
如何解決文本分類中的樣本不均衡問題
大家好,我是躺平的 DASOU.
文本分類不平衡問題是工作中常常遇見的一個(gè)問題;我之前針對(duì)這個(gè)問題,寫了一個(gè)自己的實(shí)踐總結(jié),感興趣的朋友見看這里:真實(shí)場(chǎng)景下如何解決類別不平衡問題;
另外關(guān)于這個(gè)問題刷到一個(gè)不錯(cuò)的文章,分享給大家,希望有所幫助;
正文如下:
摘要:本篇主要從理論到實(shí)踐解決文本分類中的樣本不均衡問題。首先講了下什么是樣本不均衡現(xiàn)象以及可能帶來的問題;然后重點(diǎn)從數(shù)據(jù)層面和模型層面講解樣本不均衡問題的解決策略。數(shù)據(jù)層面主要通過欠采樣和過采樣的方式來人為調(diào)節(jié)正負(fù)樣本比例,模型層面主要是通過加權(quán)Loss,包括基于類別Loss、Focal Loss和GHM Loss三種加權(quán)Loss函數(shù);最后講了下其他解決樣本不均衡的策略,可以通過調(diào)節(jié)閾值修改正負(fù)樣本比例和利用半監(jiān)督或自監(jiān)督學(xué)習(xí)解決樣本不均衡問題。需要說明下上面解決樣本不均衡問題的策略不僅僅適用于文本分類任務(wù),還可以擴(kuò)展到其他的機(jī)器學(xué)習(xí)任務(wù)中。對(duì)于希望解決樣本不均衡問題的小伙伴可能有所幫助。
下面主要按照如下思維導(dǎo)圖進(jìn)行學(xué)習(xí)分享:

01 機(jī)器學(xué)習(xí)中的樣本不均衡問題
1.1 什么是樣本不均衡現(xiàn)象
機(jī)器學(xué)習(xí)領(lǐng)域中樣本不均衡現(xiàn)象隨處可見。咱們舉一些例子說明,圖片分類任務(wù)中假如我們要做貓狗圖片的識(shí)別任務(wù),因?yàn)樨埞吩谌粘I钪须S處可見,所以對(duì)應(yīng)的樣本貓和狗的圖片很好找,樣本比較均衡,咱們能很容易的得到1W張貓的圖片和1W張狗的圖片。但是如果我們現(xiàn)在做狗和狼圖片識(shí)別任務(wù),那情況就有些變化了。我們還是能方便的得到1W張狗的圖片,但是狼因?yàn)樵谏钪胁辉趺闯R姡栽谕瑯拥臄?shù)據(jù)采集成本下我們可能只得到100張甚至更少的狼的圖片。
還有比如CTR任務(wù)中我們需要預(yù)測(cè)用戶是否會(huì)對(duì)廣告進(jìn)行點(diǎn)擊,通常情況下曝光一個(gè)廣告用戶點(diǎn)擊的比率非常低,這里我們假如給101個(gè)用戶曝光廣告可能只有一個(gè)人點(diǎn)擊,那么得到的正負(fù)樣本比例就為1:100。如果是更高層級(jí)的廣告轉(zhuǎn)化目標(biāo)比如下載、付費(fèi)等正負(fù)樣本的比例就更低了。
同樣的例子會(huì)出現(xiàn)在文本分類任務(wù)中,假如我們要做一個(gè)識(shí)別是否對(duì)傳奇游戲標(biāo)簽感興趣的文本二分類器,用戶搜索中這部分的比例非常少,也許1W條用戶搜索query中只有50條甚至更少的樣本屬于正例。這種現(xiàn)象就是樣本不均衡,因?yàn)闃颖緯?huì)呈現(xiàn)一個(gè)長(zhǎng)尾分布,頭部的標(biāo)簽包含了大量的樣本,而尾部的標(biāo)簽擁有很少的樣本,就像下面這張圖片中表現(xiàn)的那樣出現(xiàn)一個(gè)長(zhǎng)長(zhǎng)的尾巴,所以這種現(xiàn)場(chǎng)也稱為長(zhǎng)尾現(xiàn)象。

圖1 長(zhǎng)尾現(xiàn)象
1.2 樣本不均衡可能帶來的問題
上面講了樣本不均衡的現(xiàn)象在機(jī)器學(xué)習(xí)場(chǎng)景中經(jīng)常出現(xiàn),那么樣本不均衡會(huì)帶來什么問題呢?眾所周知模型訓(xùn)練的本質(zhì)是最小化損失函數(shù),當(dāng)某個(gè)類別的樣本數(shù)量非常龐大,損失函數(shù)的值大部分被樣本數(shù)量較大的類別所影響,導(dǎo)致的結(jié)果就是模型分類會(huì)傾向于樣本量較大的類別。咱們拿上面文本分類的例子來說明,現(xiàn)在有1W條用戶搜索的樣本,其中50條和傳奇游戲標(biāo)簽有關(guān),9950條和傳奇游戲標(biāo)簽無(wú)關(guān),那么模型全部將樣本預(yù)測(cè)為負(fù)例,也能得到99.5%的準(zhǔn)確率,會(huì)讓人有一種模型效果還不錯(cuò)的假象,但是實(shí)際的情況是這個(gè)模型根本沒什么卵用,因?yàn)槲覀兊哪繕?biāo)是識(shí)別出這些數(shù)量較少的類別。這也是我們?cè)趯?shí)際業(yè)務(wù)場(chǎng)景中遇到的問題。
總體來看,解決樣本不均衡的問題主要從數(shù)據(jù)層面和模型層面來解決,下面會(huì)分別從理論到實(shí)踐的角度分享樣本不均衡問題的解決策略。
02 從數(shù)據(jù)層面解決樣本不均衡問題
現(xiàn)在我們遇到樣本不均衡的問題,假如我們的正樣本只有100條,而負(fù)樣本可能有1W條。如果不采取任何策略,那么我們就是使用這1.01W條樣本去訓(xùn)練模型。從數(shù)據(jù)層面解決樣本不均衡的問題核心是通過人為控制正負(fù)樣本的比例,分成欠采樣和過采樣兩種。
2.1 欠采樣
欠采樣的基本做法是這樣的,現(xiàn)在我們的正負(fù)樣本比例為1:100。如果我們想讓正負(fù)樣本比例不超過1:10,那么模型訓(xùn)練的時(shí)候數(shù)量比較少的正樣本也就是100條全部使用,而負(fù)樣本隨機(jī)挑選1000條,這樣通過人為的方式我們把樣本的正負(fù)比例強(qiáng)行控制在了1:10。這種方式存在一個(gè)問題,為了強(qiáng)行控制樣本比例我們生生的舍去了那9000條負(fù)樣本,這對(duì)于模型來說是莫大的損失。
相比于簡(jiǎn)單的對(duì)負(fù)樣本隨機(jī)采樣的欠采樣方法,實(shí)際工作中我們會(huì)使用迭代預(yù)分類的方式來采樣負(fù)樣本。具體流程如下圖所示:
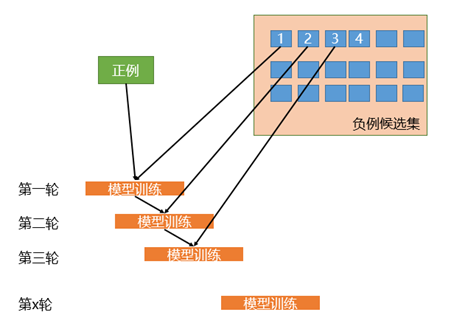
圖2 迭代預(yù)分類方式的欠采樣
首先我們會(huì)使用全部的正樣本和從負(fù)例候選集中隨機(jī)采樣一部分負(fù)樣本(這里假如是100條)去訓(xùn)練第一輪分類器;然后用第一輪分類器去預(yù)測(cè)負(fù)例候選集剩余的9900條數(shù)據(jù),把9900條負(fù)例中預(yù)測(cè)為正例的樣本(也就是預(yù)測(cè)錯(cuò)誤的樣本)再隨機(jī)采樣100條和第一輪訓(xùn)練的數(shù)據(jù)放到一起去訓(xùn)練第二輪分類器;同樣的方法用第二輪分類器去預(yù)測(cè)負(fù)例候選集剩余的9800條數(shù)據(jù),直到訓(xùn)練的第N輪分類器可以全部識(shí)別負(fù)例候選集,這就是使用迭代預(yù)分類的方式進(jìn)行欠采樣。
相比于隨機(jī)欠采樣來說迭代預(yù)分類的欠采樣方式能最大限度的利用負(fù)樣本中差異性較大的負(fù)樣本,從而在控制正負(fù)樣本比例的基礎(chǔ)上采樣出了最有代表意義的負(fù)樣本。
欠采樣的方式整體來說或多或少的會(huì)損失一些樣本,對(duì)于那些需要控制樣本量級(jí)的場(chǎng)景下比較合適。如果沒有嚴(yán)格控制樣本量級(jí)的要求那么下面的過采樣可能會(huì)更加適合你。
2.2 過采樣
過采樣和上面的欠采樣比較類似,都是人工干預(yù)控制樣本的比例,不同的是過采樣不會(huì)損失樣本。還拿上面的例子,現(xiàn)在有正樣本100條,負(fù)樣本1W條,最簡(jiǎn)單的過采樣方式是我們會(huì)使用全部的負(fù)樣本1W條,但是為了維持正負(fù)樣本比例,我們會(huì)從正樣本中有放回的重復(fù)采樣,直到獲取了1000條正樣本,也就是說有些正樣本可能會(huì)被重復(fù)采樣到,這樣就能保持1:10的正負(fù)樣本比例了。這是最簡(jiǎn)單的過采樣方式。
之前組里的小伙伴分享了基于SMOTE算法的過采樣方式,感興趣的小伙伴們可以關(guān)注下。在文本分類場(chǎng)景中我們主要通過樣本增強(qiáng)技術(shù)來實(shí)現(xiàn)過采樣。之前分享過一篇關(guān)于樣本增強(qiáng)技術(shù)的文章《廣告行業(yè)中那些趣事系列13:NLP中超實(shí)用的樣本增強(qiáng)技術(shù)》,里面包含了回譯技術(shù)、替換技術(shù)、隨機(jī)噪聲引入技術(shù)等方法可以實(shí)現(xiàn)樣本增強(qiáng),通過這種方式可以增加正樣本,并且使得增加的正樣本不僅僅是簡(jiǎn)單的重復(fù)樣本,而是有細(xì)微差異的正樣本,這里不再贅述。因?yàn)橹斑€沒接觸過文本生成,所以介紹的方法里通過文本生成來增強(qiáng)樣本的部分比較少。最近參加了公司的比賽,了解了一些文本生成的技術(shù),增加點(diǎn)這段時(shí)間學(xué)到的通過文本生成的角度來實(shí)現(xiàn)文本增強(qiáng)的知識(shí)和大家分享下。
從文本生成的角度來增加正樣本從而間接的使用過采樣的方式來控制正負(fù)樣本比例主要嘗試過基于BERT的有條件生成任務(wù)和基于SIMBERT來生成相似文本任務(wù):
(1) 基于BERT的有條件生成文本
基于BERT的有條件生成任務(wù)主要是利用微軟提供的UNILM來將BERT改造成可以處理Seq2Seq的任務(wù),從而完成文本生成任務(wù)。下面是我用廣告文案語(yǔ)料微調(diào)BERT從而生成的部分標(biāo)簽的文案的結(jié)果數(shù)據(jù):

圖3 基于BERT的有條件生成任務(wù)部分結(jié)果
從上圖中可以發(fā)現(xiàn)生成的文本其實(shí)和我們使用的文案語(yǔ)料很相似,但是又不完全相同。模型通過微調(diào)訓(xùn)練語(yǔ)料學(xué)習(xí)到了各個(gè)標(biāo)簽的知識(shí),然后運(yùn)用這些知識(shí)生成了相似的文案,這些文案雖然只有部分修改,但是語(yǔ)義是比較合理的,所以生成的結(jié)果也比較合理。這塊使用的是蘇劍林的bert4keras中的例子,有興趣的小伙伴可以自己跑來玩一下:
https://github.com/bojone/bert4keras/blob/2accce143a9b7b6164a1a3a1a38507fc03788ec9/examples/task_conditional_language_model.py
(2) 基于SIMBERT生成相似文本
基于SIMBERT生成相似文本的方法是另外一種文本生成的方式,主要原理是生成和當(dāng)前query比較相似的文本從而達(dá)到樣本增強(qiáng)的目的。下面是我們使用SIMBERT來生成相似文本的結(jié)果:

圖4 使用SIMBERT生成相似文本
上圖中我們輸入的初始文本是“想開一家奶茶店,需要多少的預(yù)算?”,然后下面就是自動(dòng)生成的相似的文本。可以發(fā)現(xiàn)生成的結(jié)果還不賴,整體語(yǔ)義一致,而文本的形式會(huì)有些許不同,從而達(dá)到了樣本增強(qiáng)的目的。這塊使用的也是蘇劍林的bert4keras中的例子,感興趣的小伙伴可以去試試:
https://github.com/bojone/bert4keras/blob/2accce143a9b7b6164a1a3a1a38507fc03788ec9/examples/basic_simple_web_serving_simbert.py
03 從模型層面解決樣本不均衡問題
上面主要從數(shù)據(jù)的層面來解決樣本不均衡的問題,本節(jié)主要從模型層面解決樣本不均衡的問題。相比于控制正負(fù)樣本的比例,我們還可以通過控制Loss損失函數(shù)來解決樣本不均衡的問題。拿二分類任務(wù)來舉例,通常使用交叉熵來計(jì)算損失,下面是交叉熵的公式:
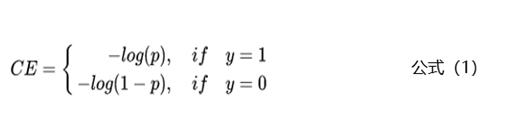
上面的公式中y是樣本的標(biāo)簽,p是樣本預(yù)測(cè)為正例的概率。
3.1 類別加權(quán)Loss
為了解決樣本不均衡的問題,最簡(jiǎn)單的是基于類別的加權(quán)Loss,具體公式如下:

基于類別加權(quán)的Loss其實(shí)就是添加了一個(gè)參數(shù)a,這個(gè)a主要用來控制正負(fù)樣本對(duì)Loss帶來不同的縮放效果,一般和樣本數(shù)量成反比。還拿上面的例子舉例,有100條正樣本和1W條負(fù)樣本,那么我們?cè)O(shè)置a的值為10000/10100,那么正樣本對(duì)Loss的貢獻(xiàn)值會(huì)乘以一個(gè)系數(shù)10000/10100,而負(fù)樣本對(duì)Loss的貢獻(xiàn)值則會(huì)乘以一個(gè)比較小的系數(shù)100/10100,這樣相當(dāng)于控制模型更加關(guān)注正樣本對(duì)損失函數(shù)的影響。通過這種基于類別的加權(quán)的方式可以從不同類別的樣本數(shù)量角度來控制Loss值,從而一定程度上解決了樣本不均衡的問題。
3.2 Focal Loss
上面基于類別加權(quán)Loss雖然在一定程度上解決了樣本不均衡的問題,但是實(shí)際的情況是不僅樣本不均衡會(huì)影響Loss,而且樣本的難易區(qū)分程度也會(huì)影響Loss。基于這個(gè)問題2017年何愷明大神在論文《Focal Loss for Dense Object Detection》中提出了非常火的Focal Loss,下面是Focal Loss的計(jì)算公式:
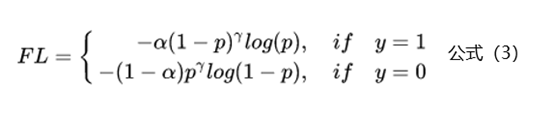
相比于公式2來說,F(xiàn)ocal Loss添加了參數(shù)γ從置信的角度來加權(quán)Loss值。假如γ設(shè)置為0,那么公式3蛻變成了基于類別的加權(quán)也就是公式2;下面重點(diǎn)看看如何通過設(shè)置參數(shù)r來使得簡(jiǎn)單和困難樣本對(duì)Loss的影響。當(dāng)γ設(shè)置為2時(shí),對(duì)于模型預(yù)測(cè)為正例的樣本也就是p>0.5的樣本來說,如果樣本越容易區(qū)分那么(1-p)的部分就會(huì)越小,相當(dāng)于乘了一個(gè)系數(shù)很小的值使得Loss被縮小,也就是說對(duì)于那些比較容易區(qū)分的樣本Loss會(huì)被抑制,同理對(duì)于那些比較難區(qū)分的樣本Loss會(huì)被放大,這就是Focal Loss的核心:通過一個(gè)合適的函數(shù)來度量簡(jiǎn)單樣本和困難樣本對(duì)總的損失函數(shù)的貢獻(xiàn)。
關(guān)于參數(shù)γ的設(shè)置問題,F(xiàn)ocal Loss的作者建議設(shè)置為2。下面是不同的參數(shù)值γ樣本難易程度對(duì)Loss的影響對(duì)比圖:
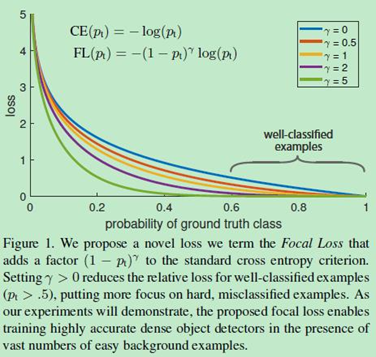
圖5 不同的參數(shù)值γ樣本難易程度對(duì)Loss的影響對(duì)比圖
下面是一個(gè)Focal Loss的實(shí)現(xiàn),感興趣的小伙伴可以試試,看能不能對(duì)下游任務(wù)有積極效果:

圖6 Focal Loss的代碼實(shí)現(xiàn)
3.3 GHM Loss
Focal Loss主要結(jié)合樣本的難易區(qū)分程度來解決樣本不均衡的問題,使得整個(gè)Loss的曲線平滑穩(wěn)定的下降,但是對(duì)于一些特別難區(qū)分的樣本比如離群點(diǎn)會(huì)存在問題。可能一個(gè)模型已經(jīng)收斂訓(xùn)練的很好了,但是因?yàn)橐恍┍热鐦?biāo)注錯(cuò)誤的離群點(diǎn)使得模型去關(guān)注這些樣本,反而降低了模型的效果。比如下面的離群點(diǎn)圖:
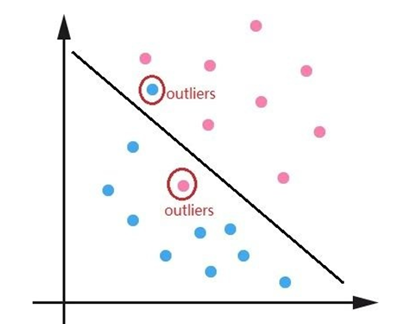
圖7 離群點(diǎn)圖
針對(duì)Focal Loss存在的問題,2019年論文《Gradient Harmonized Single-stage Detector》中提出了GHM(gradient harmonizing mechanism) Loss。相比于Focal Loss從置信度的角度去調(diào)整Loss,GHM Loss則是從一定范圍置信度p的樣本數(shù)量(論文中稱為梯度密度)去調(diào)整Loss。
理解GHM Loss的第一步是先理解梯度模長(zhǎng)的概念,梯度模長(zhǎng)g的計(jì)算公式如下:

公式4中p代表模型預(yù)測(cè)為1的概率值,p*是標(biāo)簽值。也就是說如果樣本越難區(qū)分,那么g的值就越大。下面看看梯度模長(zhǎng)g和樣本數(shù)量的關(guān)系圖:

圖8 梯度模長(zhǎng)g和樣本數(shù)量的關(guān)系
從上圖中可以看出樣本中有很大一部分是容易區(qū)分的樣本,也就是梯度模長(zhǎng)g趨于0的部分。但是還存在一些十分困難區(qū)分的樣本,也就是上圖中右邊紅圈中的樣本。GHM Loss認(rèn)為不僅僅要多關(guān)注容易區(qū)分的樣本,這點(diǎn)和Focal Loss一致,同時(shí)還認(rèn)為需要關(guān)注那些十分困難區(qū)分的樣本,因?yàn)檫@部分樣本可能是標(biāo)注錯(cuò)誤的離群點(diǎn),過多的關(guān)注這部分樣本不僅不會(huì)提升模型的效果,反而還會(huì)有一定的逆向效果。那么問題來了,怎么同時(shí)抑制容易區(qū)分的樣本和十分困難區(qū)分的樣本呢?
針對(duì)這個(gè)問題,從上圖中可以發(fā)現(xiàn)容易區(qū)分的樣本和十分困難區(qū)分的樣本都存在一個(gè)共同點(diǎn):數(shù)量多。那么只要我們抑制一定梯度范圍內(nèi)數(shù)量多的樣本就可以達(dá)到這個(gè)效果,GHM Loss通過梯度密度GD(g)來表示一定梯度范圍內(nèi)的樣本數(shù)量。這個(gè)其實(shí)有點(diǎn)像物理學(xué)中的密度,一定體積的物體的質(zhì)量。梯度密度GD(G)的公式如下:
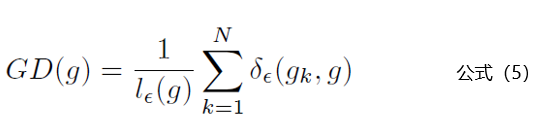
公式5中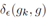 代表樣本中梯度模長(zhǎng)g分布在
代表樣本中梯度模長(zhǎng)g分布在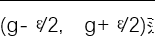 范圍里面的樣本的個(gè)數(shù),
范圍里面的樣本的個(gè)數(shù),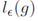 代表了區(qū)間的長(zhǎng)度。公式里面的細(xì)節(jié)小伙伴們可以去論文里面詳細(xì)了解。
代表了區(qū)間的長(zhǎng)度。公式里面的細(xì)節(jié)小伙伴們可以去論文里面詳細(xì)了解。
說完了梯度密度GD(g)的計(jì)算公式,下面就是GHM Loss的計(jì)算公式:
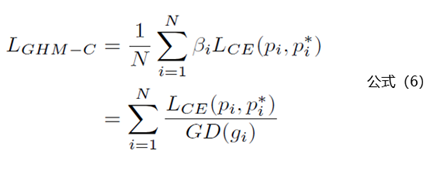
公式6中的Lce其實(shí)就是交叉熵?fù)p失函數(shù),也就是公式1。
下面看看交叉熵?fù)p失函數(shù)、Focal Loss和GHM Loss三種損失函數(shù)對(duì)不同梯度模長(zhǎng)樣本的抑制效果圖:
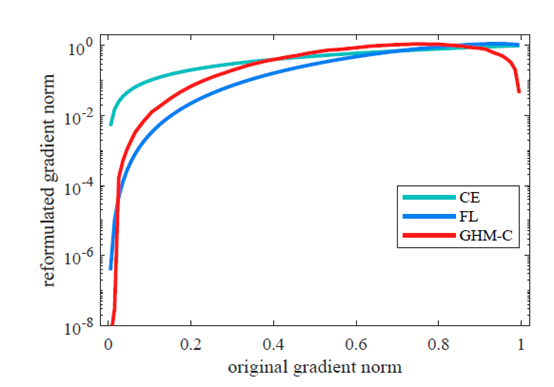
圖9 三種損失函數(shù)對(duì)樣本的抑制效果圖
從上圖中可以看出交叉熵?fù)p失函數(shù)基本沒有抑制效果,F(xiàn)ocal Loss可以有效的抑制容易區(qū)分的樣本,而GHM Loss不僅可以很好的抑制簡(jiǎn)單樣本,還能抑制十分困難的樣本。
下面是復(fù)現(xiàn)了GHM Loss的一個(gè)github上工程,有興趣的小伙伴可以試試:
https://github.com/libuyu/GHM_Detection
04 其他解決樣本不均衡問題的策略
上面主要是從數(shù)據(jù)層面和模型損失函數(shù)來解決樣本不均衡的問題,下面是一些其他的樣本不均衡策略:
4.1 調(diào)節(jié)閾值修改正負(fù)樣本比例
通常情況下Sigmoid函數(shù)會(huì)將大于0.5的閾值預(yù)測(cè)為正樣本。這時(shí)候我們可以通過調(diào)節(jié)閾值來調(diào)整正負(fù)樣本比例,比如設(shè)置0.3分作為閾值,將大于0.3的樣本都判定為正樣本,這樣相當(dāng)于增加了正樣本的比例。
4.2 利用半監(jiān)督或自監(jiān)督學(xué)習(xí)解決樣本不均衡
之前領(lǐng)導(dǎo)分享過一篇知乎高贊的文章,主要是通過半監(jiān)督或自監(jiān)督學(xué)習(xí)來解決樣本不均衡的問題,因?yàn)槠邢蓿@里就不詳細(xì)介紹。后面可能會(huì)專門出一篇文章來詳細(xì)講解這種策略。這里先把鏈接放在這里,有興趣的小伙伴也可以學(xué)習(xí)下:
NeurIPS 2020 | 數(shù)據(jù)類別不平衡/長(zhǎng)尾分布?不妨利用半監(jiān)督或自監(jiān)督學(xué)習(xí)
https://zhuanlan.zhihu.com/p/259710601?utm_source=wechat_session&utm_medium=social&utm_oi=27198249500672#ref_6
總結(jié)
本篇主要從理論到實(shí)踐解決文本分類中的樣本不均衡問題。首先講了下什么是樣本不均衡現(xiàn)象以及可能帶來的問題;然后重點(diǎn)從數(shù)據(jù)層面和模型層面講解樣本不均衡問題的解決策略。數(shù)據(jù)層面主要通過欠采樣和過采樣的方式來人為調(diào)節(jié)正負(fù)樣本比例,模型層面主要是通過加權(quán)Loss,包括基于類別Loss、Focal Loss和GHM Loss三種加權(quán)Loss函數(shù);最后講了下其他解決樣本不均衡的策略,可以通過調(diào)節(jié)閾值修改正負(fù)樣本比例和利用半監(jiān)督或自監(jiān)督學(xué)習(xí)解決樣本不均衡問題。需要說明下上面解決樣本不均衡問題的策略不僅僅適用于文本分類任務(wù),還可以擴(kuò)展到其他的機(jī)器學(xué)習(xí)任務(wù)中。對(duì)于希望解決樣本不均衡問題的小伙伴可能有所幫助。
參考資料
[1] 《Focal Loss forDense Object Detection》
[2]《GradientHarmonized Single-stage Detector》