
【TensorFlow】筆記:基礎知識-使用keras建立線性回歸
點擊上方“公眾號”可訂閱哦!
Keras 模型以類的形式呈現(xiàn),我們可以通過繼承?tf.keras.layers.Layer?這個 Python 類來定義自己的模型。在繼承類中,我們需要重寫?__init__()?(構造函數(shù),初始化)和?call(input)?(模型調(diào)用)兩個方法,同時也可以根據(jù)需要增加自定義的方法。
01
keras模型類定義示意
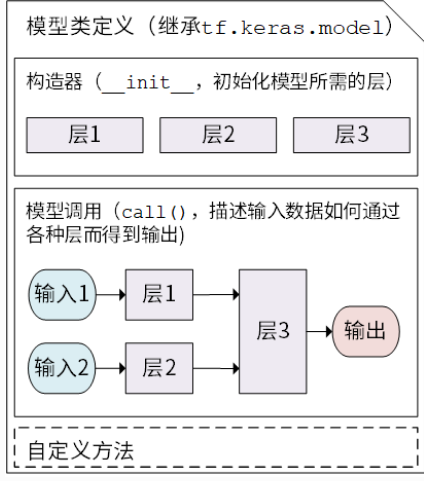
繼承?tf.keras.Model?后,我們同時可以使用父類的若干方法和屬性,例如在實例化類?model?=?Model()?后,可以通過?model.variables?這一屬性直接獲得模型中的所有變量,免去我們一個個顯式指定變量的麻煩。
使用模型類編寫線性模型
import tensorflow as tfX = tf.constant([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])y = tf.constant([[10.0], [20.0]])class Linear(tf.keras.Model):def __init__(self):super().__init__()self.dense = tf.keras.layers.Dense(units=1,activation=None,kernel_initializer=tf.zeros_initializer(),bias_initializer=tf.zeros_initializer())def call(self, input):output = self.dense(input)return output
實例化模型:
model = Linear()optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)for i in range(100):with tf.GradientTape() as tape:y_pred = model(X) # 調(diào)用模型 y_pred = model(X) 而不是顯式寫出 y_pred = a * X + bloss = tf.reduce_mean(tf.square(y_pred - y))grads = tape.gradient(loss, model.variables) # 使用 model.variables 這一屬性直接獲得模型中的所有變量optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))print(model.variables)
這里,我們沒有顯式地聲明?a?和?b?兩個變量并寫出?y_pred?=?a?*?X?+?b?這一線性變換,而是建立了一個繼承了?tf.keras.Model?的模型類?Linear?。這個類在初始化部分實例化了一個?全連接層(?tf.keras.layers.Dense?),并在 call 方法中對這個層進行調(diào)用,實現(xiàn)了線性變換的計算。
02
全連接層
全連接層?(Fully-connected Layer,tf.keras.layers.Dense?)是 Keras 中最基礎和常用的層之一,對輸入矩陣?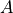 ?進行?
?進行?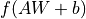 ?的線性變換 + 激活函數(shù)操作。如果不指定激活函數(shù),即是純粹的線性變換?
?的線性變換 + 激活函數(shù)操作。如果不指定激活函數(shù),即是純粹的線性變換?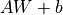 。具體而言,給定輸入張量 input =?[batch_size, input_dim]?,該層對輸入張量首先進行 tf.matmul(input, kernel)?+ bias 的線性變換( kernel 和 bias 是層中可訓練的變量),然后對線性變換后張量的每個元素通過激活函數(shù) activation ,從而輸出形狀為?[batch_size, units]?的二維張量。
。具體而言,給定輸入張量 input =?[batch_size, input_dim]?,該層對輸入張量首先進行 tf.matmul(input, kernel)?+ bias 的線性變換( kernel 和 bias 是層中可訓練的變量),然后對線性變換后張量的每個元素通過激活函數(shù) activation ,從而輸出形狀為?[batch_size, units]?的二維張量。
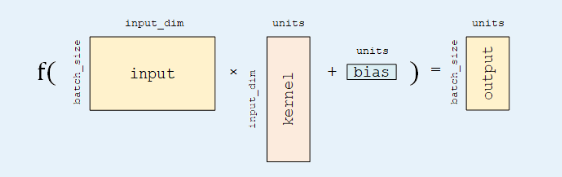
units:輸出張量的維度
activation:激活函數(shù),常用激活函數(shù)tf.nn.relu 、 tf.nn.tanh 和 tf.nn.sigmoid
use_bias:是否加入偏置向量bias
kernel_initializer 、 bias_initializer:權重矩陣 kernel 和偏置向量 bias 兩個變量的初始化器
?END

深度學習入門筆記
微信號:sdxx_rmbj
日常更新學習筆記、論文簡述