
老黃狂拼CPU!英偉達(dá)掏出800億晶體管顯卡,外加世界最快AI超算Eos

??新智元報(bào)道??
編輯:編輯部
【新智元導(dǎo)讀】「拼裝」CPU,4納米顯卡,世界最快AI超算,還有游戲開(kāi)發(fā)者的元宇宙。這次,老黃的百寶箱里都有啥?
 ?雖然沒(méi)有了那個(gè)熟悉的廚房,但這次的陣仗反而更加豪華。?英偉達(dá)用Omniverse把新總部從內(nèi)到外渲染了一遍!??
?雖然沒(méi)有了那個(gè)熟悉的廚房,但這次的陣仗反而更加豪華。?英偉達(dá)用Omniverse把新總部從內(nèi)到外渲染了一遍!??800億個(gè)晶體管的Hopper H100
?隨著拔地而起的平臺(tái),英偉達(dá)推出了為超算設(shè)計(jì)的最新AI顯卡Hopper H100。?相比于「只有」540億個(gè)晶體管的前輩A100,英偉達(dá)在H100中裝入了800億個(gè)晶體管,并采用了定制的臺(tái)積電4納米工藝。?也就是說(shuō),H100將具有更好的功率/性能特性,并在密度方面有一定程度上的改進(jìn)。? ?在算力上,H100的FP16、TF32以及FP64性能都是A100的3倍,分別為2000 TFLOPS、1000 TFLOPS和60 TFLOPS。?此外,H100還增加了對(duì)FP8支持,算力高達(dá)4000 TFLOPS,比A100快6倍。畢竟在 這方面,后者由于缺乏原生FP8支持而不得不依賴(lài)FP16。?內(nèi)存方面,H100也將默認(rèn)支持帶寬為3TB/s的HBM3,比A100的HBM2E提升1.5倍。?
?在算力上,H100的FP16、TF32以及FP64性能都是A100的3倍,分別為2000 TFLOPS、1000 TFLOPS和60 TFLOPS。?此外,H100還增加了對(duì)FP8支持,算力高達(dá)4000 TFLOPS,比A100快6倍。畢竟在 這方面,后者由于缺乏原生FP8支持而不得不依賴(lài)FP16。?內(nèi)存方面,H100也將默認(rèn)支持帶寬為3TB/s的HBM3,比A100的HBM2E提升1.5倍。? ?H100支持的第四代NVLink接口可以提供高達(dá)128GB/s的帶寬,是A100的1.5倍;而在PCIe 5.0下也可以達(dá)到128GB/s的速度,是PCIe 4.0的2倍。?同時(shí),H100的SXM版本將TDP增加到了700W,而A100為400W。而75%的功率提升,通常來(lái)說(shuō)可以預(yù)計(jì)獲得2到3倍的性能。?為了優(yōu)化性能,Nvidia還推出了一個(gè)新的Transformer Engine,將根據(jù)工作負(fù)載在FP8和FP16格式之間自動(dòng)切換。?
?H100支持的第四代NVLink接口可以提供高達(dá)128GB/s的帶寬,是A100的1.5倍;而在PCIe 5.0下也可以達(dá)到128GB/s的速度,是PCIe 4.0的2倍。?同時(shí),H100的SXM版本將TDP增加到了700W,而A100為400W。而75%的功率提升,通常來(lái)說(shuō)可以預(yù)計(jì)獲得2到3倍的性能。?為了優(yōu)化性能,Nvidia還推出了一個(gè)新的Transformer Engine,將根據(jù)工作負(fù)載在FP8和FP16格式之間自動(dòng)切換。?| H100 | A100 (80GB) | |
| CUDA核心 | 16896 | 6912 |
| 張量核心 | 528 | 432 |
| 超頻頻率 | 約1.78GHz | 1.41GHz |
| 內(nèi)存 | 4.8Gbps HBM3 | 3.2Gbps HBM2e |
| 內(nèi)存帶寬 | 3TB/s | 2TB/s |
| FP32矢量 | 60 TFLOPS | 19.5 TFLOPS |
| FP64矢量 | 30 TFLOPS | 9.7 TFLOPS(1/2 FP32) |
| INT8張量 | 2000 TOPS | 624 TOPS |
| FP16張量 | 1000 TFLOPS | 312 TFLOPS |
| TF32張量 | 500 TFLOPS | 156 TFLOPS |
| FP64張量 | 60 TFLOPS | 19.5 TFLOPS |
| 總線 | NVLink 418條 (900GB/s) | NVLink 312條 (600GB/s) |
| GPU | GH100(814平方毫米) | GA100(826平方毫米) |
| 晶體管數(shù)量 | 800億 | 542億 |
| TDP | 700W | 400W |
| 制造工藝 | TSMC 4N | TSMC 7N |
| 架構(gòu) | Hopper | Ampere |
 ?
?DGX服務(wù)器系統(tǒng)
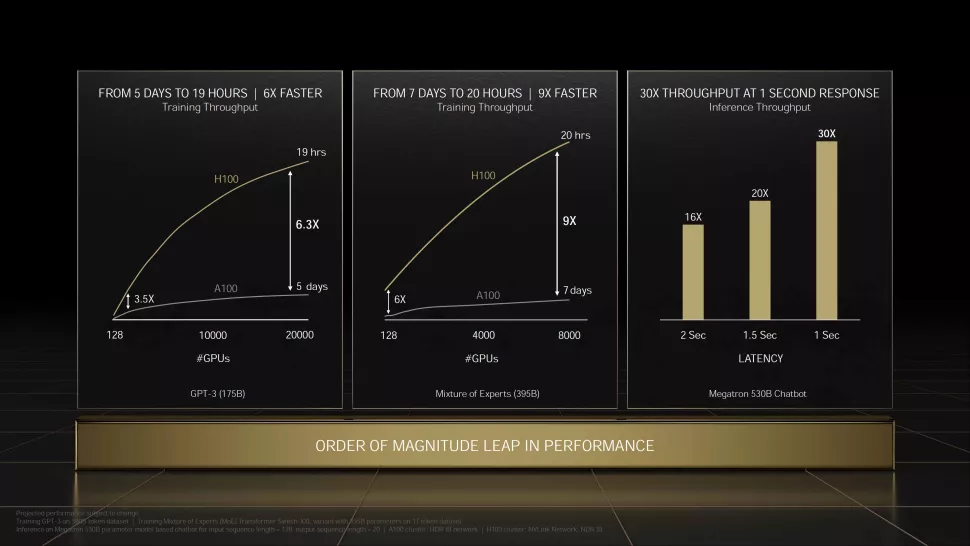
?第四代英偉達(dá)DGX服務(wù)器系統(tǒng),將世界上第一個(gè)采用H100顯卡構(gòu)建的AI服務(wù)器平臺(tái)。?DGX H100服務(wù)器系統(tǒng)可提供滿(mǎn)足大型語(yǔ)言模型、推薦系統(tǒng)、醫(yī)療保健研究和氣候科學(xué)的海量計(jì)算需求所需的規(guī)模。?其中,每個(gè)服務(wù)器系統(tǒng)包含8個(gè)H100顯卡,通過(guò)NVLink鏈接為單個(gè)整體,晶體管總計(jì)6400億個(gè)。?在FP8精度下,DGX H100可以提供32 PFLOPS的性能,比上一代高6倍。? ?此外,每個(gè)DGX H100系統(tǒng)還包括兩個(gè)NVIDIA BlueField-3 DPU,用于卸載、加速和隔離網(wǎng)絡(luò)、存儲(chǔ)和安全服務(wù)。?8個(gè)NVIDIA ConnectX-7 Quantum-2 InfiniBand網(wǎng)絡(luò)適配器提供每秒400 Gb的吞吐量來(lái)連接計(jì)算和存儲(chǔ)模塊——速度是上一代系統(tǒng)的兩倍。?第四代NVLink與NVSwitch相結(jié)合,可在每個(gè)DGX H100系統(tǒng)中的每個(gè)GPU之間提供每秒900 GB的連接,是上一代的1.5倍。?而最新的DGX SuperPOD架構(gòu)則可連接多達(dá)32個(gè)節(jié)點(diǎn)、總共256個(gè)H100顯卡。?DGX SuperPOD可提供1 EFLOPS的FP8性能,同樣也是前代的6倍。?
?此外,每個(gè)DGX H100系統(tǒng)還包括兩個(gè)NVIDIA BlueField-3 DPU,用于卸載、加速和隔離網(wǎng)絡(luò)、存儲(chǔ)和安全服務(wù)。?8個(gè)NVIDIA ConnectX-7 Quantum-2 InfiniBand網(wǎng)絡(luò)適配器提供每秒400 Gb的吞吐量來(lái)連接計(jì)算和存儲(chǔ)模塊——速度是上一代系統(tǒng)的兩倍。?第四代NVLink與NVSwitch相結(jié)合,可在每個(gè)DGX H100系統(tǒng)中的每個(gè)GPU之間提供每秒900 GB的連接,是上一代的1.5倍。?而最新的DGX SuperPOD架構(gòu)則可連接多達(dá)32個(gè)節(jié)點(diǎn)、總共256個(gè)H100顯卡。?DGX SuperPOD可提供1 EFLOPS的FP8性能,同樣也是前代的6倍。? ?
?世界上最快的AI超算
?由576個(gè)DGX H100服務(wù)器系統(tǒng)和4608個(gè)DGX H100顯卡組成的「Eos」超級(jí)計(jì)算機(jī)預(yù)計(jì)將提供18.4 EFLOPS的AI計(jì)算性能,比目前世界上最快的超算——日本的「富岳」快4倍。?對(duì)于傳統(tǒng)的科學(xué)計(jì)算,Eos有望提供275 PFLOPS的性能。? ?
?Transformer Engine
?作為新Hopper架構(gòu)的一部分,將顯著提高AI的性能,大型模型的訓(xùn)練可以在數(shù)天甚至數(shù)小時(shí)內(nèi)完成。?傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)模型在訓(xùn)練過(guò)程中采用的精度是固定的,因此也難以將FP8應(yīng)用在整個(gè)模型之中。?而Transformer Engine則可以在FP16和FP8之間逐層訓(xùn)練,并利用英偉達(dá)提供的啟發(fā)式方法來(lái)選擇所需的最低精度。?此外,Transformer Engine可以用2倍于FP16的速度打包和處理FP8數(shù)據(jù),于是模型的每一層可以用FP8處理的數(shù)據(jù)都可以提升2倍的速度。?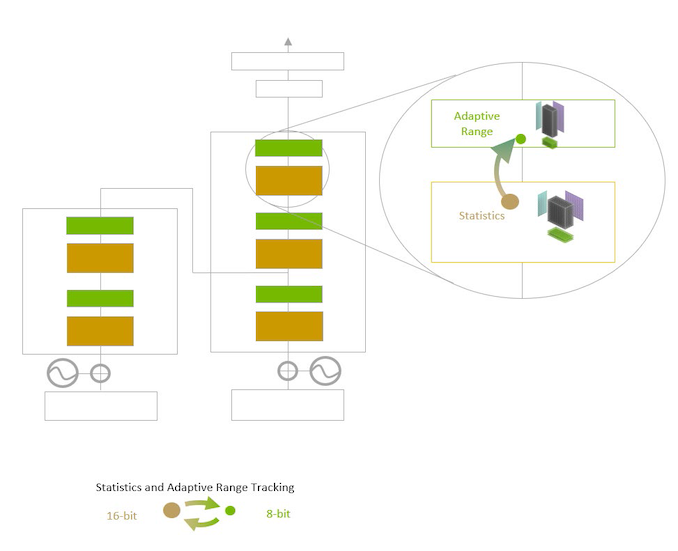 ?
?Grace CPU超級(jí)芯片
?除了顯卡,英偉達(dá)今天還推出了其首款基于Arm Neoverse架構(gòu)的處理器——Grace CPU超級(jí)芯片。?它基于此前發(fā)布的Grace Hopper CPU+GPU設(shè)計(jì),只不過(guò)把顯卡換成了CPU。?據(jù)英偉達(dá)實(shí)驗(yàn)室估計(jì),在使用同類(lèi)編譯器時(shí),Grace CPU超級(jí)芯片性能可以提升1.5倍以上。?在技術(shù)規(guī)格上,可以概括為:?- 2個(gè)72核芯片,高達(dá)144個(gè)Arm v9 CPU核心
- 采用ECC技術(shù)的新一代LPDDR5x內(nèi)存,總帶寬為1TB/s
- SPECrate 2017_int_base得分預(yù)計(jì)超過(guò)740
- 900GB/s 一致性接口,比PCIe 5.0快7倍
- 封裝密度比DIMM解決方案提高了2倍
- 每瓦性能2倍于當(dāng)今領(lǐng)先的CPU
 ?超級(jí)芯片中的兩個(gè)CPU通過(guò)英偉達(dá)最新的NVLink「芯片到芯片」(C2C) 接口進(jìn)行通信。?這種「裸晶到裸晶」和「芯片到芯片」的互連支持低延遲內(nèi)存一致性,允許連接的設(shè)備同時(shí)在同一個(gè)內(nèi)存池上工作。?
?超級(jí)芯片中的兩個(gè)CPU通過(guò)英偉達(dá)最新的NVLink「芯片到芯片」(C2C) 接口進(jìn)行通信。?這種「裸晶到裸晶」和「芯片到芯片」的互連支持低延遲內(nèi)存一致性,允許連接的設(shè)備同時(shí)在同一個(gè)內(nèi)存池上工作。? ?Grace CPU超級(jí)芯片擁有更先進(jìn)的能效和內(nèi)存帶寬,其創(chuàng)新的內(nèi)存子系統(tǒng)由帶有ECC的LPDDR5x內(nèi)存組成。?LPDDR5x可以提供兩倍于傳統(tǒng)DDR5的帶寬,同時(shí)還能使CPU加內(nèi)存的功耗顯著降低至500瓦。?相比之下,AMD的芯片在基準(zhǔn)測(cè)試中的結(jié)果從382到424不等,且每個(gè)芯片的功耗最高可達(dá)280W(還不包括內(nèi)存)。?此外,Grace CPU超級(jí)芯片與NVIDIA ConnectX-7 NIC一起提供了配置到服務(wù)器中的靈活性,可作為獨(dú)立的純CPU系統(tǒng)或作為具有1 個(gè)、2個(gè)、4個(gè)或8個(gè)基于Hopper顯卡的加速服務(wù)器。?
?Grace CPU超級(jí)芯片擁有更先進(jìn)的能效和內(nèi)存帶寬,其創(chuàng)新的內(nèi)存子系統(tǒng)由帶有ECC的LPDDR5x內(nèi)存組成。?LPDDR5x可以提供兩倍于傳統(tǒng)DDR5的帶寬,同時(shí)還能使CPU加內(nèi)存的功耗顯著降低至500瓦。?相比之下,AMD的芯片在基準(zhǔn)測(cè)試中的結(jié)果從382到424不等,且每個(gè)芯片的功耗最高可達(dá)280W(還不包括內(nèi)存)。?此外,Grace CPU超級(jí)芯片與NVIDIA ConnectX-7 NIC一起提供了配置到服務(wù)器中的靈活性,可作為獨(dú)立的純CPU系統(tǒng)或作為具有1 個(gè)、2個(gè)、4個(gè)或8個(gè)基于Hopper顯卡的加速服務(wù)器。?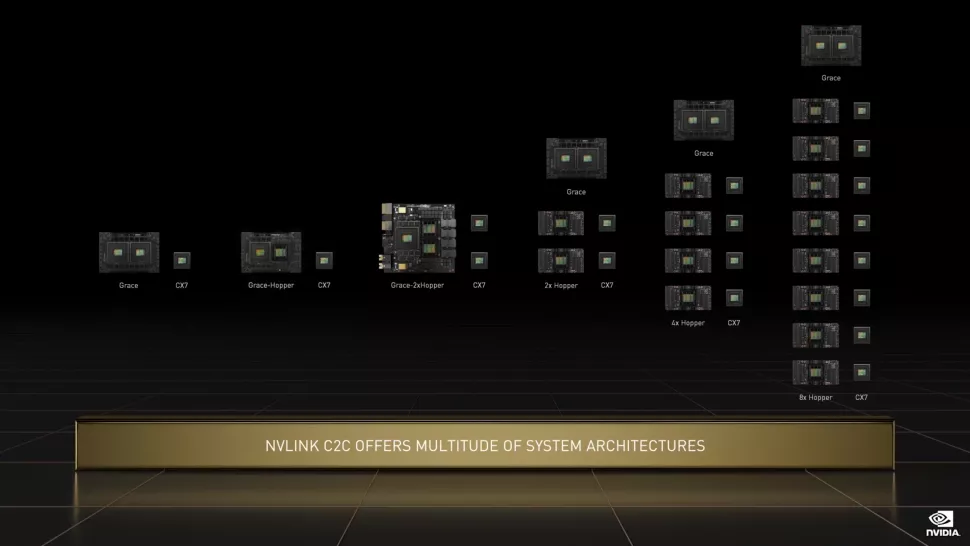 ?
?安培架構(gòu)再添新品
?今天,英偉達(dá)為筆記本電腦和臺(tái)式機(jī)提供了七種基于Ampere架構(gòu)的顯卡——RTX A500、RTX A1000、RTX A2000 8GB、RTX A3000 12GB、RTX A4500和RTX A5500。?新的RTX A5500臺(tái)式機(jī)顯卡可實(shí)現(xiàn)出色的渲染、AI、圖形和計(jì)算性能。其光線追蹤渲染比上一代快2倍,其運(yùn)動(dòng)模糊渲染性能最高可提高9倍。? ?第二代RT核心:吞吐量高達(dá)第一代的2倍,能夠同時(shí)運(yùn)行光線追蹤、著色和去噪任務(wù)。?第三代Tensor Cores:訓(xùn)練吞吐量是前一代的12倍,支持新的TF32和Bfloat16數(shù)據(jù)格式。CUDA核心。比上一代的單精度浮點(diǎn)吞吐量高達(dá)3倍。?高達(dá)48GB的GPU內(nèi)存:RTX A5500具有24GB的GDDR6內(nèi)存,帶有ECC(糾錯(cuò)碼)。使用NVLink連接兩個(gè)GPU,RTX A5500的內(nèi)存可擴(kuò)展至48GB。?虛擬化:RTX A5500支持NVIDIA RTX虛擬工作站(vWS)軟件,用于多個(gè)高性能虛擬工作站實(shí)例,使遠(yuǎn)程用戶(hù)能夠共享資源,推動(dòng)高端設(shè)計(jì)、AI和計(jì)算工作負(fù)載。?PCIe 4.0:帶寬是上一代的2倍,加快了數(shù)據(jù)密集型任務(wù)的數(shù)據(jù)傳輸,如AI、數(shù)據(jù)科學(xué)和創(chuàng)建3D模型。?
?第二代RT核心:吞吐量高達(dá)第一代的2倍,能夠同時(shí)運(yùn)行光線追蹤、著色和去噪任務(wù)。?第三代Tensor Cores:訓(xùn)練吞吐量是前一代的12倍,支持新的TF32和Bfloat16數(shù)據(jù)格式。CUDA核心。比上一代的單精度浮點(diǎn)吞吐量高達(dá)3倍。?高達(dá)48GB的GPU內(nèi)存:RTX A5500具有24GB的GDDR6內(nèi)存,帶有ECC(糾錯(cuò)碼)。使用NVLink連接兩個(gè)GPU,RTX A5500的內(nèi)存可擴(kuò)展至48GB。?虛擬化:RTX A5500支持NVIDIA RTX虛擬工作站(vWS)軟件,用于多個(gè)高性能虛擬工作站實(shí)例,使遠(yuǎn)程用戶(hù)能夠共享資源,推動(dòng)高端設(shè)計(jì)、AI和計(jì)算工作負(fù)載。?PCIe 4.0:帶寬是上一代的2倍,加快了數(shù)據(jù)密集型任務(wù)的數(shù)據(jù)傳輸,如AI、數(shù)據(jù)科學(xué)和創(chuàng)建3D模型。?游戲開(kāi)發(fā)者也有元宇宙了
?已經(jīng)在元宇宙擁有一席之地的Omniverse再次得到了加強(qiáng)。? ?本次大會(huì)上,英偉達(dá)發(fā)布了NVIDIA Omniverse的全新功能,使開(kāi)發(fā)者能夠更輕松地共享資產(chǎn)、對(duì)資產(chǎn)庫(kù)進(jìn)行分類(lèi)、開(kāi)展協(xié)作,并在全新游戲開(kāi)發(fā)流程中部署AI來(lái)為角色制作面部表情的動(dòng)畫(huà)。?借助NVIDIA Omniverse實(shí)時(shí)設(shè)計(jì)協(xié)作和模擬平臺(tái),游戲開(kāi)發(fā)者可以使用支持AI和NVIDIA RTX的工具,輕松構(gòu)建自定義工具,以簡(jiǎn)化、加速和改進(jìn)其開(kāi)發(fā)工作流。其組件包括:?
?本次大會(huì)上,英偉達(dá)發(fā)布了NVIDIA Omniverse的全新功能,使開(kāi)發(fā)者能夠更輕松地共享資產(chǎn)、對(duì)資產(chǎn)庫(kù)進(jìn)行分類(lèi)、開(kāi)展協(xié)作,并在全新游戲開(kāi)發(fā)流程中部署AI來(lái)為角色制作面部表情的動(dòng)畫(huà)。?借助NVIDIA Omniverse實(shí)時(shí)設(shè)計(jì)協(xié)作和模擬平臺(tái),游戲開(kāi)發(fā)者可以使用支持AI和NVIDIA RTX的工具,輕松構(gòu)建自定義工具,以簡(jiǎn)化、加速和改進(jìn)其開(kāi)發(fā)工作流。其組件包括:?- Omniverse Audio2Face,一款由NVIDIA AI驅(qū)動(dòng)的應(yīng)用,使角色藝術(shù)家通過(guò)音頻文件生成高質(zhì)量的面部動(dòng)畫(huà)。Audio2Face支持完整的面部動(dòng)畫(huà),藝術(shù)家們還能控制表演的情感。有了Audio2Face,游戲開(kāi)發(fā)者可以快速、輕松地為其游戲角色添加逼真的表情,促進(jìn)玩家和游戲角色之間更強(qiáng)的情感連接,增強(qiáng)沉浸感。
- Omniverse Nucleus Cloud現(xiàn)已開(kāi)放搶先體驗(yàn)版,可實(shí)現(xiàn)Omniverse場(chǎng)景的一鍵式簡(jiǎn)單共享,無(wú)需在本地或私有云中部署Nucleus。通過(guò)Nucleus Cloud,游戲開(kāi)發(fā)者可輕松地在內(nèi)、外部開(kāi)發(fā)團(tuán)隊(duì)之間實(shí)時(shí)分享和協(xié)作3D資產(chǎn)。
- Omniverse DeepSearch是一項(xiàng)AI服務(wù),現(xiàn)在可供Omniverse企業(yè)用戶(hù)使用,它允許游戲開(kāi)發(fā)者使用自然語(yǔ)言輸入和圖像來(lái)即時(shí)搜索其整個(gè)未標(biāo)記的3D資產(chǎn)、物體對(duì)象和角色目錄。
- Omniverse Connectors實(shí)現(xiàn)第三方設(shè)計(jì)工具和Omniverse之間的「實(shí)時(shí)同步」協(xié)作工作流的插件。全新虛幻引擎5 Omniverse Connector允許游戲藝術(shù)家在游戲引擎和Omniverse之間交換USD和材料定義語(yǔ)言數(shù)據(jù)。
將數(shù)據(jù)中心轉(zhuǎn)變?yōu)椤窤I工廠」
不管是Hopper顯卡架構(gòu)還是AI加速軟件,抑或是強(qiáng)大的數(shù)據(jù)中心系統(tǒng)。?所有的這些都將由Omniverse匯集起來(lái),從而更好地模擬和理解現(xiàn)實(shí)世界,并作為新型機(jī)器人的試驗(yàn)場(chǎng),即所謂「下一波AI」。?由于加速計(jì)算技術(shù)的發(fā)展,AI的進(jìn)展驚人,人工智能已經(jīng)從根本上改變了軟件可以做什么,以及如何開(kāi)發(fā)軟件。?老黃表示,Transformer擺脫了對(duì)人類(lèi)標(biāo)記數(shù)據(jù)的需求,使自監(jiān)督學(xué)習(xí)成為可能,而人工智能一躍以空前的速度發(fā)展。?用于語(yǔ)言理解的谷歌BERT,用于藥物發(fā)現(xiàn)的英偉達(dá)MegaMolBART,以及DeepMind AlphaFold2都是Transformer帶來(lái)的突破。?英偉達(dá)的AI平臺(tái)也得到了重大的更新,包括Triton推理服務(wù)器、用于訓(xùn)練大型語(yǔ)言模型的NeMo Megatron 0.9框架,以及用于音頻和視頻質(zhì)量增強(qiáng)的Maxine框架。?
 ?「我們將在未來(lái)十年再爭(zhēng)取實(shí)現(xiàn)百萬(wàn)倍的算力提升,」老黃在結(jié)束他的演講時(shí)說(shuō),「我迫不及待地想看看下一個(gè)百萬(wàn)倍會(huì)帶來(lái)什么了。」
?「我們將在未來(lái)十年再爭(zhēng)取實(shí)現(xiàn)百萬(wàn)倍的算力提升,」老黃在結(jié)束他的演講時(shí)說(shuō),「我迫不及待地想看看下一個(gè)百萬(wàn)倍會(huì)帶來(lái)什么了。」參考資料:
https://www.nvidia.cn/gtc-global/keynote/

評(píng)論
圖片
表情