
UNet為什么在醫(yī)學(xué)圖像分割表現(xiàn)好?
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達

本文轉(zhuǎn)自:人工智能與算法學(xué)習(xí)
UNet網(wǎng)絡(luò)在被提出后,就大范圍地用于醫(yī)學(xué)圖像的分割。其能在醫(yī)學(xué)圖像展現(xiàn)優(yōu)秀的性能和它本身網(wǎng)絡(luò)結(jié)構(gòu)存在怎樣的一種聯(lián)系?
這個問題在面試醫(yī)療影像算法崗位的時候,偶爾會提到,我這里提供一些個人的思考。問題中有兩個關(guān)鍵詞,【UNet】和【醫(yī)療影像】,接下來我們一一分析這兩個關(guān)鍵詞。
首先我們說說【UNet】。
UNet最早發(fā)表在2015的MICCAI上,短短3年,引用量目前已經(jīng)達到了4070,足以見得其影響力。而后成為大多做醫(yī)療影像語義分割任務(wù)的baseline,也啟發(fā)了大量研究者去思考U型語義分割網(wǎng)絡(luò)。而如今在自然影像理解方面,也有越來越多的語義分割和目標(biāo)檢測SOTA模型開始關(guān)注和使用U型結(jié)構(gòu),比如語義分割Discriminative Feature Network(DFN)(CVPR2018),目標(biāo)檢測Feature Pyramid Networks for Object Detection(FPN)(CVPR 2017)等。
我們言歸正傳,UNet只是一個網(wǎng)絡(luò)結(jié)構(gòu)的代號而已,我們究其細節(jié),到底UNet是由哪些組件構(gòu)成的呢?
UNet的結(jié)構(gòu),我認為有兩個最大的特點,U型結(jié)構(gòu)和skip-connection(如下圖)。
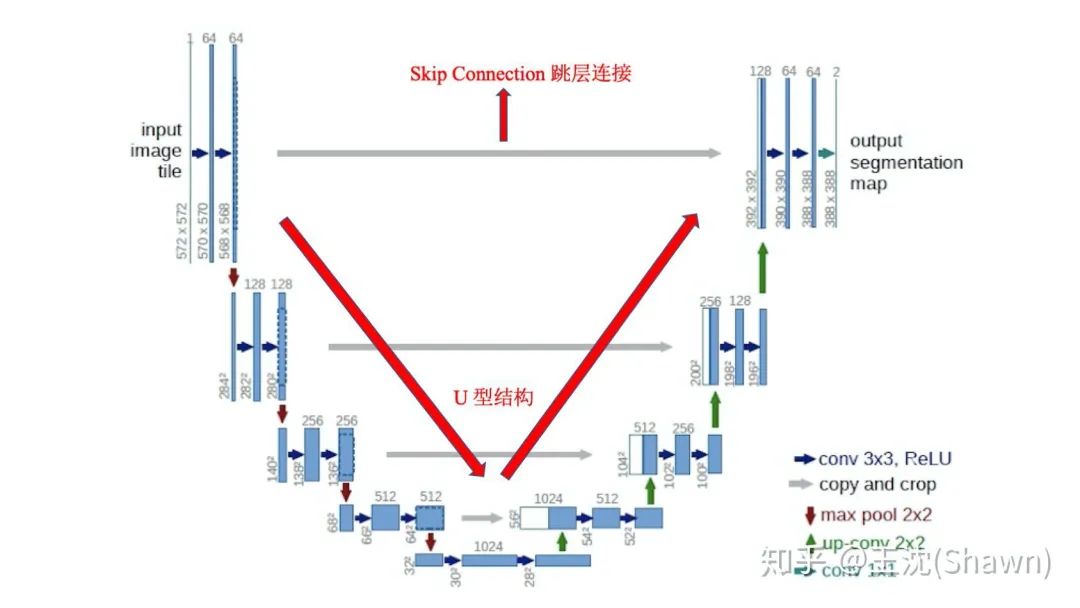
UNet的encoder下采樣4次,一共下采樣16倍,對稱地,其decoder也相應(yīng)上采樣4次,將encoder得到的高級語義特征圖恢復(fù)到原圖片的分辨率。
相比于FCN和Deeplab等,UNet共進行了4次上采樣,并在同一個stage使用了skip connection,而不是直接在高級語義特征上進行監(jiān)督和loss反傳,這樣就保證了最后恢復(fù)出來的特征圖融合了更多的low-level的feature,也使得不同scale的feature得到了的融合,從而可以進行多尺度預(yù)測和DeepSupervision。4次上采樣也使得分割圖恢復(fù)邊緣等信息更加精細。
其次我們聊聊【醫(yī)療影像】,醫(yī)療影像有什么樣的特點呢(尤其是相對于自然影像而言)?
1.圖像語義較為簡單、結(jié)構(gòu)較為固定。我們做腦的,就用腦CT和腦MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一個固定的器官的成像,而不是全身的。由于器官本身結(jié)構(gòu)固定和語義信息沒有特別豐富,所以高級語義信息和低級特征都顯得很重要(UNet的skip connection和U型結(jié)構(gòu)就派上了用場)。舉兩個例子直觀感受下。
A.腦出血. 在CT影像上,高密度的區(qū)域就大概率是一塊出血,如下圖紅色框區(qū)域。

B.眼底水腫。左圖原圖,右圖標(biāo)注(不同灰度值代表不同的水腫病變區(qū)域)。在OCT上,凸起或者凹陷的區(qū)域就大概率是一個水腫病變的區(qū)域。

2.數(shù)據(jù)量少。醫(yī)學(xué)影像的數(shù)據(jù)獲取相對難一些,很多比賽只提供不到100例數(shù)據(jù)。所以我們設(shè)計的模型不宜多大,參數(shù)過多,很容易導(dǎo)致過擬合。
原始UNet的參數(shù)量在28M左右(上采樣帶轉(zhuǎn)置卷積的UNet參數(shù)量在31M左右),而如果把channel數(shù)成倍縮小,模型可以更小。縮小兩倍后,UNet參數(shù)量在7.75M。縮小四倍,可以把模型參數(shù)量縮小至2M以內(nèi),非常輕量。個人嘗試過使用Deeplab v3+和DRN等自然圖像語義分割的SOTA網(wǎng)絡(luò)在自己的項目上,發(fā)現(xiàn)效果和UNet差不多,但是參數(shù)量會大很多。
3.多模態(tài)。相比自然影像,醫(yī)療影像比較有趣和不同的一點是,醫(yī)療影像是具有多種模態(tài)的。以ISLES腦梗競賽為例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多種模態(tài)的數(shù)據(jù)。
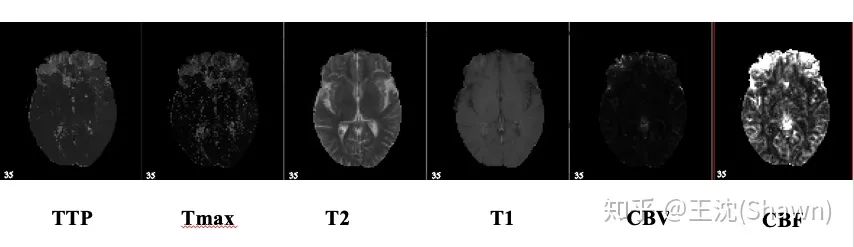
這就需要我們更好的設(shè)計網(wǎng)絡(luò)去提取不同模態(tài)的特征feature。這里提供兩篇論文供大家參考。
Joint Sequence Learning and Cross-Modality Convolution for 3D Biomedical Segmentation(CVPR 2017) ,
Dense Multi-path U-Net for Ischemic Stroke Lesion Segmentation in Multiple Image Modalities.
4.可解釋性重要。由于醫(yī)療影像最終是輔助醫(yī)生的臨床診斷,所以網(wǎng)絡(luò)告訴醫(yī)生一個3D的CT有沒有病是遠遠不夠的,醫(yī)生還要進一步的想知道,病灶在哪一層,在哪一層的哪個位置,分割出來了嗎,能求體積嘛?同時對于網(wǎng)絡(luò)給出的分類和分割等結(jié)果,醫(yī)生還想知道為什么,所以一些神經(jīng)網(wǎng)絡(luò)可解釋性的trick就有用處了,比較常用的就是畫activation map。看網(wǎng)絡(luò)的哪些區(qū)域被激活了,如下圖。

這里推薦兩篇工作:@周博磊老師的Learning Deep Features for Discriminative Localization(CVPR2016)和其實驗室同學(xué)的 Deep Learning for Identifying Metastatic Breast Cancer(上圖的出處)
BTW:沒有偏題的意思,只是覺得醫(yī)療影像的特點和本問題息息相關(guān),就一起總結(jié)了。
最后提一個問題,引發(fā)關(guān)注醫(yī)療影像的同學(xué)們思考和討論?
前面有提到,UNet成為大多做醫(yī)療影像語義分割任務(wù)的baseline,也啟發(fā)了大量研究者去思考U型語義分割網(wǎng)絡(luò)。那UNet還有什么不足呢?
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~