
實操教程|我的PyTorch模型比內(nèi)存還大,怎么訓練呀?

極市導讀
本文介紹了一種技術(shù):梯度檢查點。通過從計算圖中省略一些激活值,減少了計算圖使用的內(nèi)存,降低了總體內(nèi)存壓力。 >>公眾號后臺回復“79”或者“陳鑫”獲得CVPR 2021:TransT 直播鏈接
隨著深度學習的飛速發(fā)展,模型越來越臃腫,哦不,先進,運行SOTA模型的主要困難之一就是怎么把它塞到 GPU 上,畢竟,你無法訓練一個設備裝不下的模型。改善這個問題的技術(shù)有很多種,例如,分布式訓練和混合精度訓練。
本文將介紹另一種技術(shù): 梯度檢查點(gradient checkpointing)。簡單的說,梯度檢查點的工作原理是在反向時重新計算深層神經(jīng)網(wǎng)絡的中間值(而通常情況是在前向時存儲的)。這個策略是用時間(重新計算這些值兩次的時間成本)來換空間(提前存儲這些值的內(nèi)存成本)。
文末有一個示例基準測試,它顯示了梯度檢查點減少了模型 60% 的內(nèi)存開銷(以增加 25% 的訓練時間為代價)。
詳細代碼請查看我的 GitHub 庫: https://github.com/spellml/tweet-sentiment-extraction/blob/master/notebooks/5-checkpointing.ipynb
>>> 神經(jīng)網(wǎng)絡如何使用內(nèi)存
為了理解梯度檢查點是如何起作用的,我們首先需要了解一下模型內(nèi)存分配是如何工作的。
神經(jīng)網(wǎng)絡使用的總內(nèi)存基本上是兩個部分的和。
第一部分是模型使用的靜態(tài)內(nèi)存。盡管 PyTorch 模型中內(nèi)置了一些固定開銷,但總的來說幾乎完全由模型權(quán)重決定。當今生產(chǎn)中使用的現(xiàn)代深度學習模型的總參數(shù)在100萬到10億之間。作為參考,一個帶 16GB GPU 內(nèi)存的 NVIDIA T4 的實際限制大約在1-1.5億個參數(shù)之間。
第二部分是模型的計算圖所占用的動態(tài)內(nèi)存。在訓練模式下,每次通過神經(jīng)網(wǎng)絡的前向傳播都為網(wǎng)絡中的每個神經(jīng)元計算一個激活值,這個值隨后被存儲在所謂的計算圖中。必須為批中的每個單個訓練樣本存儲一個值,因此數(shù)量會迅速的累積起來。總開銷由模型大小和批次大小決定,一般設置最大批次大小限制來適配你的 GPU 內(nèi)存。
要了解更多關(guān)于 PyTorch autograd 的信息,請查看我的 Kaggle 筆記本《PyTorch autograd 解釋》: https://www.kaggle.com/residentmario/pytorch-autograd-explained
>>> 梯度檢查點是如何起作用的
大型模型在靜態(tài)和動態(tài)方面都很耗資源。首先,它們很難適配 GPU,而且哪怕你把它們放到了設備上,也很難訓練,因為批次大小被迫限制的太小而無法收斂。
現(xiàn)有的各種技術(shù)可以改善這些問題中的一個或兩個。梯度檢查點就是這樣一種技術(shù); 分布式訓練,是另一種技術(shù)。
梯度檢查點(gradient checkpointing) 的工作原理是從計算圖中省略一些激活值。這減少了計算圖使用的內(nèi)存,降低了總體內(nèi)存壓力(并允許在處理過程中使用更大的批次大小)。
但是,一開始存儲激活的原因是,在反向傳播期間計算梯度時需要用到激活。在計算圖中忽略它們將迫使 PyTorch 在任何出現(xiàn)這些值的地方重新計算,從而降低了整體計算速度。
因此,梯度檢查點是計算機科學中折衷的一個經(jīng)典例子,即在內(nèi)存和計算之間的權(quán)衡。
PyTorch 通過 torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 提供梯度檢查點,根據(jù)官方文檔的 notes,它實現(xiàn)了如下功能,在前向傳播時,PyTorch 將保存模型中的每個函數(shù)的輸入元組。在反向傳播過程中,對于每個函數(shù),輸入元組和函數(shù)的組合以實時的方式重新計算,插入到每個需要它的函數(shù)的梯度公式中,然后丟棄。網(wǎng)絡計算開銷大致相當于每個樣本通過模型前向傳播開銷的兩倍。
梯度檢查點首次發(fā)表在2016年的論文 《Training Deep Nets With Sublinear Memory Cost》 中。論文聲稱提出的梯度檢查點算法將模型的動態(tài)內(nèi)存開銷從 O(n)(n 為模型中的層數(shù))降低到 O(sqrt(n)),并通過實驗展示了將 ImageNet 的一個變種從 48GB 壓縮到了 7GB 內(nèi)存占用。
>>> 測試 API
PyTorch API 中有兩個不同的梯度檢查點方法,都在 torch.utils.checkpoint 命名空間中。兩者中比較簡單的一個是 checkpoint_sequential,它被限制用于順序模型(例如使用 torch.nn.Sequential wrapper 的模型)。另一個是更靈活的 checkpoint,可以用于任何模塊。
下面是一個完整的代碼示例,顯示了 checkpoint_sequential 的實際用法:
import torchimport torch.nn as nn
from torch.utils.checkpoint import checkpoint_sequential
# a trivial modelmodel = nn.Sequential( nn.Linear(100, 50), nn.ReLU(), nn.Linear(50, 20), nn.ReLU(), nn.Linear(20, 5), nn.ReLU())
# model inputinput_var = torch.randn(1, 100, requires_grad=True)
# the number of segments to divide the model intosegments = 2
# finally, apply checkpointing to the model# note the code that this replaces:# out = model(input_var)out = checkpoint_sequential(modules, segments, input_var)
# backpropagateout.sum().backwards()
如你所見,checkpoint_sequential 替換了 module 對象上的 forward 或 __call__ 方法。out 幾乎和我們調(diào)用 model(input_var) 時得到的張量一樣; 關(guān)鍵的區(qū)別在于它缺少了累積值,并且附加了一些額外的元數(shù)據(jù),指示 PyTorch 在 out.backward() 期間需要這些值時重新計算。
值得注意的是,checkpoint_sequential 接受整數(shù)值的片段數(shù)作為輸入。checkpoint_sequential 將模型分割成 n 個縱向片段,并對除了最后一個的每個片段應用檢查點。
這工作很容易,但有一些主要的限制。你無法控制片段的邊界在哪里,也無法對整個模塊應用檢查點(而是其中的一部分)。
替代方法是使用更靈活的 checkpoint API. 下面展示了一個簡單的卷積模型:
class CIFAR10Model(nn.Module):def __init__(self):super().__init__()self.cnn_block_1 = nn.Sequential(*[nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25)])self.cnn_block_2 = nn.Sequential(*[nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25)])self.flatten = lambda inp: torch.flatten(inp, 1)self.head = nn.Sequential(*[nn.Linear(64 * 8 * 8, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 10)])def forward(self, X):X = self.cnn_block_1(X)X = self.cnn_block_2(X)X = self.flatten(X)X = self.head(X)return X
這種模型有兩個卷積塊,一些 dropout,和一個線性頭(10個輸出對應 CIFAR10 的10類)。
下面是這個模型使用梯度檢查點的更新版本:
class CIFAR10Model(nn.Module): def __init__(self): super().__init__() self.cnn_block_1 = nn.Sequential(*[ nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2) ]) self.dropout_1 = nn.Dropout(0.25) self.cnn_block_2 = nn.Sequential(*[ nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.Conv2d(64, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=2) ]) self.dropout_2 = nn.Dropout(0.25) self.flatten = lambda inp: torch.flatten(inp, 1) self.linearize = nn.Sequential(*[ nn.Linear(64 * 8 * 8, 512), nn.ReLU() ]) self.dropout_3 = nn.Dropout(0.5) self.out = nn.Linear(512, 10)
def forward(self, X): X = self.cnn_block_1(X) X = self.dropout_1(X) X = checkpoint(self.cnn_block_2, X) X = self.dropout_2(X) X = self.flatten(X) X = self.linearize(X) X = self.dropout_3(X) X = self.out(X) return X
在 forward 中顯示的 checkpoint 接受一個模塊(或任何可調(diào)用的模塊,如函數(shù))及其參數(shù)作為輸入。參數(shù)將在前向時被保存,然后用于在反向時重新計算其輸出值。
為了使其能夠工作,我們必須對模型定義進行一些額外的更改。
首先,你會注意到我們從卷積塊里刪除了 nn.Dropout 層; 這是因為檢查點與 dropout 不兼容(回想一下,樣本有效地通過模型兩次 —— dropout 會在每次通過時任意丟失不同的值,從而產(chǎn)生不同的輸出)。基本上,任何在重新運行時表現(xiàn)出非冪等(non-idempotent )行為的層都不應該應用檢查點(nn.BatchNorm 是另一個例子)。解決方案是重構(gòu)模塊,這樣問題層就不會被排除在檢查點片段之外,這正是我們在這里所做的。
其次,你會注意到我們在模型中的第二卷積塊上使用了檢查點,但是第一個卷積塊上沒有使用檢查點。這是因為檢查點簡單地通過檢查輸入張量的 requires_grad 行為來決定它的輸入函數(shù)是否需要梯度下降(例如,它是否處于 requires_grad=True 或 requires_grad=False模式)。模型的輸入張量幾乎總是處于 requires_grad=False 模式,因為我們感興趣的是計算相對于網(wǎng)絡權(quán)重而不是輸入樣本本身的梯度。因此,模型中的第一個子模塊應用檢查點沒多少意義: 它反而會凍結(jié)現(xiàn)有的權(quán)重,阻止它們進行任何訓練。更多細節(jié)請參考這個 PyTorch 論壇帖子:https://discuss.pytorch.org/t/use-of-torch-utils-checkpoint-checkpoint-causes-simple-model-to-diverge/116271
在 PyTorch 文檔(https://pytorch.org/docs/stable/checkpoint.html#)中還討論了 RNG 狀態(tài)以及與分離張量不兼容的一些其他細節(jié)。
完整的訓練代碼示例可以看這里:https://gist.github.com/ResidentMario/e3254172b4706191089bb63ecd610e21
和這里: https://gist.github.com/ResidentMario/9c3a90504d1a027aab926fd65ae08139
>>> 基準測試
作為一個快速的基準測試,我在 tweet-sentiment-extraction 上啟用了模型檢查點,這是一個基于 Twitter 數(shù)據(jù)的帶有 BERT 主干的情感分類器模型。你可以在這里看到代碼:https://github.com/spellml/tweet-sentiment-extraction。transformers 已經(jīng)將模型檢查點作為 API 的一個可選部分來實現(xiàn); 為我們的模型啟用它就像翻轉(zhuǎn)一個布爾值標記一樣簡單:
# code from model_5.py
cfg = transformers.PretrainedConfig.get_config_dict("bert-base-uncased")[0]cfg["output_hidden_states"] = Truecfg["gradient_checkpointing"] = True # NEW!cfg = transformers.BertConfig.from_dict(cfg)self.bert = transformers.BertModel.from_pretrained( "bert-base-uncased", config=cfg)
我對這個模型進行了四次訓練: 分別在 NVIDIA T4和 NVIDIA V100 GPU 上,包括檢查點和無檢查點模式。所有運行的批次大小為 64。以下是結(jié)果:
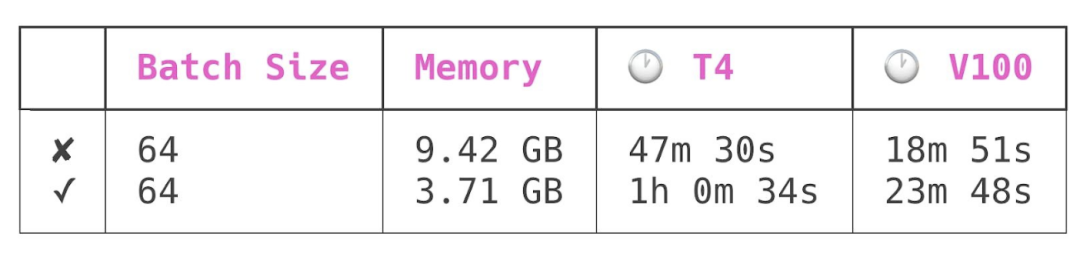
第一行是在模型檢查點關(guān)閉的情況下進行的訓練,第二行是在模型檢查點開啟的情況下進行的訓練。
模型檢查點降低了峰值模型內(nèi)存使用量 60% ,同時增加了模型訓練時間 25% 。
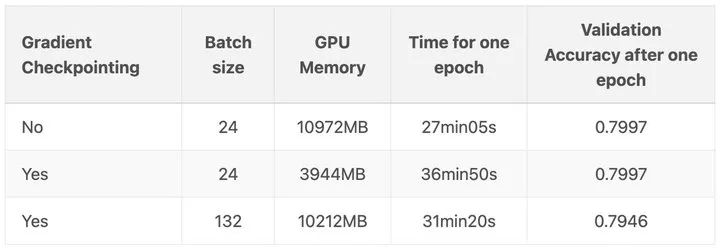
當然,你想要使用檢查點的主要原因可能是,這樣你就可以在 GPU 上使用更大的批次大小。在另一篇博文:https://qywu.github.io/2019/05/22/explore-gradient-checkpointing.html 中演示了這個很好的例子: 在他們的例子中,每批次樣本從 24 個提高到驚人的 132 個!
要處理大型神經(jīng)網(wǎng)絡,模型檢查點顯然是一個非常強大和有用的工具。
原文:https://spell.ml/blog/gradient-checkpointing-pytorch-YGypLBAAACEAefHs
本文亮點總結(jié)
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復“李鐸”獲取【極市線下沙龍】CVPR2021:通過反轉(zhuǎn)卷積的內(nèi)在性質(zhì)進行視覺識別資源
YOLO教程:YOLO系列(從V1到V5)模型解讀|YOLO算法最全綜述:從YOLOv1到Y(jié)OLOv5
實操教程:使用Transformer來做物體檢測?DETR模型完整指南|PyTorch編譯并調(diào)用自定義CUDA算子的三種方式
算法技巧(trick):半監(jiān)督深度學習訓練和實現(xiàn)|8點PyTorch提速技巧匯總
最新CV競賽:2021 高通人工智能應用創(chuàng)新大賽|CVPR 2021 | Short-video Face Parsing Challenge

# CV技術(shù)社群邀請函 #
備注:姓名-學校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
