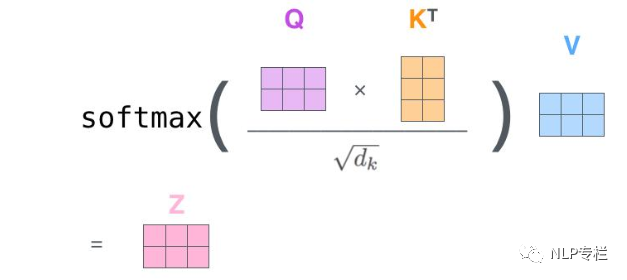BERT_self-attention原理(面試必備)
文章目錄
1. 概述
2. Attention is all your need
3. Self-Attention in Detail
3.1. 使用向量
3.2. Matrix Calculation of Self-Attention
1. 概述
本系列文章希望對google BERT模型做一點(diǎn)解讀。打算采取一種由點(diǎn)到線到面的方式,從基本的元素講起,逐漸展開。
講到BERT就不能不提到Transformer,而self-attention則是Transformer的精髓所在。簡單來說,可以將Transformer看成和RNN類似的特征提取器,而其有別于RNN、CNN這些傳統(tǒng)特征提取器的是,它另辟蹊徑,采用的是attention機(jī)制對文本序列進(jìn)行特征提取。
所以我們從self-Attention出發(fā)。
文章內(nèi)容參考https://jalammar.github.io/illustrated-transformer/,jalammar的博客十分通俗易懂,且切中要害。
2. Attention is all your need
盡管attention機(jī)制由來已久,但真正令其聲名大噪的是google 2017年的這篇名為《attention is all your need》的論文。
讓我們從一個簡單的例子看起:
假設(shè)我們想用機(jī)器翻譯的手段將下面這句話翻譯成中文:
“The animal didn’t cross the street because it was too tired”
當(dāng)機(jī)器讀到“it”時,“it”代表“animal”還是“street”呢?對于人類來講,這是一個極其簡單的問題,但是對于機(jī)器或者說算法來講卻十分不容易。
self-Attention則是處理此類問題的一個解決方案,也是目前看起來一個比較好的方案。當(dāng)模型處理到“it”時,self-Attention可以將“it”和“animal‘聯(lián)系到一起。
它是怎么做到的呢?
通俗地講,當(dāng)模型處理一句話中某一個位置的單詞時,self-Attention允許它看一看這句話中其他位置的單詞,看是否能夠找到能夠一些線索,有助于更好地表示(或者說編碼)這個單詞。
如果你對RNN比較熟悉的話,我們不妨做一個比較。RNN通過保存一個隱藏態(tài),將前面詞的信息編碼后依次往后面?zhèn)鬟f,達(dá)到利用前面詞的信息來編碼當(dāng)前詞的目的。而self-Attention仿佛有個上帝之眼,縱觀全局,看看上下文中每個詞對當(dāng)前詞的貢獻(xiàn)。

下面來看下具體是怎么實(shí)現(xiàn)的。
3. Self-Attention in Detail
首先,來看下怎樣使用向量來計算self-attention,緊接著看如何用矩陣來計算self-attention。
3.1. 使用向量
如下圖所示,一般而言,輸入的句子進(jìn)入模型的第一步是對單詞進(jìn)行embedding,每個單詞對應(yīng)一個embedding。對于每個embedding,我們創(chuàng)建三個向量,Query、Key和Value向量。我們?nèi)绾蝸韯?chuàng)建三個向量呢?如圖,我們假設(shè)embedding的維度為4,我們希望得到一個維度為3的Query、Key和Value向量,只需將每個embedding乘上一個維度為4*3的矩陣即可。這些矩陣就是訓(xùn)練過程中要學(xué)習(xí)的。
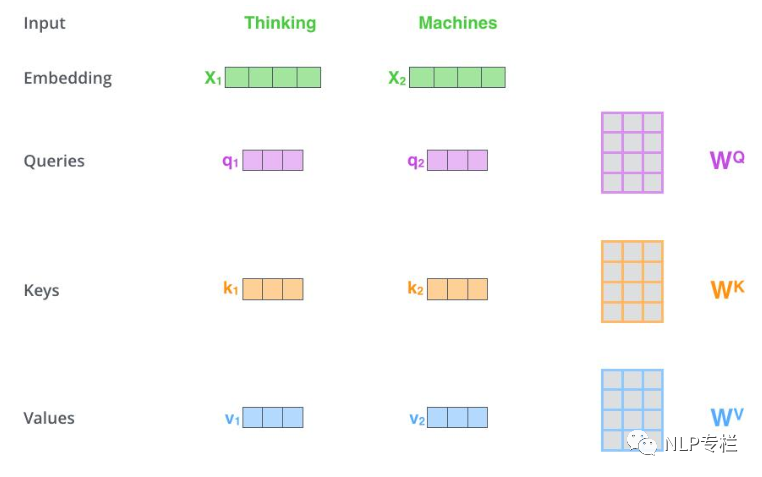
那么,Query、Key和Value向量代表什么呢?他們在attention的計算中發(fā)揮了什么樣的作用呢?
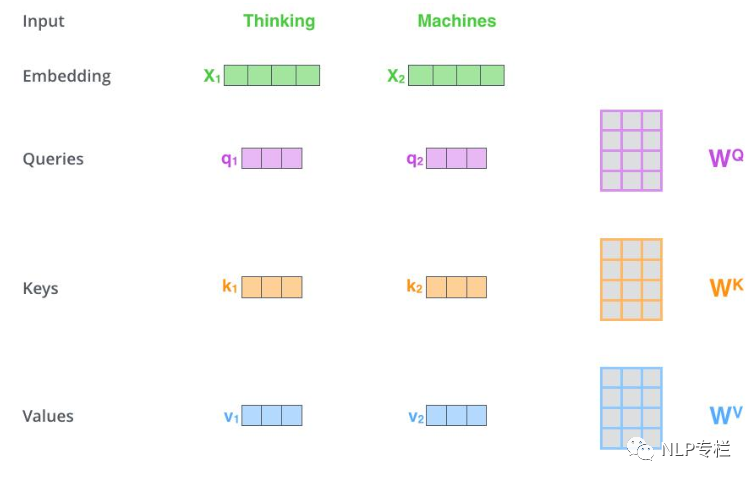
我們用一個例子來說明:
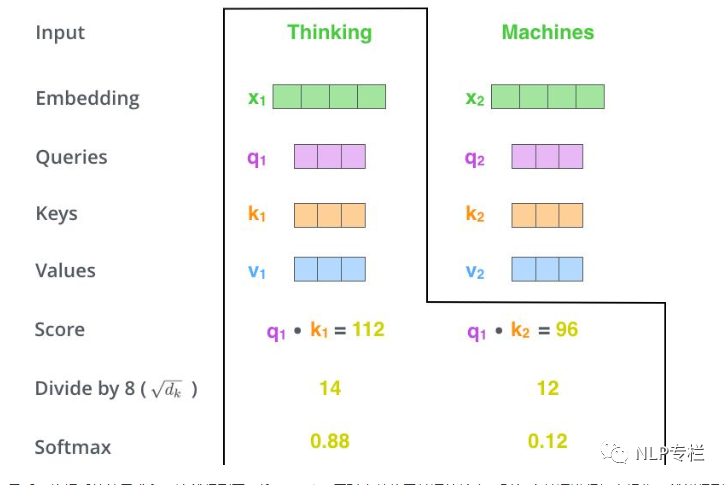
首先要明確一點(diǎn),self-attention其實(shí)是在計算每個單詞對當(dāng)前單詞的貢獻(xiàn),也就是對每個單詞對當(dāng)前單詞的貢獻(xiàn)進(jìn)行打分score。假設(shè)我們現(xiàn)在要計算下圖中所有單詞對第一個單詞"Thinking"的打分。那么分分?jǐn)?shù)如何計算呢,只需要將該單詞的Query向量和待打分單詞的Key向量做點(diǎn)乘即可。比如,第一個單詞對第一個單詞的分?jǐn)?shù)為q1× k1,第二個單詞對第一個單詞的分?jǐn)?shù)為q1×k2。
我們現(xiàn)在得到了兩個單詞對第一個單詞的打分(分?jǐn)?shù)是個數(shù)字了),然后將其進(jìn)行softmax歸一化。需要注意的是,在BERT模型中,作者在softmax之前將分?jǐn)?shù)除以了Key的維度的平方根(據(jù)說可以保持梯度穩(wěn)定)。softmax得到的是每個單詞在Thinking這個單詞上的貢獻(xiàn)的權(quán)重。顯然,當(dāng)前單詞對其自身的貢獻(xiàn)肯定是最大的。
接著就是Value向量登場的地方了。將上面的分?jǐn)?shù)分別和Value向量相乘,注意這里是對應(yīng)位置相乘。
最后,將相乘的結(jié)果求和,這就得到了self-attention層對當(dāng)前位置單詞的輸出。對每個單詞進(jìn)行如上操作,就能得到整個句子的attention輸出了。在實(shí)際使用過程中,一般采用矩陣計算使整個過程更加高效。
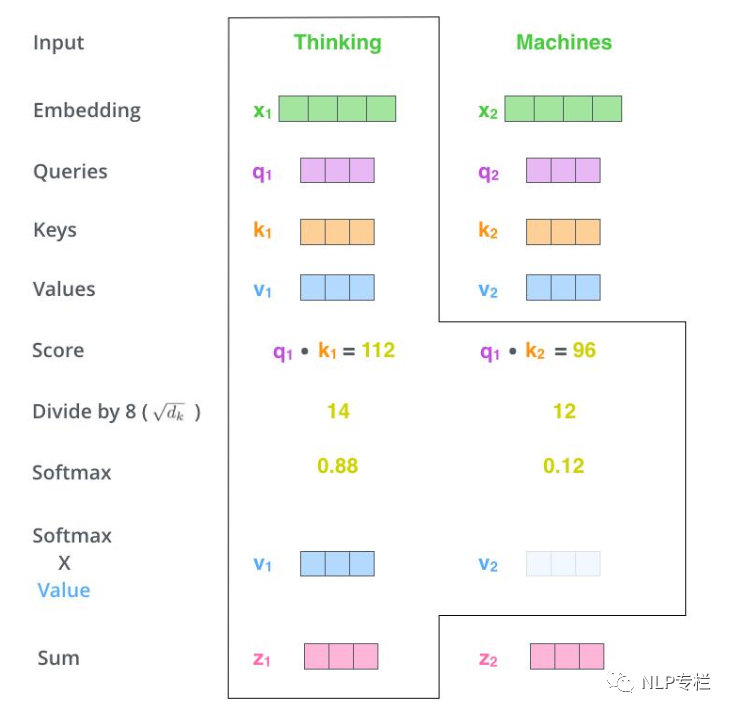
在開始矩陣計算之前,先回顧總結(jié)一下上面的步驟:
創(chuàng)建Query、Key、Value向量
計算每個單詞在當(dāng)前單詞的分?jǐn)?shù)
將分?jǐn)?shù)歸一化后與Value相乘
求和
值得注意的是,上面闡述的過程實(shí)際上是Attention機(jī)制的計算流程,對于self-Attention,Query=Value。
3.2. Matrix Calculation of Self-Attention
其實(shí)矩陣計算就是將上面的向量放在一起,同時參與計算。
首先,將embedding向量pack成一個矩陣X。假設(shè)我們有一句話有長度為10,embedding維度為4,那么X的維度為(10 × 4).
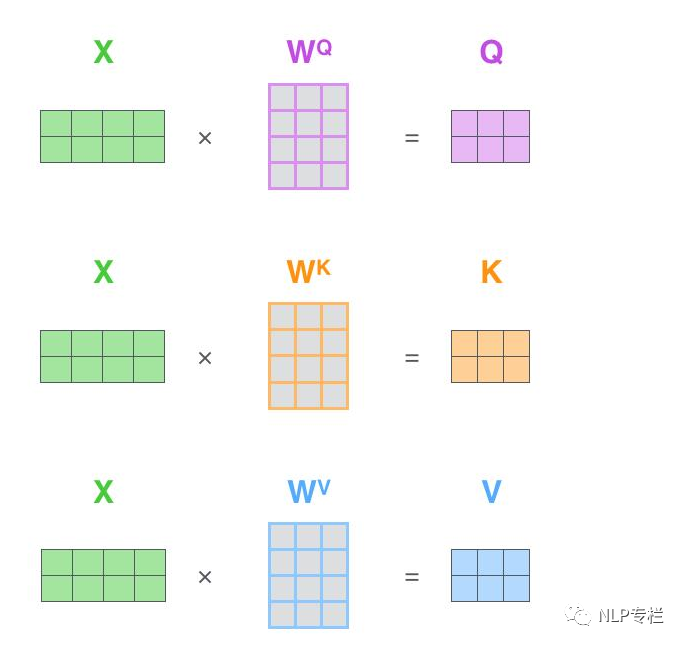
假設(shè)我們設(shè)定Q、K、V的維度為3.第二步我們構(gòu)造一個維度為(4×3)的權(quán)值矩陣。將其與X做矩陣乘法,得到一個10×3的矩陣,這就能得到Query了。依樣畫葫蘆,同樣可以得到Key和Value。
最后,將Query和Key相乘,得到打分,然后經(jīng)過softmax,接著乘上V的到最終的輸出。