
學(xué)習(xí)網(wǎng)絡(luò)爬蟲有多難?
點(diǎn)擊上方藍(lán)字關(guān)注我們


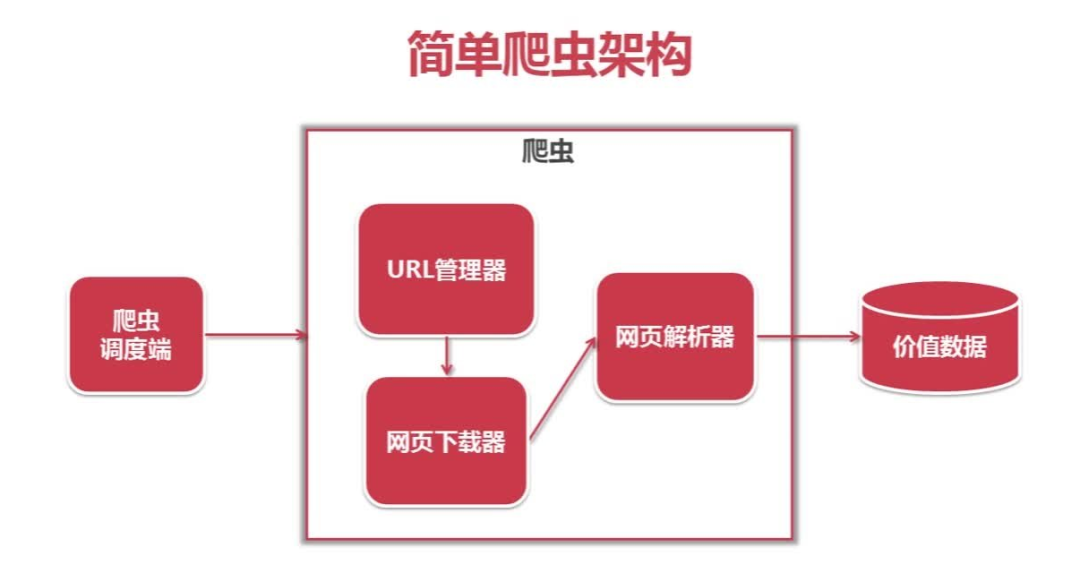
學(xué)習(xí)爬蟲,我們首先要了解什么是爬蟲以及它的工作流程,知己知彼,方能百戰(zhàn)百勝嘛。
爬蟲基礎(chǔ)知識(shí)點(diǎn)
1、請求與響應(yīng)
2、爬蟲與反爬蟲
3、開發(fā)工具
4、Urllib庫使用詳解與項(xiàng)目實(shí)戰(zhàn)
5、requests庫安裝使用與項(xiàng)目實(shí)戰(zhàn)
爬蟲進(jìn)階
1、爬蟲框架實(shí)現(xiàn)
2、破解反爬技術(shù)
3、代理池實(shí)現(xiàn)
4、模擬登陸
5、pyspider框架
爬蟲高級部分
1、APP的抓取
2、Scrapy框架
3、分布式爬蟲實(shí)戰(zhàn)
4、分布式爬蟲部署
可見在學(xué)習(xí)python網(wǎng)絡(luò)爬蟲的道路上任重而道遠(yuǎn)。不過也沒有你想的那么復(fù)雜,因?yàn)橹泵媾老x的道路上我會(huì)和你一起!
文末福利:

掃碼二維碼
獲取更多精彩
python學(xué)前班


掃碼回復(fù)‘爬蟲’分享給你最新爬蟲教程!

點(diǎn)個(gè)在看你最好看

評論
圖片
表情