
綜述:解決目標(biāo)檢測中的樣本不均衡問題
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)


極市導(dǎo)讀
?本文對(duì)目標(biāo)檢測中的樣本不均衡問題類別進(jìn)行了詳細(xì)敘述,介紹了包括OHEM、S-OHEM、Focal loss、GHM等在內(nèi)的幾種主要方法,并梳理了它們的思路和優(yōu)缺點(diǎn)。
本文主要介紹如何解決樣本不均衡問題。
當(dāng)前基于深度學(xué)習(xí)的目標(biāo)檢測主要包括:基于two-stage的目標(biāo)檢測和基于one-stage的目標(biāo)檢測。two-stage的目標(biāo)檢測框架一般檢測精度相對(duì)較高,但檢測速度慢;而one-stage的目標(biāo)檢測速度相對(duì)較快,但是檢測精度相對(duì)較低。one-stage的精度不如two-stage的精度,一個(gè)主要的原因是訓(xùn)練過程中樣本極度不均衡造成的。
定義
樣本不均衡問題:指在訓(xùn)練的時(shí)候各個(gè)類別的樣本數(shù)量不均衡,由于檢測算法各不相同,以及數(shù)據(jù)集之間的差異,可能會(huì)存在正負(fù)樣本、難易樣本、類別間樣本這3種不均衡問題。一般在目標(biāo)檢測任務(wù)框架中,保持正負(fù)樣本的比例為1:3(經(jīng)驗(yàn)值)。
樣本不平衡實(shí)際上是一種非常常見的現(xiàn)象。比如:在欺詐交易檢測,欺詐交易的訂單應(yīng)該是占總交易數(shù)量極少部分;工廠中產(chǎn)品質(zhì)量檢測問題,合格產(chǎn)品的數(shù)量應(yīng)該是遠(yuǎn)大于不合格產(chǎn)品的;信用卡的征信問題中往往就是正樣本居多。
目標(biāo)檢測任務(wù)中,樣本包括哪些類別
正樣本:標(biāo)簽區(qū)域內(nèi)的圖像區(qū)域,即目標(biāo)圖像塊
負(fù)樣本:標(biāo)簽區(qū)域以外的圖像區(qū)域,即圖像背景區(qū)域
易分正樣本:容易正確分類的正樣本,在實(shí)際訓(xùn)練過程中,該類占總體樣本的比重非常高,單個(gè)樣本的損失函數(shù)較小,但是累計(jì)的損失函數(shù)會(huì)主導(dǎo)損失函數(shù)
易分負(fù)樣本:容易正確分類的負(fù)樣本,在實(shí)際訓(xùn)練過程中,該類占的比重非常高,單個(gè)樣本的損失函數(shù)較小,但是累計(jì)的損失函數(shù)會(huì)主導(dǎo)損失函數(shù)
難分正樣本:錯(cuò)分成負(fù)樣本的正樣本,這部分樣本在訓(xùn)練過程中單個(gè)樣本的損失函數(shù)較高,但是該類占總體樣本的比例較小
難分負(fù)樣本:錯(cuò)分成正樣本的負(fù)樣本,這部分樣本在訓(xùn)練過程中單個(gè)樣本的損失函數(shù)教高,但是該類占總體樣本的比例教小
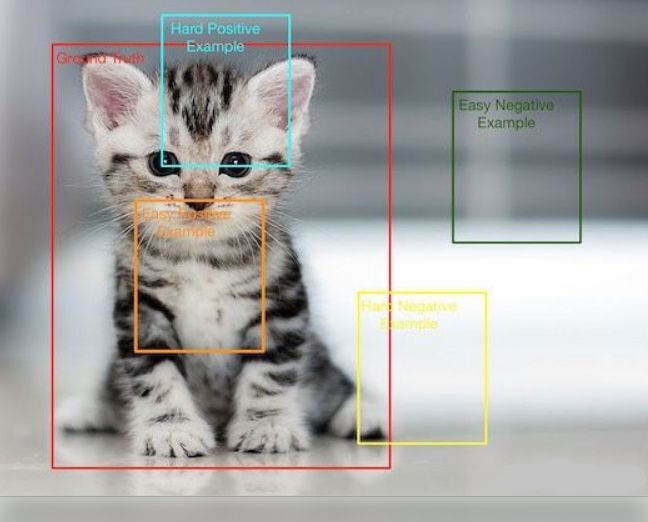
1.正負(fù)樣本不均衡
以Faster RCNN為例,在RPN部分會(huì)生成20000個(gè)左右的Anchor,由于一張圖中通常有10個(gè)左右的物體,導(dǎo)致可能只有100個(gè)左右的Anchor會(huì)是正樣本,正負(fù)樣本比例約為1∶200,存在嚴(yán)重的不均衡。
對(duì)于目標(biāo)檢測算法,主要需要關(guān)注的是對(duì)應(yīng)著真實(shí)物體的正樣本,在訓(xùn)練時(shí)會(huì)根據(jù)其loss來調(diào)整網(wǎng)絡(luò)參數(shù)。相比之下,負(fù)樣本對(duì)應(yīng)著圖像的背景,如果有大量的負(fù)樣本參與訓(xùn)練,則會(huì)淹沒正樣本的損失,從而降低網(wǎng)絡(luò)收斂的效率與檢測精度。
2.難易樣本不均衡
難樣本指的是分類不太明確的邊框,處在前景與背景的過渡區(qū)域上,在網(wǎng)絡(luò)訓(xùn)練中難樣本損失會(huì)較大,也是我們希望模型去學(xué)習(xí)優(yōu)化的樣本,利用這部分訓(xùn)練可以提升檢測的準(zhǔn)確率。
然而,大量的樣本并非處在前景與背景的過渡區(qū),而是與真實(shí)物體沒有重疊區(qū)域的負(fù)樣本,或者與真實(shí)物體重疊程度很高的正樣本,這部分被稱為簡單樣本,單個(gè)損失會(huì)較小,對(duì)參數(shù)收斂的作用有限。
雖然簡單樣本單個(gè)損失小,但由于數(shù)量眾多,因此如果全都計(jì)算損失的話,其損失也會(huì)比難樣本大很多,這種難易樣本的不均衡也會(huì)影響模型的收斂與精度。
值得注意的是,由于負(fù)樣本中大量的是簡單樣本,導(dǎo)致難易樣本與正負(fù)樣本這兩個(gè)不均衡問題有一定的重疊,解決方法往往能同時(shí)對(duì)這兩個(gè)問題起作用。
3.類別間樣本不均衡
在有些目標(biāo)檢測的數(shù)據(jù)集中,還會(huì)存在類別間的不均衡問題。舉個(gè)例子,數(shù)據(jù)集中有100萬個(gè)車輛、1000個(gè)行人的實(shí)例標(biāo)簽,樣本比例為1000∶1,屬于典型的類別不均衡。
這種情況下,如果不做任何處理,使用該數(shù)據(jù)集進(jìn)行訓(xùn)練,由于行人這一類別可參考標(biāo)簽太少,會(huì)使得模型主要關(guān)注車這一類別的檢測,網(wǎng)絡(luò)中的參數(shù)主要根據(jù)車輛的損失進(jìn)行優(yōu)化,導(dǎo)致行人的檢測精度大大下降。
目前,解決樣本不均衡問題的一些思路:
機(jī)器學(xué)習(xí)中,解決樣本不均衡問題主要有2種思路:數(shù)據(jù)角度和算法角度。從數(shù)據(jù)角度出發(fā),有擴(kuò)大數(shù)據(jù)集、數(shù)據(jù)類別均衡采樣等方法。在算法層面,目標(biāo)檢測方法使用的方法主要有:
Faster RCNN、SSD等算法在正負(fù)樣本的篩選時(shí),根據(jù)樣本與真實(shí)物體的IoU大小,設(shè)置了3∶1的正負(fù)樣本比例,這一點(diǎn)緩解了正負(fù)樣本的不均衡,同時(shí)也對(duì)難易樣本不均衡起到了作用。
Faster RCNN在RPN模塊中,通過前景得分排序篩選出了2000個(gè)左右的候選框,這也會(huì)將大量的負(fù)樣本與簡單樣本過濾掉,緩解了前兩個(gè)不均衡問題。
權(quán)重懲罰:對(duì)于難易樣本與類別間的不均衡,可以增大難樣本與少類別的損失權(quán)重,從而增大模型對(duì)這些樣本的懲罰,緩解不均衡問題。
數(shù)據(jù)增強(qiáng):從數(shù)據(jù)側(cè)入手,可以在當(dāng)前數(shù)據(jù)集上使用隨機(jī)生成和添加擾動(dòng)的方法,也可以利用網(wǎng)絡(luò)爬蟲數(shù)據(jù)等增加數(shù)據(jù)集的豐富性,從而緩解難易樣本和類別間樣本等不均衡問題,可以參考SSD的數(shù)據(jù)增強(qiáng)方法。
近年來,不少的研究者針對(duì)樣本不均衡問題進(jìn)行了深入研究,比較典型的有OHEM(在線困難樣本挖掘)、S-OHEM、Focal Loss、GHM(梯度均衡化)。下面將詳細(xì)介紹:
OHEM算法(online hard example miniing,發(fā)表于2016年的CVPR)主要是針對(duì)訓(xùn)練過程中的困難樣本自動(dòng)選擇,其核心思想是根據(jù)輸入樣本的損失進(jìn)行篩選,篩選出困難樣本(即對(duì)分類和檢測影響較大的樣本),然后將篩選得到的這些樣本應(yīng)用在隨機(jī)梯度下降中訓(xùn)練。
?
傳統(tǒng)的Fast RCNN系列算法在正負(fù)樣本選擇的時(shí)候采用當(dāng)前RoI與真實(shí)物體的IoU閾值比較的方法,這樣容易忽略一些較為重要的難負(fù)樣本,并且固定了正、負(fù)樣本的比例與最大數(shù)量,顯然不是最優(yōu)的選擇。以此為出發(fā)點(diǎn),OHEM將交替訓(xùn)練與SGD優(yōu)化方法進(jìn)行了結(jié)合,在每張圖片的RoI中選擇了較難的樣本,實(shí)現(xiàn)了在線的難樣本挖掘。
?
 ?
?
OHEM實(shí)現(xiàn)在線難樣本挖掘的網(wǎng)絡(luò)如上圖所示。圖中包含了兩個(gè)相同的RCNN網(wǎng)絡(luò),上半部的a部分是只可讀的網(wǎng)絡(luò),只進(jìn)行前向運(yùn)算;下半部的b網(wǎng)絡(luò)即可讀也可寫,需要完成前向計(jì)算與反向傳播。
?
在一個(gè)batch的訓(xùn)練中,基于Fast RCNN的OHEM算法可以分為以下5步:
(1)按照原始Fast RCNN算法,經(jīng)過卷積提取網(wǎng)絡(luò)與RoI Pooling得到了每一張圖像的RoI。
(2)上半部的a網(wǎng)絡(luò)對(duì)所有的RoI進(jìn)行前向計(jì)算,得到每一個(gè)RoI的損失。
(3)對(duì)RoI的損失進(jìn)行排序,進(jìn)行一步NMS操作,以去除掉重疊嚴(yán)重的RoI,并在篩選后的RoI中選擇出固定數(shù)量損失較大的部分,作為難樣本。
(4)將篩選出的難樣本輸入到可讀寫的b網(wǎng)絡(luò)中,進(jìn)行前向計(jì)算,得到損失。
(5)利用b網(wǎng)絡(luò)得到的反向傳播更新網(wǎng)絡(luò),并將更新后的參數(shù)與上半部的a網(wǎng)絡(luò)同步,完成一次迭代。
?
當(dāng)然,為了實(shí)現(xiàn)方便,OHEM的簡單實(shí)現(xiàn)可以是:在原有的Fast-RCNN里的loss layer里面對(duì)所有的props計(jì)算其loss,根據(jù)loss對(duì)其進(jìn)行排序,選出K個(gè)hard examples,反向傳播時(shí),只對(duì)這K個(gè)props的梯度/殘差回傳,而其他的props的梯度/殘差設(shè)為0。
但是,由于其特殊的損失計(jì)算方式,把簡單的樣本都舍棄了,導(dǎo)致模型無法提升對(duì)于簡單樣本的檢測精度,這也是OHEM方法的一個(gè)弊端。
?
優(yōu)點(diǎn):
1) 對(duì)于數(shù)據(jù)的類別不平衡問題不需要采用設(shè)置正負(fù)樣本比例的方式來解決,這種在線選擇方式針對(duì)性更強(qiáng);
2) 隨著數(shù)據(jù)集的增大,算法的提升更加明顯;
?
缺點(diǎn):
只保留loss較高的樣本,完全忽略簡單的樣本,這本質(zhì)上是改變了訓(xùn)練時(shí)的輸入分布(僅包含困難樣本),這會(huì)導(dǎo)致模型在學(xué)習(xí)的時(shí)候失去對(duì)簡單樣本的判別能力。
在OHEM中定義的多任務(wù)損失函數(shù)(包括分類損失? ?和定位損失?
?和定位損失? ?),在整個(gè)訓(xùn)練過程中各類損失具有相同的權(quán)重,這種方法忽略了訓(xùn)練過程中不同損失類型的影響,例如在訓(xùn)練期的后期,定位損失更為重要,因此OHEM缺乏對(duì)定位精度的足夠關(guān)注。
?),在整個(gè)訓(xùn)練過程中各類損失具有相同的權(quán)重,這種方法忽略了訓(xùn)練過程中不同損失類型的影響,例如在訓(xùn)練期的后期,定位損失更為重要,因此OHEM缺乏對(duì)定位精度的足夠關(guān)注。
S-OHEM算法采用了分層抽樣的方法,根據(jù)loss的分布抽樣訓(xùn)練樣本。它的做法是:
首先將預(yù)設(shè)loss的四個(gè)分段:?

給定一個(gè)batch,先生成輸入batch中所有圖像的候選RoI,再將這些RoI送入到Read only RoI網(wǎng)絡(luò)得到RoIs的損失,然后將每個(gè)RoI計(jì)算損失并劃分到上面四個(gè)分段中,然后針對(duì)每個(gè)分段,通過排序篩選困難樣本.再將經(jīng)過篩選的RoIs送入反向傳播,用于更新網(wǎng)絡(luò)參數(shù)。
網(wǎng)絡(luò)中損失是一個(gè)組合,具體公式為? ?,?
?,? ?隨著訓(xùn)練階段變化而變化)之所以采用這個(gè)公式是因?yàn)?/span>在訓(xùn)練初期階段,分類損失占主導(dǎo)作用;在訓(xùn)練后期階段,邊框回歸損失函數(shù)占主導(dǎo)作用。
?隨著訓(xùn)練階段變化而變化)之所以采用這個(gè)公式是因?yàn)?/span>在訓(xùn)練初期階段,分類損失占主導(dǎo)作用;在訓(xùn)練后期階段,邊框回歸損失函數(shù)占主導(dǎo)作用。
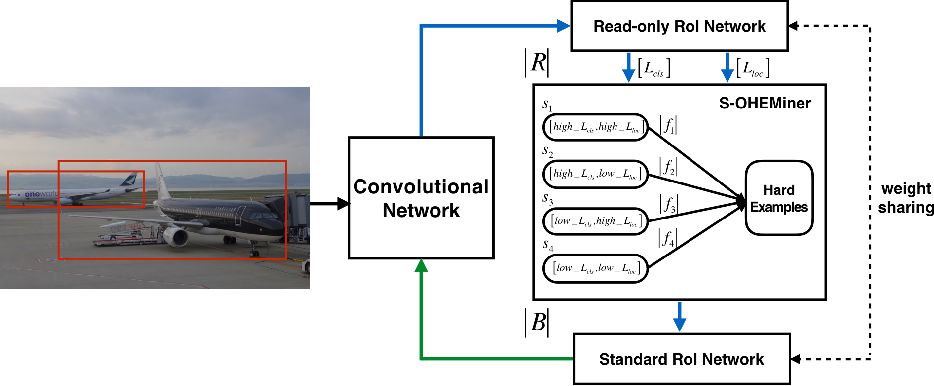
S-OHEM是基于OHEM的改進(jìn),如上圖所示。網(wǎng)絡(luò)分成兩個(gè)部分:ConvNet和RoINet。RoINet又可看成兩部分:Read-only RoI Network和Standard RoI Network。圖中R表示向前傳播的RoI的數(shù)量,B表示被饋送到反向傳播的子采樣的RoI的數(shù)量。S-OHEMiner根據(jù)當(dāng)前訓(xùn)練階段的采樣分布對(duì)region proposals進(jìn)行抽樣。Read-only RoI Network只有forward操作,Standard RoI Network包括forward和backward操作,以hard example作為輸入,計(jì)算損失并回傳梯度。
RoINet的兩部分共享權(quán)重,可實(shí)現(xiàn)高效地分配內(nèi)存。在圖中,藍(lán)色箭頭表示向前傳播的過程,綠色箭頭表示反向傳播過程。
優(yōu)點(diǎn):
相比原生OHEM,S-OHEM考慮了基于不同損失函數(shù)的分布來抽樣選擇困難樣本,避免了僅使用高損失的樣本來更新模型參數(shù)。
缺點(diǎn):
因?yàn)椴煌A段,分類損失和定位損失的貢獻(xiàn)不同,所以選擇損失中的兩個(gè)參數(shù)??需要根據(jù)不同訓(xùn)練階段進(jìn)行改變,當(dāng)應(yīng)用與不同數(shù)據(jù)集時(shí),參數(shù)的選取也是不一樣的。即引入了額外的超參數(shù)。
當(dāng)前一階的物體檢測算法,如SSD和YOLO等雖然實(shí)現(xiàn)了實(shí)時(shí)的速度,但精度始終無法與兩階的Faster RCNN相比。是什么阻礙了一階算法的高精度呢?何凱明等人將其歸咎于正、負(fù)樣本的不均衡,并基于此提出了新的損失函數(shù)Focal Loss及網(wǎng)絡(luò)結(jié)構(gòu)RetinaNet,在與同期一階網(wǎng)絡(luò)速度相同的前提下,其檢測精度比同期最優(yōu)的二階網(wǎng)絡(luò)還要高。
對(duì)于SSD等一階網(wǎng)絡(luò),由于其需要直接從所有的預(yù)選框中進(jìn)行篩選,即使使用了固定正、負(fù)樣本比例的方法,仍然效率低下,簡單的負(fù)樣本仍然占據(jù)主要地位,導(dǎo)致其精度不如兩階網(wǎng)絡(luò)。為了解決一階網(wǎng)絡(luò)中樣本的不均衡問題,何凱明等人首先改善了分類過程中的交叉熵函數(shù),提出了可以動(dòng)態(tài)調(diào)整權(quán)重的Focal Loss。
1.標(biāo)準(zhǔn)交叉熵?fù)p失
首先回顧一下標(biāo)準(zhǔn)的交叉熵(Cross Entropy, CE)函數(shù),其形式如下式所示。

公式中,p代表樣本在該類別的預(yù)測概率,y代表樣本標(biāo)簽。可以看出,當(dāng)標(biāo)簽為1時(shí),p越接近1,則損失越小;標(biāo)簽為0時(shí)p越接近0,則損失越小,符合優(yōu)化的方向。
為了方便表示,按照上式將p標(biāo)記為pt:

則交叉熵可以表示為下式的形式:
![]()
可以看出,標(biāo)準(zhǔn)的交叉熵中所有樣本的權(quán)重都是相同的,因此如果正、負(fù)樣本不均衡,大量簡單的負(fù)樣本會(huì)占據(jù)主導(dǎo)地位,少量的難樣本與正樣本會(huì)起不到作用,導(dǎo)致精度變差。
2.平衡交叉熵?fù)p失
為了改善樣本的不平衡問題,平衡交叉熵在標(biāo)準(zhǔn)的基礎(chǔ)上增加了一個(gè)系數(shù)αt來平衡正、負(fù)樣本的權(quán)重,αt由超參α按照下式計(jì)算得來,α取值在[0,1]區(qū)間內(nèi)。

有了αt,平衡交叉熵?fù)p失公式如下式所示。
![]()
盡管平衡交叉熵?fù)p失改善了正、負(fù)樣本間的不平衡,但由于其缺乏對(duì)難易樣本的區(qū)分,因此沒有辦法控制難易樣本之間的不均衡。
3. 專注難樣本Focal loss
Focal Loss為了同時(shí)調(diào)節(jié)正、負(fù)樣本與難易樣本,提出了如下所示的損失函數(shù)。
![]()
其中? ?用于控制正負(fù)樣本的權(quán)重,當(dāng)其取比較小的值來降低負(fù)樣本(多的那類樣本)的權(quán)重;?
?用于控制正負(fù)樣本的權(quán)重,當(dāng)其取比較小的值來降低負(fù)樣本(多的那類樣本)的權(quán)重;? ?用于控制難易樣本的權(quán)重,目的是通過減少易分樣本的權(quán)重,從而使得模型在訓(xùn)練的時(shí)候更加專注難分樣本的學(xué)習(xí)。文中通過批量實(shí)驗(yàn)統(tǒng)計(jì)得到當(dāng)?
?用于控制難易樣本的權(quán)重,目的是通過減少易分樣本的權(quán)重,從而使得模型在訓(xùn)練的時(shí)候更加專注難分樣本的學(xué)習(xí)。文中通過批量實(shí)驗(yàn)統(tǒng)計(jì)得到當(dāng)? ?時(shí)效果最好。
?時(shí)效果最好。
可以看出,對(duì)于Focal loss損失函數(shù),有如下3個(gè)屬性:
與平衡交叉熵類似,引入了αt權(quán)重,為了改善正負(fù)樣本的不均衡,可以提升一些精度。
- 是為了調(diào)節(jié)難易樣本的權(quán)重。當(dāng)一個(gè)邊框被誤分類時(shí),pt較小,則接近于1,其損失幾乎不受影響;當(dāng)pt接近于1時(shí),表明其分類預(yù)測較好,是簡單樣本,接近于0,因此其損失被調(diào)低了。
γ是一個(gè)調(diào)制因子,γ越大,簡單樣本損失的貢獻(xiàn)會(huì)越低。
為了驗(yàn)證Focal Loss的效果,何凱明等人還提出了一個(gè)一階物體檢測結(jié)構(gòu)RetinaNet,其結(jié)構(gòu)如下圖所示。

對(duì)于RetinaNet的網(wǎng)絡(luò)結(jié)構(gòu),有以下5個(gè)細(xì)節(jié):
(1)在Backbone部分,RetinaNet利用ResNet與FPN構(gòu)建了一個(gè)多尺度特征的特征金字塔。
(2)RetinaNet使用了類似于Anchor的預(yù)選框,在每一個(gè)金字塔層,使用了9個(gè)大小不同的預(yù)選框。
(3)分類子網(wǎng)絡(luò):分類子網(wǎng)絡(luò)為每一個(gè)預(yù)選框預(yù)測其類別,因此其輸出特征大小為KA×W×H, A默認(rèn)為9, K代表類別數(shù)。中間使用全卷積網(wǎng)絡(luò)與ReLU激活函數(shù),最后利用Sigmoid函數(shù)輸出預(yù)測值。
(4)回歸子網(wǎng)絡(luò):回歸子網(wǎng)絡(luò)與分類子網(wǎng)絡(luò)平行,預(yù)測每一個(gè)預(yù)選框的偏移量,最終輸出特征大小為4A×W×W。與當(dāng)前主流工作不同的是,兩個(gè)子網(wǎng)絡(luò)沒有權(quán)重的共享。
(5)Focal Loss:與OHEM等方法不同,F(xiàn)ocal Loss在訓(xùn)練時(shí)作用到所有的預(yù)選框上。對(duì)于兩個(gè)超參數(shù),通常來講,當(dāng)γ增大時(shí),α應(yīng)當(dāng)適當(dāng)減小。實(shí)驗(yàn)中γ取2、α取0.25時(shí)效果最好。
論文地址:
https://arxiv.org/pdf/1811.05181.pdf
代碼地址:
https://github.com/libuyu/GHM_Detection
前面講到的OHEM算法和Focal loss各有利弊:
1、OHEM算法會(huì)丟棄loss比較低的樣本,使得這些樣本無法被學(xué)習(xí)到。
2、FocalLoss則是對(duì)正負(fù)樣本進(jìn)行加權(quán),使得全部的樣本可以得到學(xué)習(xí),容易分類的負(fù)樣本賦予低權(quán)值,hard examples賦予高權(quán)值。但是在所有的anchor examples中,出了大量的易分類的負(fù)樣本外,還存在很多的outlier,F(xiàn)ocalLoss對(duì)這些outlier并沒有相關(guān)策略處理。并且FocalLoss存在兩個(gè)超參,根據(jù)不同的數(shù)據(jù)集,調(diào)試兩個(gè)超參需要大量的實(shí)驗(yàn),一旦確定參數(shù)無法改變,不能根據(jù)數(shù)據(jù)的分布動(dòng)態(tài)的調(diào)整。
GHM主要思想
GHM做法則是從樣本的梯度范數(shù)出發(fā),通過梯度范數(shù)所占的樣本比例,對(duì)樣本進(jìn)行動(dòng)態(tài)的加權(quán),使得具有小梯度的容易分類的樣本降權(quán),具有中梯度的hard expamle升權(quán),具有大梯度的outlier降權(quán)。
損失函數(shù)的權(quán)重(梯度密度的倒數(shù))?
就是把梯度幅值范圍(X軸)劃分為M個(gè)區(qū)域,對(duì)于落在每個(gè)區(qū)域樣本的權(quán)重采取相同的修正方式,類似于直方圖。具體推導(dǎo)公式如下所示。
X軸的梯度分為M個(gè)區(qū)域,每個(gè)區(qū)域長度即為 ,第j個(gè)區(qū)域范圍即為? ?,用?
?,用? ?表示落在第j個(gè)區(qū)域內(nèi)的樣本數(shù)量。定義ind(g)表示梯度為g的樣本所落區(qū)域的序號(hào),那么即可得出新的參數(shù)?
?表示落在第j個(gè)區(qū)域內(nèi)的樣本數(shù)量。定義ind(g)表示梯度為g的樣本所落區(qū)域的序號(hào),那么即可得出新的參數(shù)? ?。由于樣本的梯度密度是訓(xùn)練時(shí)根據(jù)batch計(jì)算出來的,通常情況下batch較小,直接計(jì)算出來的梯度密度可能不穩(wěn)定,所以采用滑動(dòng)平均的方式處理梯度計(jì)算。
?。由于樣本的梯度密度是訓(xùn)練時(shí)根據(jù)batch計(jì)算出來的,通常情況下batch較小,直接計(jì)算出來的梯度密度可能不穩(wěn)定,所以采用滑動(dòng)平均的方式處理梯度計(jì)算。
?


這里注意M的選取。當(dāng)M太小的時(shí)候,不同梯度模上的密度不具備較好的方差;當(dāng)然M也不能太大,因?yàn)镸過大的時(shí)候,受限于GPU限制,batch size一般都比較小,此時(shí)如果M太大的話,會(huì)導(dǎo)致每次統(tǒng)計(jì)過于稀疏(分的太細(xì)了),異常值對(duì)小區(qū)間的影響較大,導(dǎo)致訓(xùn)練不穩(wěn)定。論文根據(jù)實(shí)驗(yàn)統(tǒng)計(jì),M取30為最佳。
GHM-C分類損失函數(shù)?
對(duì)于分類損失函數(shù),這里采用的是交叉熵函數(shù),梯度密度中的梯度模長是基于交叉熵函數(shù)的導(dǎo)數(shù)進(jìn)行計(jì)算的,GHM-C公式如下:
根據(jù)GHM-C的計(jì)算公式可以看出,候選樣本的中的簡單負(fù)樣本和非常困難的異常樣本(離群點(diǎn))的權(quán)重都會(huì)被降低,即loss會(huì)被降低,對(duì)于模型訓(xùn)練的影響也會(huì)被大大減少,正常困難樣本的權(quán)重得到提升,這樣模型就會(huì)更加專注于那些更有效的正常困難樣本,以提升模型的性能。
GHM-R邊框回歸損失函數(shù)?
對(duì)于回歸損失函數(shù),由于原生的Smooth L1損失函數(shù)的導(dǎo)數(shù)為1時(shí),樣本之間就沒有難易區(qū)分度了,這樣的統(tǒng)計(jì)明顯不合理.論文修改了損失函數(shù)? ?,梯度密度中的梯度模長是基于修改后的損失函數(shù)ASL1的導(dǎo)數(shù)進(jìn)行計(jì)算的,GHM-R公式如下:
?,梯度密度中的梯度模長是基于修改后的損失函數(shù)ASL1的導(dǎo)數(shù)進(jìn)行計(jì)算的,GHM-R公式如下:
因?yàn)镚HM-C和GHM-R是定義的損失函數(shù),因此可以非常方便的嵌入到很多目標(biāo)檢測方法中,論文作者以focal loss(大概是以RetinaNet作為baseline),對(duì)交叉熵,focal loss和GHM-C做了對(duì)比,發(fā)現(xiàn)GHM-C在focal loss 的基礎(chǔ)上在AP上提升了0.2個(gè)百分點(diǎn)。
具體細(xì)節(jié)可參考論文原文《Gradient Harmonized Single-stage Detector》。
OHEM系列的困難樣本挖掘方法在當(dāng)前的目標(biāo)檢測框架上還是被大量地使用,在一些文本檢測方法中還是被經(jīng)常使用;
OHEM是針對(duì)現(xiàn)有樣本并根據(jù)損失loss進(jìn)行困難樣本挖掘,F(xiàn)ocal Loss和GHM則從損失函數(shù)本身進(jìn)行困難樣本挖掘;
相比Focal loss,GHM是一個(gè)動(dòng)態(tài)的損失函數(shù),即隨著不同數(shù)據(jù)的分布進(jìn)行變換,不需要額外的超參數(shù)調(diào)整(但是這里其實(shí)還是會(huì)涉及到一個(gè)參數(shù),就是Unit region的數(shù)量);此外GHM在降低易分樣本權(quán)重的同時(shí),對(duì)outliner也會(huì)有一定程度的降權(quán);
無論是Focal Loss,還是基于GHM的損失函數(shù)都可以嵌入到現(xiàn)有的目標(biāo)檢測框架中;Focal Loss只針對(duì)分類損失,而GHM對(duì)分類損失和邊框損失都可以;
GHM方法在源碼實(shí)現(xiàn)上,作者采用平均滑動(dòng)的方式來計(jì)算梯度密度,不過與論文中有一個(gè)區(qū)別是在計(jì)算梯度密度的時(shí)候,沒有乘以M,而是乘以有效的(也就是說有梯度信息的區(qū)間)bin個(gè)數(shù);
之前嘗試過Focal Loss用于多分類任務(wù)中,發(fā)現(xiàn)在精度并沒有提升;但是我試過將訓(xùn)練數(shù)據(jù)按照訓(xùn)練數(shù)據(jù)的原始分布并將其引入到交叉熵函數(shù)中,準(zhǔn)確率提升了;GHM方法的本質(zhì)也是在改變訓(xùn)練數(shù)據(jù)的分布(將難易樣本拉勻),但是到底什么的數(shù)據(jù)分布是最優(yōu)的,目前尚未定論。
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~