
5行Python實現(xiàn)驗證碼識別,穩(wěn)得一批!
作者 | 朱小五
來源 | 快學(xué)Python
在很久之前,分享過一次Python代碼實現(xiàn)驗證碼識別的辦法。
當(dāng)時采用的是pillow+pytesseract,優(yōu)點是免費,較為易用。但其識別精度一般,若想要更高要求的驗證碼識別,初學(xué)者就只能去選擇使用百度API接口了。
但其實百度API接口和pytesseract其實都需要進行前期配置,對于初學(xué)者來說就不太友好了。
而且百度API必須要聯(lián)網(wǎng),對于某些機器不能聯(lián)網(wǎng)的朋友而言,就得pass了
最近群里有位群友分享了一個新庫,試用一下發(fā)現(xiàn)非常實用,特意今天分享給大家。
Github地址:https://github.com/sml2h3/ddddocr
該庫名也是非常有趣 —— ddddocr(諧音帶帶弟弟OCR)
環(huán)境要求:
python >= 3.8
Windows/Linux/Macox..
可以通過以下命令安裝
pip install ddddocr
參數(shù)說明:

在網(wǎng)上隨機尋找了一個驗證碼圖片,使用這個庫來實戰(zhàn)一下。

import ddddocr
ocr = ddddocr.DdddOcr()
with open('1.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print(res)

成功識別出來了驗證碼文字!
而且優(yōu)點也非常明顯:首先代碼非常精簡,對比前文提到的兩種方法,不需要額外設(shè)置環(huán)境變量等等,5行代碼即可輕松識別驗證碼圖片。另一方面,我們使用魔法命令%%time也測試出來嗎,這段代碼識別速度非常快。
下面用更多的驗證碼圖片繼續(xù)測試:
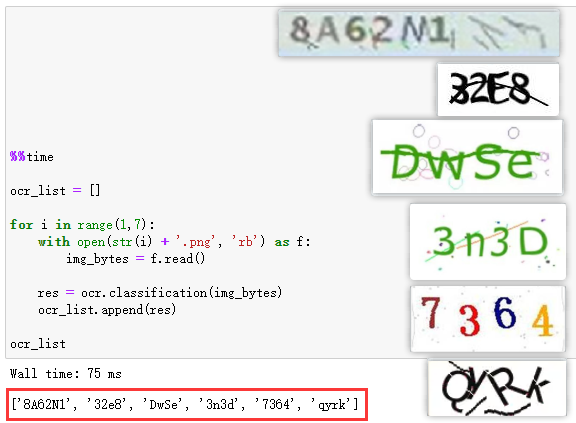
我又找了6個驗證碼圖片來測試,觀察結(jié)果,發(fā)現(xiàn)這類簡單的驗證碼基本可以進行快速識別。但也有部分結(jié)果有問題——字母大小寫沒有進行區(qū)分(比如第6張圖片)。
總而言之,如果你需要進行驗證碼識別,且對精度要求不是過高。
那么,帶帶弟弟OCR(ddddocr)這個庫是一個不錯的選擇~
- EOF -
回復(fù)關(guān)鍵字“簡明python ”,立即獲取入門必備書籍《簡明python教程》電子版
回復(fù)關(guān)鍵字“爬蟲”,立即獲取爬蟲學(xué)習(xí)資料

推薦