
Go:高可用延遲隊列設(shè)計與實現(xiàn)
延遲隊列:一種帶有 延遲功能 的消息隊列
延時 → 未來一個不確定的時間 mq → 消費行為具有順序性
這樣解釋,整個設(shè)計就清楚了。你的目的是 延時,承載容器是 mq。
背景
列舉一下我日常業(yè)務(wù)中可能存在的場景:
建立延時日程,需要提醒老師上課 延時推送 → 推送老師需要的公告以及作業(yè)
為了解決以上問題,最簡單直接的辦法就是定時去掃表:
服務(wù)啟動時,開啟一個異步協(xié)程 → 定時掃描 msg table,到了事件觸發(fā)事件,調(diào)用對應(yīng)的 handler
幾個缺點:
每一個需要定時/延時任務(wù)的服務(wù),都需要一個 msg table 做額外存儲 → 存儲與業(yè)務(wù)耦合 定時掃描 → 時間不好控制,可能會錯過觸發(fā)時間 對 msg table instance 是一個負(fù)擔(dān)。反復(fù)有一個服務(wù)不斷對數(shù)據(jù)庫產(chǎn)生持續(xù)不斷的壓力
最大問題其實是什么?
調(diào)度模型基本統(tǒng)一,不要做重復(fù)的業(yè)務(wù)邏輯
我們可以考慮將邏輯從具體的業(yè)務(wù)邏輯里面抽出來,變成一個公共的部分。
而這個調(diào)度模型,就是 延時隊列 。
其實說白了:
延時隊列模型,就是將未來執(zhí)行的事件提前存儲好,然后不斷掃描這個存儲,觸發(fā)執(zhí)行時間則執(zhí)行對應(yīng)的任務(wù)邏輯。
那么開源界是否已有現(xiàn)成的方案呢?答案是肯定的。Beanstalk (https://github.com/beanstalkd/beanstalkd) 它基本上已經(jīng)滿足以上需求
設(shè)計目的
消費行為 at least 高可用 實時性 支持消息刪除
一次說說上述這些目的的設(shè)計方向:
消費行為
這個概念取自 mq 。mq 中提供了消費投遞的幾個方向:
at most once→ 至多一次,消息可能會丟,但不會重復(fù)at least once→ 至少一次,消息肯定不會丟失,但可能重復(fù)exactly once→ 有且只有一次,消息不丟失不重復(fù),且只消費一次。
exactly once 盡可能是 producer + consumer 兩端都保證。當(dāng) producer 沒辦法保證是,那 consumer 需要在消費前做一個去重,達(dá)到消費過一次不會重復(fù)消費,這個在延遲隊列內(nèi)部直接保證。
最簡單:使用 redis 的 setNX 達(dá)到 job id 的唯一消費
高可用
支持多實例部署。掛掉一個實例后,還有后備實例繼續(xù)提供服務(wù)。
這個對外提供的 API 使用 cluster 模型,內(nèi)部將多個 node 封裝起來,多個 node 之間冗余存儲。
為什么不使用 Kafka?
考慮過類似基于 kafka/rocketmq 等消息隊列作為存儲的方案,最后從存儲設(shè)計模型放棄了這類選擇。
舉個例子,假設(shè)以 Kafka 這種消息隊列存儲來實現(xiàn)延時功能,每個隊列的時間都需要創(chuàng)建一個單獨的 topic(如: Q1-1s, Q1-2s..)。這種設(shè)計在延時時間比較固定的場景下問題不太大,但如果是延時時間變化比較大會導(dǎo)致 topic 數(shù)目過多,會把磁盤從順序讀寫會變成隨機讀寫從導(dǎo)致性能衰減,同時也會帶來其他類似重啟或者恢復(fù)時間過長的問題。
topic 過多 → 存儲壓力 topic 存儲的是現(xiàn)實時間,在調(diào)度時對不同時間 (topic) 的讀取,順序讀 → 隨機讀 同理,寫入的時候順序?qū)?→ 隨機寫
架構(gòu)設(shè)計
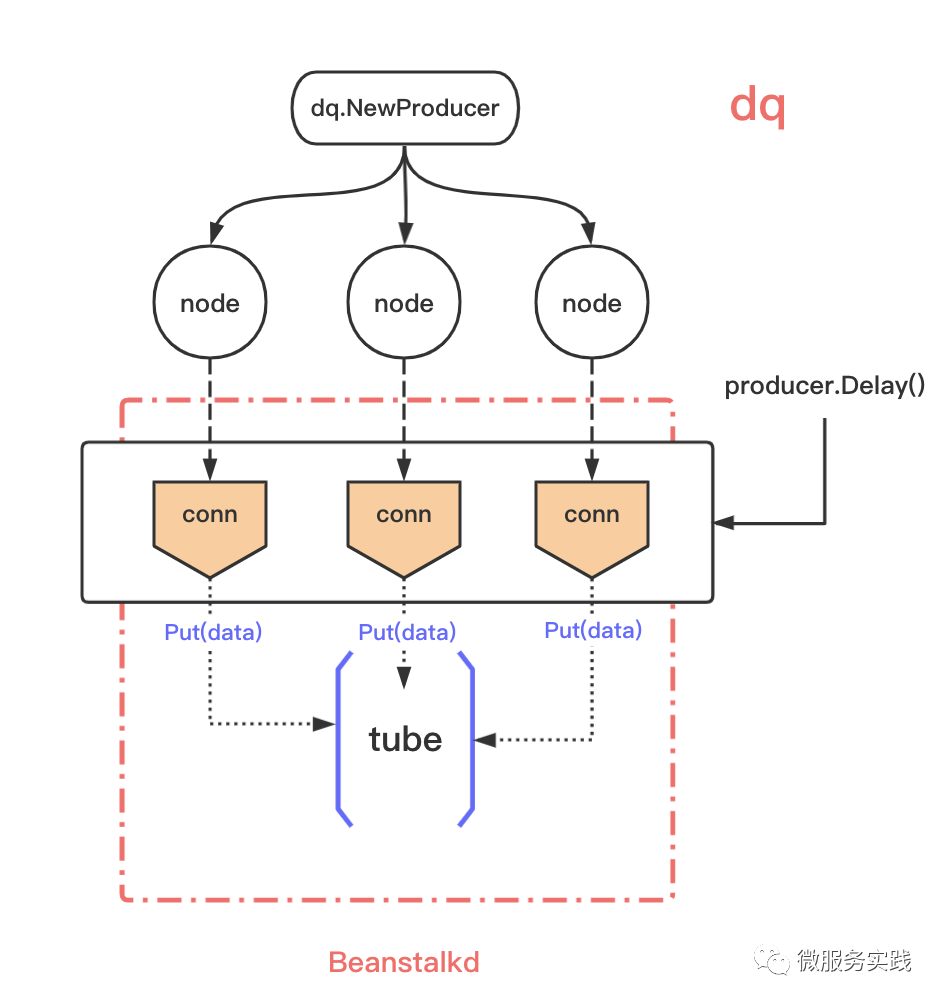
API 設(shè)計
producer
producer.At(msg []byte, at time.Time)producer.Delay(body []byte, delay time.Duration)producer.Revoke(ids string)
consumer
consumer.Consume(consume handler)
使用延時隊列后,服務(wù)整體結(jié)構(gòu)如下,以及隊列中 job 的狀態(tài)變遷:
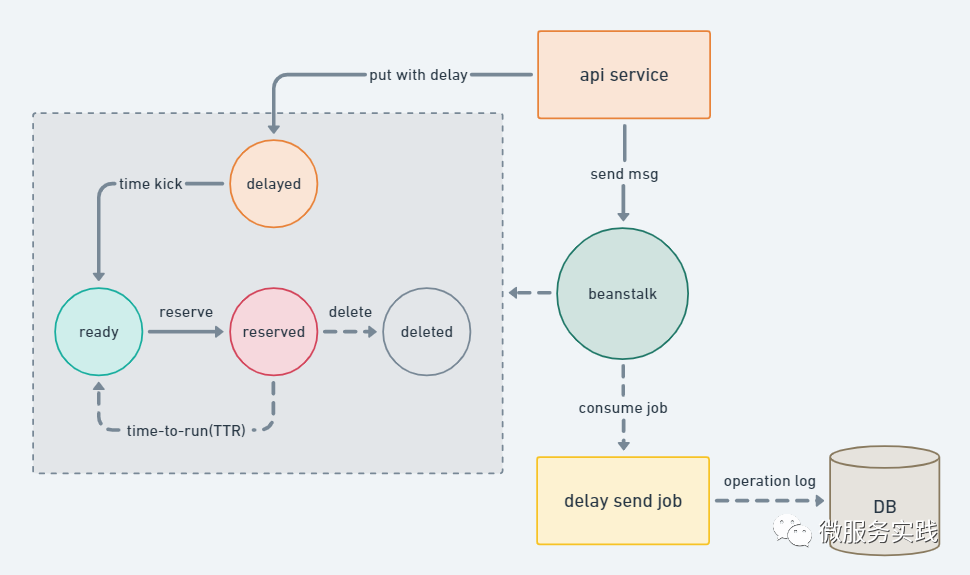
service → producer.At(msg []byte, at time.Time)→ 插入延時job到 tube 中定時觸發(fā) → job 狀態(tài)更新為 ready consumer 獲取到 ready job → 取出 job,開始消費;并更改狀態(tài)為 reserved 執(zhí)行傳入 consumer 中的 handler 邏輯處理函數(shù)
生產(chǎn)實踐
主要介紹一下在日常開發(fā),我們使用到延時隊列的哪些具體功能。
生產(chǎn)端
開發(fā)中生產(chǎn)延時任務(wù),只需確定任務(wù)執(zhí)行時間 傳入 At() producer.At(msg []byte, at time.Time)內(nèi)部會自行計算時間差值,插入 tube 如果出現(xiàn)任務(wù)時間的修改,以及任務(wù)內(nèi)容的修改 在生產(chǎn)時可能需要額外建立一個 logic_id → job_id 的關(guān)系表 查詢到 job_id → producer.Revoke(ids string),對其刪除,然后重新插入
消費端
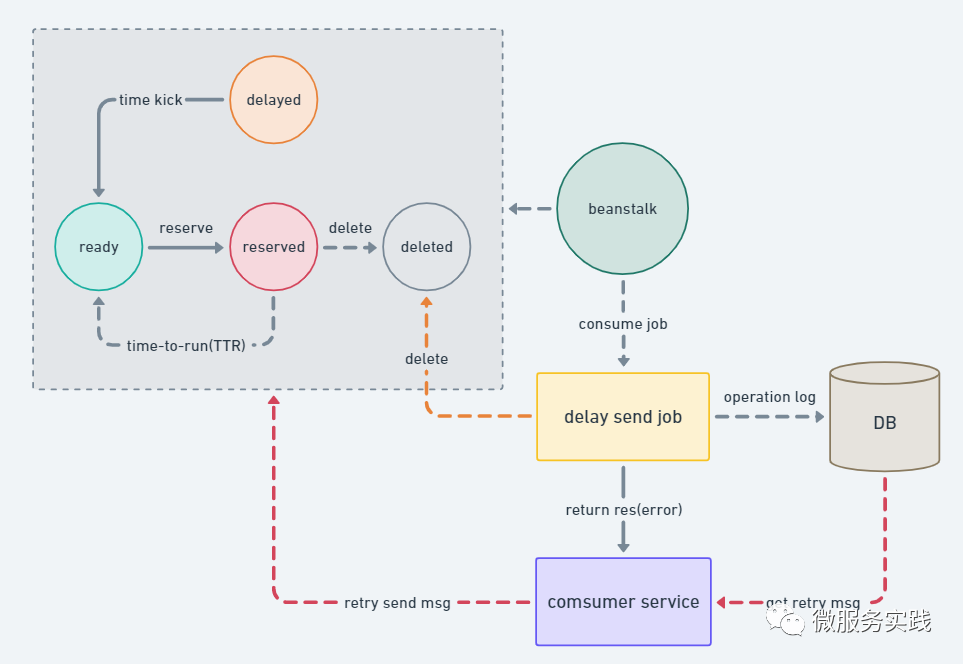
首先,框架層面保證了消費行為的 exactly once ,但是上層業(yè)務(wù)邏輯消費失敗或者是出現(xiàn)網(wǎng)絡(luò)問題,亦或者是各種各樣的問題,導(dǎo)致消費失敗,兜底交給業(yè)務(wù)開發(fā)做。這樣做的原因:
框架以及基礎(chǔ)組件只保證 job 狀態(tài)的流轉(zhuǎn)正確性 框架消費端只保證消費行為的統(tǒng)一 延時任務(wù)在不同業(yè)務(wù)中行為不統(tǒng)一 強調(diào)任務(wù)的必達(dá)性,則消費失敗時需要不斷重試直到任務(wù)成功 強調(diào)任務(wù)的準(zhǔn)時性,則消費失敗時,對業(yè)務(wù)不敏感則可以選擇丟棄
這里描述一下框架消費端是怎么保證消費行為的統(tǒng)一:
分為 cluster 和 node。cluster:
https://github.com/tal-tech/go-queue/blob/master/dq/consumer.go#L45
cluster 內(nèi)部將 consume handler 做了一層再封裝 對 consume body 做hash,并使用此 hash 作為 redis 去重的key 如果存在,則不做處理,丟棄
node:
https://github.com/tal-tech/go-queue/blob/master/dq/consumernode.go#L36
消費 node 獲取到 ready job;先執(zhí)行 Reserve(TTR),預(yù)訂此job,將執(zhí)行該job進行邏輯處理 在 node 中 delete(job);然后再進行消費 如果失敗,則上拋給業(yè)務(wù)層,做相應(yīng)的兜底重試
所以對于消費端,開發(fā)者需要自己實現(xiàn)消費的冪等性。
項目地址
go-queue 是基于 go-zero 實現(xiàn)的,go-zero 在 github 上 Used by 有300+,開源一年獲得11k+ stars.
go-zero: https://github.com/zeromicro/go-zero
go-queue: https://github.com/tal-tech/go-queue
歡迎使用并 star 支持我們!
推薦閱讀