線是比較一致的!模型預(yù)測效果較好。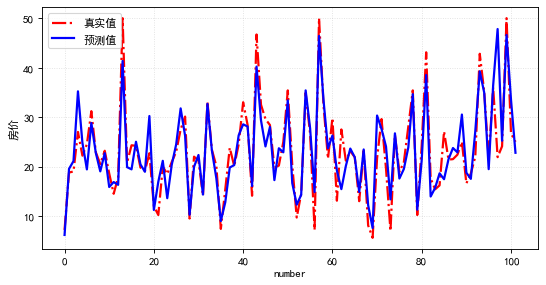
2.5 模型預(yù)測結(jié)果及解釋性
決策應(yīng)用是機器學習最終目的,對模型預(yù)測信息加以分析解釋,并應(yīng)用于實際的工作領(lǐng)域。
對于實際工作需要注意的是,工程上是結(jié)果導向,模型在線上運行的效果直接決定模型的成敗,不僅僅包括其準確程度、誤差等情況,還包括其運行的速度(時間復雜度)、資源消耗程度(空間復雜度)、穩(wěn)定性的綜合考慮。
對于神經(jīng)網(wǎng)絡(luò)模型預(yù)測的分析解釋,我們有時需要知道學習的內(nèi)容,決策的過程是怎么樣的(模型的可解釋性)。具體可見系列文章:神經(jīng)網(wǎng)絡(luò)學習到的是什么?一個可以解釋的AI模型(Explainable AI, 簡稱XAI)意味著運作的透明,便于人類對于對AI決策的監(jiān)督及接納,以保證算法的公平性、安全性及隱私性,從而創(chuàng)造更加安全可靠的應(yīng)用。深度學習可解釋性常用方法有:LIME、LRP、SHAP等方法。
本節(jié)代碼
如下通過SHAP方法,對模型預(yù)測單個樣本的結(jié)果做出解釋,可見在這個樣本的預(yù)測中,CRIM犯罪率為0.006、RM平均房間數(shù)為6.575對于房價是負相關(guān)的。LSTAT弱勢群體人口所占比例為4.98對于房價的貢獻是正相關(guān)的...,在綜合這些因素后模型給出最終預(yù)測值。
import?shap?
import?tensorflow?as?tf??#?tf版本<2.0
#?模型解釋性
background?=?test_x[np.random.choice(test_x.shape[0],100,?replace=False)]
explainer?=?shap.DeepExplainer(model,background)
shap_values?=?explainer.shap_values(test_x)??#?傳入特征矩陣X,計算SHAP值
#?可視化第一個樣本預(yù)測的解釋??
shap.force_plot(explainer.expected_value,?shap_values[0,:],?test_x.iloc[0,:])