
Pandas數(shù)據(jù)分析,你不能不知道的技能
大家好,我是濤哥。
一、pandas merge
1 merge函數(shù)用途
pandas中的merge()函數(shù)類似于SQL中join的用法,可以將不同數(shù)據(jù)集依照某些字段(屬性)進行合并操作,得到一個新的數(shù)據(jù)集。
2 merge函數(shù)的具體參數(shù)
- 用法:
DataFrame1.merge(DataFrame2,?
how=‘inner’,?on=None,?left_on=None,?
right_on=None,?left_index=False,?
right_index=False,?sort=False,?suffixes=(‘_x’,?‘_y’))
- 參數(shù)說明:
- how:默認為inner,可設為inner/outer/left/right;
- on:根據(jù)某個字段進行連接,必須存在于兩個DateFrame中(若未同時存在,則需要分別使用left_on和right_on來設置);
- left_on:左連接,以DataFrame1中用作連接鍵的列;
- right_on:右連接,以DataFrame2中用作連接鍵的列;
- left_index:將DataFrame1行索引用作連接鍵;
- right_index:將DataFrame2行索引用作連接鍵;
- sort:根據(jù)連接鍵對合并后的數(shù)據(jù)進行排列,默認為True;
- suffixes:對兩個數(shù)據(jù)集中出現(xiàn)的重復列,新數(shù)據(jù)集中加上后綴_x,_y進行區(qū)別。
3 merge函數(shù)的應用
?merge一般應用
import?pandas?as?pd
#?定義資料集并打印出來
left?=?pd.DataFrame({'key1':?['K0',?'K0',?'K1',?'K2'],
?????????????????????'key2':?['K0',?'K1',?'K0',?'K1'],
?????????????????????'A':?['A0',?'A1',?'A2',?'A3'],
?????????????????????'B':?['B0',?'B1',?'B2',?'B3']})
right?=?pd.DataFrame({'key1':?['K0',?'K1',?'K1',?'K2'],
??????????????????????'key2':?['K0',?'K0',?'K0',?'K0'],
??????????????????????'C':?['C0',?'C1',?'C2',?'C3'],
??????????????????????'D':?['D0',?'D1',?'D2',?'D3']})
print(left)
print('------------')
print(right)

- 單個字段連接
#?依據(jù)key1?column合并,并打印
res?=?pd.merge(left,?right,?on='key1')
print(res)
- 多字段連接
#?依據(jù)key1和key2?column進行合并,并打印出四種結果['left',?'right','outer',?'inner']
res?=?pd.merge(left,?right,?on=['key1',?'key2'],?how='inner')
print(res)
res?=?pd.merge(left,?right,?on=['key1',?'key2'],?how='outer')
print(res)
res?=?pd.merge(left,?right,?on=['key1',?'key2'],?how='left')?#?以left為主進行合并
print(res)
res?=?pd.merge(left,?right,?on=['key1',?'key2'],?how='right')?#?以right為主進行合并
print(res)
2 merge進階應用
- indicator 設置合并列數(shù)據(jù)來源
#?indicator?設置合并列數(shù)據(jù)來源
df1?=?pd.DataFrame({'coll':?[0,?1],?'col_left':?['a',?'b']})
df2?=?pd.DataFrame({'coll':?[1,?2,?2],?'col_right':?[2,?2,?2]})
print(df1)
print('---------')
print(df2)
#?依據(jù)coll進行合并,并啟用indicator=True,最后打印
res?=?pd.merge(df1,?df2,?on='coll',?how='outer',?indicator=True)
print(res)
'''
left_only?表示數(shù)據(jù)來自左表
right_only?表示數(shù)據(jù)來自右表
both?表示兩個表中都有,也就是匹配上的
'''

#?自定義indicator?column的名稱并打印出
res?=?pd.merge(df1,?df2,?on='coll',?how='outer',?indicator='indicator_column')
print(res)
- 依據(jù)index合并
#?依據(jù)index合并
#?定義數(shù)據(jù)集并打印出
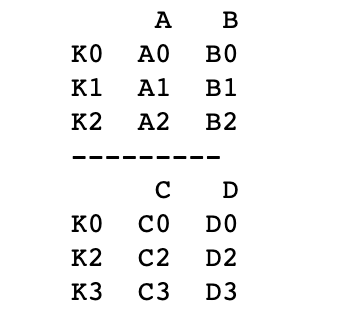
left?=?pd.DataFrame({'A':?['A0',?'A1',?'A2'],
?????????????????????'B':?['B0',?'B1',?'B2']},
???????????????????index?=?['K0',?'K1',?'K2'])
right?=?pd.DataFrame({'C':?['C0',?'C2',?'C3'],
?????????????????????'D':?['D0',?'D2',?'D3']},
???????????????????index?=?['K0',?'K2',?'K3'])
print(left)
print('---------')
print(right)
#?依據(jù)左右數(shù)據(jù)集的index進行合并,how='outer',并打印
res?=?pd.merge(left,?right,?left_index=True,?right_index=True,?how='outer')
print(res)
#?依據(jù)左右數(shù)據(jù)集的index進行合并,how='inner',并打印
res?=?pd.merge(left,?right,?left_index=True,?right_index=True,?how='inner')
print(res)
- 解決overlapping的問題
#?解決overlapping的問題
#?定義資料集
boys?=?pd.DataFrame({'k':?['K0',?'K1',?'K2'],?'age':?[1,?2,?3]})
girls?=?pd.DataFrame({'k':?['K0',?'K1',?'K3'],?'age':?[4,?5,?6]})
print(boys)
print('---------')
print(girls)
#?使用suffixes解決overlapping的問題
#?比如將上面兩個合并時,age重復了,則可通過suffixes設置,以此保證不重復,不同名(默認會在重名列名后加_x?_y)
res?=?pd.merge(boys,?girls,?on='k',?suffixes=['_boy',?'_girl'],?how='inner')
print(res)
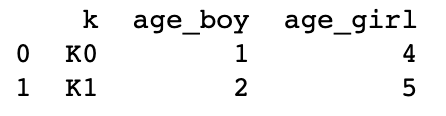
二、pandas apply
1 pandas apply by pluto
apply函數(shù)是pandas中極其好用的一個函數(shù),它可以對dataframe在行或列方向上進行批量化處理,從而大大簡化數(shù)據(jù)處理的過程。
apply函數(shù)的基本形式:
DataFrame.apply(func,?
axis=0,?broadcast=False,?
raw=False,?reduce=None,?args=(),?**kwds)
我們最常用前兩個參數(shù),分別是func運算函數(shù)和axis運算的軸,運算軸默認是axis=0,按列作為序列傳入func運算函數(shù),設置axis=1則表示按行進行計算。
在運算函數(shù)并不復雜的情況下,第一個參數(shù)通常使用lambda函數(shù)。當函數(shù)復雜時可以另外寫一個函數(shù)來調用。下面通過一個實例來說明:
import?pandas?as?pd
df?=?pd.DataFrame({'A':[3,1,4,1,5,9,None,6],
??????????????'B':[1,2,3,None,5,6,7,8]})
d?=?df.apply(lambda?x:?x.fillna(x.mean()))
print(df)
print('----------')
print(d)
處理前的數(shù)據(jù):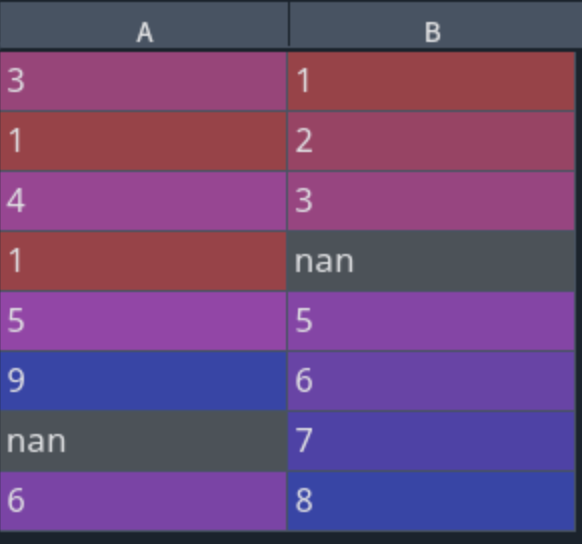 處理后的數(shù)據(jù):
處理后的數(shù)據(jù):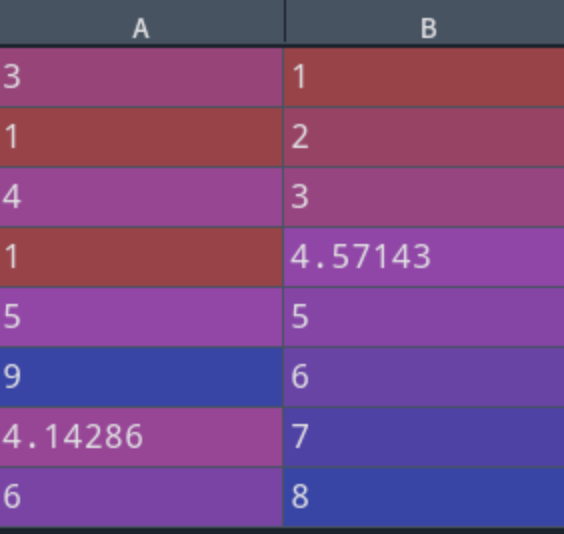
可以看到上面代碼通過apply對nan值進行了均值填充,填充的為nan值所在列的均值。
在默認情況下,axis參數(shù)值為0,表示在行方向上進行特定的函數(shù)運算,即對每一列進行運算。
我們可以設置axis=1來對每一行進行運算。例如我將上例設置為axis=1,結果變?yōu)椋?img src="https://filescdn.proginn.com/1a59baaf4315a50d5e5faac7e715e594/a90f4077b39ab9c4f6d0fffbf43dc7a2.webp" alt="a90f4077b39ab9c4f6d0fffbf43dc7a2.webp" />
可以看出它是使用每行的均值對nan值進行了填充。
apply也可以另寫函數(shù)來調用:
import?pandas?as?pd
df?=?pd.DataFrame({'A':[3,1,4,1,5,9,None,6],
??????????????'B':[1,2,3,None,5,6,7,8]})
def?add(x):
????return?x+1
d?=?df.apply(add,?axis=1)
print(df)
print('----------')
print(d)
這個函數(shù)實現(xiàn)了對每一列上的數(shù)字加一:
注意:行方向,不是指對行進行運算。
比如:一行有[a, b, c, d],行方向運算指的是按先計算a列,然后計算b列,再計算c列,最后計算d列,所以行方向指的只是運算順序的方向。
(不用過度糾結,記住axis=0是對列進行計算,axis=1是對行進行計算即可)
2 pandas apply
最深感觸是其在處理EXCEL數(shù)據(jù)方面可為鬼斧神工,無論增、刪、查、分都高效快捷,本以為Pandas做到這種程度已經相當棒了,但是當學到apply函數(shù)時,才發(fā)覺它超出了自己的想象力。
Apply簡單案例如下:
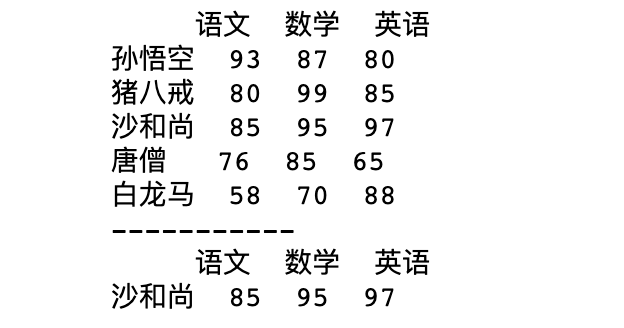
唐僧師徒加上白龍馬一行五人去參加成人考試,考試科目包含語文、數(shù)學、英語共三門,現(xiàn)在想要知道三門科目成績均不小于85分的人有哪些?
import?pandas?as?pd
df?=?pd.DataFrame({'語文':[93,80,85,76,58],
???????????????????'數(shù)學':[87,99,95,85,70],
???????????????????'英語':[80,85,97,65,88]},?
??????????????????index=['孫悟空','豬八戒','沙和尚','唐僧','白龍馬']
?????????????????)
print(df)
print('-----------')
df1?=?df.loc[df['語文'].apply(lambda?x:85<=x<100)]?\
????.loc[df['英語'].apply(lambda?x:85<=x<100)]?\
????.loc[df['數(shù)學'].apply(lambda?x:85<=x<100)]
print(df1)
三、pandas pivot_table?
在pandas中 除了pivot_table ?還有pivot函數(shù)也一樣可以實現(xiàn)數(shù)據(jù)透視功能,前者可以看成后者的增強版。
pivot_table函數(shù)的基本形式:
DataFrame.pivot_table(self,?values=None,?index=None,?columns=None,?aggfunc='mean',?fill_value=None,?margins=False,?dropna=True,?margins_name='All',?observed=False)
pivot_tabel對數(shù)據(jù)格式要求不高,而且支持aggfunc/fillvalue等參數(shù),所以應用更加廣泛。
pivot_table函數(shù)的參數(shù)有values(單元格值)、index(索引)、columns(列名),這些參數(shù)組成一個數(shù)據(jù)透視表的基本結構。
復雜一點 要用到aggfunc方法,默認是求均值(針對于數(shù)值列),當然也可以求其他統(tǒng)計量或者得到數(shù)據(jù)類型的轉換,而且可以多個統(tǒng)計方法同時使用。
總而言之,pivot_table可以轉換各個維度去觀察數(shù)據(jù),達到“透視”的目的。
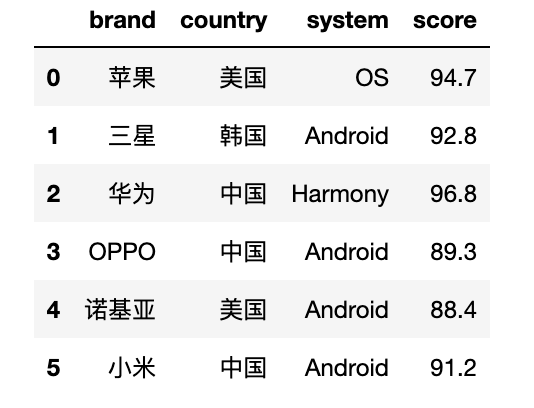
案例說明:
import?numpy?as?np
import?pandas?as?pd
df?=?pd.DataFrame({'brand':?['蘋果',?'三星',?'華為',?'OPPO',?'諾基亞',?'小米'],
????????????????????'country':?['美國','韓國','中國','中國','美國','中國'],
???????????????????'system':?['OS',?'Android',?'Harmony',?'Android',?'Android',?'Android'],
???????????????????'score':?[94.7,??92.8,?96.8,?89.3,?88.4,?91.2]})
df
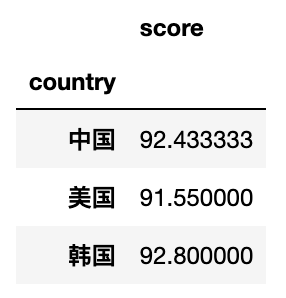
#?按country進行分組,默認計算數(shù)值列的均值
df.pivot_table(index='country')
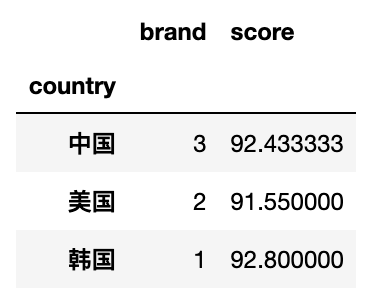
#?按country進行分組,除了計算score均值,另外計算每個國家出現(xiàn)的品牌個數(shù)(不重復)
df.pivot_table(index='country',aggfunc={'score':np.mean,'brand':lambda?x?:?len(x.unique())})
#?按country進行分組,system作為列名,score作為表中的值(重復的取均值),取對應的數(shù)據(jù)生成新的表
df.pivot_table(index='country',columns='system',values='score')
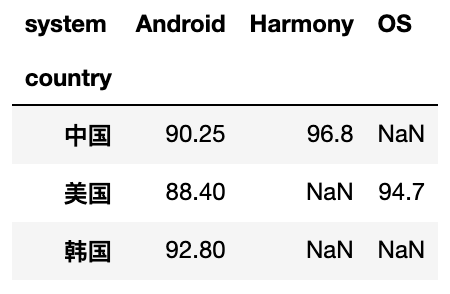
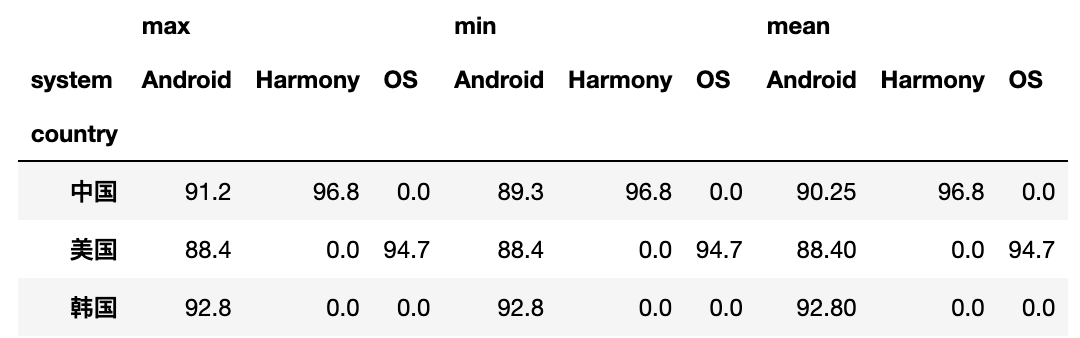
#?統(tǒng)計各個國家手機的最高分?最低分??平均分,空值填充為零
df.pivot_table(index='country',columns='system',values='score',aggfunc=[max,min,np.mean],fill_value=0)
 點贊+留言+轉發(fā),就是對我最大的支持啦~
點贊+留言+轉發(fā),就是對我最大的支持啦~好了,今天的學習就到這里,如果大家希望深度學習的話,可以加入我的社群,與900多位同學一起學習;我是濤哥,我決定干一件大事:做最專業(yè)的Python社群!
往期文章Python 文本數(shù)據(jù)預處理實踐利用Python定制可愛的舉牌小人別再問我如何雙擊打開.ipynb文件了!揭露:我是如何保持每天7小時高效工作的?Python最會變魔術的魔術方法,我覺得是它!