
南京大學(xué)開源!ResT:高效Transformer架構(gòu)!
↑↑↑點擊上方藍(lán)字,回復(fù)資料,10個G的驚喜

paper: https://arxiv.org/abs/2105.13677
code: https://github.com/wofmanaf/ResT
本文是南京大學(xué)提出的一種高效Transformer架構(gòu):ResT,它采用了類似ResNet的設(shè)計思想:stem提取底層特征信息、stages捕獲多尺度特征信息。與此同時,為解決MSA存在的計算量與內(nèi)存占用問題,提出了EMSA模塊進(jìn)一步降低計算量與內(nèi)存消耗。所提ResT在圖像分類、目標(biāo)檢測以及實例分割等任務(wù)均取得了顯著的性能提升,比如在ImageNet數(shù)據(jù)上,在同等計算量前提下,所提方法取得了優(yōu)于PVT、Swin的優(yōu)異性能,實乃一種強(qiáng)力骨干網(wǎng)絡(luò)。
Abstract
本文提出一種高效多尺度Vision Transformer:ResT,它可作為圖像中識別的通用骨干架構(gòu)。不同于現(xiàn)有采用固定分辨率+標(biāo)準(zhǔn)Transformer模塊的Transformer模型,它有這樣幾個優(yōu)勢:
(1) 提出了一種內(nèi)容高效的多頭自注意力模塊,它采用簡單的深度卷積進(jìn)行內(nèi)存壓縮,并跨注意力頭維度進(jìn)行投影交互,同時保持多頭的靈活性; (2) 將位置編碼構(gòu)建為空域注意力,它可以更靈活的處理任意分辨率輸入,且無需插值或者微調(diào); (3) 并未在每個階段的開始部分進(jìn)行序列化,我們把塊嵌入設(shè)計成重疊卷積堆疊方式。
我們在圖像分類與下游任務(wù)上對所提ResT進(jìn)行了性能驗證,實驗結(jié)果表明:所提ResT大幅優(yōu)于現(xiàn)有骨干架構(gòu),比如,ResNet18(69.7%)、PVT-Tiny(75.1%)相似大小的模型下,所提方法取得了79.5%的top1精度,這說明它是一種強(qiáng)有力的骨干網(wǎng)絡(luò)。
Method
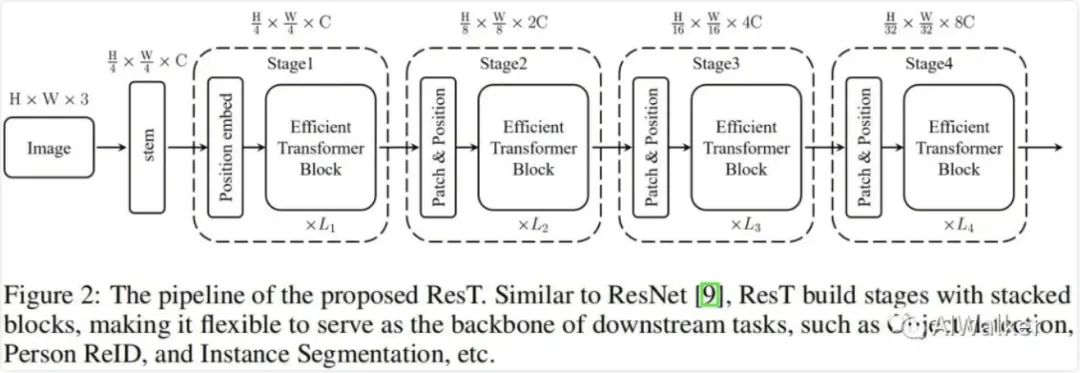
上圖給出了ResT的架構(gòu)示意圖,它具有與ResNet相似的結(jié)構(gòu)方案,比如采用stem模塊提取底層特征,后接四個stage捕獲多尺度特征。每個stage包含三個成分:一個塊嵌入模塊,一個位置編碼模塊以及L個高效Transformer模塊。具體來說,在每個stge開始前,塊嵌入模塊用于降低輸入的分辨率并擴(kuò)展通道維度;位置編碼用于約束位置信息提升塊嵌入的特征提取能力;然后將所得送入到后續(xù)高效Transformer模塊中。
Rethinking of Transformer Block
標(biāo)準(zhǔn)的Transformer模塊由MSA與FFN以及殘差鏈接構(gòu)成,在MSA與FFN之前還采用LN。對于輸入token,每個Transformer模塊的輸出表示如下:
其中,MSA的單頭SA與FFN的定義分別如下:
MSA與FFN的計算復(fù)雜度分別為, 。
Efficient Transformer Block
如前所述,MSA有兩個缺點:(1) 計算量隨平方增長,這會導(dǎo)致較大的訓(xùn)練與推理負(fù)載;(2) MSA的每個頭僅負(fù)責(zé)輸入的部分子集,這會影響模型的性能,尤其當(dāng)通道維度非常小時。
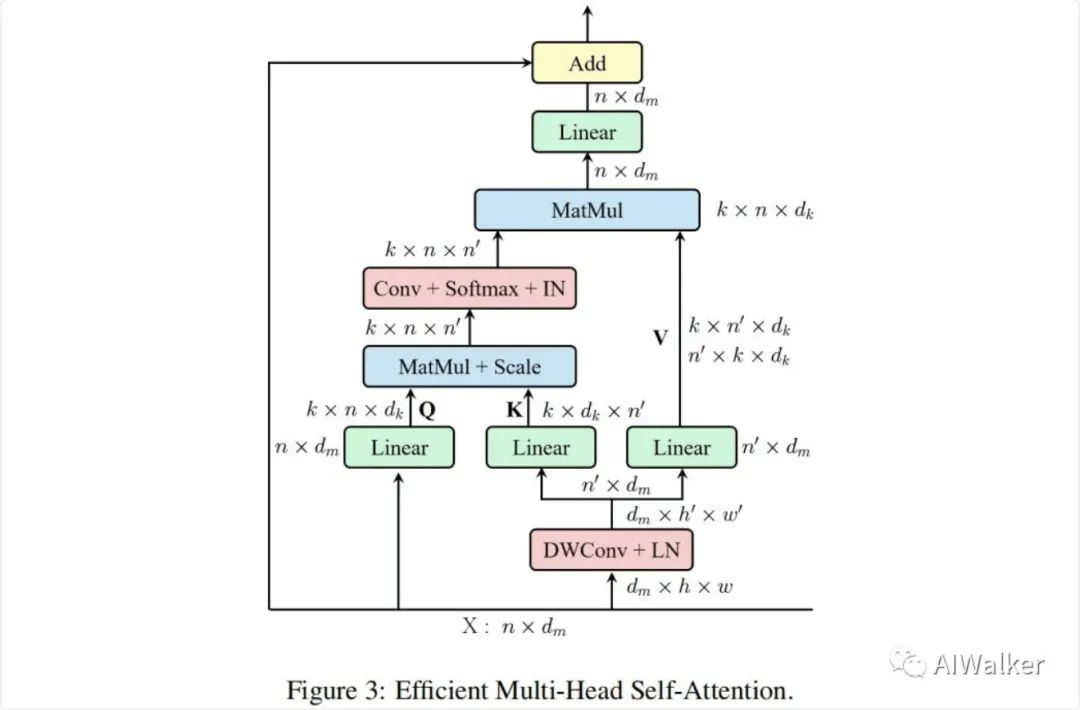
為解決上述問題,我們提出了上圖所示的高效多頭自注意力模塊。可以看到:
類似MSA,EMSA首先采用投影集合得到Q; 為壓縮內(nèi)存,2D輸入將被reshap為3D形式,然后送入深度卷積以因子降低空域維度; 將上述所得特征reshape為2D形式并送入后兩個投影集合得到K與V; 然后采用下面公式計算注意力,注:Conv為卷積,用于對不同頭進(jìn)行信息交互。為補(bǔ)償Conv導(dǎo)致的多樣性素食,我們在Softmax之后添加了IN。
最后,每個頭的輸出進(jìn)行拼接并線性 投影構(gòu)成最終的輸出。
EMSA的計算復(fù)雜度為,具有比MSA更低的計算量。此時,高效Transformer模塊定義如下:
Patch Embedding
標(biāo)準(zhǔn)的Transformer采用一序列token作為輸入,以ViT為例,3D圖像需要拆分為的塊,這些塊再平展為2D形式并映射為隱嵌入。然而,這種直接的tokenization難以捕獲底層特征信息(比如邊緣、角點)。此外,ViT中的tokens長度是固定的,這使其難以進(jìn)行下游任務(wù)(比如目標(biāo)檢測、實例分割)適配。
為解決上述問題,我們構(gòu)建了一種高效多尺度骨干ResT用于稠密預(yù)測。正如前面所提到的,每個階段的高效Transformer模塊在同尺度同分辨率上跨通道、空域維度進(jìn)行處理。因此,塊嵌入模塊同樣需要漸進(jìn)的擴(kuò)展通道維度,同時降低空域分辨率。
類似于ResNet,我們采用stem模塊以倍率4收縮寬高維度。為高效捕獲底層特征信息,我們引入了一種簡單而有效的方式:堆疊三個卷積,stride分別為212,前兩個后接BatchNorm與ReLU。在234階段,采用塊嵌入模塊下采樣空間分辨并提升通道維度,這與stride=2的卷積作用類似。
Position Encoding
位置編碼對于序列順序的探索非常關(guān)鍵,ViT一文將可學(xué)習(xí)參數(shù)加到輸入tokens中編碼位置信息。假設(shè)為輸入,表示位置參數(shù),那么編碼后輸入表示如下:
然而,此時要求位置長度與輸入tokens長度相同,這無疑會限制了其應(yīng)用。
為解決上述問題,我們需要設(shè)計一種新的變長位置編碼,我們將上式修改為如下:
其中表示組線性操作,組數(shù)為c。
除了上述形式外,我們還可以采用更靈活的注意力機(jī)制得到像素級權(quán)值。因此,我們提出了一種簡單且高效的像素注意力(Pixel-wise Attention,PA)模塊進(jìn)行位置編碼。具體來說,PA采用采用深度卷積計算像素權(quán)值,然后采用sigmoid激活,那么帶PA的位置編碼可以描述如下:
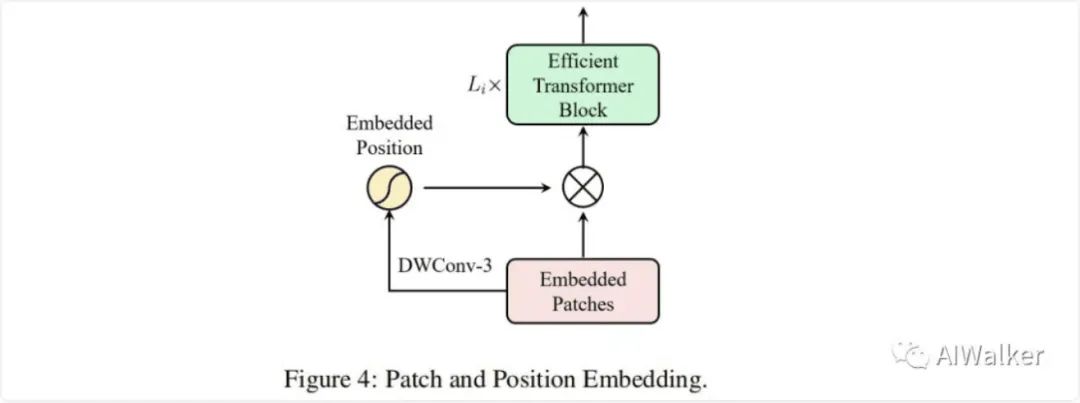
由于每個stage的輸入token通過卷積得到,我們可以將位置編碼嵌入到塊嵌入模塊中,整體結(jié)果見上圖。注:這里的PA可以采用任意空域注意力替換,這使得ResT中的PE極為靈活。
Linear Head
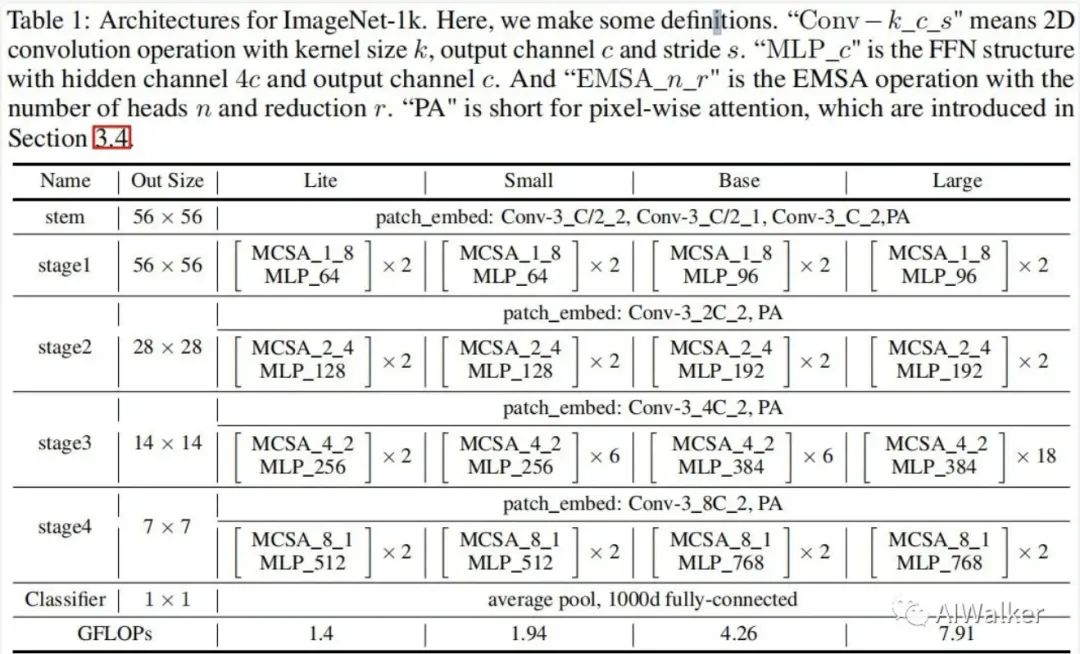
分類頭采用全局均值池化+線性分類器的方式,ResT的架構(gòu)配置信息見下表。
Experiments
接下來,我們在常用基準(zhǔn)任務(wù)上進(jìn)行所提方案驗證,包含ImageNet數(shù)據(jù)上的圖像分類、COCO數(shù)據(jù)上的目標(biāo)檢測與實例分割等。
Image Classification

上表給出了圖像分類任務(wù)上不同方案的性能對比,從中可以看到:
在小模型方面,ResT-small憑借相似的復(fù)雜度以79.6%精度大幅超過PVT-T的75.1%; 在中等模型方面,ResT-base憑借相似復(fù)雜度以81.6%超過Swin-T的81.3%; 在大模型方面,ResT-Large憑借相似復(fù)雜度以83.6%精度超過Swin-S的83.3%; 相比ConvNet,如RegNet,所提ResT憑借相似復(fù)雜度取得了更佳的性能; 總而 言之,在不同復(fù)雜度模型方面,ResT均顯著優(yōu)于現(xiàn)有模型。
Object Detection and Instance Segmentation
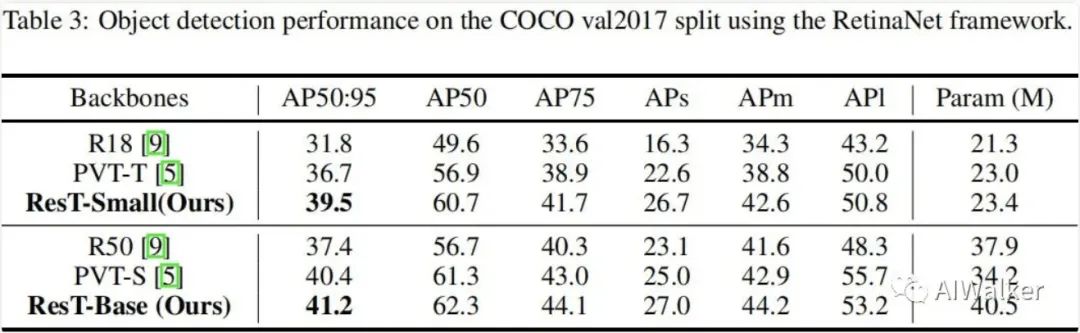
上表給出了RetinaNet架構(gòu)下的不同骨干模型在目標(biāo)檢測上的性能對比,可以看到:
在小模型方面,相比PVT-T,ResT-Small取得了2.8的指標(biāo)提升; 在大模型方面,相比PVT-S,ResT-Base取得了0.8的指標(biāo)提升。

上表給出了實例分割任務(wù)上的性能對比,可以看到:
在小模型方面,相比PVT-T,ResT-Small取得了1.8boxAP指標(biāo)提升,1.0MaskAP指標(biāo)提升; 在大模型方面,相比PVT-S,ResT-Base分別取得了2.1與1.9的指標(biāo)提升。
Ablation Study
接下來,我們對所提ResT進(jìn)行消融實驗分析,主要從stem、EMSA、PE三個角度進(jìn)行對比分析。
從下圖的Table5可以看到:ResT中的stem比PVT、ResNet中的Stem更加高效,分別取得了0.92%、0.64%的性能提升。
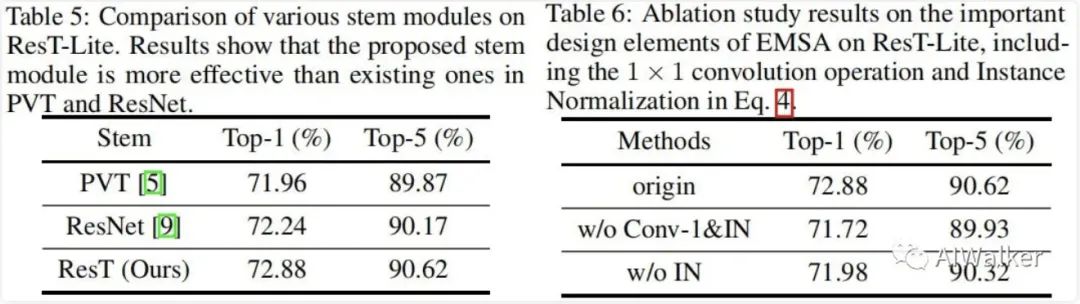
從上圖的Table6可以看到:
當(dāng)移除卷積操作與IN后,模型性能下降1.16%,這說明長序列與靈活性的組合對于注意力非常重要; 當(dāng)移除IN后,模型同樣出現(xiàn)了大幅性能下降,我們將其歸因于不同頭之間的多樣性遭到了破壞。
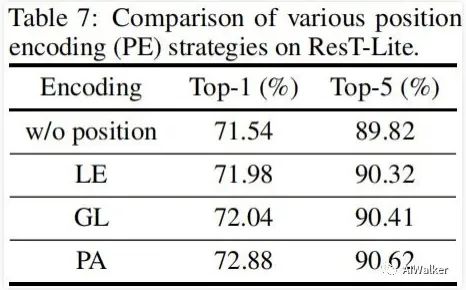
上表對比了不同PE的性能對比,從中可以看到:
當(dāng)移除PA編碼后,模型性能從72.88%下降到71.54%,這說明位置編碼對于ResT非常重要; LE與GL具有相似性能,而PA以0.84%精度優(yōu)于GL,這說明:空域注意力可用于進(jìn)行位置編碼建模。
也可以加一下老胡的微信 圍觀朋友圈~~~
推薦閱讀
(點擊標(biāo)題可跳轉(zhuǎn)閱讀)
深度學(xué)習(xí)的四個學(xué)習(xí)階段!
2021年,機(jī)器學(xué)習(xí)研究風(fēng)向要變了?
【機(jī)器學(xué)習(xí)】隨機(jī)森林是我最喜歡的模型
老鐵,三連支持一下,好嗎?↓↓↓