
一條SQL引發(fā)的“血案”:與SQL優(yōu)化相關(guān)的4個案例

導讀:筆者早年間從事了多年開發(fā)工作,后因個人興趣轉(zhuǎn)做數(shù)據(jù)庫。在長期的工作實踐中,看到了數(shù)據(jù)庫工作(特別是SQL優(yōu)化)面臨的種種問題。本文通過幾個案例探討一下SQL優(yōu)化的相關(guān)問題。
作者:馬立和 高振嬌 韓鋒
來源:大數(shù)據(jù)DT(ID:hzdashuju)

具體分析
SELECT?/*+?INDEX?(A1?xxxxx)?*/?SUM(A2.CRKSL),??SUM(A2.CRKSL*A2.DJ)?...
FROM?xxxx?A2,?xxxx?A1?
WHERE?A2.CRKFLAG=xxx?AND?A2.CDATE>=xxx?AND?A2.CDATE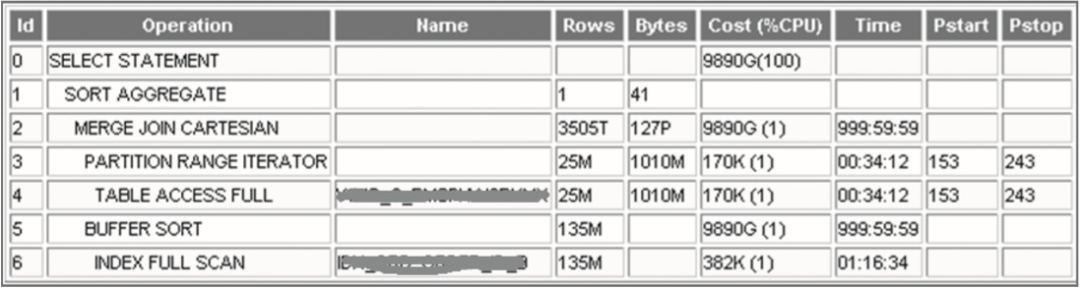
分析結(jié)論
開發(fā)人員的一個疏忽造成了嚴重的后果,原來數(shù)據(jù)庫竟是如此的脆弱。需要對數(shù)據(jù)庫保持“敬畏”之心。 電腦不是人腦,它不知道你的需求是什么,只能根據(jù)寫好的邏輯進行處理。 不要去責怪開發(fā)人員,誰都會犯錯誤,關(guān)鍵是如何從制度上保證不再發(fā)生類似的問題。

create?table?t1?as?select?*?from?dba_objects?where?1=0;
alter?table?t1?add?id?int?primary?key;
create?table?t2?as?select?*?from?dba_objects?where?1=0;
alter?table?t2?add?id?varchar2(10)?primary?key;
insert?into?t1?
select?'test','test','test',rownum,rownum,'test',sysdate,sysdate,'test','test','','','',rownum?
from?dual?
connect?by?rownum<=3200000;
insert?into?t2?
select?'test','test','test',rownum,rownum,'test',sysdate,sysdate,'test','test','','','',rownum?
from?dual?
connect?by?rownum<=3200000;
commit;
execdbms_stats.gather_table_stats(ownname?=>?'hf',tabname?=>?'t1',cascade?=>true,estimate_percent?=>?100);
execdbms_stats.gather_table_stats(ownname?=>?'hf',tabname?=>?'t2',cascade?=>true,estimate_percent?=>?100);
select?*?from?t1?where?id>=?3199990;
11?rows?selected.
--------------------------------------------------------------------------------
|?Id?|?Operation????????????????|?Name???????|Rows?|Bytes|Cost?(%CPU)|??Time????|
---------------------------------------------------------------------------------
|??0?|?SELECT?STATEMENT?????????|????????????|?11??|?693?|???4??(0)?|?00:00:01?|
|??1?|?TABLE?ACCESS?BY?INDEX?ROWID|?T1?????????|?11??|?693?|???4??(0)?|?00:00:01?|
|*?2?|?INDEX?RANGE?SCAN?????????|SYS_C0025294|?11??|?????|???3??(0)?|?00:00:01?|
---------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1??recursive?calls
0??db?block?gets
6??consistent?gets
0??physical?readsselect?*?from?t2?where?id>=?'3199990';
755565?rows?selected.
--------------------------------------------------------------------------
|?Id??|?Operation?????????|?Name?|?Rows??|?Bytes?|?Cost?(%CPU)|?Time?????|
--------------------------------------------------------------------------
|???0?|?SELECT?STATEMENT??|??????|??2417K|???149M|??8927???(2)|?00:01:48?|
|*??1?|??TABLE?ACCESS?FULL|?T2???|??2417K|???149M|??8927???(2)|?00:01:48?|
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1??recursive?calls
0??db?block?gets
82568??consistent?gets
0??physical?reads字符類型在索引中是“亂序”的,這是因為字符類型的排序方式與我們的預期不同。從“select * from t2 where id>= '3199990'”執(zhí)行返回755 565條記錄可見,不是直觀上的10條記錄。這也是當初在做表設(shè)計時,開發(fā)人員沒有注意的問題。 字符類型還導致了聚簇因子很大,原因是插入順序與排序順序不同。詳細點說,就是按照數(shù)字類型插入(1..3200000),按字符類型('1'...'32000000')t排序。
select?table_name,index_name,leaf_blocks,num_rows,clustering_factor
from?user_indexes
where?table_name?in?('T1','T2');
TABLE_NAME?????????INDEX_NAME??????LEAF_BLOCKS???NUM_ROWS????CLUSTERING_FACTOR
--------------?--------------?----------------?----------?---------------------
T1???????????????SYS_C0025294?????????????6275????3200000?????????????????31520
T2???????????????SYS_C0025295????????????13271????3200000????????????????632615
在對字符類型使用大于運算符時,會導致優(yōu)化器認為需要掃描索引大部分數(shù)據(jù)且聚簇因子很大,最終導致棄用索引掃描而改用全表掃描方式。
select?*?from?t2?where?id?between?'3199990'?and?'3200000';
--------------------------------------------------------------------------------
|?Id??|?Operation?????????????????|?Name?????????|Rows|Bytes?|Cost(%CPU)|?Time???|
--------------------------------------------------------------------------------
|???0?|?SELECT?STATEMENT??????????|?????????????|???6|??390?|???5?(0)|00:00:01|
|???1?|??TABLE?ACCESS?BY?INDEX?ROWID|?T2???????????|???6|??390?|???5?(0)|00:00:01|
|*??2?|???INDEX?RANGE?SCAN????????|?SYS_C0025295?|???6|??????|???3?(0)|00:00:01|
--------------------------------------------------------------------------------
Statistics
----------------------------------------------------------
1??recursive?calls
0??db?block?gets
13??consistent?gets
0??physical?reads糟糕的數(shù)據(jù)結(jié)構(gòu)設(shè)計往往是致命的,后期的優(yōu)化只是補救措施。只有從源頭上加以杜絕,才是優(yōu)化的根本。 在設(shè)計初期能引入數(shù)據(jù)庫審核,可以起到很好的作用。

select?...?from?...
where
(
????(?
??order_creation_date>=?to_date(20120208,'yyyy-mm-dd')?and?
????order_creation_date<to_date(20120209,'yyyy-mm-dd')
????)?
or
????(?
??send_date>=?to_date(20120208,'yyyy-mm-dd')?and?send_date<to_date(20120209, 'yyyy-mm-dd')
????)
)
andnvl(a.bd_id,0)?=?1
--------------------------------------------------------------------------------
|??Id?|?Operation??????????????|?Name???|Cost?(%CPU)|?Time???|Pstart?|?Pstop?|
--------------------------------------------------------------------------------
|???0?|?SELECT?STATEMENT???????|????????|?2470K(100)|????????|???????|???????|
|???1?|??SORT?GROUP?BY?????????|????????|???????????|????????|???????|???????|
|???2?|???TABLE?ACCESS?BY?GLOBAL?INDEX?ROWID
??????????????????????????????????|??XXXX??|?????5?(0)?|?00:00:01?|?ROW?L?|?ROW?L?|
|???3?|????NESTED?LOOPS?????????|????????|?2470K?(1)?|?08:14:11?|???????|???????|
|???4?|?????VIEW???????????????|VW_NSO_1|?2470K?(1)?|?08:14:10?|???????|???????|
|???5?|??????FILTER????????????|????????|???????????|??????????|???????|???????|
|???6?|???????HASH?GROUP?BY????|????????|??2470K?(1)|?08:14:10?|???????|???????|
|???7?|????????TABLE?ACCESS?BY?GLOBAL?INDEX?ROWID?
???????????????????????????????|??XXXX??|??????5?(0)|?00:00:01?|?ROW?L?|?ROW?L?|
|???8?|?????????NESTED?LOOPS????|????????|??2470K?(1)|?08:14:10?|???????|???????|
|???9?|??????????SORT?UNIQUE????|????????|??2340K?(2)|?07:48:11?|???????|???????|
|??10?|???????????PARTITION?RANGE?ALL??
????????????????????????????????|????????|??2340K?(2)|?07:48:11?|????1??|????92?|
|??11?|????????????TABLE?ACCESS?FULL
????????????????????????????????|??XXXX??|??2340K?(2)|?07:48:11?|????1??|????92?|
|??12?|??????????INDEX?RANGE?SCAN?
????????????????????????????????|??XXXX??|??????3?(0)|?00:00:01?|???????|???????|
|??13?|?????INDEX?RANGE?SCAN????|??XXXX??|??????3?(0)|?00:00:01?|???????|???????|
--------------------------------------------------------------------------------
select?...
from?...
where?
????order_creation_date?>=?to_date(20120208,'yyyy-mm-dd')?and?
????order_creation_date<to_date(20120209,'yyyy-mm-dd')
union?all
select?...
from?...
where
send_date>=?to_date(20120208,'yyyy-mm-dd')?and?
????send_date<to_date(20120209,'yyyy-mm-dd')?and?
nvl(a.bd_id,0)?=?5
select?...
from?...
where
(
????(?
????????order_creation_date>=?to_date(20120208,'yyyymmdd')?and?
????????order_creation_date<to_date(20120209,'yyyymmdd')
????)?
or
????(?
????????send_date>=?to_date(20120208,'yyyymmdd')?and?
????????send_date<to_date(20120209,'yyyymmdd')
????)
);
--------------------------------------------------------------------------------
|??Id???|?Operation???????????|?Name?|?Cost(%CPU)|Time??????|?Pstart??|?Pstop???|
--------------------------------------------------------------------------------
|?????0?|?SELECT?STATEMENT????|??????|??42358?(1)|?00:08:29?|?????????|?????????|
|?????1?|??SORT?AGGREGATE?????|??????|???????????|??????????|?????????|?????????|
|?????2?|???CONCATENATION?????|??????|???????????|??????????|?????????|?????????|
|?????3?|????PARTITION?RANGE?SINGLE
??????????????????????????????|??????|??17393?(1)|?00:03:29?|??????57?|?????57?|
|*????4?|?????TABLE?ACCESS?FULL
??????????????????????????????|?XXXX?|??17393?(1)|?00:03:29?|??????57?|?????57?|
|*????5?|????TABLE?ACCESS?BY?GLOBAL?INDEX?ROWID?
??????????????????????????????|?XXXX?|??24966?(1)|?00:05:00?|???ROWID?|??ROWID?|
|*????6?|?????INDEX?RANGE?SCAN??
??????????????????????????????|?XXXX?|????658?(1)|?00:00:08?|?????????|?????????|
---------------------------------------------------------------------------------
規(guī)范的SQL寫法,不但利于提高代碼可讀性,還有利于優(yōu)化器生成更優(yōu)的執(zhí)行計劃。 分區(qū)功能是Oracle應(yīng)對大數(shù)據(jù)的利器,但在使用中要注意是否真正會用到分區(qū)特性;否則,可能適得其反,使用分區(qū)會導致效率更差。
select...
from?xxx?a?join?xxx?b?on?a.order_id?=?b.lyywzdid
left?join?xxx?c?on?b.gysid?=?c.gysid
whereb.cdate>=?to_date('2012-03-31',?'yyyy-mm-dd')?–?3?and?...
a.send_date>=?to_date('2012-03-31',?'yyyy-mm-dd')?-?1?and?
a.send_date<to_date('2012-03-31',?'yyyy-mm-dd');
--------------------------------------------------------------------------------
|Id??|?Operation??????????|Name??|??Rows??|??Bytes??|?Cost?(%CPU)?|Pstart|Pstop|
--------------------------------------------------------------------------------
|??0?|?SELECT?STATEMENT???|??????|??????1?|?????104?|??????9743(1)|??????|?????|
|??1?|??HASH?JOIN?OUTER???|??????|??????1?|?????104?|??????9743(1)|??????|?????|
|??2?|???TABLE?ACCESS?BY?LOCAL?INDEX?ROWID
??????????????????????????|?XXXX?|??????1?|??????22?|?????????0(0)|?1189?|?1189|
|??3?|????NESTED?LOOPS????|??????|??????1?|??????94?|??????9739(1)|??????|?????|
|??4?|?????PARTITION?RANGE?ITERATOR????
??????????????????????????|??????|???1032?|???74304?|??????9739(1)|??123?|?518?|
|??5?|??????TABLE?ACCESS?FULL?
??????????????????????????|?XXXX?|???1032?|???74304?|??????9739(1)|??123?|?518?|
|??6?|?????PARTITION?RANGE?SINGLE
??????????????????????????|??????|??????1?|?????????|?????????0(0)|?1189?|?1189?|
|??7?|??????INDEX?RANGE?SCAN?
??????????????????????????|?XXXX?|??????1?|?????????|?????????0(0)|?1189?|?1189?|
|??8?|???TABLE?ACCESS?FULL
??????????????????????????|?XXXX?|????183?|????1830?|?????????3(0)|??????|?????|
--------------------------------------------------------------------------------
exec?dbms_stats.gather_index_stats(
??ownname=>'xxx',?
??indname=>'xxx',
??partname=>'PART_xxx',?
??estimate_percent?=>?10);
統(tǒng)計信息是優(yōu)化器優(yōu)化的重要參考依據(jù),一個完整、準確的統(tǒng)計信息是必要條件。往往在優(yōu)化過程中,第一步就是查看相關(guān)對象的統(tǒng)計信息。 分區(qū)機制是Oracle針對大數(shù)據(jù)的重要解決手段,但也很容易造成所謂“放大效應(yīng)”。即對于普通表而言,統(tǒng)計信息更新不及時可能不會導致執(zhí)行計劃偏差過大;但對于分區(qū)表、索引來說,很容易出現(xiàn)因更新不及時出現(xiàn)0的情況,進而導致執(zhí)行計劃產(chǎn)生嚴重偏差。

評論
圖片
表情