
Hive進(jìn)階—抽樣的各種玩法
抽樣
抽樣在Hive 中也是比較常用的一種手段,主要用在下面的幾個場景中
一些機(jī)器學(xué)習(xí)的場景中,數(shù)倉作為數(shù)據(jù)的提供方提供樣本數(shù)據(jù)
數(shù)據(jù)的計(jì)算結(jié)果異常或者是指標(biāo)異常,這個時候如果我們往往需要確認(rèn)數(shù)據(jù)源的數(shù)據(jù)是否本身就有異常
SQL的性能有問題的時候我們也會使用抽樣的方法區(qū)查看數(shù)據(jù),然后進(jìn)行SQL調(diào)優(yōu)
在大規(guī)模數(shù)據(jù)量的數(shù)據(jù)分析及建模任務(wù)中,往往針對全量數(shù)據(jù)進(jìn)行挖掘分析時會十分耗時和占用集群資源,因此一般情況下只需要抽取一小部分?jǐn)?shù)據(jù)進(jìn)行分析及建模操作。
隨機(jī)抽樣(rand()函數(shù))
我們一般情況下是使用排序函數(shù)和rand() 函數(shù)來完成隨機(jī)抽樣,limit關(guān)鍵字限制抽樣返回的數(shù)據(jù),不同之處再有我們使用哪個排序函數(shù)呢
利用 rand() 函數(shù)進(jìn)行抽取,這是因?yàn)?code style="color: inherit;line-height: inherit;word-break: break-all;padding: 2px 4px;border-radius: 4px;margin-right: 2px;margin-left: 2px;background: rgb(248, 248, 248);font-size: 14px;">rand() 返回一個0到1之間double 類型的隨機(jī)值。
下面我們用到了前面我們使用過的一張表大概4603089 條記錄,這里我就不給大家準(zhǔn)備數(shù)據(jù)了,大家可以看Hive進(jìn)階之?dāng)?shù)據(jù)存儲格式來獲取測試數(shù)據(jù)
create?table?ods_user_bucket_log(
?????id?int,
?????name?string,
?????city?string,
?????phone?string,
?????acctime?string)
CLUSTERED?BY?(`id`?)?INTO?5?BUCKETS?
row?format?delimited?fields?terminated?by?'\t'
stored?as?textfile;
insert?overwrite?table?ods_user_bucket_log?select?*?from?ods_user_log;
order by rand()
order by只會啟用一個reduce所以比較耗時,至于為什么我們在前面的文章中解釋過了Hive語法之常見排序方式
因?yàn)閛rder by 是全局的,所以可以做到隨機(jī)抽樣的目的
select * from ods_user_bucket_log order by rand() limit 10;
sort by rand()
sort by 提供了單個 reducer 內(nèi)的排序功能,但不保證整體有序,這個時候其實(shí)不能做到真正的隨機(jī)的,因?yàn)榇藭r的隨機(jī)是針對分區(qū)去的,所以如果我們可以通過控制進(jìn)入每個分區(qū)的數(shù)據(jù)也是隨機(jī)的話,那我們就可以做到隨機(jī)了
select * from ods_user_bucket_log sort by rand() limit 10;
distribute by rand() sort by rand()
rand函數(shù)前的distribute和sort關(guān)鍵字可以保證數(shù)據(jù)在mapper和reducer階段是隨機(jī)分布的,這個時候我們也能做到真正的隨機(jī),前面我們也介紹過cluster by 其實(shí)基本上是和distribute by sort by 等價的
select * from ods_user_bucket_log distribute by rand() sort by rand() limit 10;
cluster by rand()
cluster by 的功能是 distribute by 和 sort by 的功能相結(jié)合,distribute by rand() sort by rand() 進(jìn)行了兩次隨機(jī),cluster by rand() 僅一次隨機(jī),所以速度上會比上一種方法快
select * from ods_user_bucket_log cluster by rand() limit 10;
tablesample()抽樣函數(shù)
分桶抽樣(桶表抽樣)
hive中分桶其實(shí)就是根據(jù)某一個字段Hash取模,放入指定數(shù)據(jù)的桶中,比如將表table按照ID分成100個桶,其算法是hash(id) % 100,這樣,hash(id) % 100 = 0的數(shù)據(jù)被放到第一個桶中,hash(id) % 100 = 1的記錄被放到第二個桶中。
分桶抽樣語法:
TABLESAMPLE (BUCKET x OUT OF y [ON colname])
其中x是要抽樣的桶編號,桶編號從1開始,colname表示抽樣的列(也就是按照那個字段分桶),y表示桶的數(shù)量。所以表達(dá)的意思是按照colname字段分成y桶,抽取其中的第x桶
SELECT
????*
FROM
????ods_user_bucket_log
TABLESAMPLE?(BUCKET?1?OUT?OF?100000?ON?rand())?;

數(shù)據(jù)塊抽樣
從 Hive 0.8 開始提供塊抽樣,使用 tablesample 抽取指定的 行數(shù)/比例/大小
SELECT?*?FROM?ods_user_data?TABLESAMPLE(1000?ROWS);
SELECT?*?FROM?ods_user_data?TABLESAMPLE?(20?PERCENT);?
SELECT?*?FROM?ods_user_data?TABLESAMPLE(1M);?
按比例抽樣 ABLESAMPLE (20 PERCENT)
這將允許 Hive 至少獲取 n%的數(shù)據(jù)
SELECT
????*
FROM
????ods_user_bucket_log
TABLESAMPLE(0.0001?PERCENT);

抽取特定大小的數(shù)據(jù)TABLESAMPLE(100M)
SELECT
????*
FROM
????ods_user_bucket_log
TABLESAMPLE(1M);

需要注意的是這里必須是整數(shù)M ,以為我嘗試零點(diǎn)幾的時候報(bào)錯了

抽取特定的行數(shù) TABLESAMPLE(10 ROWS)
SELECT
????*
FROM
????ods_user_bucket_log
TABLESAMPLE(10?rows);

擴(kuò)展
隨機(jī)抽樣如何實(shí)現(xiàn)按比例抽樣
前面我們介紹了TABLESAMPLE 可以實(shí)現(xiàn)按比例抽樣,隨機(jī)抽樣可以借助limit 可以實(shí)現(xiàn)抽取特定記錄數(shù),其實(shí)我們?nèi)绻麑﹄S機(jī)抽樣進(jìn)行改進(jìn)也可以實(shí)現(xiàn)按照比例抽樣,因?yàn)閞and() 的函數(shù)值是隨機(jī)的,所以我們可以對其返回值做條件過濾從而實(shí)現(xiàn)按照比例的抽樣
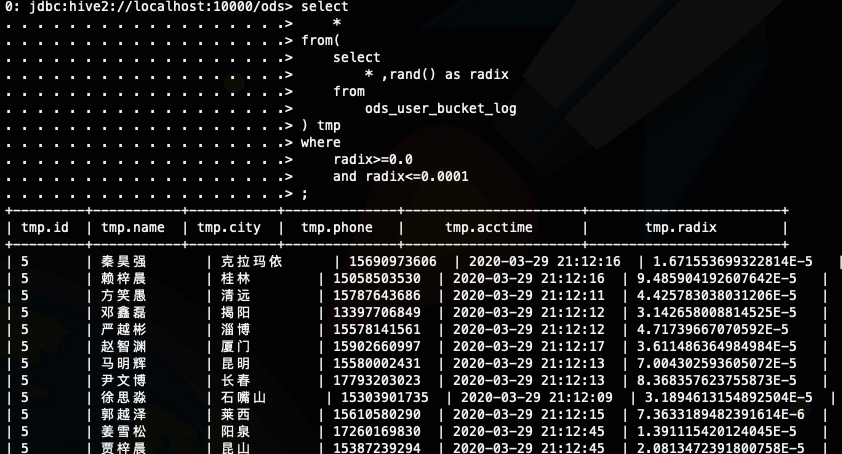
select
????*
from(
????select
????????*?,rand()?as?radix
????from
????????ods_user_bucket_log
)?tmp
where
????radix>=0.0
????and?radix<=0.0001
;
分層抽樣(分組抽樣)
分層抽樣,這里可以分為兩種,一種是分層抽個數(shù)另外一種是分層抽比例
分層抽個數(shù)
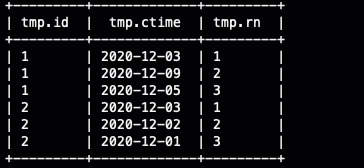
select
????*
from?(
????select
????????id,ctime,
????????row_number()?over(partition?by?id?order?by?rand()?)?as?rn
????from
????????ods_user_log
)?tmp
where?rn<=3
;
分層按比例的抽樣,也可以按照上面的方式實(shí)現(xiàn)
總結(jié)
TABLESAMPLE 抽樣函數(shù)本身是不走M(jìn)R 的所以執(zhí)行速度很快(注意抽取多少M(fèi)的時候,只能是整數(shù)M)
隨機(jī)抽樣函數(shù)需要走M(jìn)R的,所以執(zhí)行性能上沒有TABLESAMPLE那么快,而且表達(dá)能力有限,只能獲取特定的條數(shù)(limit n)
借助row_number實(shí)現(xiàn)分層抽樣