
Python處理PDF神器:PyMuPDF的安裝與使用
在公眾號后臺回復:JGNB,可獲取杰哥原創(chuàng)的 PDF 手冊。
1、
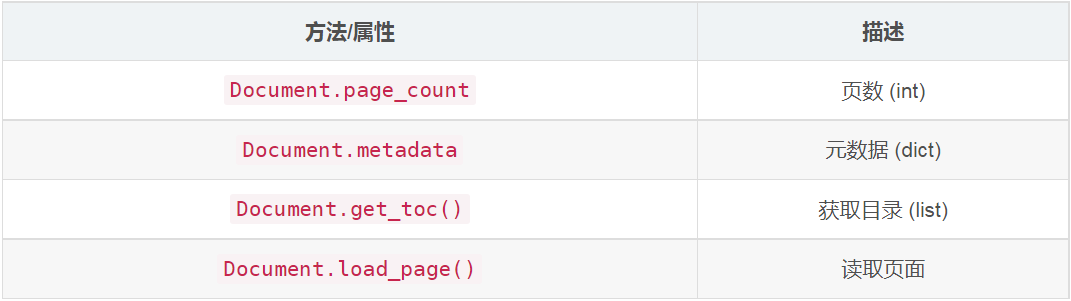
PyMuPDF簡介
1. 介紹
PyMuPDF之前,先來了解一下MuPDF,從命名形式中就可以看出,PyMuPDF是MuPDF的Python接口形式。MuPDF 是一個輕量級的 PDF、XPS和電子書查看器。MuPDF 由軟件庫、命令行工具和各種平臺的查看器組成。MuPDF 中的渲染器專為高質量抗鋸齒圖形量身定制。它以精確到像素的幾分之一內的度量和間距呈現(xiàn)文本,以在屏幕上再現(xiàn)打印頁面的外觀時獲得最高保真度。PDF、XPS、OpenXPS、CBZ、EPUB和FictionBook 2。您可以使用移動查看器對PDF文檔進行注釋和填寫表單(這個功能很快也將應用于桌面查看器)。HTML、SVG、PDF和CBZ。您還可以使用Javascript編寫腳本來操作文檔。PyMuPDF(當前版本1.18.17)是支持MuPDF(當前版本1.18.*)的Python綁定。PyMuPDF,你可以訪問擴展名為“.pdf”、“.xps”、“.oxps”、“.cbz”、“.fb2”或“.epub”。此外,大約10種流行的圖像格式也可以像文檔一樣處理:“.png”,“.jpg”,“.bmp”,“.tiff”等。2. 功能
解密文件
訪問元信息、鏈接和書簽
以柵格格式(
PNG和其他格式)或矢量格式SVG呈現(xiàn)頁面搜索文本
提取文本和圖像
轉換為其他格式:
PDF, (X)HTML, XML, JSON, text對于
PDF文檔,存在大量的附加功能:它們可以創(chuàng)建、合并或拆分。頁面可以通過多種方式插入、刪除、重新排列或修改(包括注釋和表單字段)。可以提取或插入圖像和字體
完全支持嵌入式文件
pdf文件可以重新格式化,以支持雙面打印,色調分離,應用標志或水印
完全支持密碼保護:解密、加密、加密方法選擇、權限級別和用戶/所有者密碼設置
支持圖像、文本和繪圖的 PDF 可選內容概念
可以訪問和修改低級 PDF 結構
命令行模塊
"python -m fitz…"具有以下特性的多功能實用程序新:布局保存文本提取!
腳本fitzcliy .py通過子命令“gettext”提供不同格式的文本提取。特別有趣的當然是布局保存,它生成的文本盡可能接近原始物理布局,周圍有圖像的區(qū)域,或者在表格和多列文本中復制文本。加密/解密/優(yōu)化 創(chuàng)建子文檔 文檔連接 圖像/字體提取 完全支持嵌入式文件 保存布局的文本提取(所有文檔)
2、安裝
PyMuPDF可以從源碼安裝,也可以從wheels安裝。Windows, Linux和Mac OSX平臺,在PyPI的下載部分有wheels。這包括Python 64位版本3.6到3.9。Windows版本也有32位版本。從最近開始,Linux ARM架構也出現(xiàn)了一些問題——查找平臺標簽manylinux2014_aarch64。Pillow:當使用Pixmap.pil_save()和Pixmap.pil_tobytes()時需要fontTools:當使用Document.subset_fonts()時需要pymupdf-fonts是一個不錯的字體選擇,可以用于文本輸出方法
pip安裝命令:pip install PyMuPDFimport?fitz
關于命名fitz的說明
Python導入語句是import fitz。這是有歷史原因的:MuPDF的原始渲染庫被稱為Libart。MuPDF項目后,開發(fā)的重點轉移到編寫一種新的現(xiàn)代圖形圖書館稱為“Fitz”。Fitz最初是作為一個研發(fā)項目,以取代老化的Ghostscript圖形庫,但卻成為了MuPDF的渲染引擎(引用自維基百科)。3、使用方法
1. 導入庫,查看版本
import?fitz
print(fitz.__doc__)
PyMuPDF?1.18.16:?Python?bindings?for?the?MuPDF?1.18.0?library.
Version?date:?2021-08-05?00:00:01.
Built?for?Python?3.8?on?linux?(64-bit).
2. 打開文檔
doc?=?fitz.open(filename)
Document對象doc。文件名必須是一個已經(jīng)存在的文件的python字符串。也可以從內存數(shù)據(jù)打開文檔,或創(chuàng)建新的空PDF。您還可以將文檔用作上下文管理器。3. Document的方法和屬性
>>>?doc.count_page
1
>>>?doc.metadata
{'format':?'PDF?1.7',
?'title':?'',
?'author':?'',
?'subject':?'',
?'keywords':?'',
?'creator':?'',
?'producer':?'福昕閱讀器PDF打印機?版本?10.0.130.3456',
?'creationDate':?"D:20210810173328+08'00'",
?'modDate':?"D:20210810173328+08'00'",
?'trapped':?'',
?'encryption':?None}
4. 獲取元數(shù)據(jù)
PyMuPDF完全支持標準元數(shù)據(jù)。Document.metadata是一個具有以下鍵的Python字典。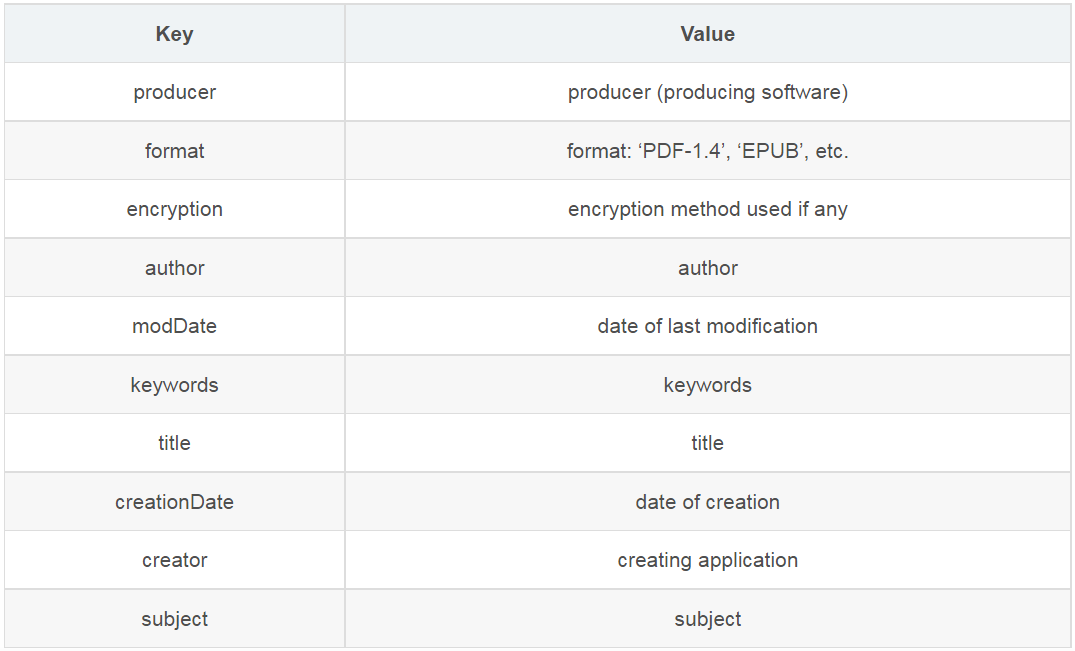
5. 獲取目標大綱
toc?=?doc.get_toc()
6. 頁面(Page)
MuPDF功能的核心。? 您可以將頁面呈現(xiàn)為光柵或矢量(
SVG)圖像,可以選擇縮放、旋轉、移動或剪切頁面。? 您可以提取多種格式的頁面文本和圖像,并搜索文本字符串。
? 對于
PDF文檔,可以使用更多的方法向頁面添加文本或圖像。Page。這是Document的一種方法:page?=?doc.load_page(pno)?#?loads?page?number?'pno'?of?the?document?(0-based)
page?=?doc[pno]?#?the?short?form
-inf。負數(shù)從末尾開始倒數(shù),所以doc[-1]是最后一頁,就像Python序列一樣。for?page?in?doc:
????#?do?something?with?'page'
????
#?...?or?read?backwards
for?page?in?reversed(doc):
????#?do?something?with?'page'
????
#?...?or?even?use?'slicing'
for?page?in?doc.pages(start,?stop,?step):
????#?do?something?with?'page'
接下來,主要介紹 Page的常用操作!
a. 檢查頁面的鏈接、批注或表單字段
#?get?all?links?on?a?page
links?=?page.get_links()
links是一個Python字典列表。for?link?in?page.links():
????#?do?something?with?'link'
Annot)或表單字段(Widget),每個字段都有自己的迭代器:for?annot?in?page.annots():
????#?do?something?with?'annot'
????
for?field?in?page.widgets():
????#?do?something?with?'field'
b. 呈現(xiàn)頁面
pix?=?page.get_pixmap()
pix是一個Pixmap對象,它(在本例中)包含頁面的RGB圖像,可用于多種用途。Page.get_pixmap()提供了許多用于控制圖像的變體:分辨率、顏色空間(例如,生成灰度圖像或具有減色方案的圖像)、透明度、旋轉、鏡像、移位、剪切等。pix=page.get_pixmap(alpha=True)。\Pixmap包含以下引用的許多方法和屬性。其中包括整數(shù)寬度、高度(每個像素)和跨距(一個水平圖像行的字節(jié)數(shù))。屬性示例表示表示圖像數(shù)據(jù)的矩形字節(jié)區(qū)域(Python字節(jié)對象)。page.get_svg_image()創(chuàng)建頁面的矢量圖像。c. 將頁面圖像保存到文件中
PNG文件中:pix.save("page-%i.png"?%?page.number)
d. 提取文本和圖像
text?=?page.get_text(opt)
opt使用以下字符串之一以獲取不同的格式:"text":(默認)帶換行符的純文本。無格式、無文字位置詳細信息、無圖像"blocks":生成文本塊(段落)的列表"words":生成單詞列表(不包含空格的字符串)"html":創(chuàng)建頁面的完整視覺版本,包括任何圖像。這可以通過internet瀏覽器顯示"dict"/"json":與HTML相同的信息級別,但作為Python字典或resp.JSON字符串。"rawdict"/"rawjson":"dict"/"json"的超級集合。它還提供諸如XML之類的字符詳細信息。"xhtml":文本信息級別與文本版本相同,但包含圖像。"xml":不包含圖像,但包含每個文本字符的完整位置和字體信息。使用XML模塊進行解釋。
e. 搜索文本
areas?=?page.search_for("mupdf")
“mupdf”(不區(qū)分大小寫)。您可以使用此信息來突出顯示這些區(qū)域(僅限PDF)或創(chuàng)建文檔的交叉引用。7. PDF操作
PDF是唯一可以使用PyMuPDF修改的文檔類型。其他文件類型是只讀的。PyMuPDF功能應用于轉換結果,Document.convert_to_pdf()。Document.save()始終將PDF以其當前(可能已修改)狀態(tài)存儲在磁盤上。a. 修改、創(chuàng)建、重新排列和刪除頁面
PDF:Document.delete_page()和Document.delete_pages()刪除頁面Document.copy_page()、Document.fullcopy_page()和Document.move_page()將頁面復制或移動到同一文檔中的其他位置。Document.select()將PDF壓縮到選定頁面,參數(shù)是要保留的頁碼序列。這些整數(shù)都必須在0<=i范圍內。執(zhí)行時,此列表中缺少的所有頁面都將被刪除。剩余的頁面將按順序出現(xiàn),次數(shù)相同(!)正如您所指定的那樣。因此,您可以輕松地使用創(chuàng)建新的PDF:
保存的新文檔將包含仍然有效的鏈接、注釋和書簽(i.a.w.指向所選頁面或某些外部資源)。
第一頁或最后10頁 僅奇數(shù)頁或偶數(shù)頁(用于雙面打印) 包含或不包含給定文本的頁 顛倒頁面順序 Document.insert_page()和Document.new_page()插入新頁面。
此外,頁面本身可以通過一系列方法進行修改(例如頁面旋轉、注釋和鏈接維護、文本和圖像插入)。
b. 連接和拆分PDF文檔
Document.insert_pdf()在不同的pdf文檔之間復制頁面。下面是一個簡單的joiner示例(doc1和doc2在PDF中打開):#?append?complete?doc2?to?the?end?of?doc1
doc1.insert_pdf(doc2)
doc2?=?fitz.open()?#?new?empty?PDF
doc2.insert_pdf(doc1,?to_page?=?9)?#?first?10?pages
doc2.insert_pdf(doc1,?from_page?=?len(doc1)?-?10)?#?last?10?pages
doc2.save("first-and-last-10.pdf")
c. 保存
Document.save()將始終以當前狀態(tài)保存文檔。incremental=True將更改寫回原始PDF。這個過程(通常)非常快,因為更改會附加到原始文件,而不會完全重寫它。d. 關閉
Document.close()方法實現(xiàn)。除了關閉基礎文件外,還將釋放與文檔關聯(lián)的緩沖區(qū)。來源:網(wǎng)絡
推薦閱讀:
太酷了!手把手教你用 Python 繪制桑基圖!| 用戶行為路徑分析
用 Python 批量提取 PDF 的圖片,并存儲到指定文件夾
用 Python 批量提取 PDF 的表格數(shù)據(jù),保存為 Excel
太強了!Python 開發(fā)桌面小工具,讓代碼替我們干重復的工作!
