
企業(yè)級日志平臺新秀Loki,比ELK輕量多了~
最近,在對公司容器云的日志方案進行設(shè)計時,發(fā)現(xiàn)主流的 ELK 或者 EFK 比較重,再加上現(xiàn)階段對于 ES 復(fù)雜的搜索功能很多都用不上,最終選擇了 Grafana 開源的 Loki 日志系統(tǒng),下面介紹下 Loki 的背景。
背景和動機
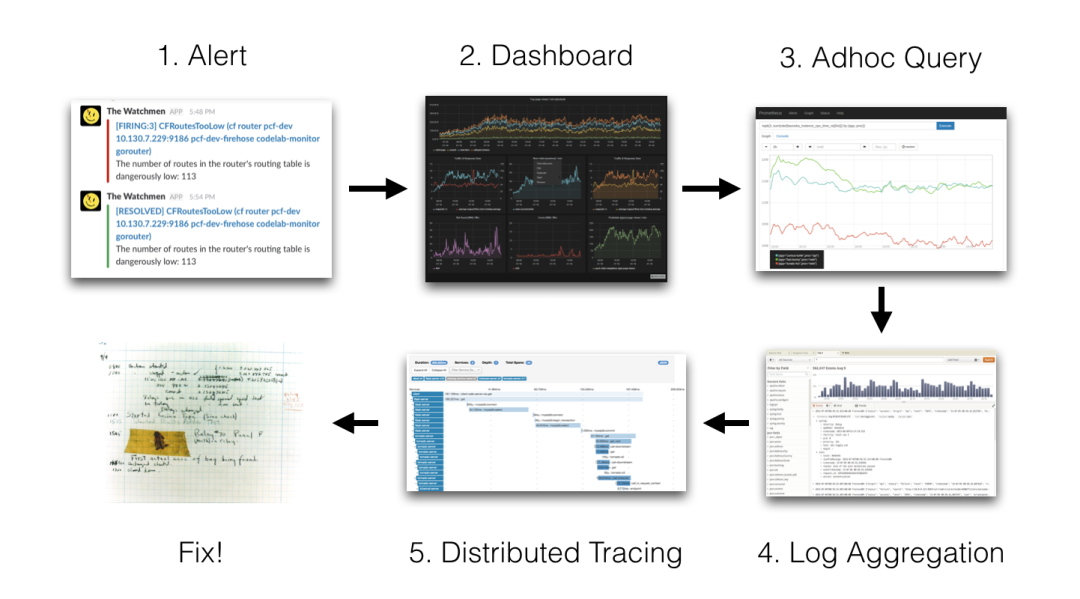
我們的監(jiān)控使用的是基于 Prometheus 體系進行改造的,Prometheus 中比較重要的是 Metric 和 Alert。
Metric 是來說明當(dāng)前或者歷史達到了某個值,Alert 設(shè)置 Metric 達到某個特定的基數(shù)觸發(fā)了告警,但是這些信息明顯是不夠的。
我們都知道,Kubernetes 的基本單位是 Pod,Pod 把日志輸出到 stdout 和 stderr,平時有什么問題我們通常在界面或者通過命令查看相關(guān)的日志。
舉個例子:當(dāng)我們的某個 Pod 的內(nèi)存變得很大,觸發(fā)了我們的 Alert,這個時候管理員,去頁面查詢確認(rèn)是哪個 Pod 有問題,然后要確認(rèn) Pod 內(nèi)存變大的原因。
如果,這個時候應(yīng)用突然掛了,這個時候我們就無法查到相關(guān)的日志了,所以需要引入日志系統(tǒng),統(tǒng)一收集日志。
而使用 ELK 的話,就需要在 Kibana 和 Grafana 之間切換,影響用戶體驗。
所以 ,Loki 的第一目的就是最小化度量和日志的切換成本,有助于減少異常事件的響應(yīng)時間和提高用戶的體驗。
ELK 存在的問題
現(xiàn)有的很多日志采集的方案都是采用全文檢索對日志進行索引(如 ELK 方案),優(yōu)點是功能豐富,允許復(fù)雜的操作。但是,這些方案往往規(guī)模復(fù)雜,資源占用高,操作苦難。
因此,Loki 的第二個目的是,在查詢語言的易操作性和復(fù)雜性之間可以達到一個權(quán)衡。
成本
全文檢索的方案也帶來成本問題,簡單的說就是全文搜索(如 ES)的倒排索引的切分和共享的成本較高。
后來出現(xiàn)了其他不同的設(shè)計方案如:OKlog(https://github.com/oklog/oklog),采用最終一致的、基于網(wǎng)格的分布策略。
這兩個設(shè)計決策提供了大量的成本降低和非常簡單的操作,但是查詢不夠方便。因此,Loki 的第三個目的是,提高一個更具成本效益的解決方案。
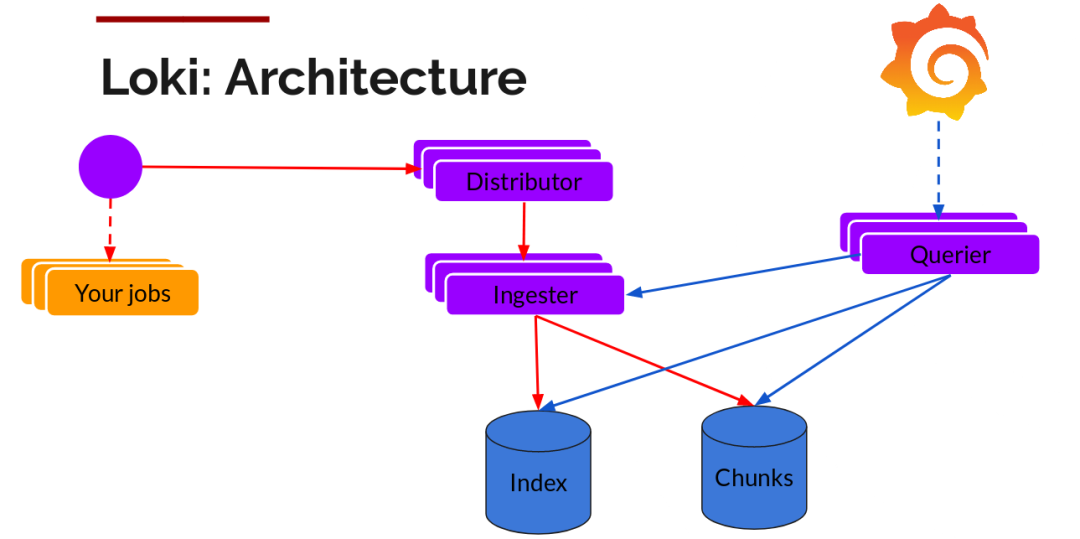
整體架構(gòu)
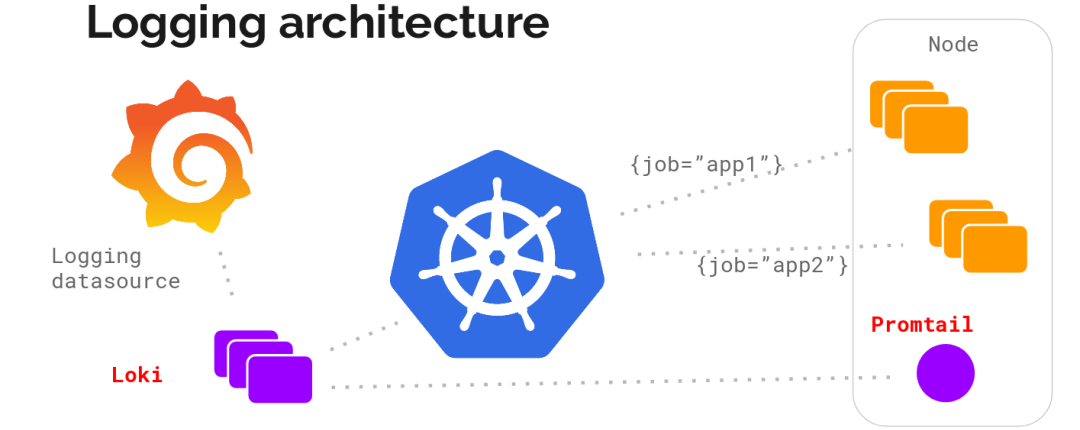
不難看出,Loki 的架構(gòu)非常簡單,使用了和 Prometheus 一樣的標(biāo)簽來作為索引。
也就是說,你通過這些標(biāo)簽既可以查詢?nèi)罩镜膬?nèi)容也可以查詢到監(jiān)控的數(shù)據(jù),不但減少了兩種查詢之間的切換成本,也極大地降低了日志索引的存儲。
Loki 將使用與 Prometheus 相同的服務(wù)發(fā)現(xiàn)和標(biāo)簽重新標(biāo)記庫,編寫了 Pormtail,在 Kubernetes 中 Promtail 以 DaemonSet 方式運行在每個節(jié)點中,通過 Kubernetes API 等到日志的正確元數(shù)據(jù),并將它們發(fā)送到 Loki。
讀寫
日志數(shù)據(jù)的寫主要依托的是 Distributor 和 Ingester 兩個組件,整體的流程如下:
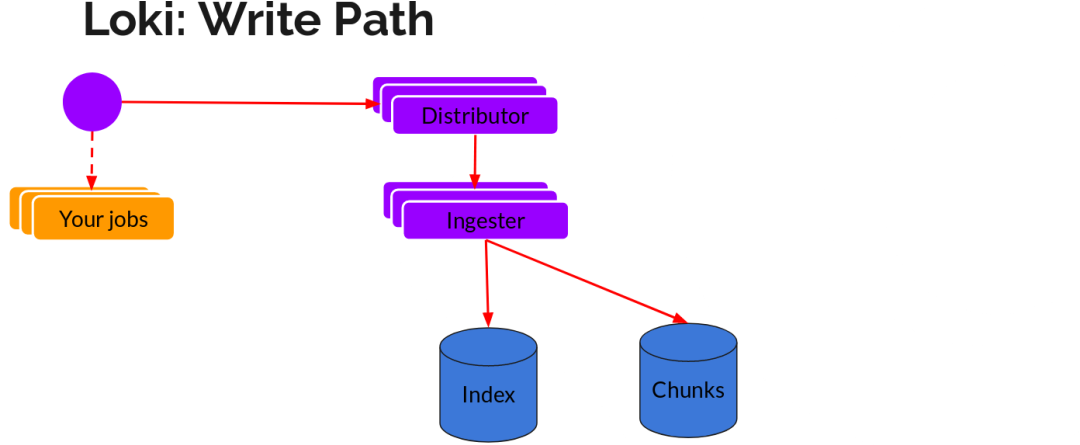
Distributor
一旦 Promtail 收集日志并將其發(fā)送給 Loki,Distributor 就是第一個接收日志的組件。
由于日志的寫入量可能很大,所以不能在它們傳入時將它們寫入數(shù)據(jù)庫。這會毀掉數(shù)據(jù)庫。我們需要批處理和壓縮數(shù)據(jù)。
Loki 通過構(gòu)建壓縮數(shù)據(jù)塊來實現(xiàn)這一點,方法是在日志進入時對其進行 Gzip 操作,組件 Ingester 是一個有狀態(tài)的組件,負責(zé)構(gòu)建和刷新 Chunck,當(dāng) Chunk 達到一定的數(shù)量或者時間后,刷新到存儲中去。

此外,為了冗余和彈性,我們將其復(fù)制 n(默認(rèn)情況下為 3)次。
Ingester
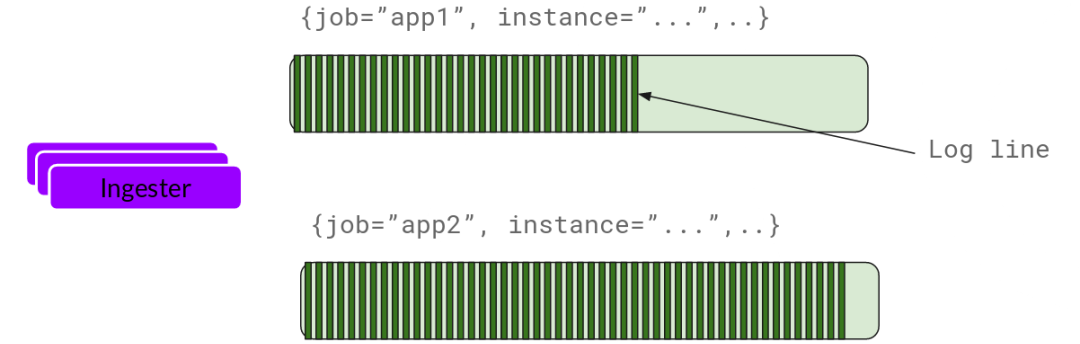
基本上就是將日志進行壓縮并附加到 Chunk 上面。一旦 Chunk“填滿”(數(shù)據(jù)達到一定數(shù)量或者過了一定期限),Ingester 將其刷新到數(shù)據(jù)庫。
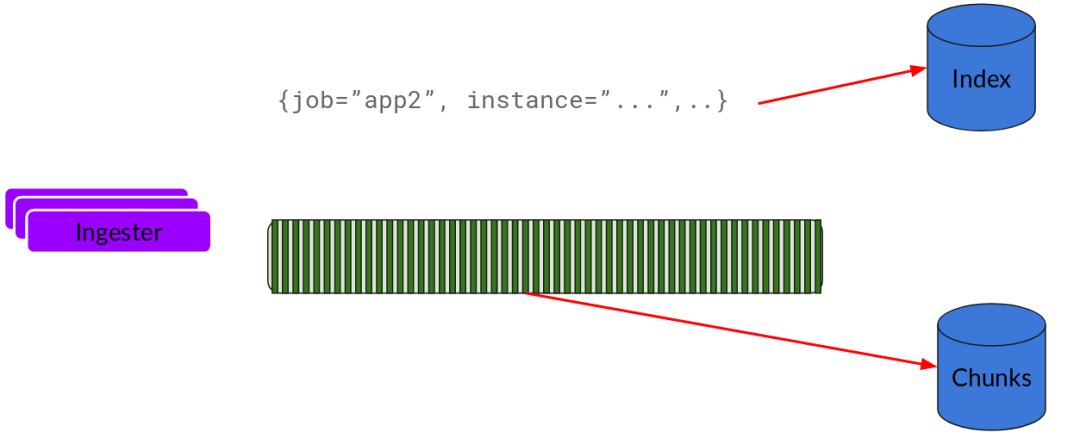
刷新一個 Chunk 之后,Ingester 然后創(chuàng)建一個新的空 Chunk 并將新條目添加到該 Chunk 中。
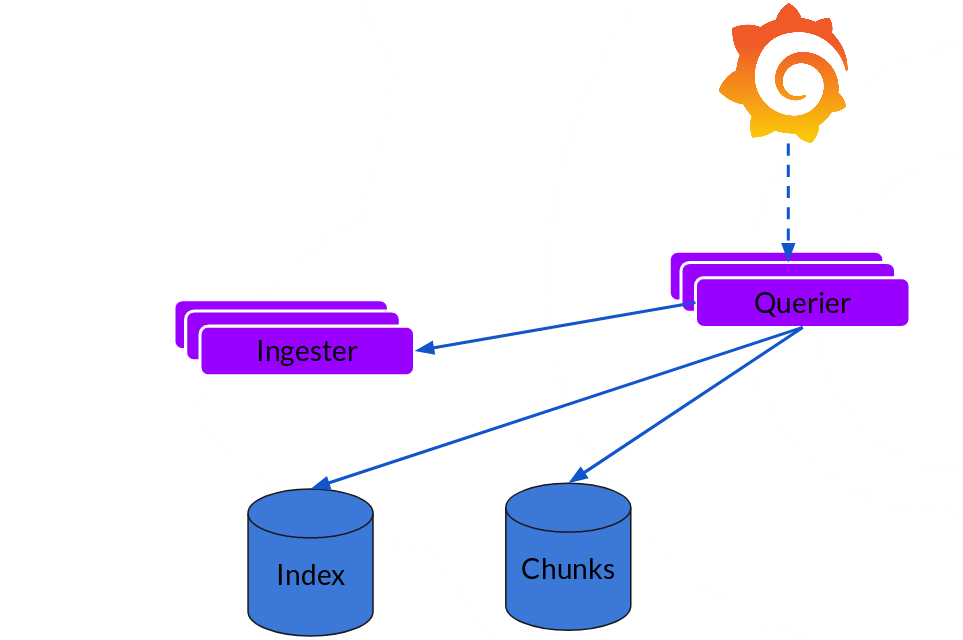
Querier
讀取就非常簡單了,由 Querier 負責(zé)給定一個時間范圍和標(biāo)簽選擇器,Querier 查看索引以確定哪些塊匹配,并通過 greps 將結(jié)果顯示出來。它還從 Ingester 獲取尚未刷新的最新數(shù)據(jù)。
可擴展性
Loki 的索引存儲可以是 cassandra/bigtable/dynamodb,而 Chuncks 可以是各種對象存儲,Querier 和 Distributor 都是無狀態(tài)的組件。
對于 Ingester 他雖然是有狀態(tài)的但是,當(dāng)新的節(jié)點加入或者減少,整節(jié)點間的 Chunk 會重新分配,已適應(yīng)新的散列環(huán)。
而 Loki 底層存儲的實現(xiàn) Cortex 已經(jīng)在實際的生產(chǎn)中投入使用多年了。有了這句話,我可以放心的在環(huán)境中實驗一把了。
原文鏈接:http://blog.csdn.net/Linkthaha/article/details/100575651
關(guān)注「開源Linux」加星標(biāo),提升IT技能
