
深度學(xué)習(xí)中GPU和顯存分析

向AI轉(zhuǎn)型的程序員都關(guān)注了這個(gè)號(hào)???
機(jī)器學(xué)習(xí)AI算法工程?? 公眾號(hào):datayx
何為“資源”
不同操作都耗費(fèi)什么資源
如何充分的利用有限的資源
如何合理選擇顯卡
顯存和GPU等價(jià),使用GPU主要看顯存的使用?
Batch Size 越大,程序越快,而且近似成正比?
顯存占用越多,程序越快?
顯存占用大小和batch size大小成正比?
0 預(yù)備知識(shí)
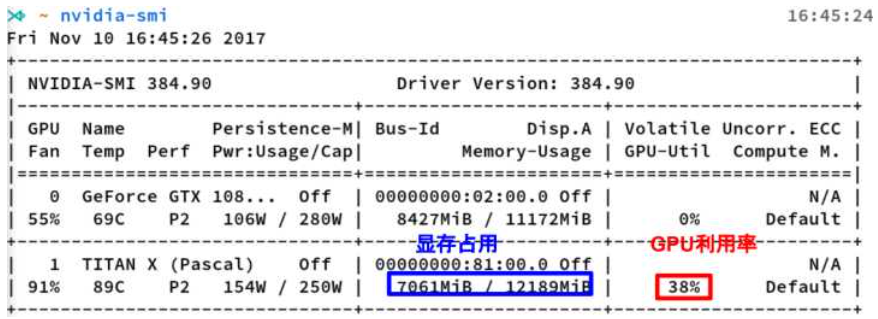
nvidia-smi的輸出
顯存占用
GPU利用率
watch --color -n1 gpustat -cpu
gpustat 輸出
顯存用于存放模型,數(shù)據(jù)
顯存越大,所能運(yùn)行的網(wǎng)絡(luò)也就越大

1. 顯存分析
1.1 存儲(chǔ)指標(biāo)

Type:有Int,F(xiàn)loat,Double等
Num: 一般是 8,16,32,64,128,表示該類型所占據(jù)的比特?cái)?shù)目
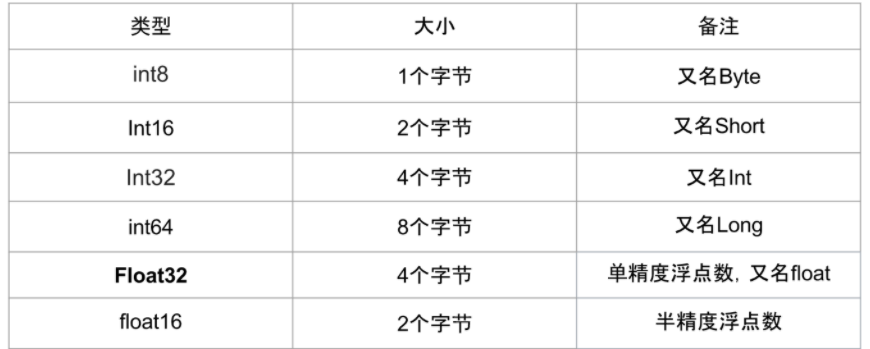
常用的數(shù)值類型

1.2 神經(jīng)網(wǎng)絡(luò)顯存占用
模型自身的參數(shù)
模型的輸出
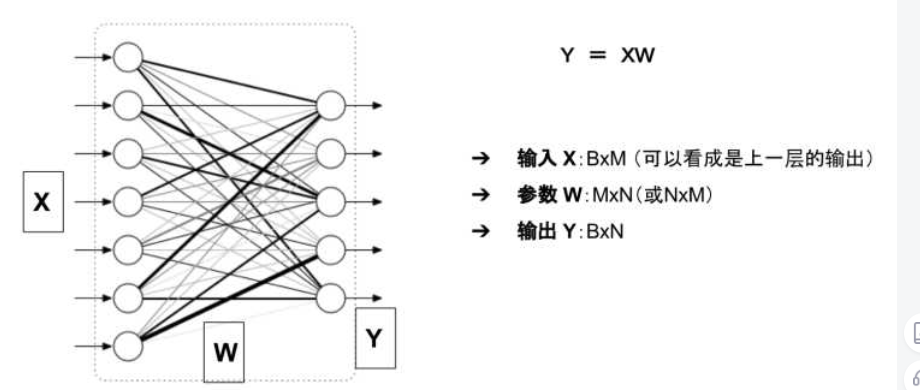
模型的輸入輸出和參數(shù)
參數(shù):二維數(shù)組 W
模型的輸出:二維數(shù)組 Y
1.2.1 參數(shù)的顯存占用
卷積
全連接
BatchNorm
Embedding層
... ...
多數(shù)的激活層(Sigmoid/ReLU)
池化層
Dropout
... ...
Linear(M->N): 參數(shù)數(shù)目:M×N
Conv2d(Cin, Cout, K): 參數(shù)數(shù)目:Cin × Cout × K × K
BatchNorm(N): 參數(shù)數(shù)目:2N
Embedding(N,W): 參數(shù)數(shù)目:N × W
1.2.2 梯度與動(dòng)量的顯存占用

參數(shù)?W
梯度?dW(一般與參數(shù)一樣)
優(yōu)化器的動(dòng)量(普通SGD沒有動(dòng)量,momentum-SGD動(dòng)量與梯度一樣,Adam優(yōu)化器動(dòng)量的數(shù)量是梯度的兩倍)
1.2.3 輸入輸出的顯存占用
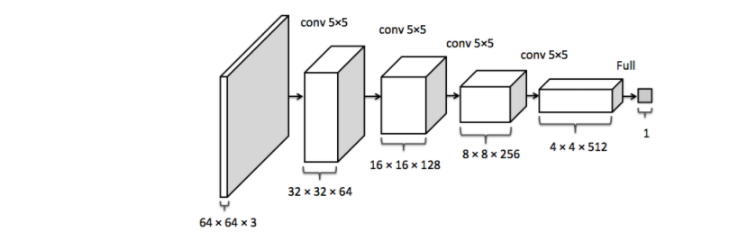
feature map
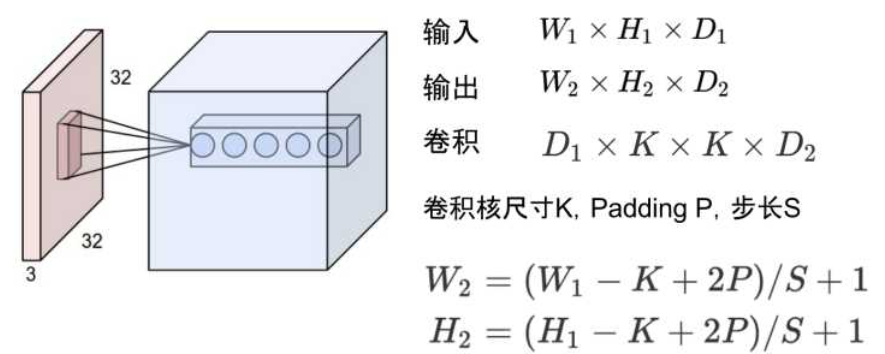
需要計(jì)算每一層的feature map的形狀(多維數(shù)組的形狀)
模型輸出的顯存占用與 batch size 成正比
需要保存輸出對(duì)應(yīng)的梯度用以反向傳播(鏈?zhǔn)椒▌t)
模型輸出不需要存儲(chǔ)相應(yīng)的動(dòng)量信息(因?yàn)椴恍枰獔?zhí)行優(yōu)化)
顯存占用 = 模型顯存占用 + batch_size × 每個(gè)樣本的顯存占用
輸入(數(shù)據(jù),圖片)一般不需要計(jì)算梯度
神經(jīng)網(wǎng)絡(luò)的每一層輸入輸出都需要保存下來(lái),用來(lái)反向傳播,但是在某些特殊的情況下,我們可以不要保存輸入。比如ReLU,在PyTorch中,使用
nn.ReLU(inplace = True)?能將激活函數(shù)ReLU的輸出直接覆蓋保存于模型的輸入之中,節(jié)省不少顯存。感興趣的讀者可以思考一下,這時(shí)候是如何反向傳播的(提示:y=relu(x) ->?dx = dy.copy();dx[y<=0]=0)
1.3 節(jié)省顯存的方法
降低batch-size
下采樣(NCHW -> (1/4)*NCHW)
減少全連接層(一般只留最后一層分類用的全連接層)
2 計(jì)算量分析
2.1 常用操作的計(jì)算量
全連接層:BxMxN , B是batch size,M是輸入形狀,N是輸出形狀。
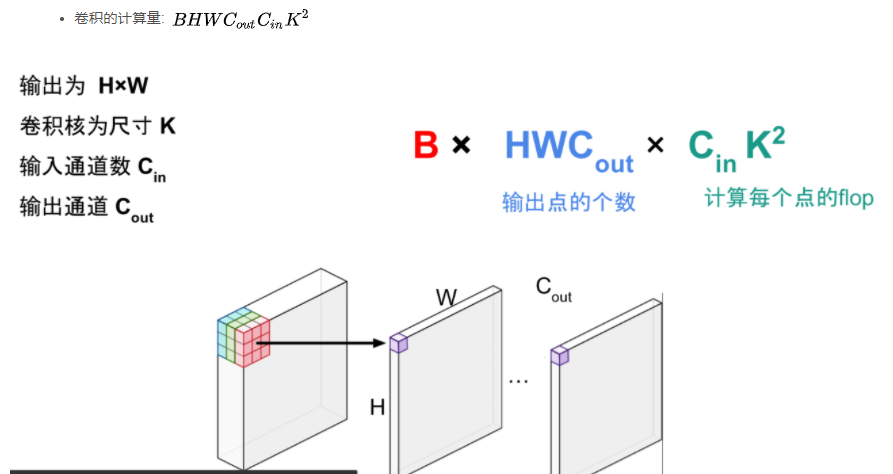
卷積的計(jì)算量分析
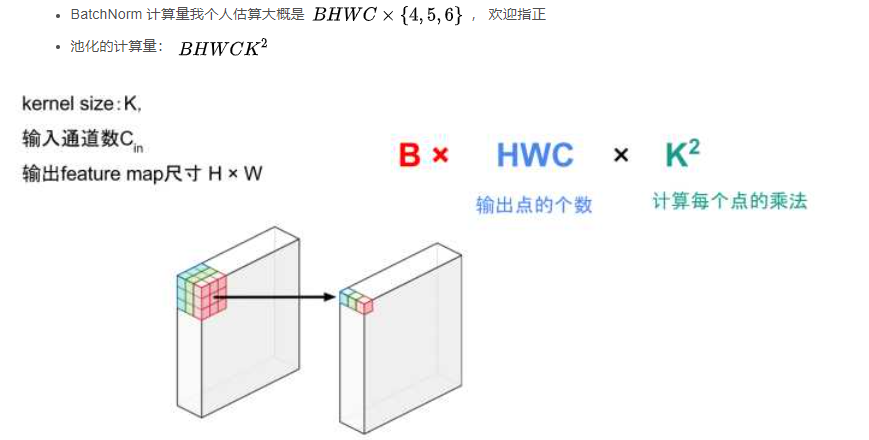
ReLU的計(jì)算量:BHWC
2.2 AlexNet 分析

AlexNet分析
全連接層占據(jù)了絕大多數(shù)的參數(shù)
卷積層的計(jì)算量最大
2.3 減少卷積層的計(jì)算量
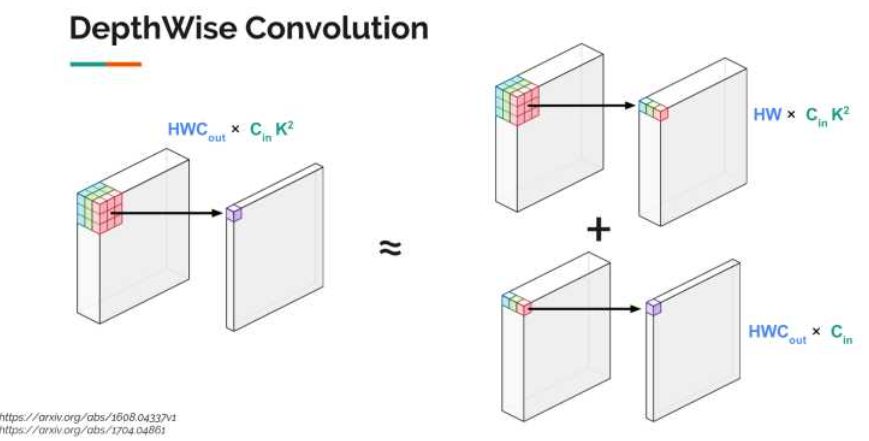
Depthwise Convolution
顯存占用變多(每一步的輸出都要保存
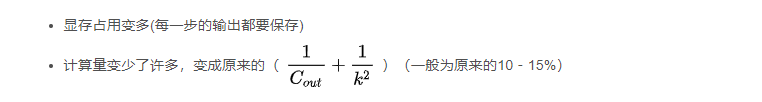
2.4 常用模型 顯存/計(jì)算復(fù)雜度/準(zhǔn)確率
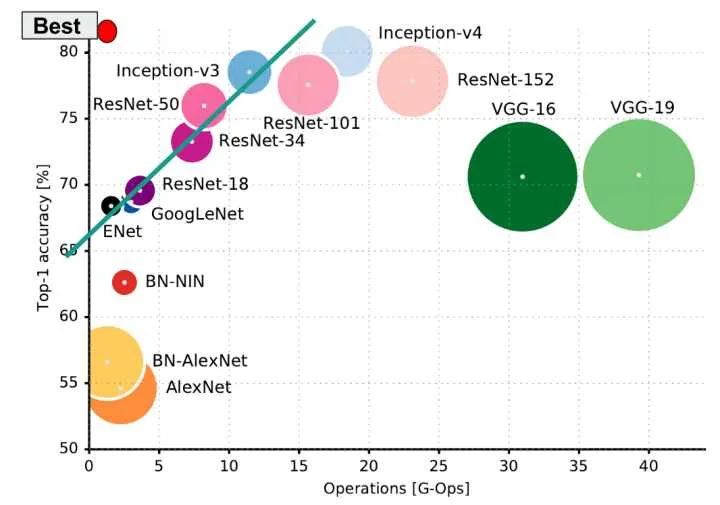
常見模型計(jì)算量/顯存/準(zhǔn)確率
3 總結(jié)
3.1 建議
時(shí)間更寶貴,盡可能使模型變快(減少flop)
顯存占用不是和batch size簡(jiǎn)單成正比,模型自身的參數(shù)及其延伸出來(lái)的數(shù)據(jù)也要占據(jù)顯存
batch size越大,速度未必越快。在你充分利用計(jì)算資源的時(shí)候,加大batch size在速度上的提升很有限
增大batch size能增大速度,但是很有限(主要是并行計(jì)算的優(yōu)化)
增大batch size能減緩梯度震蕩,需要更少的迭代優(yōu)化次數(shù),收斂的更快,但是每次迭代耗時(shí)更長(zhǎng)。
增大batch size使得一個(gè)epoch所能進(jìn)行的優(yōu)化次數(shù)變少,收斂可能變慢,從而需要更多時(shí)間才能收斂(比如batch_size 變成全部樣本數(shù)目)。
3.2 關(guān)于顯卡選購(gòu)
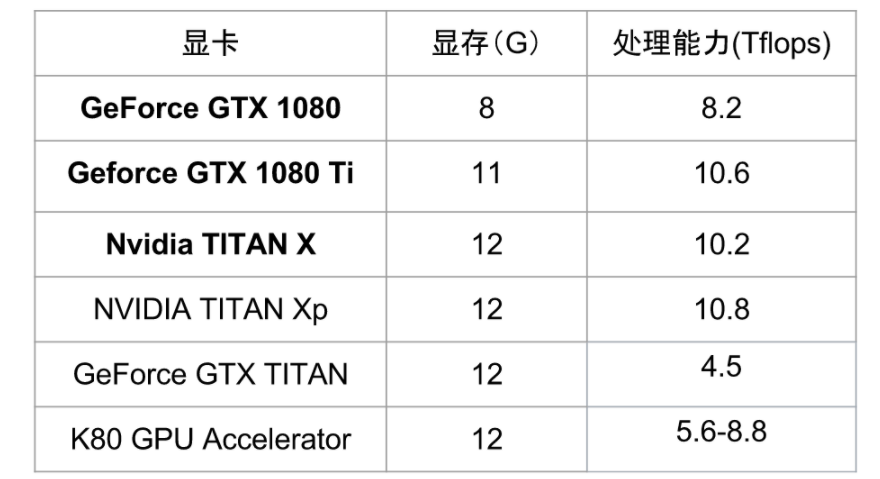
常見顯卡指標(biāo)
K80性價(jià)比很低(速度慢,而且賊貴)
注意GTX TITAN和Nvidia TITAN的區(qū)別,別被騙
另外,針對(duì)本文,我做了一個(gè)Google 幻燈片:神經(jīng)網(wǎng)絡(luò)性能分析,國(guó)內(nèi)用戶可以點(diǎn)此下載ppt
http://link.zhihu.com/?target=http%3A//misc-1252820389.cosbj.myqcloud.com/%25E7%25A5%259E%25E7%25BB%258F%25E7%25BD%2591%25E7%25BB%259C%25E5%2588%2586%25E6%259E%2590.pptx
Google幻燈片格式更好,后者格式可能不太正常。
閱讀過(guò)本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實(shí)戰(zhàn)
基于40萬(wàn)表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測(cè)
《基于深度學(xué)習(xí)的自然語(yǔ)言處理》中/英PDF
Deep Learning 中文版初版-周志華團(tuán)隊(duì)
【全套視頻課】最全的目標(biāo)檢測(cè)算法系列講解,通俗易懂!
《美團(tuán)機(jī)器學(xué)習(xí)實(shí)踐》_美團(tuán)算法團(tuán)隊(duì).pdf
《深度學(xué)習(xí)入門:基于Python的理論與實(shí)現(xiàn)》高清中文PDF+源碼
python就業(yè)班學(xué)習(xí)視頻,從入門到實(shí)戰(zhàn)項(xiàng)目
2019最新《PyTorch自然語(yǔ)言處理》英、中文版PDF+源碼
《21個(gè)項(xiàng)目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實(shí)踐詳解》完整版PDF+附書代碼
《深度學(xué)習(xí)之pytorch》pdf+附書源碼
PyTorch深度學(xué)習(xí)快速實(shí)戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評(píng)分8.1,《機(jī)器學(xué)習(xí)實(shí)戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識(shí)圖譜項(xiàng)目實(shí)戰(zhàn)視頻(全23課)
李沐大神開源《動(dòng)手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計(jì)學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
將機(jī)器學(xué)習(xí)模型部署為REST API
FashionAI服裝屬性標(biāo)簽圖像識(shí)別Top1-5方案分享
重要開源!CNN-RNN-CTC 實(shí)現(xiàn)手寫漢字識(shí)別
同樣是機(jī)器學(xué)習(xí)算法工程師,你的面試為什么過(guò)不了?
前海征信大數(shù)據(jù)算法:風(fēng)險(xiǎn)概率預(yù)測(cè)
【Keras】完整實(shí)現(xiàn)‘交通標(biāo)志’分類、‘票據(jù)’分類兩個(gè)項(xiàng)目,讓你掌握深度學(xué)習(xí)圖像分類
VGG16遷移學(xué)習(xí),實(shí)現(xiàn)醫(yī)學(xué)圖像識(shí)別分類工程項(xiàng)目
特征工程(二) :文本數(shù)據(jù)的展開、過(guò)濾和分塊
如何利用全新的決策樹集成級(jí)聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
全球AI挑戰(zhàn)-場(chǎng)景分類的比賽源碼(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識(shí)別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競(jìng)賽華人第1名團(tuán)隊(duì)-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機(jī)器學(xué)習(xí)、數(shù)據(jù)分析、python
?搜索公眾號(hào)添加:?datayx??
機(jī)大數(shù)據(jù)技術(shù)與機(jī)器學(xué)習(xí)工程
?搜索公眾號(hào)添加:?datanlp
長(zhǎng)按圖片,識(shí)別二維碼