
解Bug之路-記一次線上請求偶爾變慢的排查
解Bug之路-記一次線上請求偶爾變慢的排查
前言
最近解決了個比較棘手的問題,由于排查過程挺有意思,于是就以此為素材寫出了本篇文章。
Bug現(xiàn)場
這是一個偶發(fā)的性能問題。在每天幾百萬比交易請求中,平均耗時大約為300ms,但總有那么100多筆會超過1s,讓我們業(yè)務(wù)耗時監(jiān)控的99.99線變得很尷尬。如下圖所示: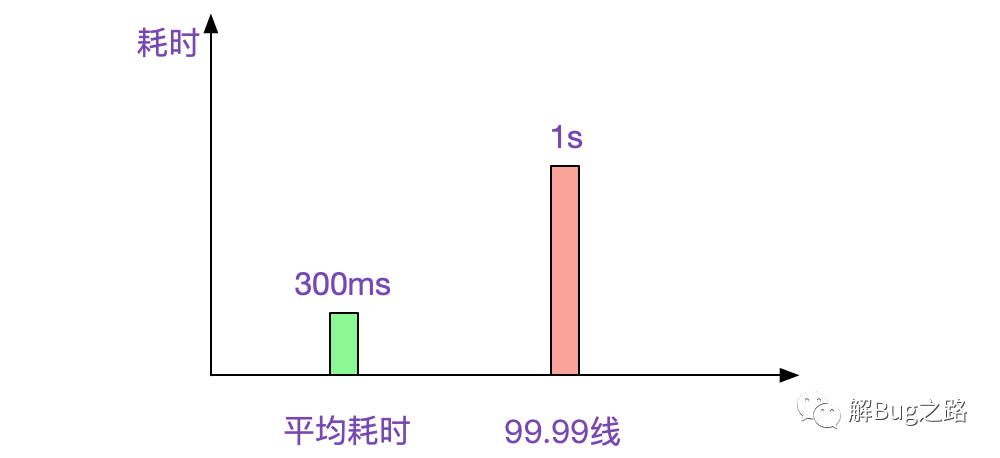
為了精益求精,更為了消除這個尷尬的指標(biāo),筆者開始探尋起這100多慢請求筆的原因。
先找一筆看看
由于筆者寫的框架預(yù)留了traceId,所以找到這筆請求的整個調(diào)用的鏈路還是非常簡單的。而且通過框架中的攔截器在性能日志中算出了每一筆請求的耗時。這樣,非常便于分析鏈路到底是在哪邊耗時了。性能日志中的某個例子如下圖所示:
2020-09-01 15:06:59.010 [abcdefg,A->B,Dubbo-thread-1,ipA->ipB] B.facade,cost 10 ms
拉出來一整條調(diào)用鏈路后,發(fā)現(xiàn)最前面的B系統(tǒng)調(diào)用C系統(tǒng)就比較慢。后面鏈路還有幾個調(diào)用慢的,那先不管三七二十一,先分析B調(diào)用C系統(tǒng)吧。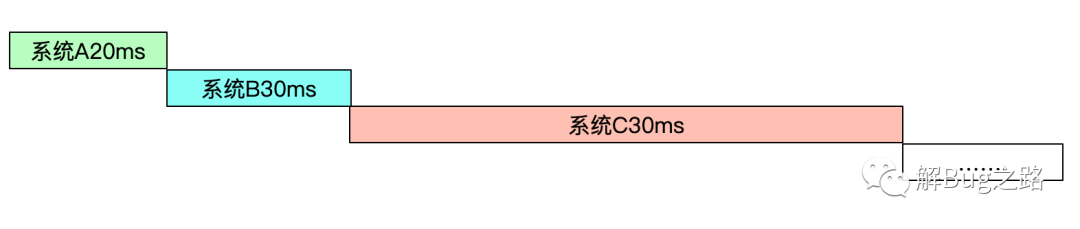
我們從監(jiān)控系統(tǒng)看出來正常的B系統(tǒng)調(diào)用C系統(tǒng)平均耗時只有20ms,這次的耗時增長了10倍!
正常思路,那當(dāng)然是C系統(tǒng)有問題么,畢竟慢了10倍!去C系統(tǒng)的性能日志里面看看,
2020-09-01 15:06:59.210 [abcdefg,B->C,Dubbo-thread-1,ipB->ipC] C.facade,cost 20 ms
啪啪啪打臉,竟然只有20ms,和平均耗時差不多。難道問題在網(wǎng)絡(luò)上?B到C之間由于丟包重傳所以到了200ms?
甩給網(wǎng)絡(luò)?
由于筆者對TCP協(xié)議還是比較了解的,tcp第一次丟包重傳是200ms,那么加上C處理的時間20ms,即220ms必須得大于200ms。而由于Nagle和DelayAck造成的tcp延遲也僅僅是40ms,兩者相加60ms遠(yuǎn)遠(yuǎn)小于200ms,所以這個200ms是丟包或者DelayAck的概率不大。
本著萬一呢的態(tài)度,畢竟下絕對的判斷往往會被打臉,看了下我們的監(jiān)控系統(tǒng),發(fā)現(xiàn)當(dāng)時流量距離網(wǎng)卡容量只有1/10左右,距離打滿網(wǎng)卡還有非常遠(yuǎn)的距離。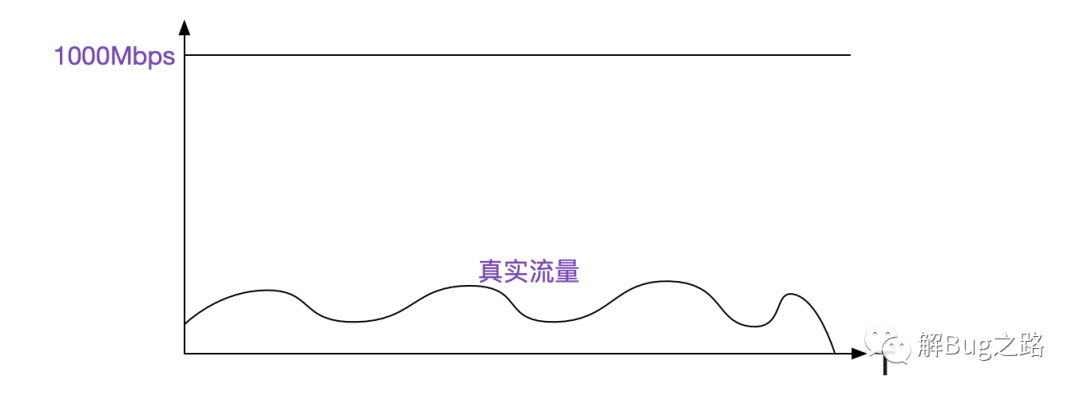
注意,這個監(jiān)控的是由KVM虛擬機(jī)虛擬出來的網(wǎng)卡。看了這個流量,筆者感覺網(wǎng)絡(luò)上問題的概率不大。
GC了?
筆者第二個想到的是GC了,但是觀察了B和C的當(dāng)時時刻的GC日志,非常正常,沒有FullGC,youngGC也在毫秒級,完全不會有200ms這么長。TCP重傳+雙方都youngGC?這個也太巧了點(diǎn)吧,也不是不可用。不過詳細(xì)的計算了時間點(diǎn),并納入了雙方機(jī)器的時鐘誤差后,發(fā)現(xiàn)基本不可能。
再看看其它幾筆
盡然這個問題每天有100多筆(當(dāng)然了,也不排除其中混雜了其它不同的問題),那么就試試看看其它幾筆,有沒有什么共性。這一看,發(fā)現(xiàn)個奇怪的現(xiàn)象,就是有時候是A調(diào)用B慢,有時候是B調(diào)用C慢,還有時候是E調(diào)用F慢。他們唯一的共性就是耗時變長了,但是這個耗時增加的比例有5倍的,有10倍的,完全沒有規(guī)律可循。
這不禁讓筆者陷入了沉思。
尋找突破點(diǎn)
既然通用規(guī)律只有變慢,暫時無法進(jìn)一步挖掘。那么還是去B系統(tǒng)上去看看情況吧,去對應(yīng)B系統(tǒng)上故意不用grep而是用less看了下,上下掃了兩眼。突然發(fā)現(xiàn),貌似緊鄰著的幾條請求都很慢,而且是無差別變慢!也就是說B系統(tǒng)調(diào)用任何系統(tǒng)在這個時間點(diǎn)都有好幾倍甚至十幾倍的耗時!
終于找到了一個突破點(diǎn),B系統(tǒng)本身或者其所屬的環(huán)境應(yīng)該有問題!于是筆者用awk統(tǒng)計了下 B系統(tǒng)這個小時內(nèi)每分鐘的平均調(diào)用時長,用了下面這條命令:
cat 性能日志 | grep '時間點(diǎn) | awk -F ' ' '{print $2, $5}' |.......| awk -F ' ' '{sum[$1]+=$3;count[$1]+=1}END{for(i in sum) {print i,sum[i]/count[i]}}'
發(fā)現(xiàn)
15:00 20
15:01 21
15:02 15
15:03 30
.......
15:06 172.4
15:07 252.4
15:08 181.4
15:10 20
15:10 21
15:10 22
在15:06-15:08這三分鐘之內(nèi),調(diào)用時間會暴漲!但奇怪的是B系統(tǒng)明明有幾十臺機(jī)器,只有這一臺在這個時間段內(nèi)會暴漲。難道這個時間有定時任務(wù)?筆者搜索了下B系統(tǒng)昨天的日志,發(fā)現(xiàn)在同樣的時間段內(nèi),還是暴漲了!再接著搜索其它調(diào)用慢的,例如E->F,發(fā)現(xiàn)他們也在15:06-15:08報錯!于是筆者,一橫心,直接用awk算出了所有系統(tǒng)間調(diào)用慢機(jī)器白天內(nèi)的所有分鐘平均耗時(晚上的流量小不計入內(nèi)),發(fā)現(xiàn):
所有調(diào)用慢的機(jī)器,都非常巧的在每個小時06-08分鐘之內(nèi)調(diào)用慢。再觀察下慢的請求,發(fā)現(xiàn)他們也全部是分布在不同小時的06-08分時間段內(nèi)!
定時任務(wù)?
第一反應(yīng)是有定時任務(wù),查了下所有調(diào)用機(jī)器的crontab沒有問題。問了下對應(yīng)的開發(fā)有沒有調(diào)度,沒有調(diào)度,而且那個時間段由于耗時的原因,每秒請求數(shù)反而變小了。翻了下機(jī)器監(jiān)控,也都挺正常。思維陷入了僵局,突然筆者靈光一閃,我們的應(yīng)用全部是在KVM虛擬機(jī)上,會不會是宿主機(jī)出了問題。于是聯(lián)系了下SA,看看這些機(jī)器的宿主機(jī)是個什么情況。
每個變慢的機(jī)器的宿主機(jī)都有Redis!
這一看就發(fā)現(xiàn)規(guī)律了,原來變慢的機(jī)器上都和Redis共宿主機(jī)!
登陸上對應(yīng)的Redis服務(wù)器,發(fā)現(xiàn)CPU果然在那個時間點(diǎn)有尖峰。而這點(diǎn)尖峰對整個宿主機(jī)的CPU毫無影響(畢竟宿主機(jī)有64個核)。crontab -l 一下,果然有定時任務(wù),腳本名為Backup!它起始時間點(diǎn)就是從06分開始往GlusterFS盤進(jìn)行備份,從06分開始CPU使用率開始上升=>07分達(dá)到頂峰=>08分降下來,和耗時曲線完全一致!
原來Redis往Gluster盤備份占據(jù)了大量的IO操作,所以導(dǎo)致宿主機(jī)上的其它應(yīng)用做IO操作時會變得很慢,進(jìn)而導(dǎo)致但凡是這個備份時間內(nèi)系統(tǒng)間調(diào)用的平均耗時都會暴漲接近10倍,最終導(dǎo)致了高耗時的請求。
為什么調(diào)用請求超時1s的概率這么低
由于我們線上每個應(yīng)用都有幾十臺機(jī)器,而基本每次調(diào)用只有幾十毫秒。所以只有這個請求連續(xù)落到三個甚至多個和Redis共宿主機(jī)的系統(tǒng)里面才會導(dǎo)致請求超過1s,這樣才能被我們的統(tǒng)計腳本監(jiān)測到,而那些大量的正常請求完全拉平了平均值。
解決方案
我們將線上實(shí)時鏈路的系統(tǒng)從對應(yīng)有Redis的宿主機(jī)中遷移出來,再也沒有那個尷尬的1s了。
借此推薦一本書。
總結(jié)
在遇到問題,并且思路陷入僵局時,可以通過一些腳本工具,例如grep以及awk或者其它一些工具對眾多日志進(jìn)行分析,不停的去尋找規(guī)律,從無序中找到有序,往往能夠產(chǎn)生意想不到的效果!歡迎大家加我公眾號,里面有各種干貨,還有大禮包相送哦!