
來聊聊幾種數(shù)據(jù)壓縮算法
前言
當(dāng)我們數(shù)據(jù)量大的時候,離不開數(shù)據(jù)壓縮技術(shù),不管是大數(shù)據(jù)量的傳輸和存儲不進(jìn)行壓縮處理都會帶來很大的挑戰(zhàn)。例如我們常見的文件壓縮包,幾個G的文件可能經(jīng)過壓縮就只有幾百M,可以為我們節(jié)省幾倍甚至十幾倍的空間,讓我們硬盤能存儲更多文件,帶來了極大的便利和成本節(jié)約。
在項目開發(fā)上,當(dāng)遇到文件傳輸或者一些大數(shù)據(jù)傳輸?shù)臅r候就需要使用到數(shù)據(jù)壓縮技術(shù)了,數(shù)據(jù)包得到成倍的減少,意味著我們同樣的帶寬、同樣的磁盤可以更快處理更多的數(shù)據(jù)包。今天就來聊聊下面5種數(shù)據(jù)壓縮算法的原理、實現(xiàn)以及性能測試。
- Deflate
- GZIP
- LZO
- LZ4
- Snappy
以上壓縮算法底層實現(xiàn)大多基于LZ77算法和Huffman編碼,咱們先來看看這兩種算法的原理。
LZ77算法
如果文件中有兩塊內(nèi)容相同,那么只要知道前一塊的位置和大小,我們就可以確定后一塊的內(nèi)容,我們可以用(兩者之間的距離,相同內(nèi)容的長度)這樣的信息來替換后一塊內(nèi)容。由于(兩者之間的距離,相同內(nèi)容的長度)這一信息的大小小于被替換內(nèi)容的大小,所以文件得到了壓縮。例如有一個文件的內(nèi)容如下:http://www.baidu.comhttp://www.qq.com其中有些部分的內(nèi)容,前面已經(jīng)出現(xiàn)過了,下面用()括起來的部分就是相同的部分:http://www.baidu.com (http://www.)qq(.com)我們使用 (兩者之間的距離,相同內(nèi)容的長度) 這樣一對信息,來替換后一塊內(nèi)容:http://www.baidu.com (21,12).qq(18,4) (21,11)中,21[是21,圖片上寫錯了]為相同內(nèi)容塊與當(dāng)前位置之間的距離,11為相同內(nèi)容的長度,即是:http://www.的長度;(18,4)中,18為相同內(nèi)容塊與當(dāng)前位置之間的距離,4為相同內(nèi)容的長度,即是:.com的長度;由于(兩者之間的距離,相同內(nèi)容的長度)這一對信息的大小,小于被替換內(nèi)容的大小,所以文件得到了壓縮。通過以上例子可以了解到LZ77算法的基本實現(xiàn)核心,下面來深入理解一下。要理解這種算法,需要對3個關(guān)鍵詞有所了解。前向緩沖區(qū)每次讀取數(shù)據(jù)的時候,先把一部分?jǐn)?shù)據(jù)預(yù)載入前向緩沖區(qū)。為移入滑動窗口做準(zhǔn)備滑動窗口一旦數(shù)據(jù)通過緩沖區(qū),那么它將移動到滑動窗口中,并變成字典的一部分。短語字典從字符序列S1...Sn,組成n個短語。比如字符(A,B,D) ,可以組合的短語為{(A),(A,B),(A,B,D),(B),(B,D),(D)},如果這些字符在滑動窗口里面,就可以記為當(dāng)前的短語字典,因為滑動窗口不斷的向前滑動,所以短語字典也是不斷的變化。LZ77的主要算法邏輯就是,先通過前向緩沖區(qū)預(yù)讀數(shù)據(jù),然后再向滑動窗口移入(滑動窗口有一定的長度),不斷地尋找能與字典中短語匹配的最長短語,然后通過標(biāo)記符標(biāo)記。當(dāng)壓縮數(shù)據(jù)的時候,前向緩沖區(qū)與移動窗口之間在做短語匹配的是后會存在2種情況:找不到匹配時:將未匹配的符號編碼成符號標(biāo)記(多數(shù)都是字符本身)找到匹配時:將其最長的匹配編碼成短語標(biāo)記短語標(biāo)記包含3個部分信息:滑動窗口中的偏移量(從匹配的地方開始計算)、匹配中的符號個數(shù)、匹配結(jié)束后的前向緩沖區(qū)的第一個符號。我們采用圖例來看:1、開始
(21,11)中,21[是21,圖片上寫錯了]為相同內(nèi)容塊與當(dāng)前位置之間的距離,11為相同內(nèi)容的長度,即是:http://www.的長度;(18,4)中,18為相同內(nèi)容塊與當(dāng)前位置之間的距離,4為相同內(nèi)容的長度,即是:.com的長度;由于(兩者之間的距離,相同內(nèi)容的長度)這一對信息的大小,小于被替換內(nèi)容的大小,所以文件得到了壓縮。通過以上例子可以了解到LZ77算法的基本實現(xiàn)核心,下面來深入理解一下。要理解這種算法,需要對3個關(guān)鍵詞有所了解。前向緩沖區(qū)每次讀取數(shù)據(jù)的時候,先把一部分?jǐn)?shù)據(jù)預(yù)載入前向緩沖區(qū)。為移入滑動窗口做準(zhǔn)備滑動窗口一旦數(shù)據(jù)通過緩沖區(qū),那么它將移動到滑動窗口中,并變成字典的一部分。短語字典從字符序列S1...Sn,組成n個短語。比如字符(A,B,D) ,可以組合的短語為{(A),(A,B),(A,B,D),(B),(B,D),(D)},如果這些字符在滑動窗口里面,就可以記為當(dāng)前的短語字典,因為滑動窗口不斷的向前滑動,所以短語字典也是不斷的變化。LZ77的主要算法邏輯就是,先通過前向緩沖區(qū)預(yù)讀數(shù)據(jù),然后再向滑動窗口移入(滑動窗口有一定的長度),不斷地尋找能與字典中短語匹配的最長短語,然后通過標(biāo)記符標(biāo)記。當(dāng)壓縮數(shù)據(jù)的時候,前向緩沖區(qū)與移動窗口之間在做短語匹配的是后會存在2種情況:找不到匹配時:將未匹配的符號編碼成符號標(biāo)記(多數(shù)都是字符本身)找到匹配時:將其最長的匹配編碼成短語標(biāo)記短語標(biāo)記包含3個部分信息:滑動窗口中的偏移量(從匹配的地方開始計算)、匹配中的符號個數(shù)、匹配結(jié)束后的前向緩沖區(qū)的第一個符號。我們采用圖例來看:1、開始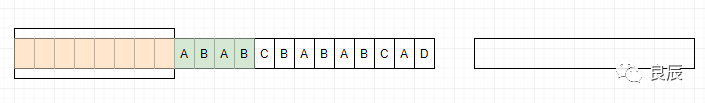 2、滑動窗口中沒有數(shù)據(jù),所以沒有匹配到短語,將字符A標(biāo)記為A
2、滑動窗口中沒有數(shù)據(jù),所以沒有匹配到短語,將字符A標(biāo)記為A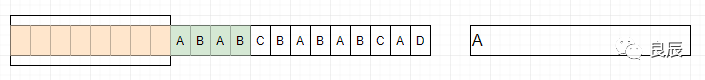 3、滑動窗口中有A,沒有從緩沖區(qū)中字符(BABC)中匹配到短語,依然把B標(biāo)記為B
3、滑動窗口中有A,沒有從緩沖區(qū)中字符(BABC)中匹配到短語,依然把B標(biāo)記為B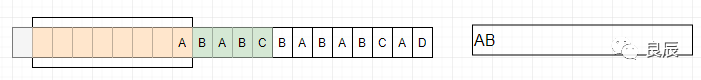 4、緩沖區(qū)字符(ABCB)在滑動窗口的位移6位置找到AB,成功匹配到短語AB,將AB編碼為(6,2,C)
4、緩沖區(qū)字符(ABCB)在滑動窗口的位移6位置找到AB,成功匹配到短語AB,將AB編碼為(6,2,C) 5、緩沖區(qū)字符(BABA)在滑動窗口位移4的位置匹配到短語BAB,將BAB編碼為(4,3,A)
5、緩沖區(qū)字符(BABA)在滑動窗口位移4的位置匹配到短語BAB,將BAB編碼為(4,3,A) 6、緩沖區(qū)字符(BCAD)在滑動窗口位移2的位置匹配到短語BC,將BC編碼為(2,2,A)
6、緩沖區(qū)字符(BCAD)在滑動窗口位移2的位置匹配到短語BC,將BC編碼為(2,2,A) 7、緩沖區(qū)字符D,在滑動窗口中沒有找到匹配短語,標(biāo)記為D
7、緩沖區(qū)字符D,在滑動窗口中沒有找到匹配短語,標(biāo)記為D 8、緩沖區(qū)中沒有數(shù)據(jù)進(jìn)入了,結(jié)束
8、緩沖區(qū)中沒有數(shù)據(jù)進(jìn)入了,結(jié)束 解壓類似于壓縮的逆向過程,通過解碼標(biāo)記和保持滑動窗口中的符號來更新解壓數(shù)據(jù)。· 當(dāng)解碼字符標(biāo)記:將標(biāo)記編碼成字符拷貝到滑動窗口中· 解碼短語標(biāo)記:在滑動窗口中查找響應(yīng)偏移量,同時找到指定長短的短語進(jìn)行替換我們還是采用圖例來看下:1、開始
解壓類似于壓縮的逆向過程,通過解碼標(biāo)記和保持滑動窗口中的符號來更新解壓數(shù)據(jù)。· 當(dāng)解碼字符標(biāo)記:將標(biāo)記編碼成字符拷貝到滑動窗口中· 解碼短語標(biāo)記:在滑動窗口中查找響應(yīng)偏移量,同時找到指定長短的短語進(jìn)行替換我們還是采用圖例來看下:1、開始 2、符號標(biāo)記A解碼
2、符號標(biāo)記A解碼 3、符號標(biāo)記B解碼
3、符號標(biāo)記B解碼 4、短語標(biāo)記(6,2,C)解碼
4、短語標(biāo)記(6,2,C)解碼 5、短語標(biāo)記(4,3,A)解碼
5、短語標(biāo)記(4,3,A)解碼 6、短語標(biāo)記(2,2,A)解碼
6、短語標(biāo)記(2,2,A)解碼 7、符號標(biāo)記D解碼
7、符號標(biāo)記D解碼 大多數(shù)情況下LZ77壓縮算法的壓縮比相當(dāng)高,當(dāng)然了也和你選擇滑動窗口大小,以及前向緩沖區(qū)大小有關(guān)系。其壓縮過程是比較耗時的,因為要花費很多時間尋找滑動窗口中的短語匹配,不過解壓過程會很快,因為每個標(biāo)記都明確告知在哪個位置可以讀取了。
大多數(shù)情況下LZ77壓縮算法的壓縮比相當(dāng)高,當(dāng)然了也和你選擇滑動窗口大小,以及前向緩沖區(qū)大小有關(guān)系。其壓縮過程是比較耗時的,因為要花費很多時間尋找滑動窗口中的短語匹配,不過解壓過程會很快,因為每個標(biāo)記都明確告知在哪個位置可以讀取了。Huffman編碼
是一種編碼方式,哈夫曼編碼是可變字長編碼的一種,該方法完全依據(jù)字符出現(xiàn)概率來構(gòu)造平均長度最短的碼字。我們把文件中一定位長的值看作是符號,比如把8位長的256種值,也就是字節(jié)的256種值看作是符號。我們根據(jù)這些符號在文件中出現(xiàn)的頻率,對這些符號重新編碼。對于出現(xiàn)次數(shù)非常多的,我們用較少的位來表示,對于出現(xiàn)次數(shù)非常少的,我們用較多的位來表示。這樣一來,文件的一些部分位數(shù)變少了,一些部分位數(shù)變多了,由于變小的部分比變大的部分多,整個文件的大小還是會減小,所以文件得到了壓縮。要進(jìn)行Huffman編碼,首先要把整個文件讀一遍,在讀的過程中,統(tǒng)計每個符號(我們把字節(jié)的256種值看作是256種符號)的出現(xiàn)次數(shù)。然后根據(jù)符號的出現(xiàn)次數(shù),建立Huffman樹,通過Huffman樹得到每個符號的新的編碼。對于文件中出現(xiàn)次數(shù)較多的符號,它的Huffman編碼的位數(shù)比較少。對于文件中出現(xiàn)次數(shù)較少的符號,它的Huffman編碼的位數(shù)比較多。然后把文件中的每個字節(jié)替換成他們新的編碼。哈夫曼樹的構(gòu)造1.根據(jù)給定的n個權(quán)值{w1,w2,…,wn}構(gòu)成二叉樹集合F={T1,T2,…,Tn},其中每棵二叉樹Ti中只有一個帶權(quán)為wi的根結(jié)點,其左右子樹為空.2.在F中選取兩棵根結(jié)點權(quán)值最小的樹作為左右子樹構(gòu)造一棵新的二叉樹,且置新的二叉樹的根結(jié)點的權(quán)值為左右子樹根結(jié)點的權(quán)值之和.3.在F中刪除這兩棵樹,同時將新的二叉樹加入F中.4.重復(fù)2、3,直到F只含有一棵樹為止.(得到哈夫曼樹)例子,有這樣一個文件的內(nèi)容如下:AAAAABBBBCCCDDEEFG我們統(tǒng)計一下各個符號的出現(xiàn)次數(shù),A(5) B(4) C(3) D(2) E(2) F(1) G(1)建立Huffman樹的過程如圖: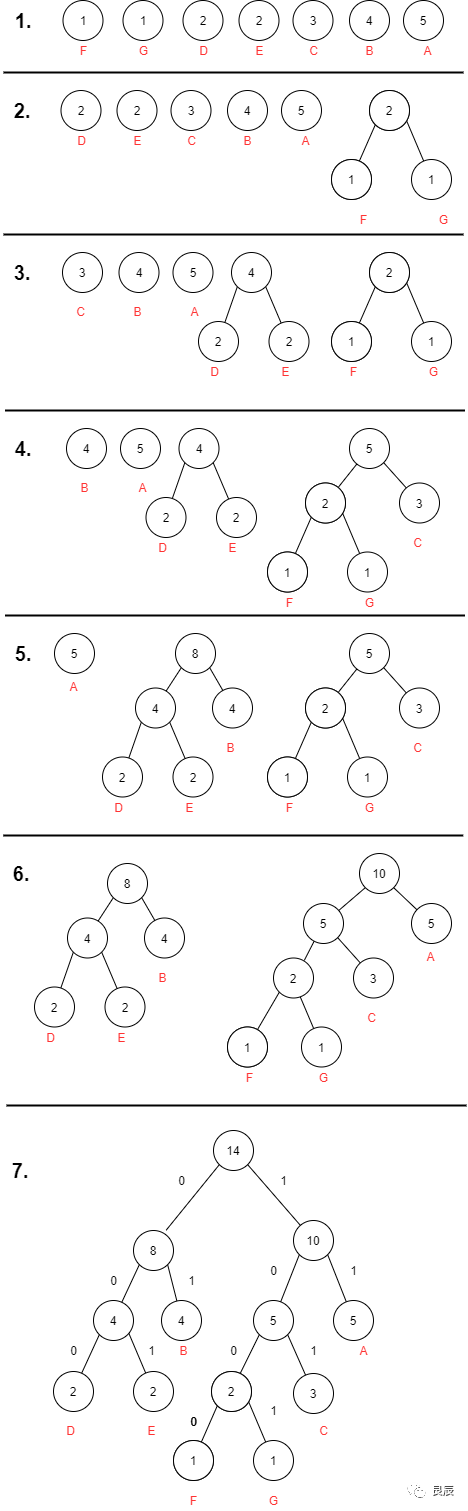 通過最終的Huffman樹,我們可以得到每個符號的Huffman編碼。A(5):11B(4):01C(3):101D(2):000E(2):001F(1):1000G(1):1001我們可以看到,Huffman樹的建立方法就保證了,出現(xiàn)次數(shù)多的符號,得到的Huffman編碼位數(shù)少,出現(xiàn)次數(shù)少的符號,得到的Huffman編碼位數(shù)多。各個符號的Huffman編碼的長度不一,也就是變長編碼。對于變長編碼,可能會遇到一個問題,就是重新編碼的文件中可能會無法如區(qū)分這些編碼。比如,a的編碼為000,b的編碼為0001,c的編碼為1,那么當(dāng)遇到0001時,就不知道0001代表ac,還是代表b。出現(xiàn)這種問題的原因是a的編碼是b的編碼的前綴。由于Huffman編碼為根結(jié)點到葉子結(jié)點路徑上的0和1的序列,而一個葉子結(jié)點的路徑不可能是另一個葉子結(jié)點路徑的前綴,所以一個Huffman編碼不可能為另一個Huffman編碼的前綴,這就保證了Huffman編碼是可以區(qū)分的。
通過最終的Huffman樹,我們可以得到每個符號的Huffman編碼。A(5):11B(4):01C(3):101D(2):000E(2):001F(1):1000G(1):1001我們可以看到,Huffman樹的建立方法就保證了,出現(xiàn)次數(shù)多的符號,得到的Huffman編碼位數(shù)少,出現(xiàn)次數(shù)少的符號,得到的Huffman編碼位數(shù)多。各個符號的Huffman編碼的長度不一,也就是變長編碼。對于變長編碼,可能會遇到一個問題,就是重新編碼的文件中可能會無法如區(qū)分這些編碼。比如,a的編碼為000,b的編碼為0001,c的編碼為1,那么當(dāng)遇到0001時,就不知道0001代表ac,還是代表b。出現(xiàn)這種問題的原因是a的編碼是b的編碼的前綴。由于Huffman編碼為根結(jié)點到葉子結(jié)點路徑上的0和1的序列,而一個葉子結(jié)點的路徑不可能是另一個葉子結(jié)點路徑的前綴,所以一個Huffman編碼不可能為另一個Huffman編碼的前綴,這就保證了Huffman編碼是可以區(qū)分的。算法實現(xiàn)和性能測試
這里直接宣布結(jié)果,詳情可以看我的這篇文章:5種數(shù)據(jù)壓縮算法實現(xiàn)和性能測試以514KB大小的JSON字符串測試為例:Benchmark ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? Mode ? Samples ? ? ? ? Mean ? Mean error ? Units
o.s.MyBenchmark.testDeflateCompress ? ? avgt ? ? ? 10 ? ? ? 12.100 ? ? ? 0.498 ? ms/op
o.s.MyBenchmark.testGzipCompress ? ? ? avgt ? ? ? 10 ? ? ? 7.434 ? ? ? 4.398 ? ms/op
o.s.MyBenchmark.testLz4Compress ? ? ? ? avgt ? ? ? 10 ? ? ? 3.310 ? ? ? 1.096 ? ms/op
o.s.MyBenchmark.testLzoCompress ? ? ? ? avgt ? ? ? 10 ? ? ? 3.255 ? ? ? 1.014 ? ms/op
o.s.MyBenchmark.testSnappyCompress ? ? avgt ? ? ? 10 ? ? ? 1.971 ? ? ? 0.209 ? ms/op
- 壓縮耗時:snappy(1.9) < lzo(3.2) < lz4(3.3) < gzip(7.4) < deflate(12.1),如果數(shù)據(jù)比較大,lzo的速度比deflate還慢
- 壓縮率(越小越好):deflate(3.3%) < gzip(3.8%) < lzo(8.4%) < snappy(11.5%) < lz4(47.3%)
- deflate壓縮耗時最大,但壓縮率最好,gzip相對deflate綜合性能更好,壓縮率相差不多但壓縮時間幾乎少一半,綜合性能最好的要算snappy,它是最快的,壓縮率也挺不錯,追求速度可以選擇它,lzo和lz4綜合性能較差,不推薦使用
評論
圖片
表情