
Python異步爬蟲進階必備,效率杠杠的!

Python異步爬蟲進階必備,
效率杠杠的!
爬蟲是 IO 密集型任務(wù),比如我們使用 requests 庫來爬取某個站點的話,發(fā)出一個請求之后,程序必須要等待網(wǎng)站返回響應(yīng)之后才能接著運行,而在等待響應(yīng)的過程中,整個爬蟲程序是一直在等待的,實際上沒有做任何的事情。
因此,有必要提高程序的運行效率,異步就是其中有效的一種方法。
今天我們一起來學(xué)習(xí)下異步爬蟲的相關(guān)內(nèi)容。
一、基本概念
阻塞
阻塞狀態(tài)指程序未得到所需計算資源時被掛起的狀態(tài)。程序在等待某個操作完成期間,自身無法繼續(xù)處理其他的事情,則稱該程序在該操作上是阻塞的。常見的阻塞形式有:網(wǎng)絡(luò) I/O 阻塞、磁盤 I/O 阻塞、用戶輸入阻塞等。阻塞是無處不在的,包括 CPU 切換上下文時,所有的進程都無法真正處理事情,它們也會被阻塞。如果是多核 CPU 則正在執(zhí)行上下文切換操作的核不可被利用。
非阻塞
程序在等待某操作過程中,自身不被阻塞,可以繼續(xù)處理其他的事情,則稱該程序在該操作上是非阻塞的。非阻塞并不是在任何程序級別、任何情況下都可以存在的。僅當(dāng)程序封裝的級別可以囊括獨立的子程序單元時,它才可能存在非阻塞狀態(tài)。非阻塞的存在是因為阻塞存在,正因為某個操作阻塞導(dǎo)致的耗時與效率低下,我們才要把它變成非阻塞的。
同步
不同程序單元為了完成某個任務(wù),在執(zhí)行過程中需靠某種通信方式以協(xié)調(diào)一致,我們稱這些程序單元是同步執(zhí)行的。例如購物系統(tǒng)中更新商品庫存,需要用“行鎖”作為通信信號,讓不同的更新請求強制排隊順序執(zhí)行,那更新庫存的操作是同步的。簡言之,同步意味著有序。
異步
為完成某個任務(wù),不同程序單元之間過程中無需通信協(xié)調(diào),也能完成任務(wù)的方式,不相關(guān)的程序單元之間可以是異步的。例如,爬蟲下載網(wǎng)頁。調(diào)度程序調(diào)用下載程序后,即可調(diào)度其他任務(wù),而無需與該下載任務(wù)保持通信以協(xié)調(diào)行為。不同網(wǎng)頁的下載、保存等操作都是無關(guān)的,也無需相互通知協(xié)調(diào)。這些異步操作的完成時刻并不確定。簡言之,異步意味著無序。
多進程
多進程就是利用 CPU 的多核優(yōu)勢,在同一時間并行地執(zhí)行多個任務(wù),可以大大提高執(zhí)行效率。
協(xié)程
協(xié)程,英文叫作 Coroutine,又稱微線程、纖程,協(xié)程是一種用戶態(tài)的輕量級線程。協(xié)程擁有自己的寄存器上下文和棧。協(xié)程調(diào)度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復(fù)先前保存的寄存器上下文和棧。因此協(xié)程能保留上一次調(diào)用時的狀態(tài),即所有局部狀態(tài)的一個特定組合,每次過程重入時,就相當(dāng)于進入上一次調(diào)用的狀態(tài)。協(xié)程本質(zhì)上是個單進程,協(xié)程相對于多進程來說,無需線程上下文切換的開銷,無需原子操作鎖定及同步的開銷,編程模型也非常簡單。我們可以使用協(xié)程來實現(xiàn)異步操作,比如在網(wǎng)絡(luò)爬蟲場景下,我們發(fā)出一個請求之后,需要等待一定的時間才能得到響應(yīng),但其實在這個等待過程中,程序可以干許多其他的事情,等到響應(yīng)得到之后才切換回來繼續(xù)處理,這樣可以充分利用 CPU 和其他資源,這就是協(xié)程的優(yōu)勢。
二、協(xié)程用法
從 Python 3.4 開始,Python 中加入了協(xié)程的概念,但這個版本的協(xié)程還是以生成器對象為基礎(chǔ)的,在 Python 3.5 則增加了 async/await,使得協(xié)程的實現(xiàn)更加方便。
asyncio
Python 中使用協(xié)程最常用的庫莫過于 asyncio
event_loop:事件循環(huán),相當(dāng)于一個無限循環(huán),我們可以把一些函數(shù)注冊到這個事件循環(huán)上,當(dāng)滿足條件發(fā)生的時候,就會調(diào)用對應(yīng)的處理方法。 coroutine:中文翻譯叫協(xié)程,在 Python 中常指代為協(xié)程對象類型,我們可以將協(xié)程對象注冊到時間循環(huán)中,它會被事件循環(huán)調(diào)用。我們可以使用 async 關(guān)鍵字來定義一個方法,這個方法在調(diào)用時不會立即被執(zhí)行,而是返回一個協(xié)程對象。 task:任務(wù),它是對協(xié)程對象的進一步封裝,包含了任務(wù)的各個狀態(tài)。 future:代表將來執(zhí)行或沒有執(zhí)行的任務(wù)的結(jié)果,實際上和 task 沒有本質(zhì)區(qū)別。
async/await 關(guān)鍵字,是從 Python 3.5 才出現(xiàn)的,專門用于定義協(xié)程。其中,async 定義一個協(xié)程,await 用來掛起阻塞方法的執(zhí)行。
定義協(xié)程
定義一個協(xié)程,感受它和普通進程在實現(xiàn)上的不同之處,代碼如下:
import?asyncio
async?def?execute(x):
????print('Number:',?x)
coroutine?=?execute(666)
print('Coroutine:',?coroutine)
print('After?calling?execute')
loop?=?asyncio.get_event_loop()
loop.run_until_complete(coroutine)
print('After?calling?loop')
運行結(jié)果如下:
Coroutine:?0x0000027808F5BE48>
After?calling?execute
Number:?666
After?calling?loop
Process?finished?with?exit?code?0
首先導(dǎo)入 asyncio 這個包,這樣才可以使用 async 和 await,然后使用 async 定義了一個 execute 方法,方法接收一個數(shù)字參數(shù),方法執(zhí)行之后會打印這個數(shù)字。
隨后我們直接調(diào)用了這個方法,然而這個方法并沒有執(zhí)行,而是返回了一個 coroutine 協(xié)程對象。隨后我們使用 get_event_loop 方法創(chuàng)建了一個事件循環(huán) loop,并調(diào)用了 loop 對象的 run_until_complete 方法將協(xié)程注冊到事件循環(huán) loop 中,然后啟動。最后我們才看到了 execute 方法打印了輸出結(jié)果。
可見,async 定義的方法就會變成一個無法直接執(zhí)行的 coroutine 對象,必須將其注冊到事件循環(huán)中才可以執(zhí)行。
前面還提到了 task,它是對 coroutine 對象的進一步封裝,它里面相比 coroutine 對象多了運行狀態(tài),比如 running、finished 等,我們可以用這些狀態(tài)來獲取協(xié)程對象的執(zhí)行情況。在上面的例子中,當(dāng)我們將 coroutine 對象傳遞給 run_until_complete 方法的時候,實際上它進行了一個操作就是將 coroutine 封裝成了 task 對象。task也可以顯式地進行聲明,如下所示:
import?asyncio
async?def?execute(x):
????print('Number:',?x)
????return?x
????
coroutine?=?execute(666)
print('Coroutine:',?coroutine)
print('After?calling?execute')
loop?=?asyncio.get_event_loop()
task?=?loop.create_task(coroutine)
print('Task:',?task)
loop.run_until_complete(task)
print('Task:',?task)
print('After?calling?loop')
運行結(jié)果如下:
Coroutine:?0x000001CB3F90BE48>
After?calling?execute
Task:?3>>
Number:?666
Task:?3>?result=666>
After?calling?loop
Process?finished?with?exit?code?0
這里我們定義了 loop 對象之后,接著調(diào)用了它的 create_task 方法將 coroutine 對象轉(zhuǎn)化為了 task 對象,隨后我們打印輸出一下,發(fā)現(xiàn)它是 pending 狀態(tài)。接著我們將 task 對象添加到事件循環(huán)中得到執(zhí)行,隨后我們再打印輸出一下 task 對象,發(fā)現(xiàn)它的狀態(tài)就變成了 finished,同時還可以看到其 result 變成了 666,也就是我們定義的 execute 方法的返回結(jié)果。
定義 task 對象還有一種常用方式,就是直接通過 asyncio 的 ensure_future 方法,返回結(jié)果也是 task 對象,這樣的話我們就可以不借助于 loop 來定義,即使還沒有聲明 loop 也可以提前定義好 task 對象,寫法如下:
import?asyncio
async?def?execute(x):
????print('Number:',?x)
????return?x
coroutine?=?execute(666)
print('Coroutine:',?coroutine)
print('After?calling?execute')
task?=?asyncio.ensure_future(coroutine)
print('Task:',?task)
loop?=?asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:',?task)
print('After?calling?loop')
運行效果如下:
Coroutine:?0x0000019794EBBE48>
After?calling?execute
Task:?3>>
Number:?666
Task:?3>?result=666>
After?calling?loop
Process?finished?with?exit?code?0
發(fā)現(xiàn)其運行效果都是一樣的
task對象的綁定回調(diào)操作
可以為某個 task 綁定一個回調(diào)方法,舉如下例子:
import?asyncio
import?requests
async?def?call_on():
????status?=?requests.get('https://www.baidu.com')
????return?status
def?call_back(task):
????print('Status:',?task.result())
corountine?=?call_on()
task?=?asyncio.ensure_future(corountine)
task.add_done_callback(call_back)
print('Task:',?task)
loop?=?asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:',?task)
定義了一個call_on 方法,請求了百度,獲取其狀態(tài)碼,但是這個方法里面我們沒有任何 print 語句。隨后我們定義了一個 call_back 方法,這個方法接收一個參數(shù),是 task 對象,然后調(diào)用 print打印了 task 對象的結(jié)果。這樣我們就定義好了一個 coroutine 對象和一個回調(diào)方法,
希望達(dá)到的效果是,當(dāng) coroutine 對象執(zhí)行完畢之后,就去執(zhí)行聲明的 callback 方法。實現(xiàn)這樣的效果只需要調(diào)用 add_done_callback 方法即可,我們將 callback 方法傳遞給了封裝好的 task 對象,這樣當(dāng) task 執(zhí)行完畢之后就可以調(diào)用 callback 方法了,同時 task 對象還會作為參數(shù)傳遞給 callback 方法,調(diào)用 task 對象的 result 方法就可以獲取返回結(jié)果了。
運行結(jié)果如下:
Task:?4>?cb=[call_back()?at?D:/python/pycharm2020/program/test_003.py:8]>
Status:?200]>
Task:?4>?result=200]>>
也可以不用回調(diào)方法,直接在 task 運行完畢之后也能直接調(diào)用 result 方法獲取結(jié)果,如下所示:
import?asyncio
import?requests
async?def?call_on():
????status?=?requests.get('https://www.baidu.com')
????return?status
def?call_back(task):
????print('Status:',?task.result())
corountine?=?call_on()
task?=?asyncio.ensure_future(corountine)
print('Task:',?task)
loop?=?asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:',?task)
print('Task:',?task.result())
運行效果一樣:
Task:?4>>
Task:?4>?result=200]>>
Task:?200]>
三、異步爬蟲實現(xiàn)
要實現(xiàn)異步處理,得先要有掛起的操作,當(dāng)一個任務(wù)需要等待 IO 結(jié)果的時候,可以掛起當(dāng)前任務(wù),轉(zhuǎn)而去執(zhí)行其他任務(wù),這樣才能充分利用好資源,要實現(xiàn)異步,需要了解一下 await 的用法,使用 await 可以將耗時等待的操作掛起,讓出控制權(quán)。當(dāng)協(xié)程執(zhí)行的時候遇到 await,時間循環(huán)就會將本協(xié)程掛起,轉(zhuǎn)而去執(zhí)行別的協(xié)程,直到其他的協(xié)程掛起或執(zhí)行完畢。
await 后面的對象必須是如下格式之一:
A native coroutine object returned from a native coroutine function,一個原生 coroutine 對象。 A generator-based coroutine object returned from a function decorated with types.coroutine,一個由 types.coroutine 修飾的生成器,這個生成器可以返回 coroutine 對象。 An object with an await method returning an iterator,一個包含 await 方法的對象返回的一個迭代器。
aiohttp 的使用
aiohttp 是一個支持異步請求的庫,利用它和 asyncio 配合我們可以非常方便地實現(xiàn)異步請求操作。下面以訪問我博客里面的文章,并返回 reponse.text() 為例,實現(xiàn)異步爬蟲。
from?lxml?import?etree
import?requests
import?logging
import?time
import?aiohttp
import?asyncio
logging.basicConfig(level=logging.INFO,?format='%(asctime)s?-?%(levelname)s:?%(message)s')
url?=?'https://blog.csdn.net/fyfugoyfa'
start_time?=?time.time()
#?先獲取博客里的文章鏈接
def?get_urls():
????headers?=?{"user-agent":?"Mozilla/5.0?(Windows?NT?6.1;?WOW64)?AppleWebKit/537.1?(KHTML,?like?Gecko)?Chrome/22.0.1207.1?Safari/537.1"}
????resp?=?requests.get(url,?headers=headers)
????html?=?etree.HTML(resp.text)
????url_list?=?html.xpath('//div[@class="article-list"]/div/h4/a/@href')
????return?url_list
async?def?request_page(url):
????logging.info('scraping?%s',?url)
????async?with?aiohttp.ClientSession()?as?session:
????????response?=?await?session.get(url)
????????return?await?response.text()
def?main():
????url_list?=?get_urls()
????tasks?=?[asyncio.ensure_future(request_page(url))?for?url?in?url_list]
????loop?=?asyncio.get_event_loop()
????tasks?=?asyncio.gather(*tasks)
????loop.run_until_complete(tasks)
if?__name__?==?'__main__':
????main()
????end_time?=?time.time()
????logging.info('total?time?%s?seconds',?end_time?-?start_time)
實例中將請求庫由 requests 改成了 aiohttp,通過 aiohttp 的 ClientSession 類的 get 方法進行請求,運行效果如下:
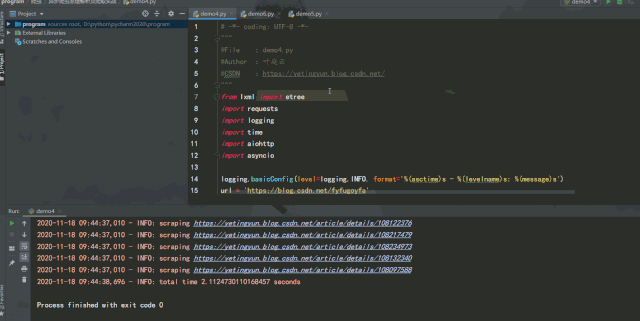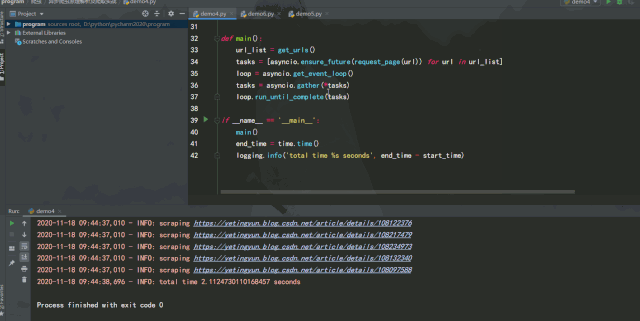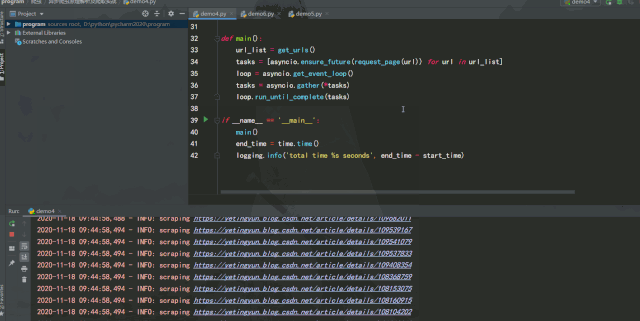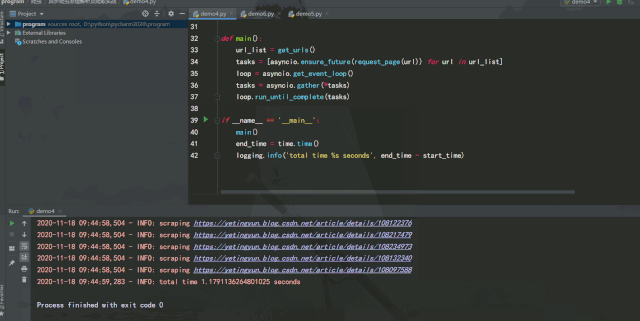
異步操作的便捷之處在于,當(dāng)遇到阻塞式操作時,任務(wù)被掛起,程序接著去執(zhí)行其他的任務(wù),而不是傻傻地等待,這樣可以充分利用 CPU 時間,而不必把時間浪費在等待 IO 上。
上面的例子與單線程版和多線程版的比較如下:
多線程版
import?requests
import?logging
import?time
from?lxml?import?etree
from?concurrent.futures?import?ThreadPoolExecutor
logging.basicConfig(level=logging.INFO,?format='%(asctime)s?-?%(levelname)s:?%(message)s')
url?=?'https://blog.csdn.net/fyfugoyfa'
headers?=?{"user-agent":?"Mozilla/5.0?(Windows?NT?6.1;?WOW64)?AppleWebKit/537.1?(KHTML,?like?Gecko)?Chrome/22.0.1207.1?Safari/537.1"}
start_time?=?time.time()
#?先獲取博客里的文章鏈接
def?get_urls():
????resp?=?requests.get(url,?headers=headers)
????html?=?etree.HTML(resp.text)
????url_list?=?html.xpath('//div[@class="article-list"]/div/h4/a/@href')
????return?url_list
def?request_page(url):
????logging.info('scraping?%s',?url)
????resp?=?requests.get(url,?headers=headers)
????return?resp.text
def?main():
????url_list?=?get_urls()
????with?ThreadPoolExecutor(max_workers=6)?as?executor:
????????executor.map(request_page,?url_list)
if?__name__?==?'__main__':
????main()
????end_time?=?time.time()
????logging.info('total?time?%s?seconds',?end_time?-?start_time)
運行效果如下:
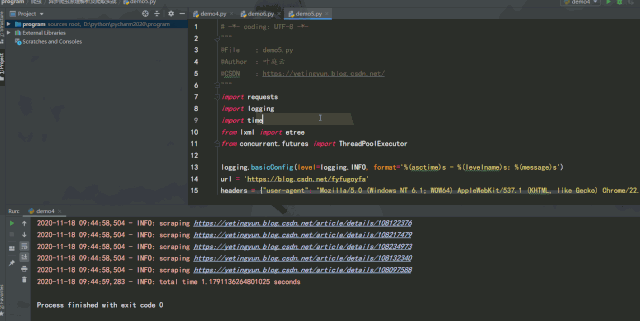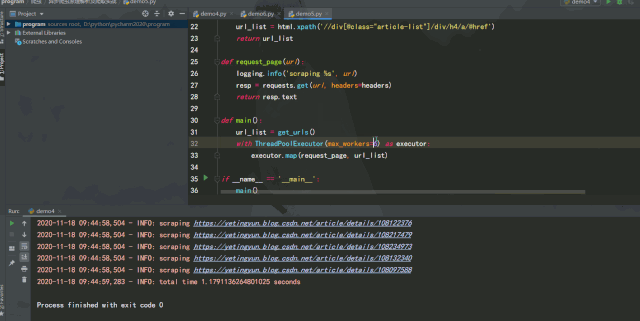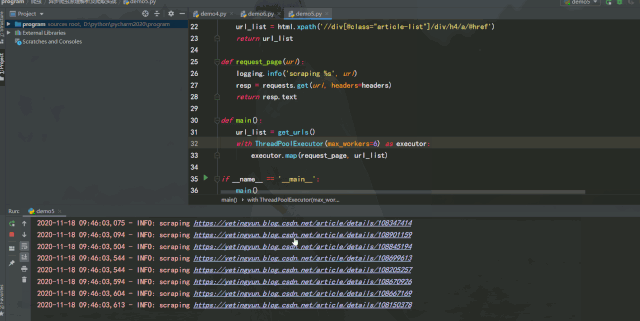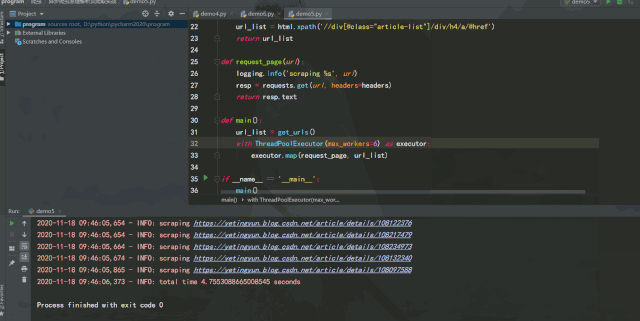
單線程版
import?requests
import?logging
import?time
from?lxml?import?etree
logging.basicConfig(level=logging.INFO,?format='%(asctime)s?-?%(levelname)s:?%(message)s')
url?=?'https://blog.csdn.net/fyfugoyfa'
headers?=?{"user-agent":?"Mozilla/5.0?(Windows?NT?6.1;?WOW64)?AppleWebKit/537.1?(KHTML,?like?Gecko)?Chrome/22.0.1207.1?Safari/537.1"}
start_time?=?time.time()
#?先獲取博客里的文章鏈接
def?get_urls():
????resp?=?requests.get(url,?headers=headers)
????html?=?etree.HTML(resp.text)
????url_list?=?html.xpath('//div[@class="article-list"]/div/h4/a/@href')
????return?url_list
def?request_page(url):
????logging.info('scraping?%s',?url)
????resp?=?requests.get(url,?headers=headers)
????return?resp.text
def?main():
????url_list?=?get_urls()
????for?url?in?url_list:
????????request_page(url)
if?__name__?==?'__main__':
????main()
????end_time?=?time.time()
????logging.info('total?time?%s?seconds',?end_time?-?start_time)
運行效果如下:
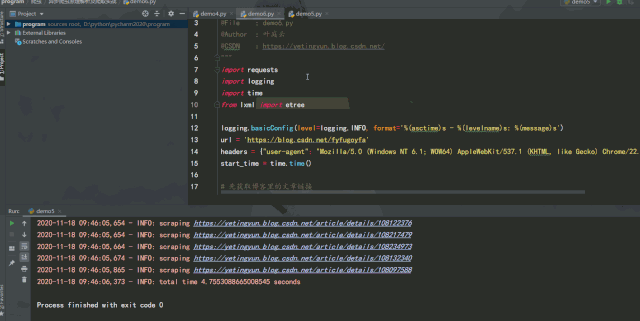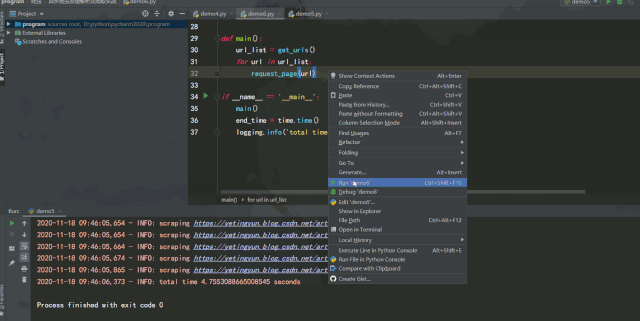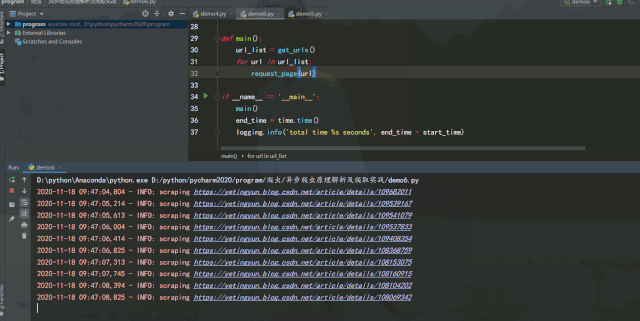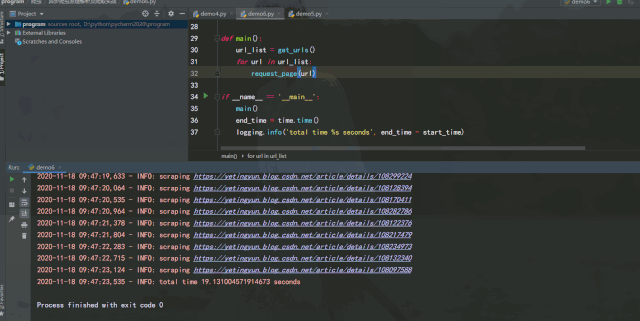
經(jīng)過測試可以發(fā)現(xiàn),如果能將異步請求靈活運用在爬蟲中,在服務(wù)器能承受高并發(fā)的前提下增加并發(fā)數(shù)量,爬取效率提升是非常可觀的。
作者簡介:
葉庭云
個人格言: 熱愛可抵歲月漫長
CSDN博客: https://yetingyun.blog.csdn.net
-------?End -------
掃碼添加早小起,進入Python技術(shù)交流群