
Hudi 實(shí)踐 | 使用 Apache Hudi 構(gòu)建下一代 Lakehouse
1. 概括
本文介紹了一種稱為Data Lakehouse的現(xiàn)代數(shù)據(jù)架構(gòu)范例。Data Lakehouse相比于傳統(tǒng)的數(shù)據(jù)湖具有很多優(yōu)勢,本文說明了如何通過現(xiàn)代化數(shù)據(jù)平臺并使用Lakehouse架構(gòu)來應(yīng)對客戶端所面臨的可擴(kuò)展性、數(shù)據(jù)質(zhì)量和延遲方面的挑戰(zhàn)。本文介紹了使用Apache Hudi實(shí)現(xiàn)Data Lakehouse的基本知識和步驟。
2. 前言
過去十年隨著物聯(lián)網(wǎng)、云應(yīng)用、社交媒體和機(jī)器學(xué)習(xí)的發(fā)展,公司收集的數(shù)據(jù)量呈指數(shù)級增長,同時對高質(zhì)量數(shù)據(jù)的需求從幾天和幾小時的頻率變?yōu)閹追昼娚踔翈酌腌姷臅r間。
數(shù)年來數(shù)據(jù)湖作為存儲原始和豐富數(shù)據(jù)的存儲庫發(fā)揮了重要作用。但是隨著它們的成熟,企業(yè)意識到維護(hù)高質(zhì)量、最新和一致的數(shù)據(jù)是非常復(fù)雜的。除了攝取增量數(shù)據(jù)的復(fù)雜性之外,填充數(shù)據(jù)湖還需業(yè)務(wù)環(huán)境和高度依賴批處理。以下是現(xiàn)代數(shù)據(jù)湖的主要挑戰(zhàn):
?基于查詢的變更數(shù)據(jù)捕獲:提取增量源數(shù)據(jù)的最常見方法是依賴定義過濾條件的查詢。當(dāng)表沒有有效字段來增量提取數(shù)據(jù)時,在源數(shù)據(jù)庫上添加額外負(fù)載或無法捕獲數(shù)據(jù)庫的每一次變更,基于查詢的CDC不包括已刪除的記錄,因為沒有簡單的方法來確定是否已刪除了記錄。基于日志的CDC是首選方法,可以解決上述挑戰(zhàn)。本文將進(jìn)一步討論該方法。?數(shù)據(jù)湖中的增量數(shù)據(jù)處理:負(fù)責(zé)更新數(shù)據(jù)湖的ETL作業(yè)必須讀取數(shù)據(jù)湖中的所有文件進(jìn)行更改,并將整個數(shù)據(jù)集重寫為新文件(因為沒有簡單的方法更新記錄所在的文件)。?缺少對ACID事務(wù)的支持:如果同時存在讀寫,不遵從ACID事務(wù)會導(dǎo)致結(jié)果不一致。
數(shù)據(jù)體量的增加和保持最新數(shù)據(jù)使上述挑戰(zhàn)更加復(fù)雜。Uber、Databricks和Netflix提出了旨在解決數(shù)據(jù)工程師面臨的挑戰(zhàn)的解決方案的數(shù)據(jù)湖處理框架,旨在在分布式文件系統(tǒng)(例如S3、OSS或HDFS)上的數(shù)據(jù)湖中執(zhí)行插入和刪除操作。下一代Data Lakes旨在以可擴(kuò)展性、適應(yīng)性和可靠的方式提供最新數(shù)據(jù),即Data Lakehouse。
3. 什么是Lakehouse
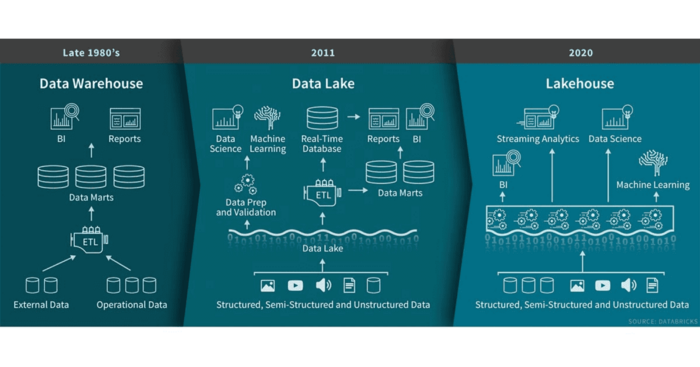
更多詳情可參考如下文章:Lakehouse: 統(tǒng)一數(shù)據(jù)倉庫和高級分析的新一代開放平臺,什么是LakeHouse
簡而言之:Data Lakehouse = Data Lake + Data Warehouse
傳統(tǒng)數(shù)據(jù)倉庫旨在提供一個用于存儲已針對特定用例/數(shù)據(jù)進(jìn)行了轉(zhuǎn)換/聚合的歷史數(shù)據(jù)平臺,以便與BI工具結(jié)合使用獲取見解。通常數(shù)據(jù)倉庫僅包含結(jié)構(gòu)化數(shù)據(jù),成本效益不高,使用批處理ETL作業(yè)加載。
Data Lakes 可以克服其中一些限制,即通過低成本存儲支持結(jié)構(gòu)化,半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù),以及使用批處理和流傳輸管道。與數(shù)據(jù)倉庫相比,數(shù)據(jù)湖包含多種存儲格式的原始數(shù)據(jù),可用于當(dāng)前和將來的用例。但是數(shù)據(jù)湖仍然存在局限性,包括事務(wù)支持(很難使數(shù)據(jù)湖保持最新狀態(tài))和ACID合規(guī)性(不支持并發(fā)讀寫)。
數(shù)據(jù)湖中心可利用S3,OSS,GCS,Azure Blob對象存儲的數(shù)據(jù)湖低成本存儲優(yōu)勢,以及數(shù)據(jù)倉庫的數(shù)據(jù)結(jié)構(gòu)和數(shù)據(jù)管理功能。支持ACID事務(wù)并確保并發(fā)讀取和更新數(shù)據(jù)的一致性來克服數(shù)據(jù)湖的限制。此外與傳統(tǒng)的數(shù)據(jù)倉庫相比,Lakehouse能夠以更低的延遲和更高的速度消費(fèi)數(shù)據(jù),因為可以直接從Lakehouse查詢數(shù)據(jù)。
Lakehouse的主要特性如下
?事務(wù)支持?Schema enforcement and governance(模式實(shí)施和治理)?BI支持?存儲與計算分離?開放性?支持從非結(jié)構(gòu)化數(shù)據(jù)到結(jié)構(gòu)化數(shù)據(jù)的多種數(shù)據(jù)類型?支持各種工作負(fù)載?端到端流
為了構(gòu)建Lakehouse,需要一個增量數(shù)據(jù)處理框架,例如Apache Hudi。
4. 什么是Apache Hudi
Apache Hudi代表Hadoop Upserts Deletes Incrementals,是Uber在2016年開發(fā)的開源框架,用于管理分布式文件系統(tǒng)(如云存儲,HDFS或任何其他Hadoop FileSystem兼容存儲)上的大型文件集,實(shí)現(xiàn)了數(shù)據(jù)湖中原子性、一致性、隔離性和持久性(ACID)事務(wù)。Hudi的commit模型基于時間軸,該時間軸包含對表執(zhí)行的所有操作,Hudi提供了以下功能:
?通過快速,可插拔的索引支持Upsert。?具有回滾的原子發(fā)布,保存點(diǎn)。?讀寫快照隔離。?使用統(tǒng)計信息管理文件大小和布局。?行和列數(shù)據(jù)的異步壓縮。?時間軸元數(shù)據(jù)以跟蹤血統(tǒng)。
4.1 使用用例
1. 使用變更數(shù)據(jù)捕獲來更新/刪除目標(biāo)數(shù)據(jù)
變更數(shù)據(jù)捕獲(CDC)是指識別和捕獲源數(shù)據(jù)庫中所做的變更。它將更改從源數(shù)據(jù)庫復(fù)制到目的端(在本例中為數(shù)據(jù)湖)。這對于將插入、更新和刪除操作捕獲到目標(biāo)表中特別重要。
一下列舉了三種最常用的CDC方法
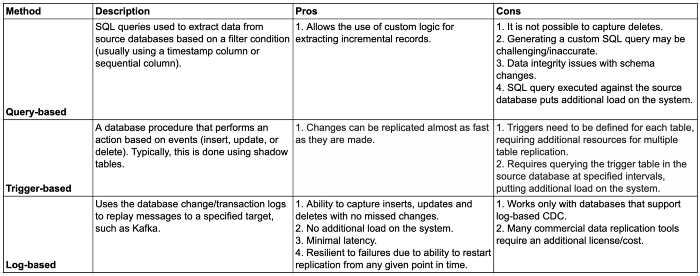
基于日志的CDC為將更改從源數(shù)據(jù)庫復(fù)制到數(shù)據(jù)湖庫是最好的方案,因為它能夠捕獲已刪除的記錄,而這些記錄無法使用基于查詢的CDC捕獲,因為如果在源數(shù)據(jù)中不存在刪除標(biāo)志,則無法捕獲。
Hudi可以通過在現(xiàn)有數(shù)據(jù)集中找到適當(dāng)?shù)奈募⒅貙懰鼈儊硖幚砀臄?shù)據(jù)捕獲。此外它還提供了基于特定時間點(diǎn)查詢數(shù)據(jù)集的功能,并提供了時間旅行。
使用CDC工具(例如Oracle GoldenGate,Qlik Replicate(以前稱為Attunity Replicate)和DMS)進(jìn)行近實(shí)時數(shù)據(jù)攝取非常通用,將這些變更應(yīng)用于現(xiàn)有數(shù)據(jù)集至關(guān)重要。
2. 隱私條例
GDPR等最新的隱私法規(guī)要求公司必須具有記錄級別的更新和刪除功能。通過支持Hudi數(shù)據(jù)集中的刪除,可以大大簡化針對特定用戶或在特定時間范圍內(nèi)更新或刪除信息的過程。
4.2 不同類型表
**COPY ON WRITE(寫時復(fù)制)**:數(shù)據(jù)以Parquet文件格式存儲(列存儲),并且每次更新都會創(chuàng)建文件的新版本。此存儲類型最適合于繁重的批處理工作負(fù)載,因為數(shù)據(jù)集的最新版本立刻可用。
**MERGE ON READ(讀取時合并)**:數(shù)據(jù)存儲為Parquet(列存儲)和Avro(基于行的存儲)文件格式的組合。更新記錄到基于行的增量文件中,當(dāng)進(jìn)行壓縮(Compaction)時將產(chǎn)生新版本列存文件。這種存儲類型更適合于繁重的流工作負(fù)載,因為提交是作為增量文件寫入的,而讀取數(shù)據(jù)集則需要合并Parquet和Avro文件。
一般經(jīng)驗法則:對于僅通過批處理ETL作業(yè)進(jìn)行更新的表,可使用"寫時復(fù)制"。對于通過流ETL作業(yè)更新的表,可使用"讀取時合并"。有關(guān)更多詳細(xì)信息,請參閱Hudi文檔中的如何為工作負(fù)載選擇存儲類型[1]。
4.3 不同查詢類型
?快照讀:指定提交/壓縮操作的表的最新快照。對于"讀時合并"表,快照查詢將即時合并基本文件和增量文件;因此有一定的延遲。?增量讀:指定提交/壓縮以來表中的所有變更。?讀優(yōu)化:指定的提交/壓縮操作的表的最新快照。對于"讀時合并"表,讀取優(yōu)化查詢返回一個視圖,該視圖僅包含基本文件中的數(shù)據(jù),而不合并增量文件。
4.4 Hudi的優(yōu)勢
?解決數(shù)據(jù)質(zhì)量問題,例如重復(fù)記錄,延遲到達(dá)的更新等,這些問題通常在傳統(tǒng)的增量批處理ETL管道中存在。?提供對實(shí)時管道的支持。?異常檢測,機(jī)器學(xué)習(xí)用例,實(shí)時檢測等?創(chuàng)建可用于跟蹤更改的機(jī)制(時間軸)。?提供對通過Hive和Presto進(jìn)行查詢的原生支持。
Apache Hudi增量數(shù)據(jù)處理框架實(shí)現(xiàn)Lakehouse,我們著手設(shè)計一種解決方案來克服尋求增強(qiáng)其數(shù)據(jù)平臺的客戶所面臨的關(guān)鍵挑戰(zhàn)。
5. 問題
我們與需要改進(jìn)、具有成本效益和可擴(kuò)展性的數(shù)據(jù)平臺的客戶合作,該平臺將使他們的數(shù)據(jù)科學(xué)家能夠使用最新數(shù)據(jù)并以較低的延遲進(jìn)行近乎實(shí)時的預(yù)測,從而獲得更好的見解。他們現(xiàn)有的批處理ETL作業(yè)按時進(jìn)行,并且計算量大,因為它需要重新處理整個數(shù)據(jù)集。此外這些過程使用基于查詢的CDC方法,導(dǎo)致無法捕獲每個源庫變更。過時的數(shù)據(jù)和不準(zhǔn)確的數(shù)據(jù)導(dǎo)致對數(shù)據(jù)平臺缺乏信任,而不能從數(shù)據(jù)中獲得任何直接價值。
6. 解決方案
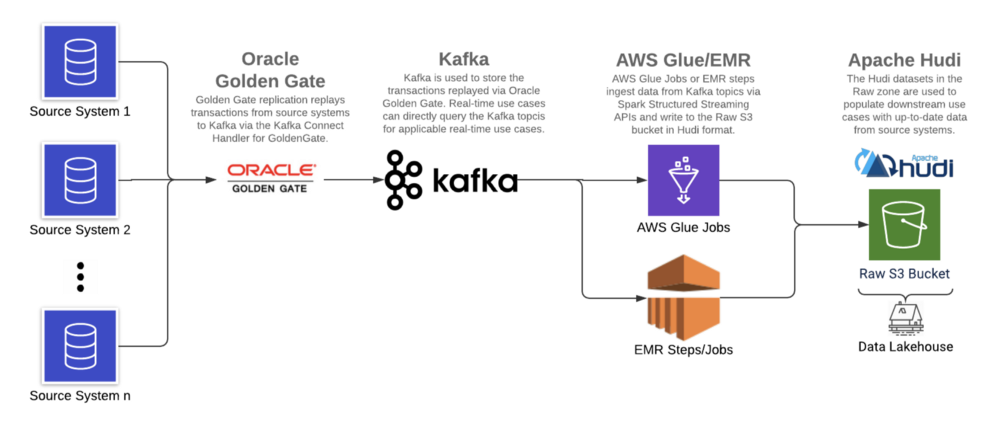
使用基于日志的CDC工具(Oracle GoldenGate),Apache Kafka和增量數(shù)據(jù)處理框架(在AWS上運(yùn)行的Apache Hudi),我們在AWS S3上構(gòu)建了數(shù)據(jù)湖,以減少延遲,改善數(shù)據(jù)質(zhì)量并支持ACID事務(wù)。
6.1 架構(gòu)
6.2 環(huán)境
?Oracle大數(shù)據(jù)Oracle GoldenGate[2]:19c?Confluent Kafka[3]:5.5.0?Apache Spark(Glue)[4]:2.4.3?ABRiS[5]:3.2?Apache Hudi[6]:0.5.3
由于客戶現(xiàn)有的Oracle GoldenGate產(chǎn)品系列,Oracle GoldenGate被用作基于日志的CDC工具從源系統(tǒng)日志中提取數(shù)據(jù),日志實(shí)時地復(fù)制到Kafka,從中讀取消息并以Hudi格式寫入數(shù)據(jù)湖。
Apache Hudi與AWS EMR和Athena集成,是增量數(shù)據(jù)處理框架的理想選擇。
6.3 實(shí)施步驟
6.3.1 使用Oracle GoldenGate復(fù)制源數(shù)據(jù)
如前所述,基于日志的CDC是最佳解決方案,因為它可以同時處理批量和流式案例。對于批處理和流式源,不再需要具有單獨(dú)的攝取模式。傳統(tǒng)上批處理工作負(fù)載是利用一條SQL語句,并以所需頻率運(yùn)行該SQL語句。相反,基于日志的CDC可以捕獲任何更改,然后將其重播到目的端(即Kafka)。攝取與消費(fèi)的解耦引入了靈活性,可根據(jù)需要在Lakehouse內(nèi)更新數(shù)據(jù)的頻率來提取增量數(shù)據(jù)。這樣可以最大程度地降低成本,因為可以在定義的保留期內(nèi)從Kafka檢索數(shù)據(jù)。
Oracle GoldenGate是一種數(shù)據(jù)復(fù)制工具,用于從源系統(tǒng)捕獲事務(wù)并將其復(fù)制到目標(biāo)(例如Kafka主題或另一個數(shù)據(jù)庫)中。它利用數(shù)據(jù)庫事務(wù)日志來工作,該日志記錄了數(shù)據(jù)庫中發(fā)生的所有操作,OGG將讀取事務(wù)并將其推送到指定的目的端, GoldenGate支持多個關(guān)系數(shù)據(jù)庫,包括Oracle,MySQL,DB2,SQL Server和Teradata。
此解決方案中使用Oracle GoldenGate將變更從源數(shù)據(jù)庫流式傳輸?shù)終afka過程分為三個步驟:
?通過Oracle GoldenGate 12c(經(jīng)典版本)從源數(shù)據(jù)庫跟蹤日志中提取數(shù)據(jù):源數(shù)據(jù)庫發(fā)生的事務(wù)以中間日志格式(跟蹤日志)存儲被實(shí)時提取。?將跟蹤日志送到輔助遠(yuǎn)程跟蹤日志:將提取的跟蹤日志送到另一個跟蹤日志(由Oracle GoldenGate for Big Data 12c實(shí)例管理)。?使用Kafka Connect處理程序,通過Oracle GoldenGate for Big Data 12c將跟蹤日志復(fù)制到Kafka:接收提取的事務(wù)并將其復(fù)制到Kafka消息中,在發(fā)布到Kafka之前,此過程將序列化(帶有或不帶有Schema Registry)Kafka消息,并對從事務(wù)日志重播的消息執(zhí)行類型轉(zhuǎn)換(如果需要)。
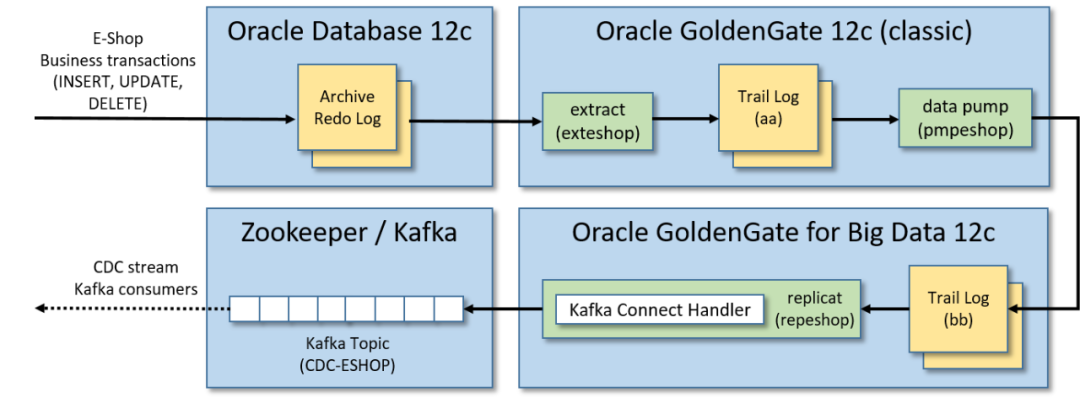
注意:默認(rèn)情況下更新的記錄僅包含通過GoldenGate復(fù)制時更新的列,為了確保增量記錄可以以最小的轉(zhuǎn)換合并到數(shù)據(jù)湖中(即復(fù)制具有所有列的整個記錄),必須啟用補(bǔ)充日志記錄[7],這將包括每個記錄的"before"和"after"圖像。
GoldenGate復(fù)制包含一個"op_type"字段,該字段指示源跟蹤文件中數(shù)據(jù)庫操作的類型:I表示插入,U表示更新,D表示刪除。該字段對于確定如何在數(shù)據(jù)湖庫中增加/刪除記錄很有幫助。
以下是樣本插入記錄:
{"table": "GG.TCUSTORD","op_type": "I","op_ts": "2013-06-02 22:14:36.000000","current_ts": "2015-09-18T10:17:49.570000","pos": "00000000000000001444","primary_keys": ["CUST_CODE","ORDER_DATE","PRODUCT_CODE","ORDER_ID"],"tokens": {"R": "AADPkvAAEAAEqL2AAA"},"before": null,"after": {"CUST_CODE": "WILL","CUST_CODE_isMissing": false,"ORDER_DATE": "1994-09-30:15:33:00","ORDER_DATE_isMissing": false,"PRODUCT_CODE": "CAR","PRODUCT_CODE_isMissing": false,"ORDER_ID": "144","ORDER_ID_isMissing": false,"PRODUCT_PRICE": 17520,"PRODUCT_PRICE_isMissing": false,"PRODUCT_AMOUNT": 3,"PRODUCT_AMOUNT_isMissing": false,"TRANSACTION_ID": "100","TRANSACTION_ID_isMissing": false}}
注意:GoldenGate記錄在"before"包含一個空值,在"after"包含一個非空值。
樣本更新記錄[8]
注意:GoldenGate更新記錄包含映像前非空和映像后非空。
樣本刪除記錄[9]
注意:GoldenGate刪除記錄在映像之前包含非null,在映像之后包含null。
6.3.2 在Kafka中捕獲復(fù)制的數(shù)據(jù)
GoldenGate 復(fù)制的目標(biāo)是 Kafka。由于 GoldenGate for BigData 將通過 Kafka Connect 處理程序?qū)⒂涗洀?fù)制到 Kafka,因此支持模式演變和通過Schema Registry提供的其他功能[10]。
為什么選擇Kafka充當(dāng)CDC工具和數(shù)據(jù)湖庫之間的中間層,主要有兩個原因。
?第一個原因是GoldenGate無法以Apache Hudi格式將CDC數(shù)據(jù)直接從源數(shù)據(jù)庫復(fù)制到 Lakehouse 。Kafka 和 Spark Structured Streaming 之間現(xiàn)有集成使Kafka成為暫存增量記錄的理想選擇,然后可以以Hudi格式對其進(jìn)行處理和寫入。?第二個原因是解決需要近實(shí)時延遲的消費(fèi)者,例如基于一組事務(wù)來檢測并避免用戶的服務(wù)丟失。
6.3.3 從Kafka讀取數(shù)據(jù)并以Hudi格式寫入S3
Spark Structured Streaming 作業(yè)執(zhí)行以下操作:
1. 讀取kafka記錄
TOPIC_NAME = "topic_name"KAFKA_BOOTSTRAP_SERVERS = "host1:port1,host2:port2"# read data from Kafkadf = (spark.readStream.format("kafka").option("kafka.bootstrap.servers", KAFKA_BOOTSTRAP_SERVERS).option("subscribe", TOPIC_NAME).load())
2. 使用Schema Registry反序列化記錄
注意:使用 Confluent Avro 格式序列化的 Kafka 主題中的任何數(shù)據(jù)都無法使用 Spark API 在本地進(jìn)行反序列化,從而阻止了對數(shù)據(jù)的任何下游處理。使用 GoldenGate 復(fù)制的記錄就是這種情況。ABRiS 是一個 Spark 庫,可以根據(jù) Schema Registry 中的模式對Confluent Avro 格式的 Kafka 記錄進(jìn)行反序列化。該解決方案中使用的ABRiS版本為3.2。
from pyspark import SparkContextfrom pyspark.sql.column import Column, _to_java_columnfrom pyspark.sql.functions import col# instantiates a Scala Map containing configurations for communicating with Schema Regsitry APIsdef get_schema_registry_conf_map(spark, schema_registry_url, topic_name):sc = spark.SparkContextjvm_gateway = sc._gateway.jvmschema_registry_config_dict = {"schema.registry.url": schema_registry_url,"schema.registry.topic": topic_name,"value.schema.id": "latest","value.schema.naming.strategy": "topic.name"}conf_map = getattr(getattr(jvm_gateway.scala.collection.immutable.Map, "EmptyMap$"), "MODULE$")for k, v in schema_registry_config_dict.items():conf_map = getattr(conf_map, "$plus")(jvm_gateway.scala.Tuple2(k, v))return conf_map# returns deserialized column (using Schema Registry)def from_avro(col, conf_map):jvm_gateway = SparkContext._active_spark_context._gateway.jvmabris_avro = jvm_gateway.za.co.absa.abris.avroreturn Column(abris_avro.functions.from_confluent_avro(_to_java_column(col), conf_map))TOPIC_NAME = "topic_name"SCHEMA_REGISTRY_URL = "host1:port1,host2:port2"# instantiate Scala Map for communicating with Schema Regsitry APIsconf_map = get_schema_registry_conf_map(spark, SCHEMA_REGISTRY_URL, TOPIC_NAME)# deserialize column containing data (using Schema Registry) and select pertinent columns for processing anddeserialized_df = df.select(col("key").cast("string"),col("partition"),col("offset"),col("timestamp"),col("timestampType"),from_avro(df.value, conf_map).alias("value"))
3. 根據(jù)Oracle GoldenGate "op_type"提取所需的前后映像,并將記錄以Hudi格式寫入數(shù)據(jù)湖
Spark代碼使用GoldenGate記錄中的"op_type"字段將傳入記錄的批次分為兩組:一組包含插入/更新,第二組包含刪除。這樣做是為了可以相應(yīng)地設(shè)置Hudi寫操作配置。隨后進(jìn)一步轉(zhuǎn)換之前或之后的映像。最后一步是設(shè)置下面提到的適當(dāng)?shù)腍udi屬性,然后以流或批處理方式通過foreachBatch Spark Structured Streaming API將Hudi格式的upserts和deletes寫入S3中。
import copy# write to a path using the Hudi formatdef hudi_write(df, schema, table, path, mode, hudi_options):hudi_options = {"hoodie.datasource.write.recordkey.field": "recordkey","hoodie.datasource.write.precombine.field": "precombine_field","hoodie.datasource.write.partitionpath.field": "partitionpath_field","hoodie.datasource.write.operation": "write_operaion","hoodie.datasource.write.table.type": "table_type","hoodie.table.name": TABLE,"hoodie.datasource.write.table.name": TABLE,"hoodie.bloom.index.update.partition.path": True,"hoodie.index.type": "GLOBAL_BLOOM","hoodie.consistency.check.enabled": True,# Set Glue Data Catalog related Hudi configs"hoodie.datasource.hive_sync.enable": True,"hoodie.datasource.hive_sync.use_jdbc": False,"hoodie.datasource.hive_sync.database": SCHEMA,"hoodie.datasource.hive_sync.table": TABLE,}if (hudi_options.get("hoodie.datasource.write.partitionpath.field")and hudi_options.get("hoodie.datasource.write.partitionpath.field") != ""):hudi_options.setdefault("hoodie.datasource.write.keygenerator.class","org.apache.hudi.keygen.ComplexKeyGenerator",)hudi_options.setdefault("hoodie.datasource.hive_sync.partition_extractor_class","org.apache.hudi.hive.MultiPartKeysValueExtractor",)hudi_options.setdefault("hoodie.datasource.hive_sync.partition_fields",hudi_options.get("hoodie.datasource.write.partitionpath.field"),)hudi_options.setdefault("hoodie.datasource.write.hive_style_partitioning", True)else:hudi_options["hoodie.datasource.write.keygenerator.class"] = "org.apache.hudi.keygen.NonpartitionedKeyGenerator"hudi_options.setdefault("hoodie.datasource.hive_sync.partition_extractor_class","org.apache.hudi.hive.NonPartitionedExtractor",)df.write.format("hudi").options(**hudi_options).mode(mode).save(path)# parse the OGG records and write upserts/deletes to S3 by calling the hudi_write functiondef write_to_s3(df, path):# select the pertitent fields from the dfflattened_df = df.select("value.*", "key", "partition", "offset", "timestamp", "timestampType")# filter for only the inserts and updatesdf_w_upserts = flattened_df.filter('op_type in ("I", "U")').select("after.*","key","partition","offset","timestamp","timestampType","op_type","op_ts","current_ts","pos",)# filter for only the deletesdf_w_deletes = flattened_df.filter('op_type in ("D")').select("before.*","key","partition","offset","timestamp","timestampType","op_type","op_ts","current_ts","pos",)# invoke hudi_write function for upsertsif df_w_upserts and df_w_upserts.count() > 0:hudi_write(df=df_w_upserts,schema="schema_name",table="table_name",path=path,mode="append",hudi_options=hudi_options)# invoke hudi_write function for deletesif df_w_deletes and df_w_deletes.count() > 0:hudi_options_copy = copy.deepcopy(hudi_options)hudi_options_copy["hoodie.datasource.write.operation"] = "delete"hudi_options_copy["hoodie.bloom.index.update.partition.path"] = Falsehudi_write(df=df_w_deletes,schema="schema_name",table="table_name",path=path,mode="append",hudi_options=hudi_options_copy)TABLE = "table_name"SCHEMA = "schema_name"CHECKPOINT_LOCATION = "s3://bucket/checkpoint_path/"TARGET_PATH="s3://bucket/target_path/"STREAMING = True# instantiate writeStream objectquery = deserialized_df.writeStream# add attribute to writeStream object for batch writesif not STREAMING:query = query.trigger(once=True)# write to a path using the Hudi formatwrite_to_s3_hudi = query.foreachBatch(lambda batch_df, batch_id: write_to_s3(df=batch_df, path=TARGET_PATH)).start(checkpointLocation=CHECKPOINT_LOCATION)# await termination of the write operationwrite_to_s3_hudi.awaitTermination()
4. 重要的Hudi配置項
hoodie.datasource.write.precombine.field:表的precombine字段是必填配置,并且字段不能為空(即對于記錄不存在)。如果數(shù)據(jù)源不滿足此要求,則可能有必要為這些表實(shí)現(xiàn)自定義重復(fù)數(shù)據(jù)刪除邏輯。
hoodie.datasource.write.keygenerator.class:對于包含復(fù)合鍵或被多個列分區(qū)的表,請將此值設(shè)置為org.apache.hudi.keygen.ComplexKeyGenerator。對于非分區(qū)表,將此值設(shè)置為org.apache.hudi.keygen.NonpartitionedKeyGenerator。
hoodie.datasource.hive_sync.partition_extractor_class:將此值設(shè)置為org.apache.hudi.hive.MultiPartKeysValueExtractor以創(chuàng)建由多個列組成分區(qū)字段的Hive表。將此值設(shè)置為org.apache.hudi.hive.NonPartitionedExtractor以創(chuàng)建無分區(qū)的Hive表。
hoodie.index.type:默認(rèn)情況下,它設(shè)置為BLOOM,它將僅在單個分區(qū)內(nèi)強(qiáng)制鍵的唯一性。使用GLOBAL_BLOOM在所有分區(qū)上保證唯一性。Hudi會將傳入記錄與整個數(shù)據(jù)集中的文件進(jìn)行比較,以確保recordKey僅出現(xiàn)在單個分區(qū)中。非常大的數(shù)據(jù)集會有延遲。
hoodie.bloom.index.update.partition.path:對于刪除操作,請確保將其設(shè)置為False(如果使用GLOBAL_BLOOM索引)。
hoodie.datasource.hive_sync.use_jdbc:將此值設(shè)置為False可將表同步到Glue Data Catalog(如果需要)。
有關(guān)配置的完整列表,請參閱Apache Hudi配置頁面[11];有關(guān)其他任何查詢,請參閱Apache Hudi FAQ頁面[12]。
注意(Apache Hudi與AWS Glue一起使用)
Maven[13]上提供的hudi-spark-bundle_2.11-0.5.3.jar不能與AWS Glue一起使用。需要通過更改原始pom.xml來創(chuàng)建自定義jar。
1.下載并更新pom.xml[14]的內(nèi)容。a)從
<include>org.apache.httpcomponents:httpclient</include>b)將以下行添加到
<relocation><pattern>org.eclipse.jetty.</pattern><shadedPattern>org.apache.hudi.org.eclipse.jetty.</shadedPattern></relocation>
1.構(gòu)建JAR:
mvn clean package -DskipTests -DskipITs然后可以使用上面的命令(位于"target / hudi-spark-bundle_2.11-0.5.3.jar"目錄)構(gòu)建的JAR作為Glue作業(yè)參數(shù)傳遞[15]。
完成上述步驟后即可使用Lakehouse。使用上面提到的Apache Hudi API可用的一種查詢方法,可以從Raw S3存儲桶中使用數(shù)據(jù)。
7. 結(jié)論
該方案成功解決了傳統(tǒng)數(shù)據(jù)湖所面臨的挑戰(zhàn):
?基于日志的CDC是用于捕獲數(shù)據(jù)庫事務(wù)/事件的更可靠的機(jī)制。?Apache Hudi負(fù)責(zé)(以前由數(shù)據(jù)平臺所有者所有)通過管理大規(guī)模Lakehouse所需的索引和相關(guān)元數(shù)據(jù)來更新數(shù)據(jù)湖庫中的目標(biāo)數(shù)據(jù)。?ACID事務(wù)的支持消除了并發(fā)操作的麻煩,因為Apache Hudi API支持并發(fā)讀寫,而不會產(chǎn)生不一致的結(jié)果。
隨著越來越多的企業(yè)采用數(shù)據(jù)平臺并增強(qiáng)其數(shù)據(jù)分析/機(jī)器學(xué)習(xí)功能,必須為服務(wù)于數(shù)據(jù)的基礎(chǔ)CDC工具和管道的重要性不斷發(fā)展以應(yīng)對一些最普遍面臨的挑戰(zhàn)。數(shù)據(jù)延遲和交付給下游消費(fèi)者的數(shù)據(jù)的整體質(zhì)量的改善表明Data Lakehouse范式是下一代數(shù)據(jù)平臺。這將成為企業(yè)從其數(shù)據(jù)中獲得更大價值和洞察力的基礎(chǔ)。
我們希望本文為您提供了使用Apache Hudi構(gòu)建Data Lakehouse的思路。
推薦閱讀
Apache Hudi與Apache Flink更好地集成,最新方案了解下?
查詢時間降低60%!Apache Hudi數(shù)據(jù)布局黑科技了解下
恭喜!Apache Hudi社區(qū)新晉兩位Committer
引用鏈接
[1] 如何為工作負(fù)載選擇存儲類型: https://cwiki.apache.org/confluence/display/HUDI/FAQ#FAQ-HowdoIchooseastoragetypeformyworkload[2] Oracle大數(shù)據(jù)Oracle GoldenGate: https://www.oracle.com/integration/goldengate/big-data/[3] Confluent Kafka: https://docs.confluent.io/5.5.0/index.html[4] Apache Spark(Glue): https://spark.apache.org/docs/2.4.3/structured-streaming-programming-guide.html[5] ABRiS: https://github.com/AbsaOSS/ABRiS/tree/branch-3.2[6] Apache Hudi: https://hudi.apache.org/docs/0.5.3-quick-start-guide.html[7] 補(bǔ)充日志記錄: https://docs.oracle.com/en/middleware/goldengate/core/19.1/oracle-db/preparing-database-oracle-goldengate.html#GUID-357BCE43-5951-466E-8EFF-C14D46A252D3[8] 樣本更新記錄: https://gist.github.com/rnbtechnology/2e3ffafb6f5e21727a27f149abef898c[9] 樣本刪除記錄: https://gist.github.com/rnbtechnology/168a92d3629474b5b1c024bf628f8b45[10] 其他功能: https://docs.confluent.io/platform/current/schema-registry/index.html#ak-serializers-and-deserializers-background[11] Apache Hudi配置頁面: https://hudi.apache.org/docs/configurations.html[12] Apache Hudi FAQ頁面: https://cwiki.apache.org/confluence/display/HUDI/FAQ[13] Maven: https://mvnrepository.com/artifact/org.apache.hudi/hudi-spark-bundle_2.11/0.5.3[14] pom.xml: https://github.com/apache/hudi/blob/release-0.5.3/packaging/hudi-spark-bundle/pom.xml[15] 參數(shù)傳遞: https://docs.aws.amazon.com/glue/latest/dg/aws-glue-programming-etl-glue-arguments.html