
挑選有用樣本,提升模型整體性能!
大家好,我是DASOU;
在模型的訓(xùn)練過(guò)程中,樣本的質(zhì)量參差不齊,在任務(wù)中找到真正有用的訓(xùn)練樣本可以說(shuō)一直是機(jī)器學(xué)習(xí)研究者們共同的訴求;今天介紹的文章解讀了兩個(gè)論文,從兩個(gè)不同角度提升模型性能;
正文如下:
今天要介紹的兩篇工作,則是以上述思路出發(fā),從兩個(gè)不同的角度去提升模型的性能。[1]通過(guò)模型的中間結(jié)果,尋找出訓(xùn)練集中真正重要的樣本,給模型訓(xùn)練,從而做到刪減數(shù)據(jù)集之后,也能得到很好的測(cè)試精度;[2]通過(guò)反復(fù)訓(xùn)練模型表現(xiàn)很差的那一部分樣本,從而提升模型的整體測(cè)試效果。
1. 開局少一半數(shù)據(jù),咱也依然能贏!
論文題目:
Deep Learning on a Data Diet: Finding Important Examples Early in Training
論文鏈接:
https://arxiv.org/abs/2107.07075
2018 年,Toneva et al.[3]從“遺忘”的角度去研究了數(shù)據(jù)的重要性。文中定義了“遺忘事件”,即在訓(xùn)練中某一個(gè)時(shí)刻,更新參數(shù)前原本預(yù)測(cè)正確的樣本在更新參數(shù)后預(yù)測(cè)錯(cuò)誤了,即認(rèn)為發(fā)生了一次遺忘。作者據(jù)此定義了樣本的“遺忘分?jǐn)?shù)”,用于量化樣本是否容易被遺忘。
由此,作者發(fā)現(xiàn),一些很少被遺忘的樣本對(duì)最終測(cè)試精度的影響也很小,反倒是容易被遺忘的那些樣本會(huì)影響最終的評(píng)測(cè)效果。而通過(guò)這種方式,我們自然也能夠通過(guò)遺忘分?jǐn)?shù)去刪減數(shù)據(jù)集,即留下那些容易被遺忘的數(shù)據(jù),去掉那些不容易被遺忘的數(shù)據(jù)。
而由于這個(gè)方法需要在訓(xùn)練中收集到遺忘的統(tǒng)計(jì)數(shù)據(jù),最終的遺忘分?jǐn)?shù)往往需要在訓(xùn)練中后期計(jì)算完成。文章在 CIFAR-10 數(shù)據(jù)集上訓(xùn)練了 200 個(gè) epoch,在第 25 個(gè) epoch 的時(shí)候開始得到比較好的遺忘分?jǐn)?shù),第 75 個(gè) epoch 開始遺忘分?jǐn)?shù)趨于穩(wěn)定。
本文作者希望,在訓(xùn)練早期,就可以確認(rèn)數(shù)據(jù)的重要性,這樣既可以大幅度減少模型訓(xùn)練時(shí)間和計(jì)算資源消耗,也可以對(duì)DNN模型的訓(xùn)練過(guò)程,及數(shù)據(jù)起到的作用等提供重要的見解。
同樣,本文也想要找到訓(xùn)練集中“重要”的數(shù)據(jù),這里對(duì)“重要”的定義是:訓(xùn)練樣本對(duì) Loss 減少的貢獻(xiàn),也就是說(shuō),在訓(xùn)練過(guò)程中,利用這個(gè)樣本優(yōu)化模型參數(shù)之后,其他樣本計(jì)算得到的 Loss 減少的量。這個(gè)定義非常直觀反映了這條樣本的泛化能力,通過(guò)擬合這一條樣本,模型能夠從中得到多少幫助其擬合其他樣本的信息。
那么,很直觀的想法就是,直接求取一條樣本計(jì)算得到的梯度的范數(shù)。由于現(xiàn)在 DNN 模型都是用梯度下降方法更新參數(shù)的,那么這個(gè)值可以直接反映出該條樣本對(duì)模型參數(shù)權(quán)重的影響程度,這個(gè)影響程度我們就可以看作它對(duì)模型擬合其他樣本的影響程度了。
樣本重要程度的定義
在訓(xùn)練的 時(shí)刻,樣本 的重要程度(GraNd)為:
其中,,也就是該時(shí)刻,樣本的 Loss 的梯度。
下面我們從數(shù)學(xué)角度論證一下:
在 時(shí)刻,Minibatch 中的樣本 計(jì)算得到 Loss 的導(dǎo)數(shù)為:
根據(jù)鏈?zhǔn)椒▌t,則:
而 是 時(shí)刻權(quán)重的變化,則有
而由于模型權(quán)重是由梯度下降更新的,則有:
從而,
那么實(shí)際上,我們需要理解,當(dāng)從 中刪除一條訓(xùn)練樣本時(shí),會(huì)怎樣影響權(quán)重的變化?
設(shè),對(duì)于所有樣本 ,存在一個(gè)常數(shù) ,使得:
證明:根據(jù)上面的式子,導(dǎo)出,代入,則令 ,結(jié)果成立。
當(dāng)然這個(gè)式子在推導(dǎo)過(guò)程中是有不嚴(yán)謹(jǐn)?shù)牡胤剑绱氲仁街螅驍?shù)是不能提取的,所以 值實(shí)際有問(wèn)題,但不等式成立,這部分在撰寫時(shí)尊重原作者。
訓(xùn)練樣本的貢獻(xiàn)由上式限定下來(lái),由于常數(shù) 不受具體樣本 影響,則只需要看樣本的 Loss 的梯度的范數(shù)即可,也就是 GraNd 分?jǐn)?shù)。(3)式表明,GraNd 分?jǐn)?shù)較小的樣本對(duì)模型區(qū)分其余樣本的的影響是有限的,那么就可以根據(jù)訓(xùn)練樣本 GraNd 分?jǐn)?shù)的排名,去裁剪樣本,越高的分?jǐn)?shù)表明樣本對(duì)的影響越大。
對(duì)于任意輸入 ,設(shè),表示第 k 個(gè) Logit 的梯度,根據(jù)鏈?zhǔn)椒▌t,則 GraNd 分?jǐn)?shù)可以寫成如下形式:
當(dāng)使用交叉熵loss時(shí),有
當(dāng)與 Logits 之間大體正交,且與 Logits 和訓(xùn)練樣本 之間有相似的大小時(shí),則 GraNd 可以通過(guò)“錯(cuò)誤向量”的范數(shù)近似計(jì)算。
此處定義訓(xùn)練樣本的 EL2N 分?jǐn)?shù)(即錯(cuò)誤向量)為。
而實(shí)際上,作者也將本文給出的兩種計(jì)算樣本重要度的分?jǐn)?shù) GraNd 和 EL2N 與[3]的遺忘分?jǐn)?shù)進(jìn)行了比較,分析得出遺忘分?jǐn)?shù)較高的樣本,GraNd 分?jǐn)?shù)也會(huì)較高,這樣看來(lái),二者所選擇的重要樣本其實(shí)也是類似的。
實(shí)驗(yàn)效果
在確定了計(jì)算重要程度的方法之后,作者直接在訓(xùn)練早期,分別計(jì)算遺忘分?jǐn)?shù)、GraNd 及 EL2N ,然后利用計(jì)算的結(jié)果刪減了數(shù)據(jù)集,之后訓(xùn)練模型,測(cè)試結(jié)果如下:
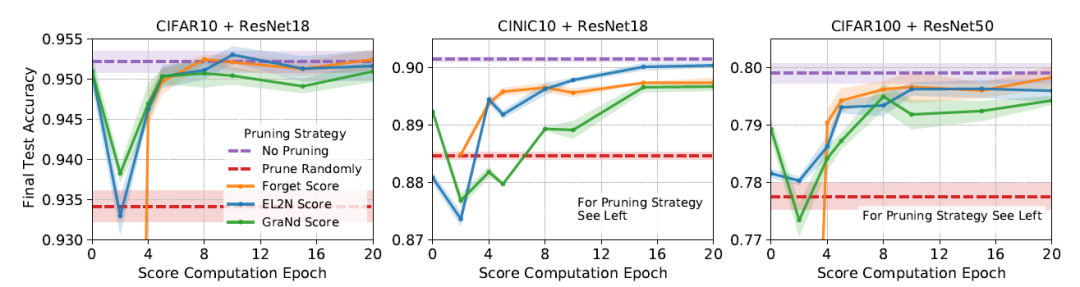
數(shù)據(jù)集和模型如上。其中,CIFAR10 保留了 50% 的數(shù)據(jù),CINIC10 保留了 60% 的數(shù)據(jù),CIFAR100 保留了75%的數(shù)據(jù)。可以看到,基本驗(yàn)證了作者在前文中的猜想:訓(xùn)練到中后期,通過(guò)三種計(jì)算方法裁剪數(shù)據(jù)的表現(xiàn)是各有優(yōu)劣的,而 GraNd 和 EL2N 的確可以在訓(xùn)練早期就得到不錯(cuò)的結(jié)果。而且按上述比例裁剪了數(shù)據(jù)集之后,相比于使用所有的數(shù)據(jù),測(cè)試精度損失的不是很大。
同時(shí),作者也對(duì)比了分別使用 200 個(gè) epoch 得到的遺忘分?jǐn)?shù),以及 20 個(gè) epoch 得到的 GraNd 和 EL2N 計(jì)算樣本重要性,以不同的比例裁剪數(shù)據(jù)后的測(cè)試結(jié)果:
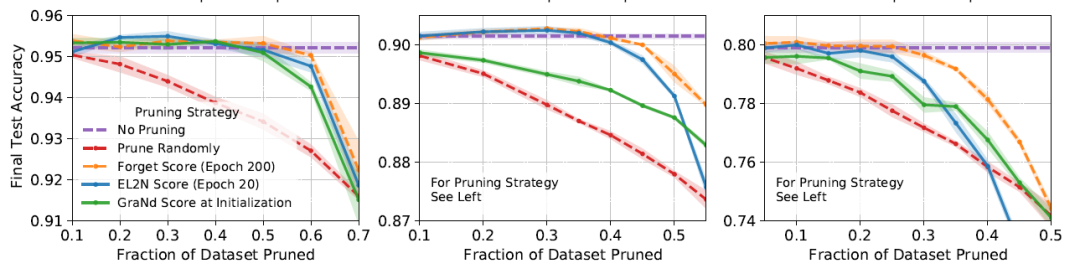
3個(gè)結(jié)果也分別是 CIFAR10 + ResNet18、CINIC10 + ResNet18 和 CIFAR100 + ResNet50。可以看到,首先相比于隨機(jī)裁剪,的確三種裁剪方式都展現(xiàn)了相當(dāng)?shù)哪芰Γ踔猎诓眉魯?shù)據(jù)比較少的時(shí)候,利用GraNd和遺忘分?jǐn)?shù)裁剪后的數(shù)據(jù)訓(xùn)練,測(cè)試精度還超過(guò)了使用整個(gè)數(shù)據(jù)集訓(xùn)練,這里我猜測(cè),在裁剪比例比較少的時(shí)候,被裁剪掉的數(shù)據(jù)主要是離群點(diǎn),所以測(cè)試精度相比于全數(shù)據(jù)訓(xùn)練會(huì)稍高。
至此,作者提出的主要貢獻(xiàn),即在訓(xùn)練早期即可得到不錯(cuò)的樣本重要度評(píng)估,以及利用它裁剪訓(xùn)練數(shù)據(jù)之后,依然能保持不錯(cuò)的測(cè)試精度都得到了驗(yàn)證,而在論文中,作者也展示了使用樣本重要度可以做到其他的什么事情,以及利用一些補(bǔ)充實(shí)驗(yàn)從多種角度分析了兩種計(jì)算重要程度的方法的性能,這里就不再贅述了,感興趣的讀者可以閱讀原文。
所以無(wú)論是計(jì)算遺忘分?jǐn)?shù)的方法,還是本文提出的 GraNd 和 EL2N,實(shí)際在固定任務(wù)場(chǎng)景之下,即固定分布、固定范圍內(nèi)是相當(dāng)有價(jià)值的。
2. 模型總出錯(cuò)怎么辦?反復(fù)教它,直到它會(huì)
當(dāng)我們訓(xùn)練好一個(gè)模型之后,在測(cè)試過(guò)程中,我們會(huì)發(fā)現(xiàn),總是有一些“疑難雜癥”一樣的樣本,怎么樣訓(xùn)練都無(wú)法訓(xùn)練正確,而實(shí)際上,我們也知道,這些樣本可能是訓(xùn)練樣本中比較邊緣的部分(假設(shè)訓(xùn)練集和測(cè)試集符合獨(dú)立同分布假設(shè),即所有測(cè)試樣本均處于訓(xùn)練集的分布之中,如超出了訓(xùn)練集分布,則怎么也解決不了)。訓(xùn)練的過(guò)程則是模型不斷擬合訓(xùn)練樣本分布的過(guò)程,那么這種邊緣的東西,則會(huì)成為模型的疑難雜癥。
雖然機(jī)器學(xué)習(xí)研究中一直假設(shè)訓(xùn)練樣本的分布就是真實(shí)數(shù)據(jù)的分布,可是我們也不得不承認(rèn),抽樣空間和真實(shí)的空間就是存在分布上的偏差,怎么樣都存在,這些“疑難雜癥”的存在正是表明了訓(xùn)練集的分布和真實(shí)數(shù)據(jù)的分布存在的 Gap ,那么自然也就有了一個(gè)研究方向:在已有訓(xùn)練集上,找到擬合的分布最接近于真實(shí)數(shù)據(jù)分布的參數(shù),即分布魯棒性優(yōu)化(Distributionally Robust Optimization, DRO),其基本思路是在訓(xùn)練過(guò)程中按照分布將訓(xùn)練樣本分成若干組,最小化最差的組的 Loss,從而去提升模型的效果。
而本文作者提到,DRO 方法雖然是可行的,但是它要對(duì)訓(xùn)練樣本分組,這個(gè)成本還是略大的,能不能不去對(duì)訓(xùn)練樣本分組,而是找到驗(yàn)證集中那些比較差的樣本,反反復(fù)復(fù)教給模型,從而讓模型的效果更好呢?
問(wèn)題定義
對(duì)于一個(gè)分類問(wèn)題,輸入為 ,類別標(biāo)簽 ,集合中有 n 個(gè)訓(xùn)練樣本 ,目標(biāo)是訓(xùn)練得到模型。
在預(yù)定義好的組 之間評(píng)估模型的性能,每個(gè)訓(xùn)練樣本 都屬于組 ,分類器的最壞組錯(cuò)誤的定義如下:
其中,。
而訓(xùn)練樣本中想得到這樣的組成本還是比較大的,但是在測(cè)試期間,使用少量的 m 個(gè)驗(yàn)證集及在驗(yàn)證集上預(yù)定義的若干個(gè)組,得到較好的最差 case 集合,用于調(diào)整超參,優(yōu)化模型。
而驗(yàn)證集的分組則是使用樣本中本身存在的一些屬性 與類別標(biāo)簽的關(guān)聯(lián)來(lái)劃分的,即 ,如下圖中例子,分類水生鳥類和陸生鳥類,觀察數(shù)據(jù)發(fā)現(xiàn),圖片的背景和標(biāo)簽存在相關(guān)關(guān)系,則分為4類:

JTT:訓(xùn)練兩次就好了
本文給出的方法則是兩階段的方法:首先,我們都知道,統(tǒng)計(jì)模型更傾向于去學(xué)習(xí)簡(jiǎn)單的關(guān)聯(lián)(例如在水上的水生鳥類,在陸地上的陸生鳥類),而復(fù)雜的關(guān)聯(lián)(例如在水上的陸生鳥類,在陸地上的水生鳥類)學(xué)習(xí)的就比較差了,那么第一階段,直接使用訓(xùn)練集訓(xùn)練一個(gè)識(shí)別模型,直接找到當(dāng)前模型的“易錯(cuò)題集合”,即:
之后,則是增大“易錯(cuò)題集合”中樣本的 Loss 權(quán)重,加強(qiáng)記憶,繼續(xù)訓(xùn)練模型:
其中,是一個(gè)超參數(shù)。方法非常直觀,就是將易錯(cuò)組加強(qiáng)記憶一遍,最終得到一個(gè)不錯(cuò)的模型。
那么我們看一下最終的訓(xùn)練結(jié)果,作者在圖像兩個(gè)圖像分類任務(wù)和兩個(gè) NLP 任務(wù)上分別嘗試了效果,可以看到,在對(duì)比中情況較差的組的效果的確改善很多:
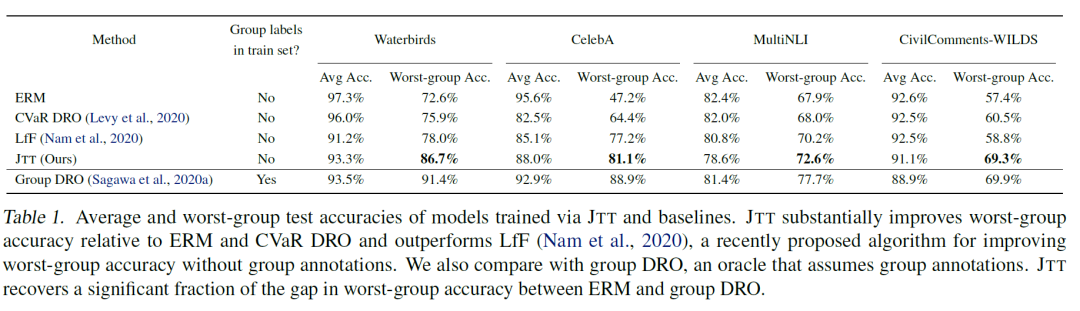
相比于要對(duì)整個(gè)訓(xùn)練集分組的 DRO 方法,這個(gè)方法的確成本上小了很多,且相比于其他類似的方法(論文中有簡(jiǎn)單介紹它所對(duì)比的幾種方法),它的提升也相對(duì)比較高,可以說(shuō)是比較符合直覺(jué),且效果比較好的方法。這個(gè)方法與分組時(shí)所定義的屬性(即)非常相關(guān),例如在水生鳥類和陸生鳥類分類中,使用了圖片的背景,在照片男女性別分類中,使用了頭發(fā)顏色;在 NLI 任務(wù)中,使用了文本中是否含有否定詞語(yǔ);在侮辱性評(píng)論分類任務(wù)中,使用了文本中是否含有性別描述詞。

可以看出,雖然不需要使用模型去計(jì)算分組了,但也需要人為地根據(jù)數(shù)據(jù)分布來(lái)對(duì)原本數(shù)據(jù)進(jìn)行歸組,而如果歸組出現(xiàn)問(wèn)題,則我想對(duì)最終的效果影響也不會(huì)小。而且,模型去過(guò)度關(guān)注預(yù)測(cè)錯(cuò)誤的樣本,實(shí)際上對(duì)已經(jīng)學(xué)到的正確的樣本似乎也會(huì)造成一定的損失,上文中可以看到,相比于一般方法,4 種改善錯(cuò)誤的方法在整體的精度上都有了一定的損失,而想得到均衡的效果,在劃分集合上和超參選擇上都有很多的講究。
而且,會(huì)不會(huì)所謂最差的集合中,實(shí)際上是存在部分錯(cuò)誤,或者離群點(diǎn)的呢?過(guò)度去擬合它,是否造成了過(guò)擬合,或者引入了噪聲呢?我們不得而知。
當(dāng)然,文章中仍然有大量的對(duì)比分析及消融實(shí)驗(yàn),本文也不再贅述。
這篇工作實(shí)際上是部分利用了人的先驗(yàn)知識(shí),用更偏向直覺(jué)的方法,使用更簡(jiǎn)單的算法去解決分布魯棒性優(yōu)化(DRO)問(wèn)題,其所關(guān)注也是模型的泛化能力。其基本動(dòng)因就是,模型在某些樣本上的效果非常差,則說(shuō)明現(xiàn)在所擬合的分布是有偏的,那么就讓模型的分布偏移,去包含那些相對(duì)“離群”的樣本,但由于盤子也只有那么大,偏向了離群的樣本,則也會(huì)舍去另一個(gè)邊緣的樣本。從最終結(jié)果上來(lái)看,雖然人為劃分的最差集合上效果變好了,但整體上變差了,實(shí)際上個(gè)人認(rèn)為也沒(méi)有達(dá)到 DRO 想要達(dá)到的理想狀態(tài)(實(shí)際上我們可以看到,發(fā)表于 ICLR2020 的 Group DRO的整體效果看上去也好得多)。
固定任務(wù)之下,似乎我們也只能使用這種權(quán)衡的方式來(lái)糾偏,而如果我們面向的是海量數(shù)據(jù),則我們也會(huì)有更多的選擇;