
數(shù)據(jù)庫優(yōu)化技巧 - SQL語句優(yōu)化
點擊上方?藍色文字?關(guān)注我們
? 溫馨提示:本文大概 3000 字,閱讀需要 5 分鐘。
拿到一段需要優(yōu)化的慢查詢sql,很多人都感覺無從下手。
其實SQL優(yōu)化是有技巧與套路的,閱讀完本文你將學(xué)會這些優(yōu)化套路,讓你成為別人眼中的數(shù)據(jù)庫高手!
判斷問題SQL
判斷SQL是否有問題時可以通過兩個表象進行判斷:
系統(tǒng)級別表象 CPU消耗嚴(yán)重 IO等待嚴(yán)重 頁面響應(yīng)時間過長 應(yīng)用的日志出現(xiàn)超時等錯誤
可以使用 sar命令,top命令查看當(dāng)前系統(tǒng)狀態(tài)。
也可以通過 Prometheus、Grafana等監(jiān)控工具觀察服務(wù)器狀態(tài)。(感興趣的可以翻看我之前的文章)
SQL語句表象 冗長 執(zhí)行時間過長 從全表掃描獲取數(shù)據(jù) 執(zhí)行計劃中的rows、cost很大
冗長的SQL都好理解,一段SQL太長閱讀性肯定會差,而且出現(xiàn)問題的頻率肯定會更高。更進一步判斷SQL問題就得從執(zhí)行計劃入手,如下所示:
執(zhí)行計劃告訴我們本次查詢走了全表掃描 Type=ALL,rows很大(9950400)基本可以判斷這是一段"有味道"的SQL。
獲取問題SQL
不同數(shù)據(jù)庫有不同的獲取方法,以下為目前主流數(shù)據(jù)庫的慢查詢SQL獲取工具
MySQL 慢查詢?nèi)罩?/span> 測試工具loadrunner Percona公司的ptquery等工具 Oracle AWR報告 測試工具loadrunner等 相關(guān)內(nèi)部視圖如v、 GRID CONTROL監(jiān)控工具 達夢數(shù)據(jù)庫 AWR報告 測試工具loadrunner等 達夢性能監(jiān)控工具(dem) 相關(guān)內(nèi)部視圖如v、
SQL編寫技巧
SQL編寫有以下幾個通用的技巧:
? 合理使用索引
索引少了查詢慢;
索引多了占用空間大,執(zhí)行增刪改語句的時候需要動態(tài)維護索引,影響性能 選擇率高(重復(fù)值少)且被where頻繁引用需要建立B樹索引;
一般join列需要建立索引;
復(fù)雜文檔類型查詢采用全文索引效率更好;
索引的建立要在查詢和DML性能之間取得平衡;
復(fù)合索引創(chuàng)建時要注意基于非前導(dǎo)列查詢的情況
? 使用UNION ALL替代UNION
UNION ALL的執(zhí)行效率比UNION高,UNION執(zhí)行時需要排重;
UNION需要對數(shù)據(jù)進行排序
? 避免select * 寫法
執(zhí)行SQL時優(yōu)化器需要將 * 轉(zhuǎn)成具體的列;
每次查詢都要回表,不能走覆蓋索引。
? JOIN字段建議建立索引
一般JOIN字段都提前加上索引
? 避免復(fù)雜SQL語句
提升可閱讀性;避免慢查詢的概率;
可以轉(zhuǎn)換成多個短查詢,用業(yè)務(wù)端處理
? 避免where 1=1寫法
? 避免order by rand()類似寫法
RAND()導(dǎo)致數(shù)據(jù)列被多次掃描
SQL優(yōu)化
執(zhí)行計劃
完成SQL優(yōu)化一定要先讀執(zhí)行計劃,執(zhí)行計劃會告訴你哪些地方效率低,哪里可以需要優(yōu)化。我們以MYSQL為例,看看執(zhí)行計劃是什么。(每個數(shù)據(jù)庫的執(zhí)行計劃都不一樣,需要自行了解)explain sql
| 字段 | 解釋 |
|---|---|
| id | 每個被獨立執(zhí)行的操作標(biāo)識,標(biāo)識對象被操作的順序,id值越大,先被執(zhí)行,如果相同,執(zhí)行順序從上到下 |
| select_type | 查詢中每個select 字句的類型 |
| table | 被操作的對象名稱,通常是表名,但有其他格式 |
| partitions | 匹配的分區(qū)信息(對于非分區(qū)表值為NULL) |
| type | 連接操作的類型 |
| possible_keys | 可能用到的索引 |
| key | 優(yōu)化器實際使用的索引(最重要的列) 從最好到最差的連接類型為 const、eq_reg、ref、range、index和 ALL。當(dāng)出現(xiàn) ALL時表示當(dāng)前SQL出現(xiàn)了“壞味道” |
| key_len | 被優(yōu)化器選定的索引鍵長度,單位是字節(jié) |
| ref | 表示本行被操作對象的參照對象,無參照對象為NULL |
| rows | 查詢執(zhí)行所掃描的元組個數(shù)(對于innodb,此值為估計值) |
| filtered | 條件表上數(shù)據(jù)被過濾的元組個數(shù)百分比 |
| extra | 執(zhí)行計劃的重要補充信息,當(dāng)此列出現(xiàn) Using filesort , Using temporary 字樣時就要小心了,很可能SQL語句需要優(yōu)化 |
接下來我們用一段實際優(yōu)化案例來說明SQL優(yōu)化的過程及優(yōu)化技巧。
優(yōu)化案例
表結(jié)構(gòu)
CREATE TABLE `a`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `b`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `c`
(
`id` int(11) NOT NULLAUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
);查詢要求
三張表關(guān)聯(lián),查詢當(dāng)前用戶在當(dāng)前時間前后10個小時的訂單情況,并根據(jù)訂單創(chuàng)建時間升序排列,具體SQL如下select a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,
b,
c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create
BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;查看數(shù)據(jù)量
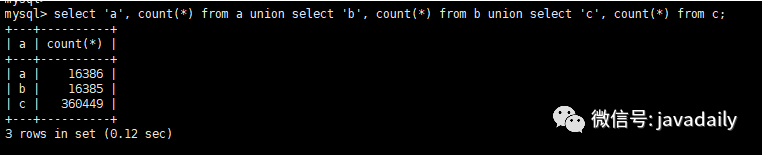
原執(zhí)行時間
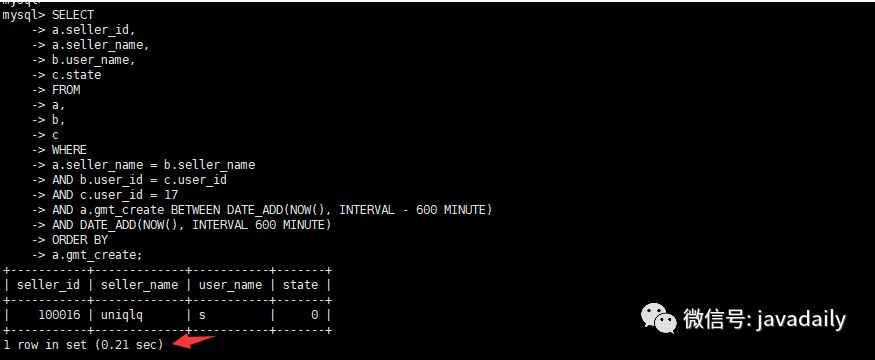
原執(zhí)行計劃
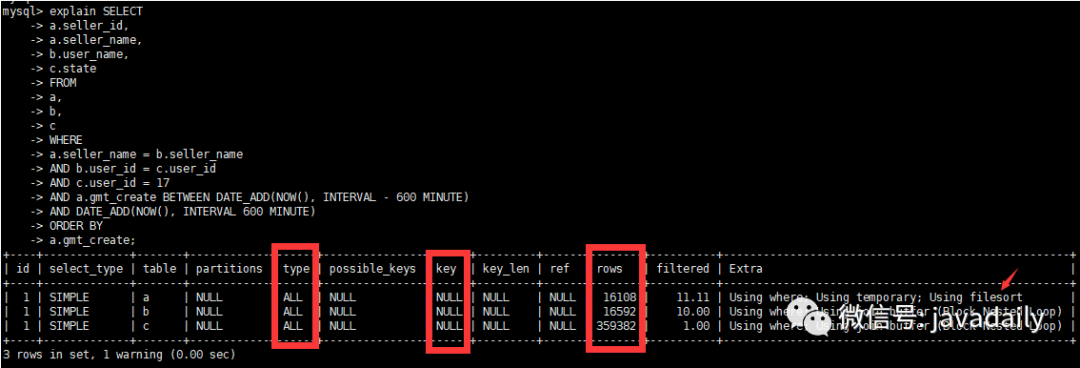
初步優(yōu)化思路
SQL中 where條件字段類型要跟表結(jié)構(gòu)一致,表中 user_id為varchar(50)類型,實際SQL用的int類型,存在隱式轉(zhuǎn)換,也未添加索引。將b和c表user_id字段改成int類型。因存在b表和c表關(guān)聯(lián),將b和c表 user_id創(chuàng)建索引因存在a表和b表關(guān)聯(lián),將a和b表 seller_name字段創(chuàng)建索引利用復(fù)合索引消除臨時表和排序 初步優(yōu)化SQL
alter table b modify `user_id` int(10) DEFAULT NULL;
alter table c modify `user_id` int(10) DEFAULT NULL;
alter table c add index `idx_user_id`(`user_id`);
alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`);
alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);查看優(yōu)化后執(zhí)行時間
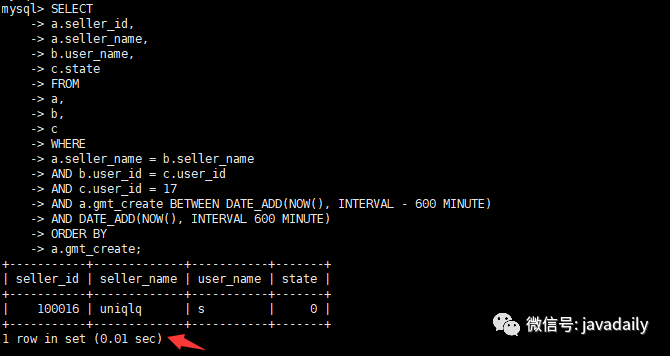
查看優(yōu)化后執(zhí)行計劃
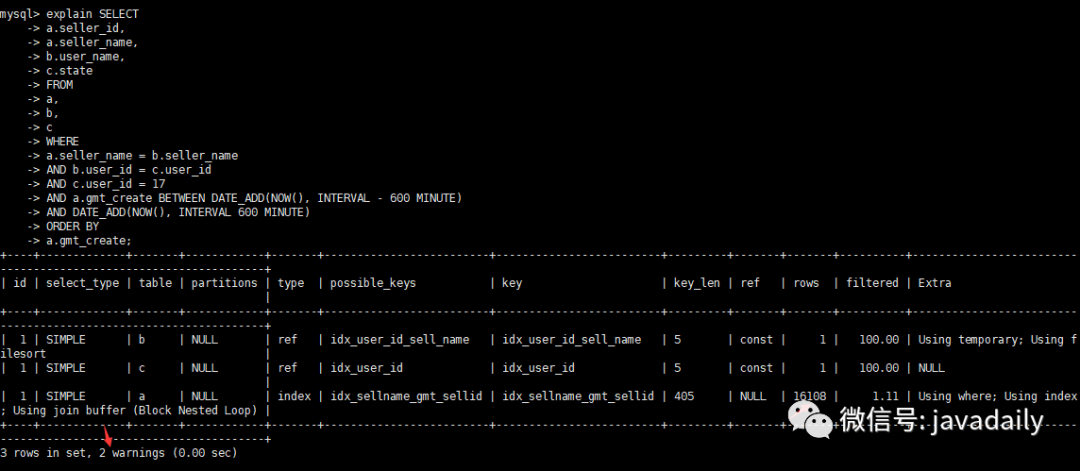
查看warnings信息

繼續(xù)優(yōu)化
alter table a modify "gmt_create" datetime DEFAULT NULL;查看執(zhí)行時間
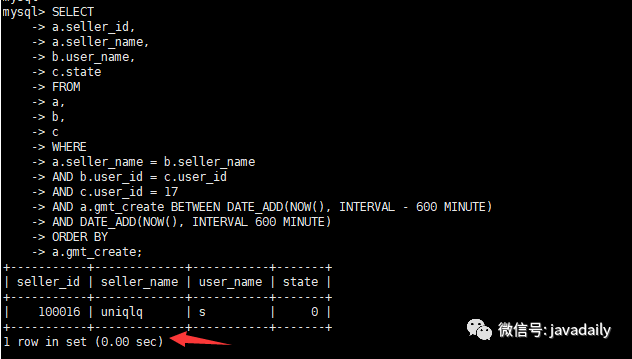
查看執(zhí)行計劃
 通過觀察執(zhí)行計劃,到了這一步已經(jīng)不再需要優(yōu)化!
通過觀察執(zhí)行計劃,到了這一步已經(jīng)不再需要優(yōu)化!優(yōu)化總結(jié)
總結(jié)一下完成一段SQL優(yōu)化的思路與過程:
1、查看執(zhí)行計劃 explain
2、如果有告警信息,查看告警信息 show warnings;
3、查看SQL涉及的表結(jié)構(gòu)和索引信息
4、根據(jù)執(zhí)行計劃,思考可能的優(yōu)化點
5、按照可能的優(yōu)化點執(zhí)行表結(jié)構(gòu)變更、增加索引、SQL改寫等操作
6、查看優(yōu)化后的執(zhí)行時間和執(zhí)行計劃
7、如果優(yōu)化效果不明顯,重復(fù)第四步操作
總結(jié)
這篇文章首先讓你了解慢查詢的表象,讓你可以通過一些工具識別出慢查詢語句;
然后告訴你SQL優(yōu)化的一些常用套路技巧,掌握這些套路技巧至少可以解決80%的SQL優(yōu)化問題;
最后通過一個示例從分析開始一步一步完成慢查詢語句的優(yōu)化,其中查看執(zhí)行計劃是優(yōu)化過程中最終要的操作,大家一定要掌握。