
ICLR2021自蒸餾方法SEED:顯著提升小模型性能
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!

注:公眾號(hào)后臺(tái)回復(fù):SEED。即可獲取本文下載鏈接。
該文是亞利桑那州立大學(xué)&微軟聯(lián)合提出的一種自監(jiān)督蒸餾表達(dá)學(xué)習(xí)方案,已被ICLR2021接收為Poster。針對(duì)現(xiàn)有對(duì)比自監(jiān)督學(xué)習(xí)方案在小模型上表現(xiàn)性能差的問(wèn)題,提出將知識(shí)蒸餾的思想嵌入到自監(jiān)督學(xué)習(xí)框架得到了本文的自監(jiān)督蒸餾學(xué)習(xí)。相比常規(guī)自監(jiān)督學(xué)習(xí)方案,所提方案可以顯著的提升輕量型模型的性能,同時(shí)具有極好的泛化性能。
Abstract
本文主要聚焦于小模型(即輕量型模型)的自監(jiān)督學(xué)習(xí)問(wèn)題,作者通過(guò)實(shí)證發(fā)現(xiàn):對(duì)比自監(jiān)督學(xué)習(xí)方法在大模型訓(xùn)練方面表現(xiàn)出了很大進(jìn)展,然這些方法在小模型上的表現(xiàn)并不好。
為解決上述問(wèn)題,本文提出了一種新的學(xué)習(xí)框架:自監(jiān)督蒸餾(SElf-SupErvised Distillation, SEED),它通過(guò)自監(jiān)督方式(SSL)將老師模型的知識(shí)表達(dá)能力遷移給學(xué)生模型。不同于直接在無(wú)監(jiān)督數(shù)據(jù)上的直接學(xué)習(xí),我們訓(xùn)練學(xué)生模型去模擬老師模型在一組示例上的相似度得分分布。
所提SEED的簡(jiǎn)潔性與靈活性不言而喻,包含這樣三點(diǎn):(1) 無(wú)需任何聚類(lèi)/元計(jì)算步驟生成偽標(biāo)簽/隱類(lèi);(2) 老師模型可以通過(guò)優(yōu)秀的自監(jiān)督學(xué)習(xí)(比如MoCo-V2、SimCLR、SWAV等)方法進(jìn)行預(yù)訓(xùn)練;(3)老師模型的知識(shí)表達(dá)能力可以蒸餾到任意小模型中(比如更淺、更細(xì),甚至可以是完全不同的架構(gòu))。
實(shí)驗(yàn)表明:SEED可以提升小模型在下游任務(wù)上的性能表現(xiàn)。相比自監(jiān)督基準(zhǔn)MoCo-V2方案,在ImageNet數(shù)據(jù)集上,SEED可以將EfficientNet-B0的精度從42.2%提升到67.6%,將MobileNetV3-Large的精度從36.3%提升到68.2%,見(jiàn)下圖對(duì)比。
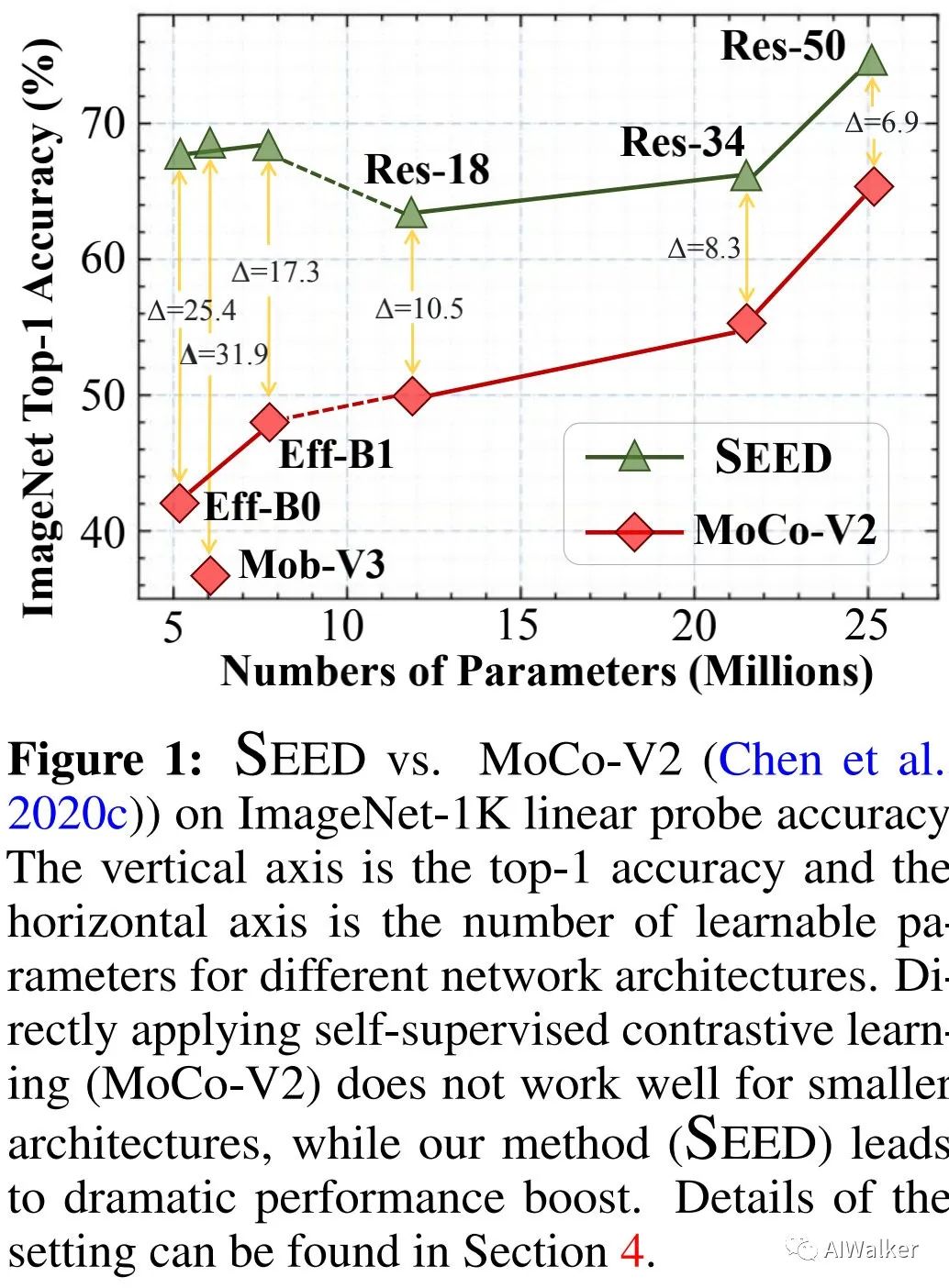
本文的主要貢獻(xiàn)包含以下幾點(diǎn):
首次解決了小模型的自監(jiān)督視覺(jué)表達(dá)學(xué)習(xí)問(wèn)題; 提出一種自監(jiān)督蒸餾技術(shù)用于將大模型的知識(shí)遷移到小模型且無(wú)需任何帶標(biāo)簽數(shù)據(jù); 基于所提SEED方案,我們可以顯著的提升現(xiàn)有SSL技術(shù)在小模型上的性能表現(xiàn); 系統(tǒng)性的比較了不同蒸餾策略,驗(yàn)證了SEED在多種配置的有效性。
Method
Knowledge Distillation
知識(shí)蒸餾最早是Hinton等人于2015年提出用于模型壓縮的技術(shù),它旨在將更大的老師模型的知識(shí)表達(dá)能力遷移給更小的學(xué)生模型。該任務(wù)可以表示成如下形式:
其中,分別表示輸入圖像及對(duì)應(yīng)的標(biāo)簽,分別表示學(xué)生模型與老師模型的參數(shù)。表示監(jiān)督損失,調(diào)控網(wǎng)絡(luò)預(yù)測(cè)與標(biāo)簽之間的差異性,對(duì)于圖像分類(lèi)而言,它往往為交叉熵?fù)p失;表示蒸餾損失,用于調(diào)控學(xué)生模型預(yù)測(cè)與老師模型預(yù)測(cè)之間的差異性,它往往為KL-散度損失。知識(shí)蒸餾的有效性已在多個(gè)任務(wù)、多個(gè)數(shù)據(jù)集上得到了驗(yàn)證;但是在無(wú)監(jiān)督任務(wù)上仍是未知的,而這是本文的聚焦所在。
Self-Supervised Distillation
不同于有監(jiān)督蒸餾,SEED希望在無(wú)標(biāo)簽數(shù)據(jù)上將大模型的知識(shí)表達(dá)能力遷移給小模型,以促使小模型所學(xué)習(xí)到的表達(dá)能力更好的作用于下游任務(wù)。受啟發(fā)于對(duì)比自監(jiān)督學(xué)習(xí),我們?cè)O(shè)計(jì)了一種簡(jiǎn)單的方案:在實(shí)例相似性分布的基礎(chǔ)上進(jìn)行知識(shí)蒸餾。類(lèi)似MoCo,我們維持一個(gè)實(shí)例隊(duì)列以保存老師模型的編碼輸出,對(duì)于新樣本,我們計(jì)算它與隊(duì)列中所有樣本的相似性得分。我們希望:學(xué)生模型與老師模型的相似性得分分布盡可能相似,這就構(gòu)成了老師模型與老師模型的相似性得分分布的交叉熵,見(jiàn)下圖。
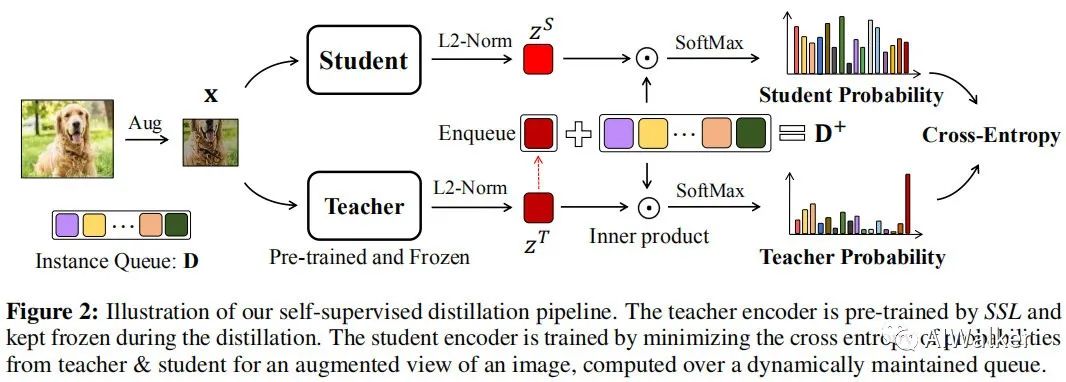
具體來(lái)講,對(duì)于輸入及其隨機(jī)增廣,首先進(jìn)行編碼&特征規(guī)范化的得到特征向量表達(dá):
其中,分別表示老師模型與學(xué)生模型。假設(shè)表示實(shí)例隊(duì)列,K表示隊(duì)列長(zhǎng)度,表示老師模型得到的特征向量。類(lèi)似于對(duì)比學(xué)習(xí)方案,D采用"先進(jìn)先出"的策略逐步更新并作為蒸餾所得,也就是說(shuō):隊(duì)列中的樣本大多是隨機(jī)的、與當(dāng)前實(shí)例不相關(guān)。最小化老師模型與學(xué)生模型在D與之間的交叉熵,而不會(huì)直接與老師模型進(jìn)行直接對(duì)齊。為緩解不對(duì)齊問(wèn)題,作者添加了老師模型的嵌入特征到上述隊(duì)列構(gòu)成了新的隊(duì)列。
假設(shè)表示老師模型提取特征與之間的相似性得分,其定義如下:
注:分別表示老師模型提取的特征、兩個(gè)特征的內(nèi)積。類(lèi)似地,我們定義。
本文所提SEED可以表示為:在所有實(shí)例上,最小化老師模型相似性得分與學(xué)生模型相似性得分之間的交叉熵。
老師模型是預(yù)訓(xùn)練好的,并且在蒸餾階段進(jìn)行參數(shù)凍結(jié),序列中的特征在訓(xùn)練階段具有一致性,更高的意味著上更大的權(quán)值。由于歸一化的存在,與之間的相似性得分在softmax歸一化前為常數(shù)1,這也是所有中的最大值。因此,的權(quán)值最大且可以通過(guò)調(diào)節(jié)進(jìn)行單獨(dú)調(diào)節(jié)。通過(guò)最小化上述損失,將與對(duì)齊同時(shí)與其他不相關(guān)特征形成反差。
當(dāng)時(shí),的softmax平滑接近與one-hot向量,其中,其他向量為0。在這種極限情況下,損失就退化為:
這種退化后的損失與廣泛采用的Info-NCE損失相似。
Experiments
Pre-Training
Self-Supervised Pre-training of Teacher Network 我們默認(rèn)采用MoCo-V2進(jìn)行老師模型的預(yù)訓(xùn)練,采用不同深度/寬度的ResNet作為骨干網(wǎng)絡(luò)并添加MLP頭,最后特征維度為128。考慮到有限算力問(wèn)題,所有的老師模型預(yù)訓(xùn)練200epoch。由于所提方案與老師模型的預(yù)訓(xùn)練方案無(wú)關(guān),作者同時(shí)還給出了其他自監(jiān)督方案(比如SWAV、SimCLR)的老師模型的結(jié)果對(duì)比。
Self-Supervised Distillation on Student Network ?我們選擇了多個(gè)小模型作為學(xué)生模型:MobileNetV3-Large、EfficientNet-B0、ResNet18、ResNet34等。類(lèi)似于老師模型,在學(xué)生模型的后端添加了MLP頭。蒸餾過(guò)程采用標(biāo)準(zhǔn)SGD進(jìn)行訓(xùn)練,momentum=0.9,weight_decay=1e-4,訓(xùn)練了200epoch,初始學(xué)習(xí)率為0.03,cosine衰減,batch=256,,隊(duì)列長(zhǎng)度K=65536。
Fine-tuning and Evaluation
為驗(yàn)證自監(jiān)督蒸餾的有效性,我們選擇在幾個(gè)下游任務(wù)上驗(yàn)證學(xué)生模型的表達(dá)能力。首先,我們先來(lái)看一下ImageNet上的性能,結(jié)果見(jiàn)下表。
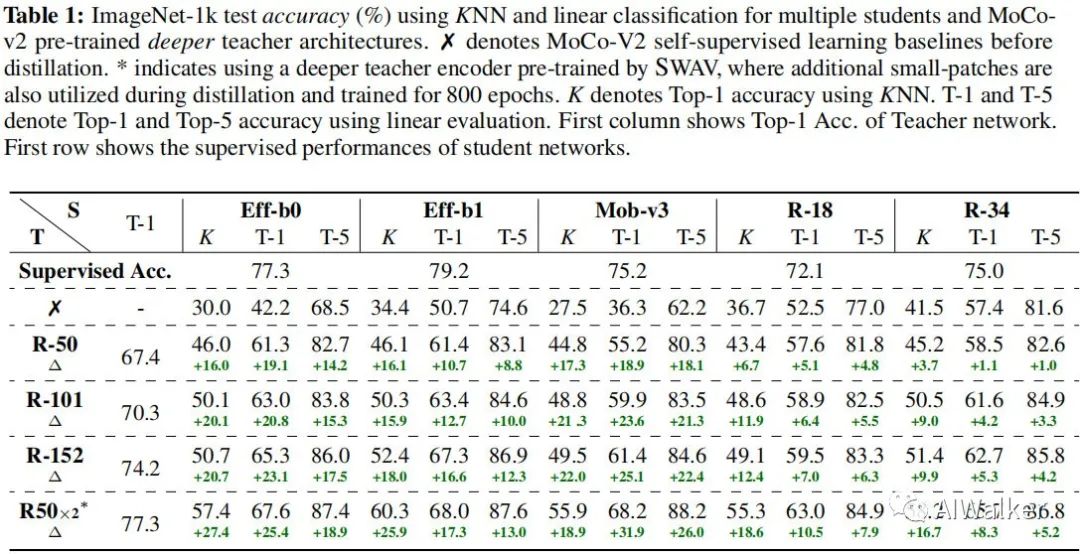
從上表結(jié)果我們可以看到:
當(dāng)僅僅采用對(duì)比自監(jiān)督學(xué)習(xí)(MoCo-V2)時(shí),越小的模型性能越差。比如MobileNetV3-Large的top1精度僅為36.3%,這與MoCoV2中的結(jié)論(越大的模型從對(duì)比自監(jiān)督學(xué)習(xí)中受益越多)相一致。 大模型的蒸餾有助于提升小模型的性能且提升非常明顯。比如以MoCoV2預(yù)訓(xùn)練的ResNet152作為老師模型,MobileNetV3-Large的top1精度可以提升到61.4%;當(dāng)采用ResNet-50x2作為老師模型時(shí),其精度還可以進(jìn)一步提升達(dá)到68.2%。 越小的模型從蒸餾得到的受益越多。
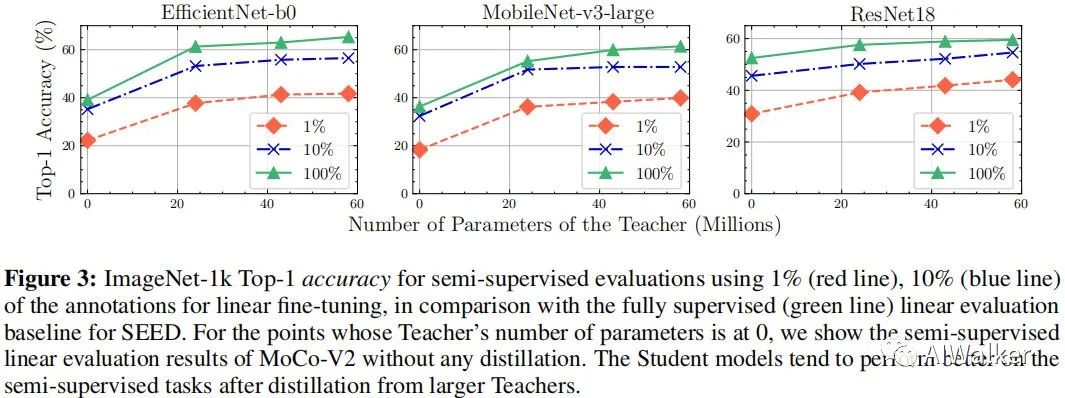
上圖給出了半監(jiān)督訓(xùn)練下的性能對(duì)比。可以看到:SEED同樣有助于提升小模型的性能,而且越強(qiáng)的老師模型會(huì)導(dǎo)致越好的學(xué)生模型。
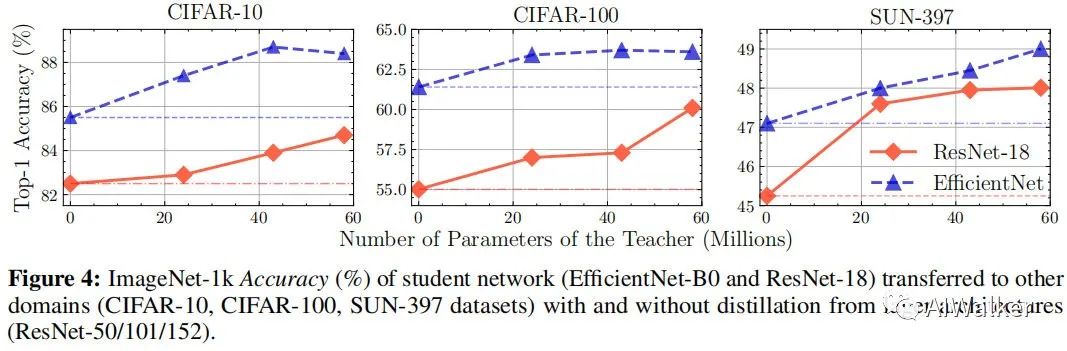
上圖給出了所提方案下學(xué)生模型在分類(lèi)任務(wù)上的遷移能力對(duì)比。可以看到:在所有基準(zhǔn)數(shù)據(jù)集上,所提方案均超越了對(duì)比自監(jiān)督預(yù)訓(xùn)練方案,驗(yàn)證了SEED的有效證;這同時(shí)也證實(shí)了通過(guò)蒸餾學(xué)習(xí)到的表達(dá)能力的泛化能力。
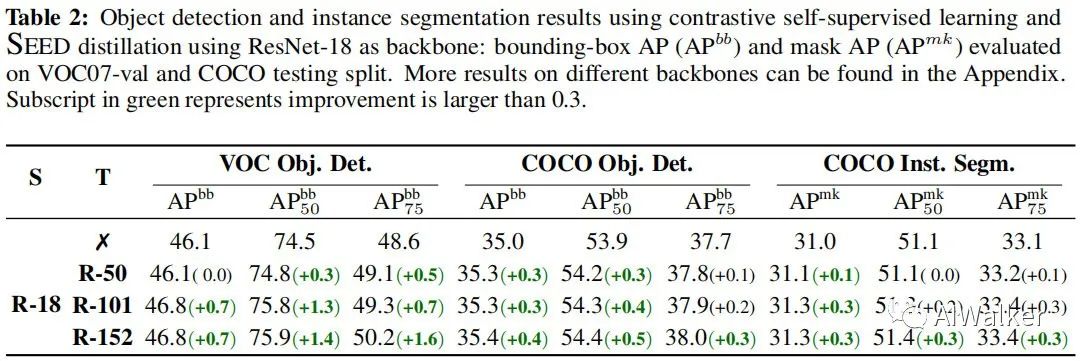
上表給出了所提方案下學(xué)生模型在檢測(cè)&分割任務(wù)上的遷移能力對(duì)比。可以看到:
在VOC數(shù)據(jù)集上,蒸餾得到的預(yù)訓(xùn)練模型取得更大的性能提升; 在COCO數(shù)據(jù)集上,提升相對(duì)較小。原因可能是:COCO訓(xùn)練集包含118k數(shù)據(jù),而VOC僅有16.5K數(shù)據(jù)。更大的訓(xùn)練集+更多的微調(diào)迭代會(huì)降低初始權(quán)重的重要性。
Ablation Study
接下來(lái),我們?cè)賹?duì)所提方案進(jìn)行一些消融實(shí)驗(yàn)分析,包含老師模型大小的影響、對(duì)比自監(jiān)督學(xué)習(xí)方法的影響、不同蒸餾技術(shù)的硬性等等。
首先,我們先看一下老師模型的影響,見(jiàn)下圖中Figure5。從中可以看到:隨著老師模型的深度/寬度提升,學(xué)生模型的性能可以進(jìn)一步提升。
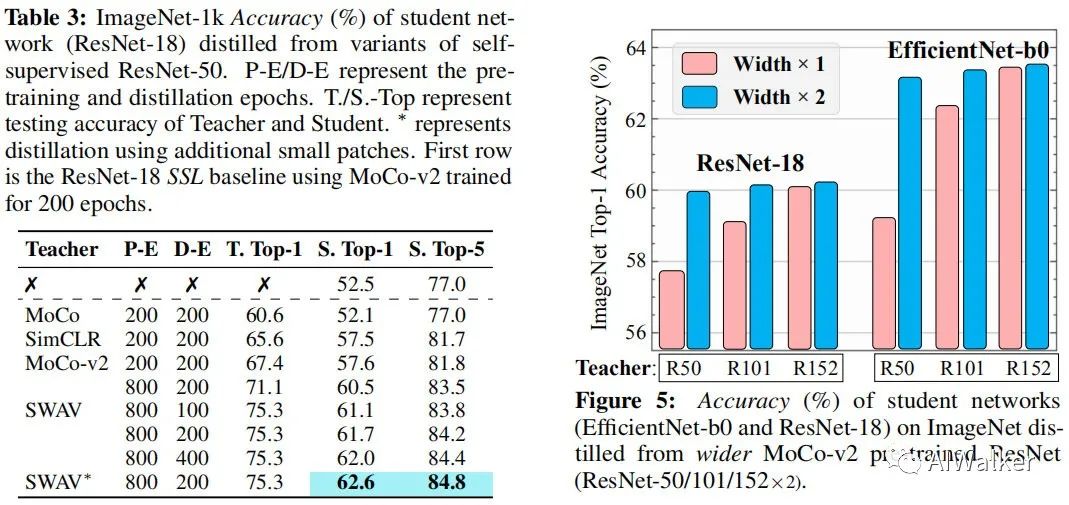
然后,我們?cè)倏匆幌虏煌瑢?duì)比自監(jiān)督學(xué)習(xí)方法的影響,見(jiàn)上圖Table3.從中可以看到:SEED可以輕易將任意自監(jiān)督模型納入到自監(jiān)督蒸餾體系中并得到不同程度的性能提升,此外還可以看到:更多的訓(xùn)練可以得到進(jìn)一步的性能增益。
其次,我們看一下不同蒸餾策略對(duì)于所提方案的影響,見(jiàn)下圖Table4。從中可以看到:(1) 簡(jiǎn)簡(jiǎn)單單的距離最小即可取得相當(dāng)好的精度,這證實(shí)了將蒸餾納入自監(jiān)督學(xué)習(xí)的有效性;(2) MoCo-V2的監(jiān)督作為輔助損失不會(huì)產(chǎn)生額外的增益,這也就意味著:SEED的損失可以很大程度上覆蓋了原始SSL損失,沒(méi)有必要在蒸餾階段引入SSL損失;(3)相比其他蒸餾策略,所提SEED取得了最高精度,這也表明學(xué)生模型向老師模型對(duì)齊+不相關(guān)樣本上差異化原則的優(yōu)越性。
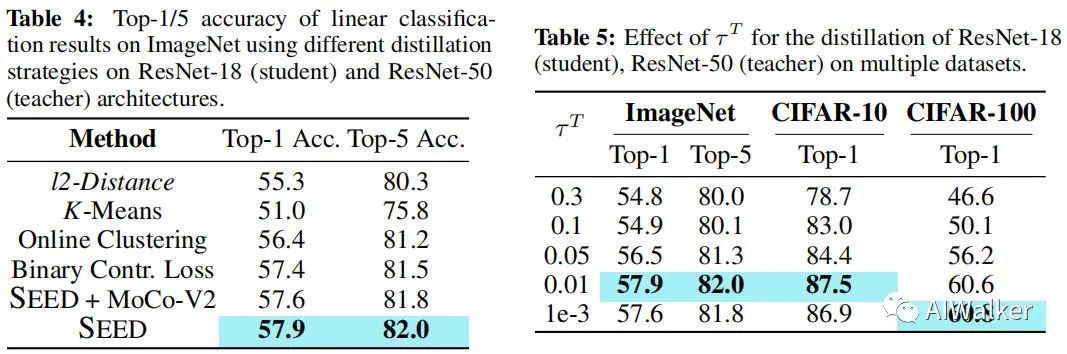
最后,我們?cè)賮?lái)看一下不同超參對(duì)于所提方案的影響,見(jiàn)上圖Table5。可以看到:當(dāng)時(shí),所提方案在ImageNet、CIFAR10上取得了更高的性能;而對(duì)于CIFAR100而言,最佳的超參為。當(dāng)比較大時(shí),與隊(duì)列中的實(shí)例的相似性得分也會(huì)變大,這就意味著:在某種程度上,相比其他圖像的特征,學(xué)生模型提取的圖像特征判別能力降低了;當(dāng)為0時(shí),老師模型將生成one-hot向量,僅將視作正例,隊(duì)列中的其他實(shí)例均為負(fù)例。因此,最好的參數(shù)設(shè)置依賴于數(shù)據(jù)分布。
全文到此結(jié)束,對(duì)該文感性的同學(xué)建議去查看原文,原文附錄部分尚未更多實(shí)驗(yàn)分析。這篇論文實(shí)用價(jià)值還是比較高的,尤其對(duì)于研究工業(yè)檢測(cè)相關(guān)應(yīng)用的同學(xué)而言,該文所提方案更是值得深入研究一番

推薦閱讀
谷歌提出Meta Pseudo Labels,刷新ImageNet上的SOTA!
漲點(diǎn)神器FixRes:兩次超越ImageNet數(shù)據(jù)集上的SOTA
SWA:讓你的目標(biāo)檢測(cè)模型無(wú)痛漲點(diǎn)1% AP
CondInst:性能和速度均超越Mask RCNN的實(shí)例分割模型
centerX: 用新的視角的方式打開(kāi)CenterNet
mmdetection最小復(fù)刻版(十一):概率Anchor分配機(jī)制PAA深入分析
MMDetection新版本V2.7發(fā)布,支持DETR,還有YOLOV4在路上!
無(wú)需tricks,知識(shí)蒸餾提升ResNet50在ImageNet上準(zhǔn)確度至80%+
不妨試試MoCo,來(lái)替換ImageNet上pretrain模型!
mmdetection最小復(fù)刻版(七):anchor-base和anchor-free差異分析
mmdetection最小復(fù)刻版(四):獨(dú)家yolo轉(zhuǎn)化內(nèi)幕
機(jī)器學(xué)習(xí)算法工程師
? ??? ? ? ? ? ? ? ? ? ? ? ??????? ??一個(gè)用心的公眾號(hào)
?
