
Elasticsearch從入門到放棄:淺談算分
今天來聊一個(gè) Elasticsearch 的另一個(gè)關(guān)鍵概念——相關(guān)性算分。在查詢 API 的結(jié)果中,我們經(jīng)常會(huì)看到 _score 這個(gè)字段,它就是用來表示相關(guān)性算分的字段,而相關(guān)性就是描述一個(gè)文檔和查詢語句的匹配程度。
打分的本質(zhì)其實(shí)就是排序,Elasticsearch 會(huì)把最符合用戶需求的文檔排在最前面。
在 Elasticsearch 5.0 之前,相關(guān)性算分算法采用的是 TF-IDF 算法,而在5.0之后采用的是 BM 25 算法。聽到這也許你會(huì)比較疑惑,想知道這兩個(gè)算法到底是怎么樣的。別急,下面我們來具體了解一下。
TF-IDF
首先來看字面意思,TF 是 Term Frequency 的縮寫,也就是詞頻。IDF 是 Inverse Document Frequency 的縮寫,也就是逆文檔頻率。
詞頻
詞頻比較好理解,就是要搜索的目標(biāo)單詞在文檔中出現(xiàn)的頻率。算式為檢索詞出現(xiàn)的次數(shù)除以文檔的總字?jǐn)?shù)。最簡單的相關(guān)性算法就是將檢索詞進(jìn)行分詞后對(duì)他們的詞頻進(jìn)行相加。例如,我要搜索“我的算法”,其相關(guān)性就可以表示為:
TF(我) + TF(的) + TF(算法)
但這里也有些問題,像“的”這樣的詞,雖然出現(xiàn)的次數(shù)很多,但是對(duì)貢獻(xiàn)的相關(guān)度幾乎沒有用處。所以在考慮相關(guān)度時(shí)不應(yīng)該考慮他們,對(duì)于這類詞,我們統(tǒng)稱為 Stop Word。
逆文檔頻率
聊完了 TF,我們再來看看 IDF,在了解逆文檔頻率之前,首先需要知道什么是文檔頻率,也就是 DF。
DF 其實(shí)是檢索詞在所有文檔中出現(xiàn)的頻率。例如,“我”在較多的文檔中出現(xiàn),“的”在非常多的文檔中都會(huì)出現(xiàn),而“算法”只會(huì)在較少的文檔中出現(xiàn)。這就是文檔頻率,那逆文檔頻率,簡單理解就是:
log(全部文檔數(shù) / 檢索詞出現(xiàn)過的文檔總數(shù))
針對(duì)上面的例子,我們將它更具體的呈現(xiàn)一下。假設(shè)我們文檔總數(shù)為1億,出現(xiàn)“我”字的文檔有5000萬,那么它的 IDF 就是 log(2) = 1 。“的”在1億文檔中都有出現(xiàn),IDF 就是 log(1) = 0,而算法只在20萬個(gè)文檔中出現(xiàn),那么它的 IDF 就是 log(500) ,大約是8.96。
由此可見,IDF 越大的單詞越重要。
好了,現(xiàn)在各位 TF 和 IDF 應(yīng)該都有一定的了解了,那么 TF-IDF 本質(zhì)上就是對(duì) TF 進(jìn)行一個(gè)加權(quán)求和。
TF(我) * IDF(我) + TF(的) * IDF(的) + TF(算法) * IDF(算法)
BM 25
BM25可以看作是對(duì) TF-IDF 的一個(gè)優(yōu)化,其優(yōu)化的效果是,當(dāng) TF 無限增加時(shí), TF-IDF 的結(jié)果會(huì)隨之增加,而 BM 25 的結(jié)果會(huì)趨近于一個(gè)數(shù)值。這就限制了一個(gè) term 對(duì)于檢索詞整體相關(guān)性的影響。
BM25算法的公式如下:
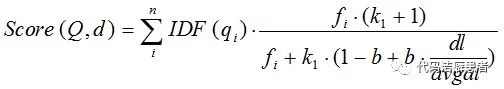
想要詳細(xì)了解BM25算法的同學(xué)可以參考這篇文章BM25 The Next Generation of Lucene Relevance。
Explain API
如果想要了解一個(gè)查詢是如何進(jìn)行打分的,我們可以使用 Elasticsearch 提供的 Explain API,其用法非常簡單,只需要在參數(shù)中增加
"explain":?true
也可以在 path 中增加 _explain,例如:
curl?-X?GET?"localhost:9200/my-index-000001/_explain/0?pretty"?-H?'Content-Type:?application/json'?-d'
{
??"query"?:?{
????"match"?:?{?"message"?:?"elasticsearch"?}
??}
}
'
這時(shí),返回結(jié)果中就會(huì)有一個(gè) explanation 字段,用來描述具體的算分過程。
小結(jié)
關(guān)于 Elasticsearch 的算分,相信各位也有一個(gè)初步的認(rèn)識(shí)了,如果感興趣的話也可以自己進(jìn)行更加深入的研究,也歡迎各位和我一起交流。