
面試HDFS技術(shù)原理

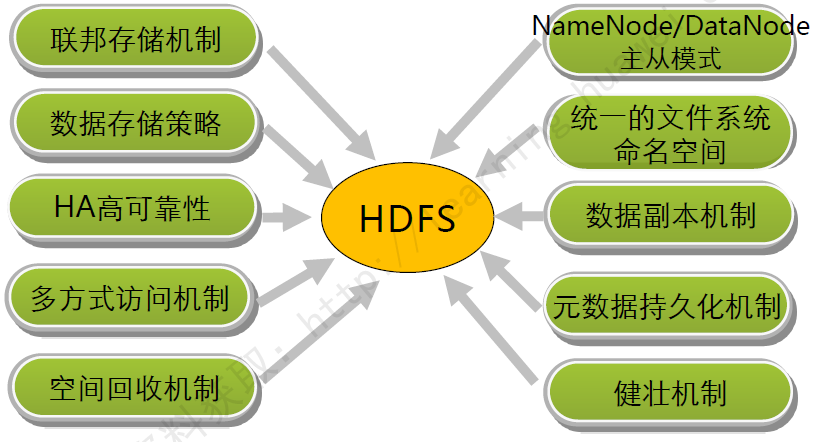
HDFS概述:
HDFS(Hadoop Distributed File System)基于Google發(fā)布的GFS論文設(shè)計開發(fā),運行在通用硬件平臺上的分布式文件系統(tǒng)。
其除具有其他分布式文件系統(tǒng)的相同特性外,還有自己特有的特性:
高容錯性:認為硬件總是不可靠的。 高吞吐量:為大量數(shù)據(jù)訪問的應用提供高可用吞吐量支持。 大文件存儲:支持存儲TB-PB級別的數(shù)據(jù)。
HDFS適合做:大文件存儲、流式數(shù)據(jù)訪問。
HDFS不適合做:大量小文件、隨機寫入、低延遲讀取。
HDFS應用場景舉例:
HDFS是Hadoop技術(shù)框架中的分布式文件系統(tǒng),對部署在多臺獨立物理機器上的文件進行管理。
可應用與以下幾種場景:
網(wǎng)站用戶行為數(shù)據(jù)存儲。 生態(tài)系統(tǒng)數(shù)據(jù)存儲。 氣象數(shù)據(jù)存儲。
系統(tǒng)設(shè)計目標:
(1)硬件失效:
硬件的異常比軟件的異常更加常見。 對于有上百臺服務(wù)器的數(shù)據(jù)中心來說,認為總有服務(wù)器異常,硬件異常是常態(tài)。 HDFS需要監(jiān)測這些異常,并自動恢復數(shù)據(jù)。
(2)流式數(shù)據(jù)訪問:
基于HDFS的應用僅采用流式方式讀數(shù)據(jù)。 運行在HDFS上的應用并非以通用業(yè)務(wù)為目的的應用程序。 應用程序關(guān)注的是吞吐量,而非響應時間。 非POSIX標準接口的數(shù)據(jù)訪問。
(3)存儲數(shù)據(jù)大:
運行在HDFS的應用程序有較大的數(shù)據(jù)需要處理。 典型的文件大小為GP到TB級別。
(4)數(shù)據(jù)一致性:
應用程序采用WORM(Write Once Read Many)的數(shù)據(jù)讀寫模型。 文件僅支持追加,而不允許修改。
(5)多硬件平臺:
HDFS可運行在不同的硬件平臺上。
(6)移動計算能力:
計算和存儲能力采用就近原則,計算離數(shù)據(jù)最近。 就近原則將有效減少網(wǎng)絡(luò)的負載,降低網(wǎng)絡(luò)擁塞。
基本系統(tǒng)架構(gòu):
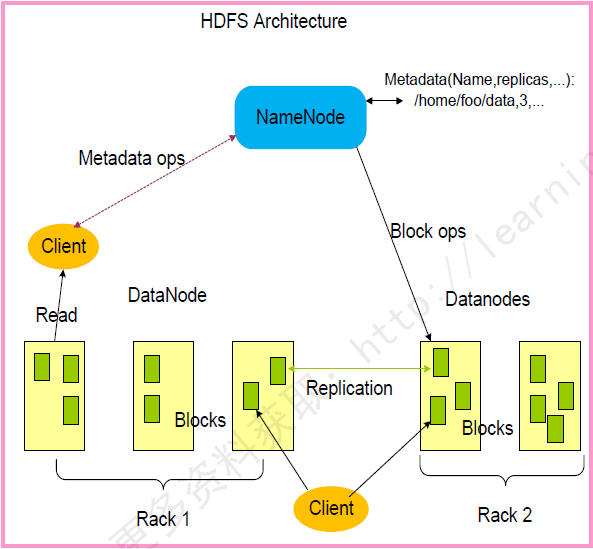
HDFS架構(gòu)包含三個部分:(NameNode,DateNode,Client)
NameDode:用于存儲、生成文件系統(tǒng)的元數(shù)據(jù)、運行一個實例。 DateNode:用于存儲實際的數(shù)據(jù),將自己管理的數(shù)據(jù)塊上報給NameNode,運行多個實例。 Client:支持業(yè)務(wù)訪問HDFS,從NameNode,DateNode獲取數(shù)據(jù)返回給業(yè)務(wù)。多個實例,和業(yè)務(wù)一起運行。
HDFS數(shù)據(jù)寫入流程:
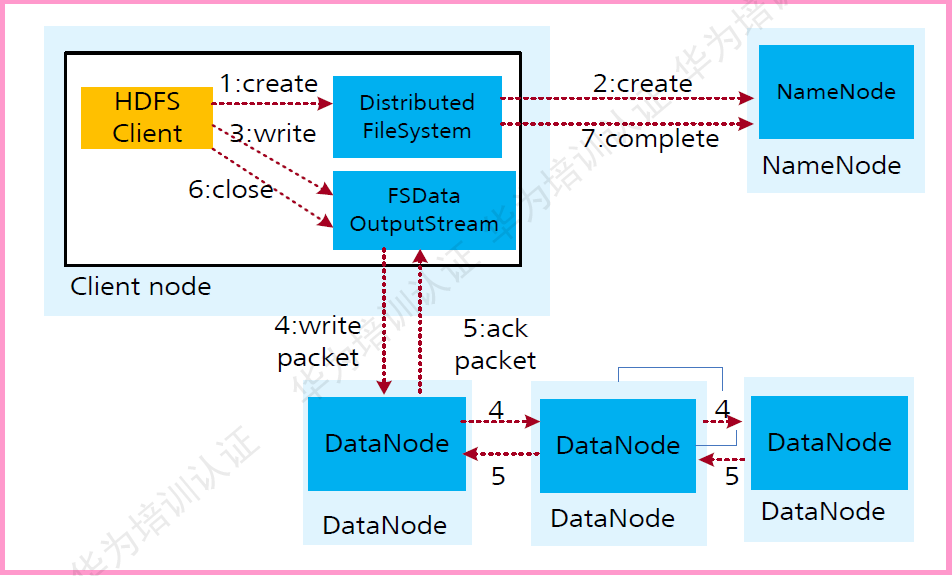
HDFS數(shù)據(jù)寫入流程如下:
業(yè)務(wù)應用調(diào)用HDFS Client提供的API創(chuàng)建文件,請求寫入。 HDFS Client聯(lián)系NameNode,NameNode在元數(shù)據(jù)中創(chuàng)建文件節(jié)點。 業(yè)務(wù)應用調(diào)用write API寫入文件。 HDFS Client收到業(yè)務(wù)數(shù)據(jù)后,從NameNode獲取到數(shù)據(jù)塊編號、位置信息后,聯(lián)系DateNode,并將要寫入數(shù)據(jù)的DateNode建立起流水線。完成后,客戶端再通過自有協(xié)議寫入數(shù)據(jù)到DateNode1,再由DateNode1復制到NateNode2,DateNode3. 寫完的數(shù)據(jù),將返回確認信息給HDFS Client。 所有數(shù)據(jù)確認完成后,業(yè)務(wù)調(diào)用HDFS CLient關(guān)閉文件。 業(yè)務(wù)調(diào)用close,flush后HDFS Client聯(lián)系NameNode,確認數(shù)據(jù)寫完成,NameNode持久化元數(shù)據(jù)。
HDFS數(shù)據(jù)讀取流程:
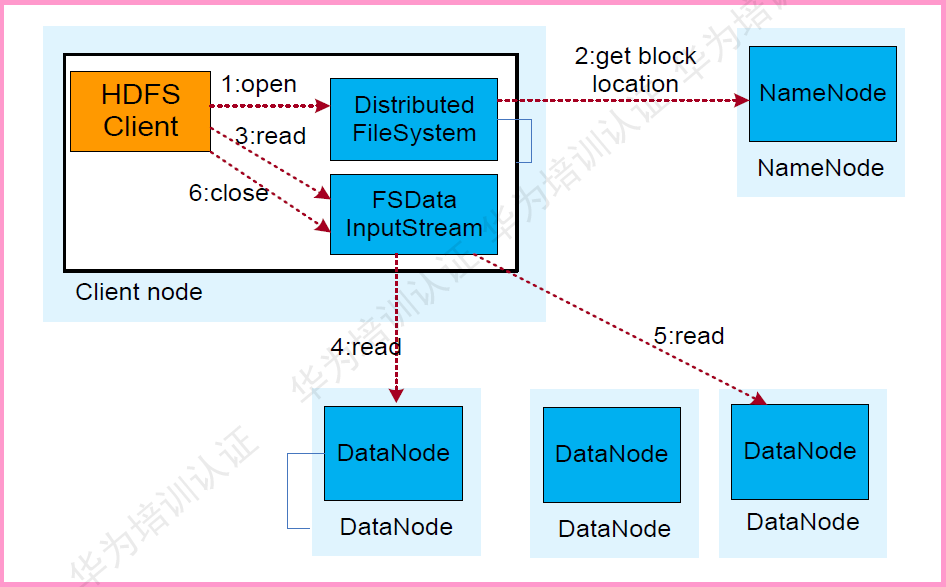
HDFS數(shù)據(jù)讀取流程如下:
業(yè)務(wù)調(diào)用HDFS Client提供的API打開文件。 HDFS Client 聯(lián)系 NmaeNode,獲取到文件信息(數(shù)據(jù)塊、DateNode位置信息)。 業(yè)務(wù)應用調(diào)用read API讀取文件。 HDFS Client根據(jù)從NmaeNode獲取到的信息,聯(lián)系DateNode,獲取相應的數(shù)據(jù)塊。(Client采用就近原則讀取數(shù)據(jù))。 HDFS Client會與多個DateNode通訊獲取數(shù)據(jù)塊。 數(shù)據(jù)讀取完成后,業(yè)務(wù)調(diào)用close關(guān)閉連接。
HDFS架構(gòu)關(guān)鍵設(shè)計:
元數(shù)據(jù)持久化:
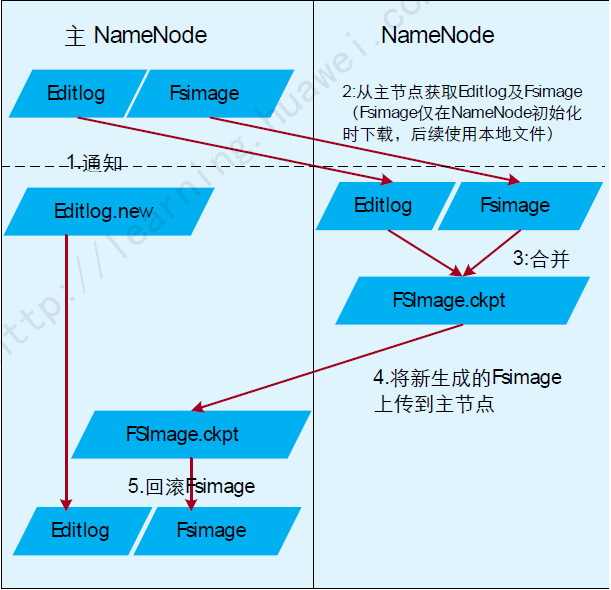 元數(shù)據(jù)持久化
元數(shù)據(jù)持久化
元數(shù)據(jù)持久化流程如下:
備NmaeNode通知主NameNode生成新的日志文件,以后的日志寫到Editlog.new中,并獲取舊的Editlog。 備NameNode從注NameNode上獲取FSImage文件及位于JournalNode上面的舊Editlog。 備NmaeNode將日志和舊的元數(shù)據(jù)合并,生成新的元數(shù)據(jù)FSImage.ckpt。 備NameNode將元數(shù)據(jù)上傳到主NameNode。 主NameNode將上傳的原書記進行回滾。 循環(huán)步驟1.
元數(shù)據(jù)持久化健壯機制:
HDFS主要目的是保證存儲數(shù)據(jù)完整性,對于各組件的失效,做了可靠性處理。
重建失效數(shù)據(jù)盤的副本數(shù)據(jù)
DateNode向NmaeNode周期上報失敗時,NmaeNode發(fā)起副本重建動作以恢復丟失副本。
集群數(shù)據(jù)均衡
HDFS架構(gòu)設(shè)計了數(shù)據(jù)均衡機制,此機制保證數(shù)據(jù)在各個DateNode上分布式平均的。
數(shù)據(jù)有效性保證
DateNode數(shù)據(jù)在讀取時校驗失敗,則從其他數(shù)據(jù)節(jié)點讀取數(shù)據(jù)。
元數(shù)據(jù)可靠性保證
采用日志機制操作元數(shù)據(jù),同時元數(shù)據(jù)存放在主備NameNode上。
快照機制實現(xiàn)了文件系統(tǒng)常見的快照機制,保證數(shù)據(jù)誤操作時,能及時恢復。
安全模式
HDFS提供獨有的安全模式機制,在數(shù)據(jù)節(jié)點故障時,能防止故障擴散。
HDFS高可靠性(HA):
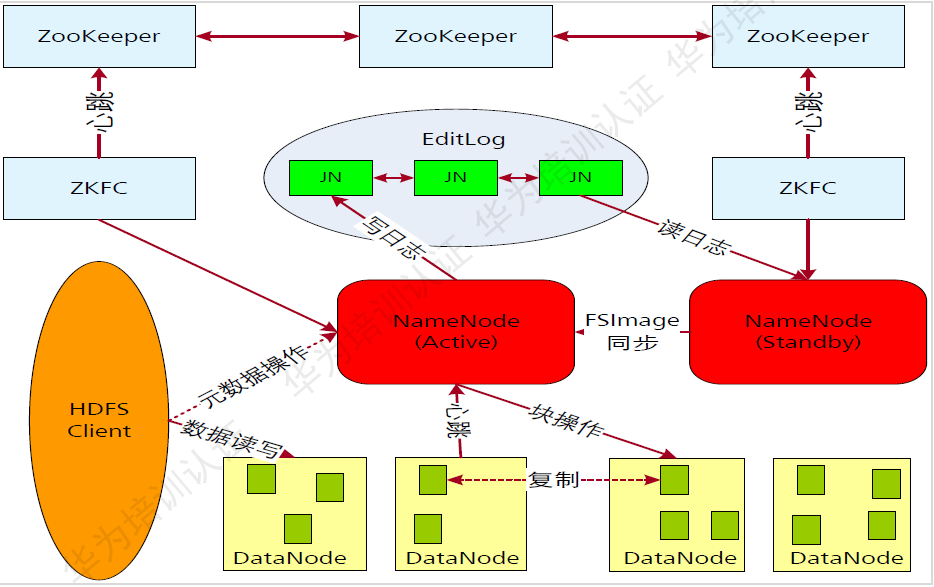 HDFS高可靠性
HDFS高可靠性
HA解決的是一個熱備份的問題。
HDFS的高可靠性(HA)架構(gòu)在基本架構(gòu)上增加了一下組件:
ZooKeeper:分布式協(xié)調(diào),主要用來存儲HA下的狀態(tài)文件,主備信息、ZK個數(shù)建議3個及以上且為奇數(shù)個。 NmaeNode主備:NmaeNode主備模式,主提供服務(wù),備合并元數(shù)據(jù)并作為主的熱備。 ZKFC(Zookeeper Failover Controller)用于控制NmaeNode節(jié)點的主備狀態(tài)。 JN(JournalNode)日志節(jié)點:用于共享存儲NmaeNode生成的Editlog。
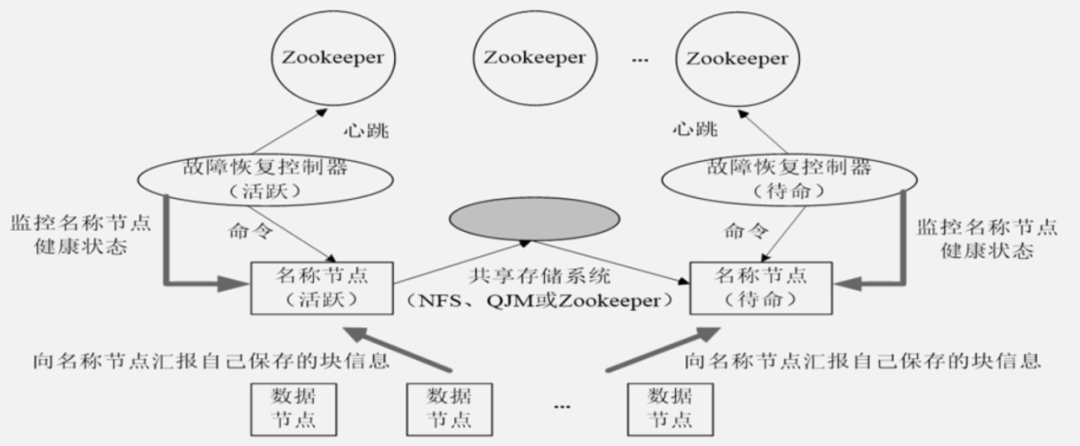 HA
HA
處于待命狀態(tài)的名稱節(jié)點和處于活狀態(tài)的名稱節(jié)點,它們元數(shù)據(jù)的兩個方面的信息是怎么同步的:
處于待命狀態(tài)的名稱節(jié)點當中,它的兩方面元數(shù)據(jù),一個就是Editlog,它是通過共享存儲系統(tǒng)來獲得同步的,處于活躍狀態(tài)的名稱節(jié)點已發(fā)生變化,馬上寫入到共享存儲系統(tǒng),然后這共享存儲系統(tǒng)會通知待命的名稱節(jié)點把它取走,這樣可以保證Editlog上兩者可以保持同步。對于映射表信息而言,也就是一個文件包含幾個塊,這些塊被保存到哪個數(shù)據(jù)節(jié)點上面。這種映射信息,它的 實時的維護是通過底層數(shù)據(jù)節(jié)點,不斷同時向活躍名稱節(jié)點和待命節(jié)點名稱節(jié)點匯報來進行維護的。這就是它的基本原理。
HDFS聯(lián)邦(Federation):
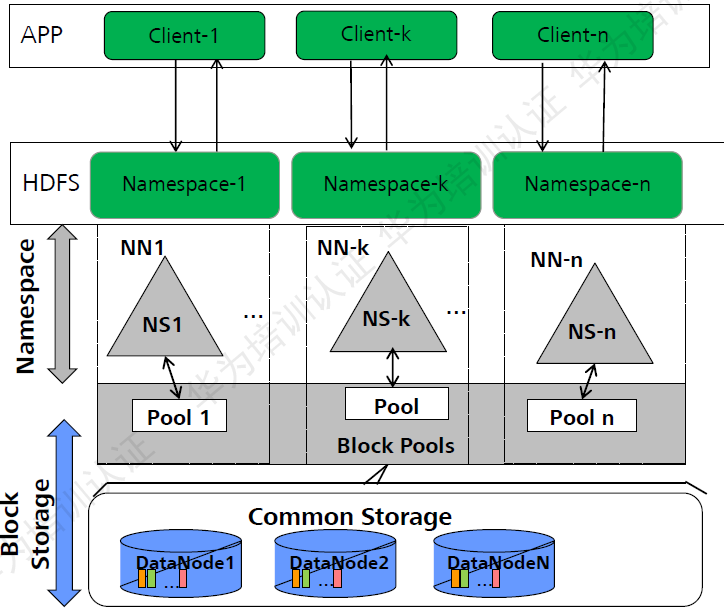
HDFS Federation主要能夠解決,單名稱節(jié)點中存在的以下問題:
HDFS集群的擴展性問題。
有了多個名稱節(jié)點,每個名稱節(jié)點都可以各自的去管理一部分目錄。管理自己對應的子命名空間的子目錄,這樣就可以讓一個集群擴展到更多節(jié)點。
在HDFS1.0中會受到內(nèi)存的限制,制約文件存儲數(shù)目等限制。一個名稱節(jié)點存儲的文件數(shù)目是有限的。
性能更高效
多個名稱節(jié)點各自都管理它不同的數(shù)據(jù),而且可以同時對外服務(wù),所以可以提供更高的數(shù)據(jù)的吞吐率。
良好的隔離性
因為它已經(jīng)根據(jù)不同業(yè)務(wù)數(shù)據(jù)要求,進行了子空間的劃分,某種業(yè)務(wù)數(shù)據(jù)可能歸某個名稱節(jié)點管理,另外一種業(yè)務(wù)數(shù)據(jù)屬于另外一個命名空間,歸另外一個名稱節(jié)點管理。所以不同數(shù)據(jù)都分給不同名稱節(jié)點去管理,這樣就可以有效地對不同應用程序進行隔離。不會導致一個應用程序消耗過多資源,而影響另外一個應用程序運行的問題。
HDFS不能解決單點故障問題。
數(shù)據(jù)副本機制:
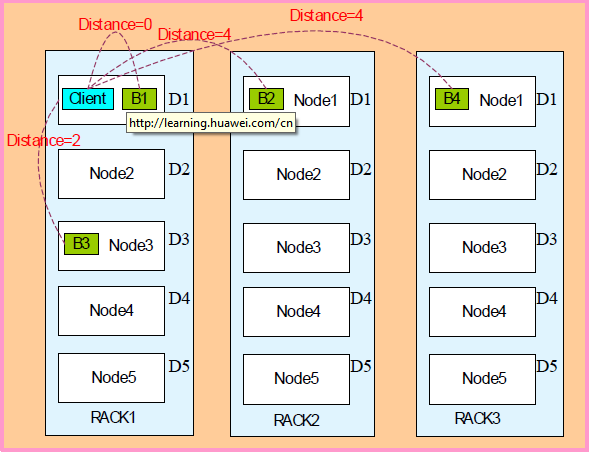
副本距離計算公式:
Distance(Rack1/D1,Rack1/D1)= 0 ,同一臺服務(wù)器的距離為0. Distance (Rack1/D1, Rack1/D3) = 2;同一機架不同的服務(wù)器距離為2. DIstance(Rack1/D1, Rack2/D1)= 4 ;不同機架的服務(wù)器距離為4.
副本放置策略:
第一個副本在本地機器。 第二個副本在遠端機架的節(jié)點。 第三個副本看之前連個副本是否在同一機架,如果是則選擇其他機架,否則選擇和第一個副本相同機架的不同節(jié)點。 第四個及以上,隨機選擇副本存放位置。
配置HDFS數(shù)據(jù)存儲策略:
默認情況下,HDFS NmaeNode自動選擇DateNode保存數(shù)據(jù)的副本。在實際義務(wù)中,存在以下場景:
DateNode上存在的不同存儲設(shè)備,數(shù)據(jù)需要選擇一個合適的設(shè)備分級存儲數(shù)據(jù)。 DateNode不同目錄中的數(shù)據(jù)重要程度不同,數(shù)據(jù)需要根據(jù)目錄標簽選擇一個格式的DateNode節(jié)點保存。 DateNode集群使用了異構(gòu)服務(wù)器,關(guān)鍵數(shù)據(jù)需要保存在具有高度可靠性的節(jié)點組中。
配置DateNode使用分級存儲:
HDFS的分級存儲框架提供了RAM_DISK(內(nèi)存盤)、DISK(機械硬盤)、ARCHIVE(高密度低成本存儲介質(zhì))、SSD(固態(tài)硬盤)四種存儲類型的存儲設(shè)備。 通過對四種存儲類型進行合理組合,即可形成使用與不公場景的存儲策略。
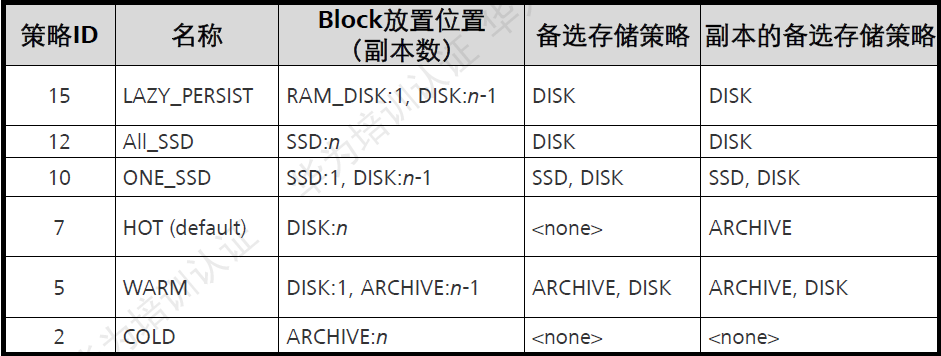
配置標簽存儲策略:
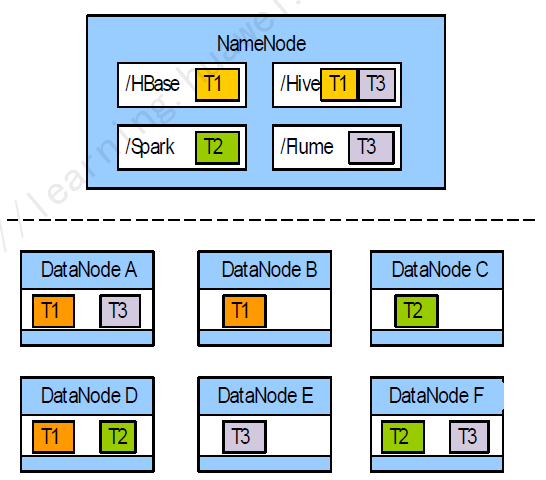
配置DateNode使用標簽存儲:
用戶通過數(shù)據(jù)特征靈活配置HDFS數(shù)據(jù)塊存放策略,即為一個HDFS目錄設(shè)置一個標簽表達式,每個DateNode可以對應一個或多個標簽;當基于標簽的數(shù)據(jù)塊存放策略為指定目錄下的文件選擇DateNode節(jié)點進行存放時,根據(jù)文件的標簽表達式選擇出將要存放的DateNode節(jié)點范圍,然后在這個DateNode節(jié)點范圍內(nèi),遵守下一個指定的數(shù)據(jù)塊存放策略進行存放。
配置DateNode使用節(jié)點組存儲:
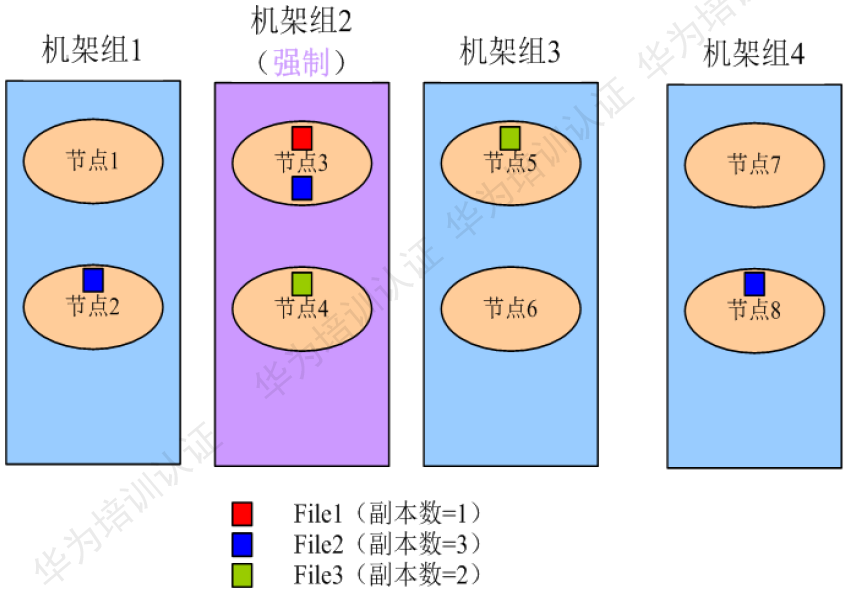
配置DateNode使用節(jié)點組存儲:
關(guān)鍵數(shù)據(jù)根據(jù)實際業(yè)務(wù)需要保存在具有高度可靠性的節(jié)點中,此時DateNode組成了異構(gòu)集群。通過修改DateNode的存儲策略,系統(tǒng)可以將數(shù)據(jù)強制保存在指定的節(jié)點組中。
使用約束:
第一份副本將從強制機架組(機架組2)中選出,如果在強制機架組中沒用可用節(jié)點,則寫入失敗。 第二份副本將從本地客戶端機器或機架組中的隨機節(jié)點(當客戶端機架組不為強制機架組時)選出。 第三份副本將從其他機架組中選出。 各副本應放在不同的機架組中。如果所需副本的數(shù)量大于可用的機架組數(shù)量,則會將多出的副本存放在隨機機架組中。
Colocation同分布:
同分布(Colocation)的定義:將存在關(guān)聯(lián)關(guān)系的數(shù)據(jù)或可能要進行關(guān)聯(lián)操作的數(shù)據(jù)存儲在相同的存儲節(jié)點上。
按照下圖存放,假設(shè)要將文件A和文件D進行關(guān)聯(lián)操作,此時不可避免地要進行大量的數(shù)據(jù)搬遷,整個集群將由于數(shù)據(jù)傳輸占用大量網(wǎng)絡(luò)帶寬,嚴重影響大數(shù)據(jù)的處理速度與系統(tǒng)性能。
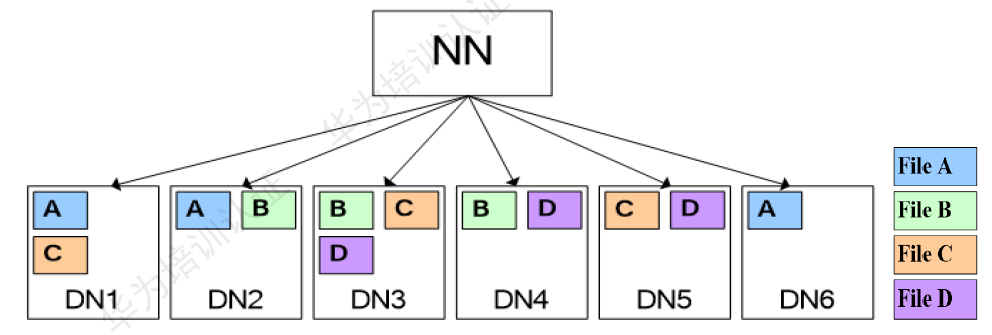
HDFS文件同分布的特性,將那些需要進行關(guān)聯(lián)操作的文件存放在相同的數(shù)據(jù)節(jié)點上,在進行關(guān)聯(lián)操作計算是避免了到其他數(shù)據(jù)節(jié)點上獲取數(shù)據(jù),大大降低了網(wǎng)絡(luò)帶寬的占用。
使用同分布特性,文件A、D進行join時,由于其對應的block都在相同的節(jié)點,因此大大降低了資源消耗。如下圖:
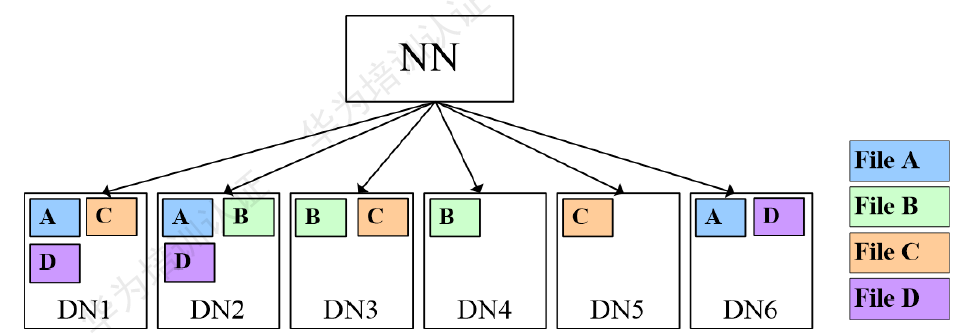 效果圖
效果圖
HDFS架構(gòu)其他關(guān)鍵設(shè)計要點說明:
統(tǒng)一的文件系統(tǒng):
HDFS對外僅呈現(xiàn)一個統(tǒng)一的文件系統(tǒng)。
統(tǒng)一的通訊協(xié)議:
統(tǒng)一采用RPC方式通信、NmaeNode被動的接收Client,DateNode的RPC請求。
空間回收機制:
支持回收站機制,以及副本數(shù)的動態(tài)設(shè)置機制。
數(shù)據(jù)組織:
數(shù)據(jù)存儲以數(shù)據(jù)塊為單位,存儲在操作系統(tǒng)的HDFS文件系統(tǒng)上。
訪問方式:
提供Java API,http,shell方式訪問HDFS數(shù)據(jù)。
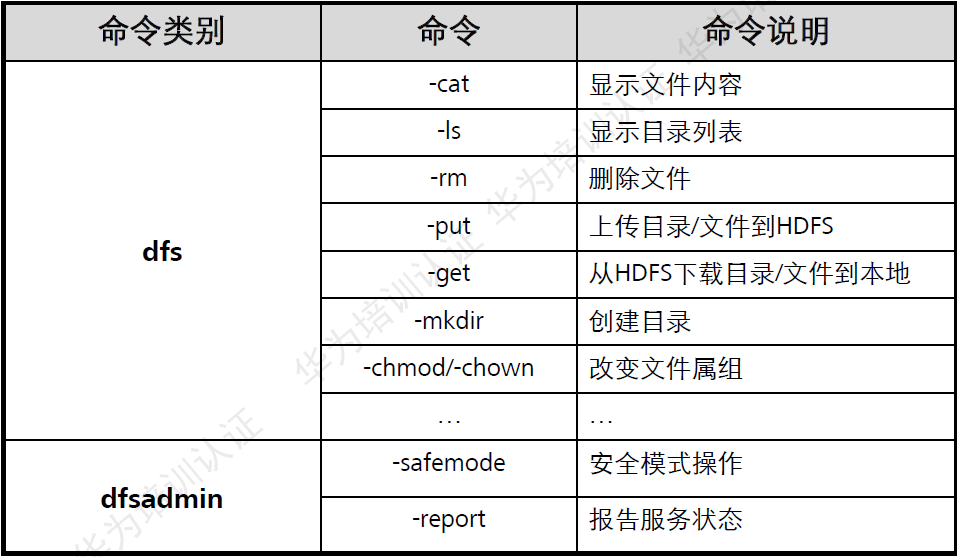
常用的shell命令:
NameNode和DateNode的對比:
| NameNode | DateNode |
|---|---|
| 存儲文件內(nèi)容 | |
| 文件內(nèi)容保存在磁盤 | |
| 保存文件,block,DateNode之間的映射關(guān)系 | 維護了block id到datenode本地文件的映射關(guān)系。 |
名稱節(jié)點的數(shù)據(jù)結(jié)構(gòu):
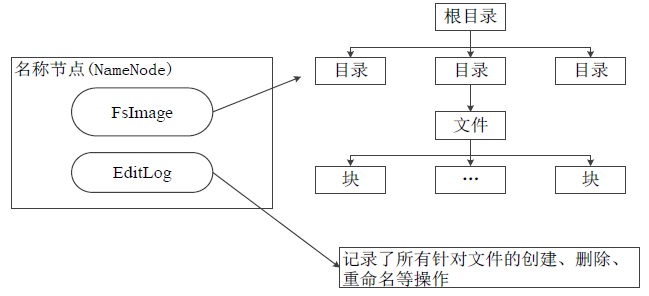
在HDFS中,名稱節(jié)點(NameNode)負責管理分布式文件系統(tǒng)的命名空間(Namespace),保存了兩個核心的數(shù)據(jù)結(jié)構(gòu),即FsImage和EditLog
FsImage用于維護文件系統(tǒng)樹以及文件樹中所有的文件和文件夾的元數(shù)據(jù) 操作日志文件EditLog中記錄了所有針對文件的創(chuàng)建、刪除、重命名等操作 名稱節(jié)點記錄了每個文件中各個塊所在的數(shù)據(jù)節(jié)點的位置信息
 名稱節(jié)點數(shù)據(jù)結(jié)構(gòu)
名稱節(jié)點數(shù)據(jù)結(jié)構(gòu)
FsImage文件:
FsImage文件包含文件系統(tǒng)中所有目錄和文件inode的序列化形式。每個inode是一個文件或目錄的元數(shù)據(jù)的內(nèi)部表示,并包含此類信息:文件的復制等級、修改和訪問時間、訪問權(quán)限、塊大小以及組成文件的塊。對于目錄,則存儲修改時間、權(quán)限和配額元數(shù)據(jù).
FsImage文件沒有記錄塊存儲在哪個數(shù)據(jù)節(jié)點。而是由名稱節(jié)點把這些映射保留在內(nèi)存中,當數(shù)據(jù)節(jié)點加入HDFS集群時,數(shù)據(jù)節(jié)點會把自己所包含的塊列表告知給名稱節(jié)點,此后會定期執(zhí)行這種告知操作,以確保名稱節(jié)點的塊映射是最新的。
名稱節(jié)點的啟動:
在名稱節(jié)點啟動的時候,它會將FsImage文件中的內(nèi)容加載到內(nèi)存中,之后再執(zhí)行EditLog文件中的各項操作,使得內(nèi)存中的元數(shù)據(jù)和實際的同步,存在內(nèi)存中的元數(shù)據(jù)支持客戶端的讀操作。 一旦在內(nèi)存中成功建立文件系統(tǒng)元數(shù)據(jù)的映射,則創(chuàng)建一個新的FsImage文件和一個空的EditLog文件。 名稱節(jié)點起來之后,HDFS中的更新操作會重新寫到EditLog文件中,因為FsImage文件一般都很大(GB級別的很常見),如果所有的更新操作都往FsImage文件中添加,這樣會導致系統(tǒng)運行的十分緩慢,但是,如果往EditLog文件里面寫就不會這樣,因為EditLog 要小很多。每次執(zhí)行寫操作之后,且在向客戶端發(fā)送成功代碼之前,edits文件都需要同步更新。
名稱節(jié)點運行期間Editlog不斷變大的問題:
在名稱節(jié)點運行期間,HDFS的所有更新操作都是直接寫到EditLog中,久而久之, EditLog文件將會變得很大。 雖然這對名稱節(jié)點運行時候是沒有什么明顯影響的,但是,當名稱節(jié)點重啟的時候,名稱節(jié)點需要先將FsImage里面的所有內(nèi)容映像到內(nèi)存中,然后再一條一條地執(zhí)行EditLog中的記錄,當EditLog文件非常大的時候,會導致名稱節(jié)點啟動操作非常慢,而在這段時間內(nèi)HDFS系統(tǒng)處于安全模式,一直無法對外提供寫操作,影響了用戶的使用。
如何解決?答案是:SecondaryNameNode第二名稱節(jié)點
第二名稱節(jié)點是HDFS架構(gòu)中的一個組成部分,它是用來保存名稱節(jié)點中對HDFS 元數(shù)據(jù)信息的備份,并減少名稱節(jié)點重啟的時間。SecondaryNameNode一般是單獨運行在一臺機器上。
SecondaryNameNode的工作情況:
(1)SecondaryNameNode會定期和NameNode通信,請求其停止使用EditLog文件,暫時將新的寫操作寫到一個新的文件edit.new上來,這個操作是瞬間完成,上層寫日志的函數(shù)完全感覺不到差別;
(2)SecondaryNameNode通過HTTP GET方式從NameNode上獲取到FsImage和EditLog文件,并下載到本地的相應目錄下;
(3)SecondaryNameNode將下載下來的FsImage載入到內(nèi)存,然后一條一條地執(zhí)行EditLog文件中的各項更新操作,使得內(nèi)存中的FsImage保持最新;這個過程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode執(zhí)行完(3)操作之后,會通過post方式將新的FsImage文件發(fā)送到NameNode節(jié)點上 (5)NameNode將從SecondaryNameNode接收到的新的FsImage替換舊的FsImage文件,同時將edit.new替換EditLog文件,通過這個過程EditLog就變小了。
數(shù)據(jù)節(jié)點:
數(shù)據(jù)節(jié)點是分布式文件系統(tǒng)HDFS的工作節(jié)點,負責數(shù)據(jù)的存儲和讀取,會根據(jù)客戶端或者是名稱節(jié)點的調(diào)度來進行數(shù)據(jù)的存儲和檢索,并且向名稱節(jié)點定期發(fā)送自己所存儲的塊的列表。 每個數(shù)據(jù)節(jié)點中的數(shù)據(jù)會被保存在各自節(jié)點的本地Linux文件系統(tǒng)中。
推薦閱讀:
企業(yè)IT技術(shù)架構(gòu)規(guī)劃方案
論數(shù)字化轉(zhuǎn)型——轉(zhuǎn)什么,如何轉(zhuǎn)?
企業(yè)10大管理流程圖,數(shù)字化轉(zhuǎn)型從業(yè)者必備!
end