
筆記 | 深入理解Transformer
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

背景知識(shí)
高層次理解
通過(guò)實(shí)例來(lái)理解Tensor
Encoding
高層次理解Self-Attention
Self-Attention的細(xì)節(jié)
Self-Attention矩陣乘法
Multi-headed完善
整體過(guò)程
使用位置編碼
編碼規(guī)則
殘差神經(jīng)網(wǎng)絡(luò) Residuals
Decoder
Linear 和 Softmax層
回顧訓(xùn)練過(guò)程
LossFunction
TargetModel Outputs
TrainedModel Outputs
一、背景知識(shí)
Transformer是Google 的論文 Attention is All You Need中提出
Google開(kāi)源了一個(gè)基于TensorFlow的 Tensor2Tensor的第三方庫(kù)
哈佛大學(xué)用PyTorch 對(duì) 這篇文章進(jìn)行了深度解讀:http://nlp.seas.harvard.edu/2018/04/03/attention.html
?
二、高層次理解
首先將Transformer理解成一個(gè)黑盒子,黑盒子的功能是翻譯,你輸入一個(gè)語(yǔ)句,它對(duì)你的輸入進(jìn)行翻譯操作。
? ? ?
? ? ? ?
? ? ?
黑盒子可以進(jìn)行展開(kāi),由兩部分組成:Encoders和Decoders
? ? ? ? ? ? ?
? ? ?
對(duì)黑盒子進(jìn)一步細(xì)化,可以發(fā)現(xiàn)由6個(gè)Encoder和6個(gè)Decoder組成
? ? ? ? ? ? ?
? ? ?
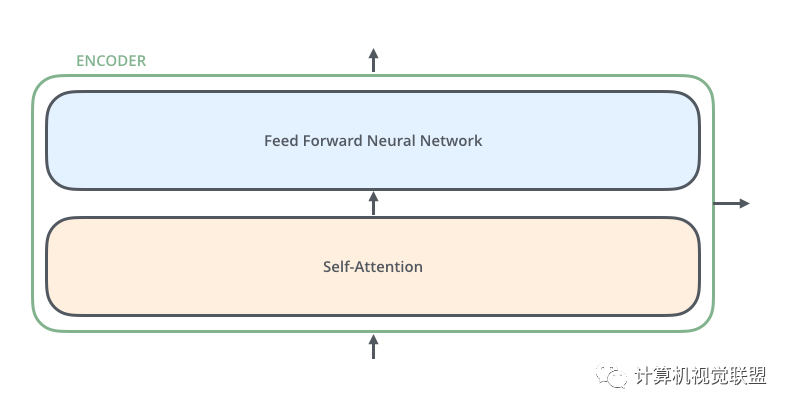
對(duì)于每一個(gè)Encoder,他們結(jié)構(gòu)都是相同的,但是權(quán)值不共享。每一層都包括兩部分:自監(jiān)督+全連接
? ? ? ? ? ? ?
? ? ?
Self-attention的輸入會(huì)被傳入一個(gè)全連接的前饋神經(jīng)網(wǎng)絡(luò),每個(gè)encoder的前饋神經(jīng)網(wǎng)絡(luò)的參數(shù)都是相同的,但是作用相互獨(dú)立。
Decoder部分也有相同的層級(jí)結(jié)構(gòu),但是中間多了一個(gè)Encoder-Decoder-Attention層,幫助專注于對(duì)應(yīng)的那個(gè)語(yǔ)句。(與Seq2Seq模型類似)
? ? ? ? ? ? ?
? ? ?
三、通過(guò)實(shí)例來(lái)理解Tensor
首先做一個(gè)embedding使得輸入的單詞成為向量,具體可看這篇博客:
https://blog.csdn.net/qq_41664845/article/details/84313419
? ? ? ? ? ? ?
? ? ?
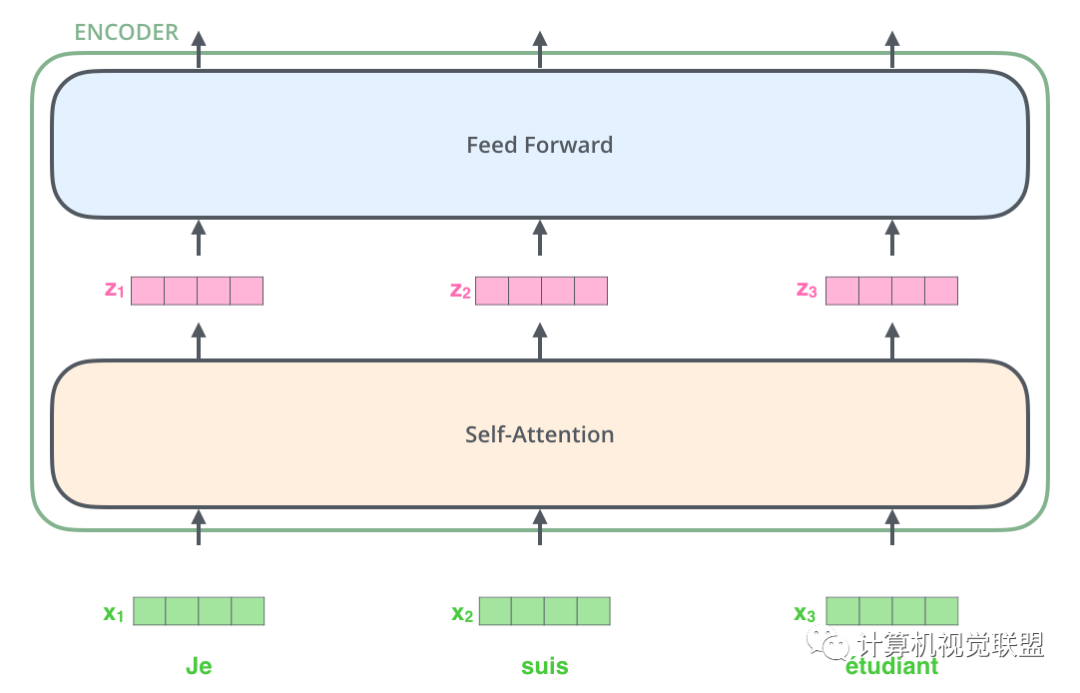
列表的大小和詞向量的維度大小都是可以設(shè)置的超參數(shù),一般設(shè)置訓(xùn)練數(shù)據(jù)集中最長(zhǎng)的句子的長(zhǎng)度。這個(gè)例子是把每個(gè)單詞編碼為512維的向量。
? ? ? ? ? ? ?
? ? ?
可以觀察到,x1,x2,x3輸入后通過(guò)self-attention,分別得到了z1,z2,z3,這點(diǎn)就要注意,其實(shí)z1,z2,z3這3個(gè)是通過(guò)x1,x2,x3一起合作產(chǎn)生的。
Encoding
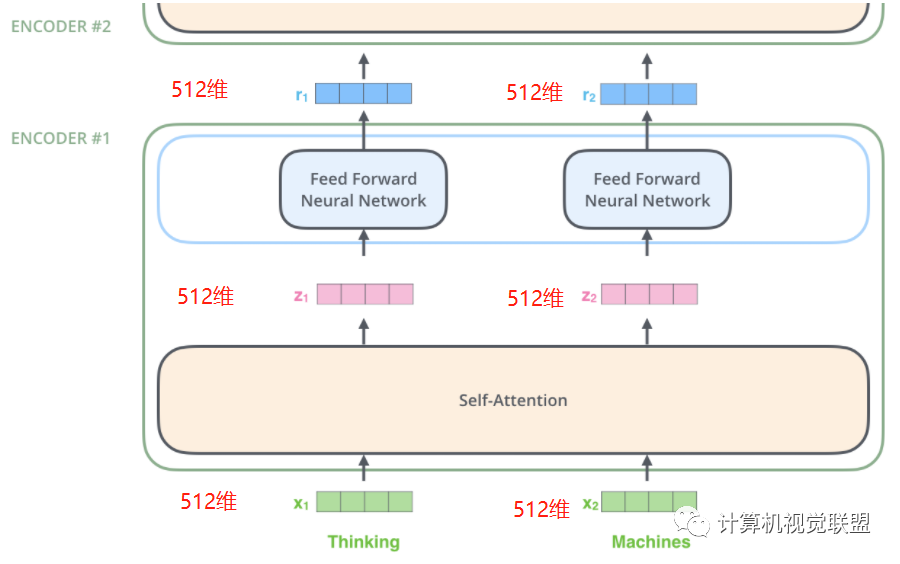
每一個(gè)Encoder接收一個(gè)512維的向量x作為輸入,然后傳遞Self-Attention,產(chǎn)生一個(gè)等量的512維的z,再經(jīng)過(guò)全連接神經(jīng)網(wǎng)絡(luò),輸出的r也是512維,然后傳遞給下一個(gè)encoder
? ? ? ? ? ? ?
? ? ?
注意,前饋神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)其實(shí)是一致的
? ? ?
四、高層次理解Self-Attention
假如輸入:
”The animal didn't cross the street because it was too tired”
這句話
那么句子中的“it”如何和“animal”關(guān)聯(lián)起來(lái)?
? ? ? ? ? ? ?
? ? ?
Self-Attention的細(xì)節(jié)
第一步:Q,K,V計(jì)算
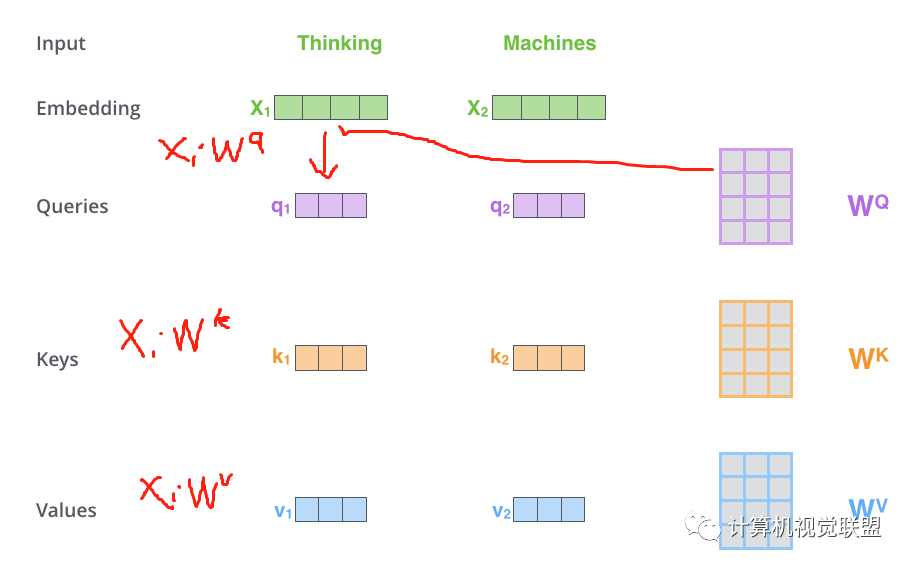
對(duì)于每個(gè)單詞,我們創(chuàng)建一個(gè)Query向量,一個(gè)Key向量和一個(gè)Value向量。這些向量是通過(guò)詞嵌入乘以我們訓(xùn)練過(guò)程中創(chuàng)建的3個(gè)訓(xùn)練矩陣而產(chǎn)生的。
輸入的向量維度是512維,新向量的維度64維。新向量的維度通過(guò)實(shí)際情況自己確定。
? ? ? ? ? ? ?
? ? ?
Multiplying?x1?by the?WQ?weight matrix produces?q1
? ? ? ? ? ? ?
? ? ?
第二步:點(diǎn)乘
? ? ? ?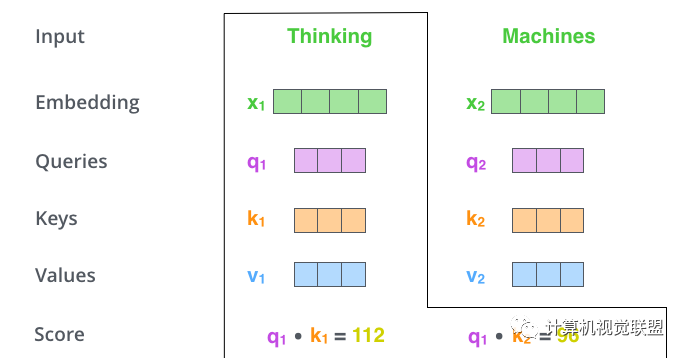 ? ? ?
? ? ?
q1和k1點(diǎn)乘,q1和k2點(diǎn)乘,注意!!!是q1和k2!看清楚,不是q2
第三步、第四步:
將點(diǎn)乘的結(jié)果除以sqrt(dk)。這個(gè)里面向量是64,開(kāi)方是8,那么就是除以8
然后進(jìn)行Softmax的操作
? ? ? ? ? ? ?
? ? ?
Softmax的操作得到的分?jǐn)?shù),就是當(dāng)前單詞在每個(gè)句子中每個(gè)單位位置的表示程度。
第五步、第六步:
將Values和Softmax的值相乘得到v1,v2,對(duì)當(dāng)前詞的關(guān)注度不變,對(duì)不相關(guān)的的進(jìn)行降低。
累加加權(quán)的向量得到z1
? ? ? ? ? ? ?
? ? ?
Self-Attention矩陣乘法
? ?第一步是去計(jì)算Query,Key和Value矩陣。X是x1和x2一起轉(zhuǎn)化為的矩陣。
? ? ? ?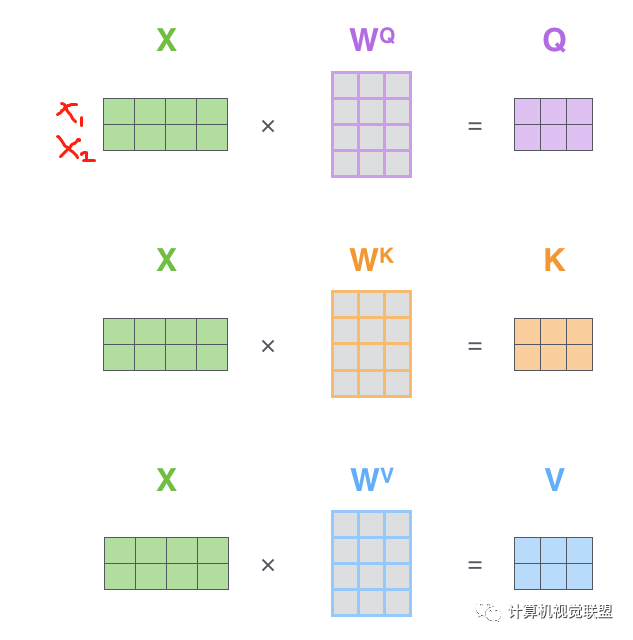 ? ? ?
? ? ?
然后一下子就操作得到后面的Z
? ? ? ?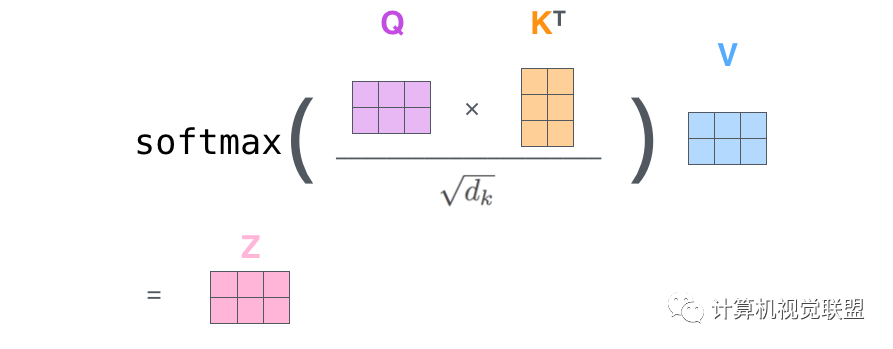 ? ? ?
? ? ?
Multi-headed 完善
擴(kuò)展了模型關(guān)注不同位置的能力
提供投影到不同的子空間subspace
? ? ? ? ? ? ?
? ? ?
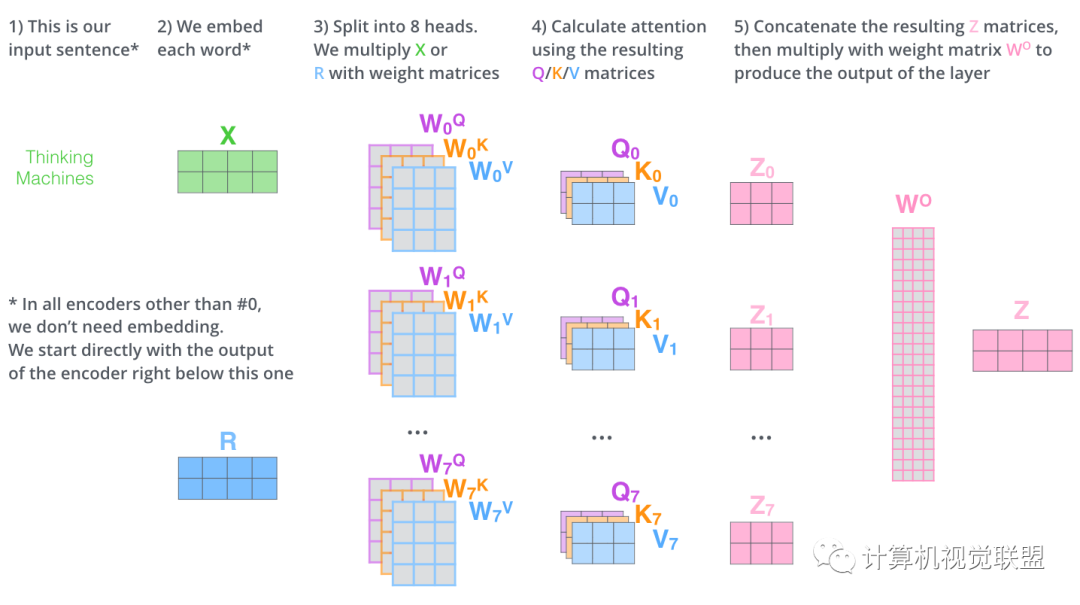
通過(guò)multi-headed attention,我們?yōu)槊總€(gè)“header”都獨(dú)立維護(hù)一套Q/K/V的權(quán)值矩陣。
使用8個(gè)時(shí)間點(diǎn)去計(jì)算權(quán)值矩陣,得到8個(gè)不同的矩陣z
? ? ? ?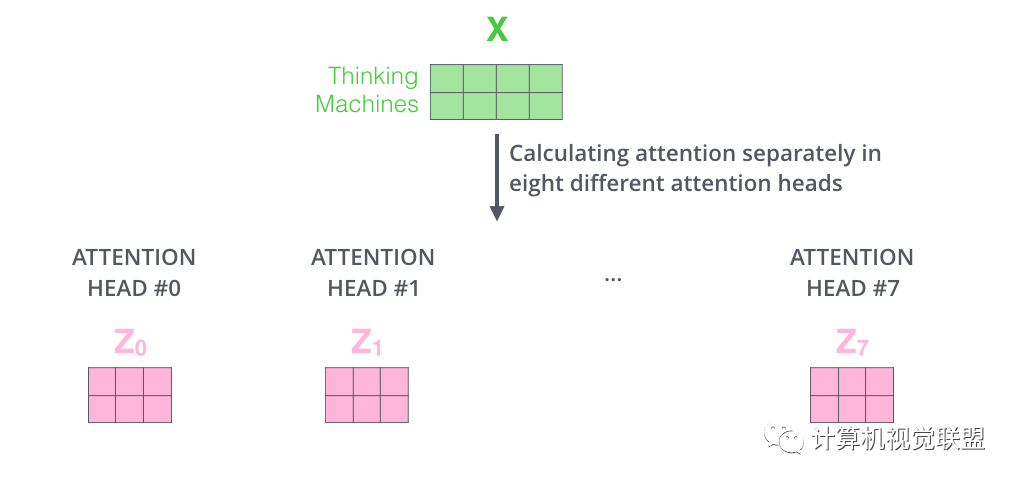 ? ? ?
? ? ?
把這8個(gè)矩陣鏈接在一起,然后再與矩陣Wo相乘
? ? ? ?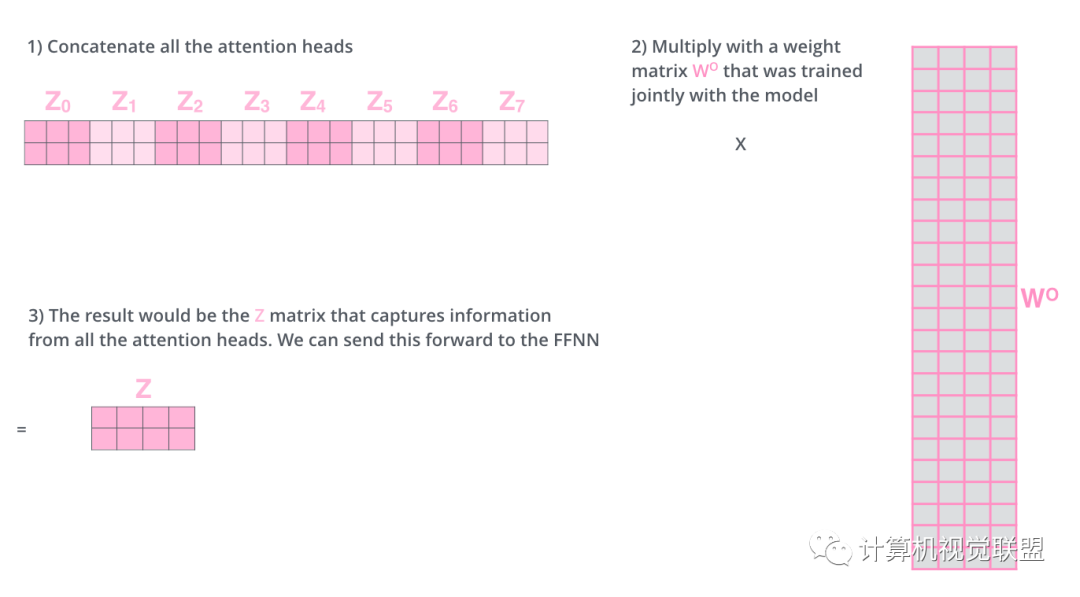 ? ? ?
? ? ?
整體過(guò)程
? ? ? ? ? ? ?
? ? ?
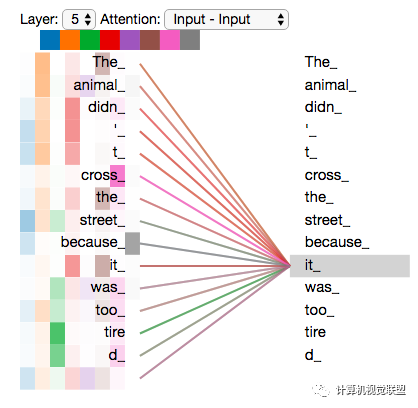
我們隨意找兩個(gè)不同的attention header的情況(8列,取下下圖的2,3列),看一下關(guān)注點(diǎn)會(huì)有什么區(qū)別
? ? ? ? ? ? ?
? ? ?
這兩個(gè)時(shí)間戳上面,發(fā)現(xiàn)it最關(guān)注兩個(gè):animal和tire
將所有注意力都添加到圖片上,可能不那么容易理解其中含義
? ? ? ? ? ? ?
? ? ?
五、使用位置編碼
輸入序列還要考慮單詞的順序的問(wèn)題
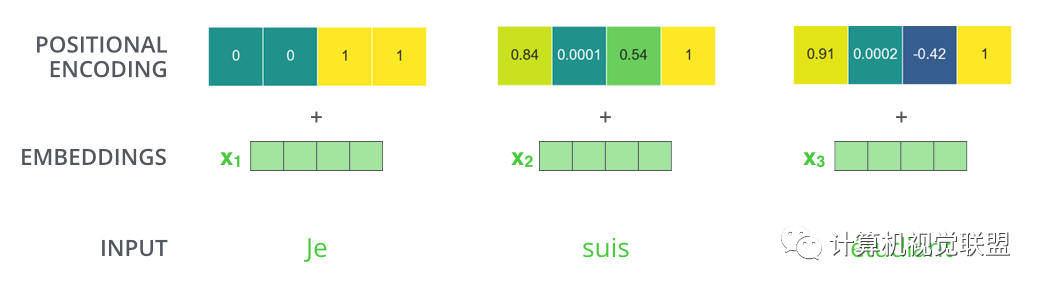
transformer為每個(gè)輸入單詞的詞嵌入了一個(gè)新的位置向量。
? ? ? ? ? ? ?
? ? ?
為了讓模型知道單詞的順序信息,將位置編碼的向量信息直接進(jìn)行規(guī)則產(chǎn)生
比如嵌入的維度是4,實(shí)際編碼效果如下:
? ? ? ? ? ? ?
? ? ?
編碼規(guī)則
? ? ? ?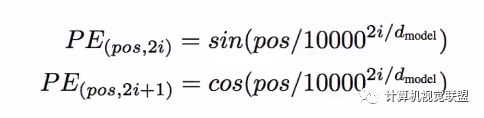 ? ? ?
? ? ?
? ? ? ? ? ? ?
? ? ?
比如20個(gè)單詞,每個(gè)單詞編碼為512維度。
一共20行,那么每一行就表示一個(gè)詞向量,包含512個(gè)值,每個(gè)值在-1到1之間。可視化顯示:
? ? ? ? ? ? ?
? ? ?
中心位置一分為2,主要是一半是正弦生成,一半是余弦生成。
對(duì)上述的Transformer2Transformer有細(xì)微改變顯示的話:
? ? ? ? ? ? ?
? ? ?
import numpy as npimport matplotlib.pyplot as plt# https://github.com/jalammar/jalammar.github.io/blob/master/notebookes/transformer/transformer_positional_encoding_graph.ipynb# Code from https://www.tensorflow.org/tutorials/text/transformerdef get_angles(pos, i, d_model):angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))return pos * angle_ratesdef positional_encoding(position, d_model):angle_rads = get_angles(np.arange(position)[:, np.newaxis],np.arange(d_model)[np.newaxis, :],d_model)# apply sin to even indices in the array; 2iangle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])# apply cos to odd indices in the array; 2i+1angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])pos_encoding = angle_rads[np.newaxis, ...]return pos_encodingtokens = 10dimensions = 64pos_encoding = positional_encoding(tokens, dimensions)print (pos_encoding.shape)plt.figure(figsize=(12,8))plt.pcolormesh(pos_encoding[0], cmap='viridis')plt.xlabel('Embedding Dimensions')plt.xlim((0, dimensions))plt.ylim((tokens,0))plt.ylabel('Token Position')plt.colorbar()plt.show()
?
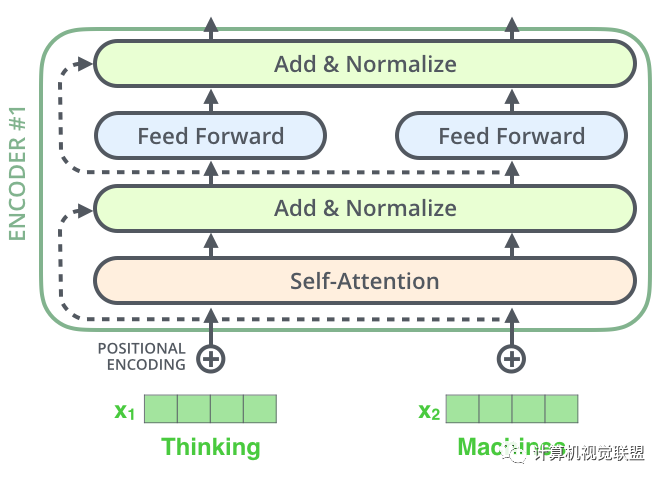
六、殘差神經(jīng)網(wǎng)絡(luò) Residuals
layer-normalization步驟
? ? ? ?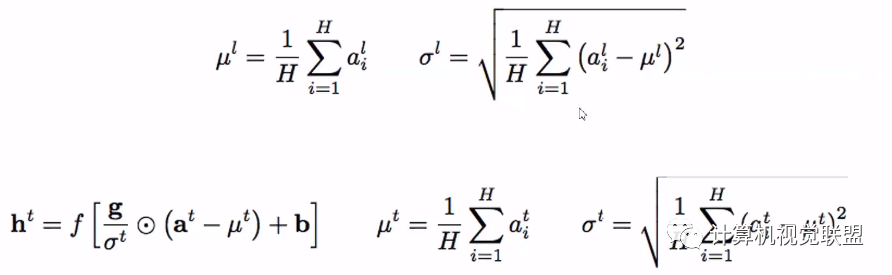 ? ? ?
? ? ?
? ? ? ? ? ? ?
? ? ?
?
?
? ? ? ? ? ? ?
? ? ?
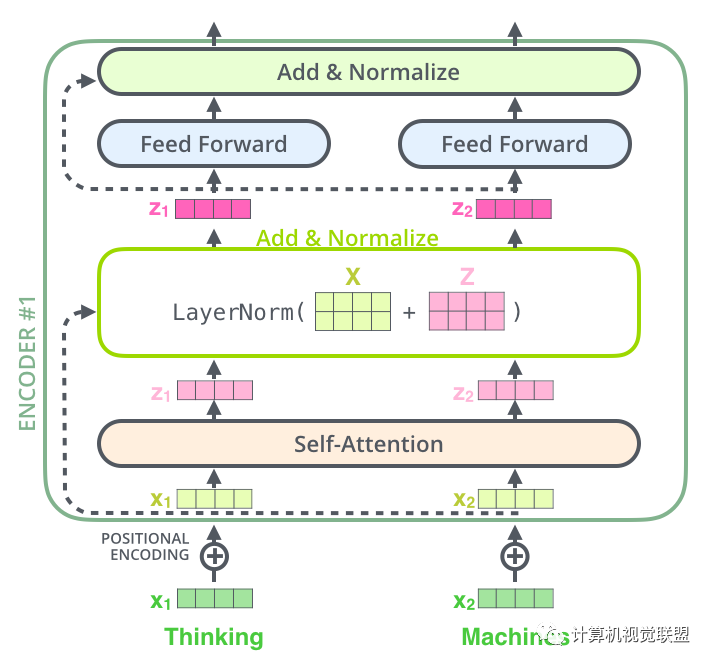
進(jìn)一步可視化
? ? ? ? ? ? ?
? ? ?
Decoder部分和這個(gè)是同樣的。我們堆疊了2個(gè)Encoder和2個(gè)Decoder
? ? ? ?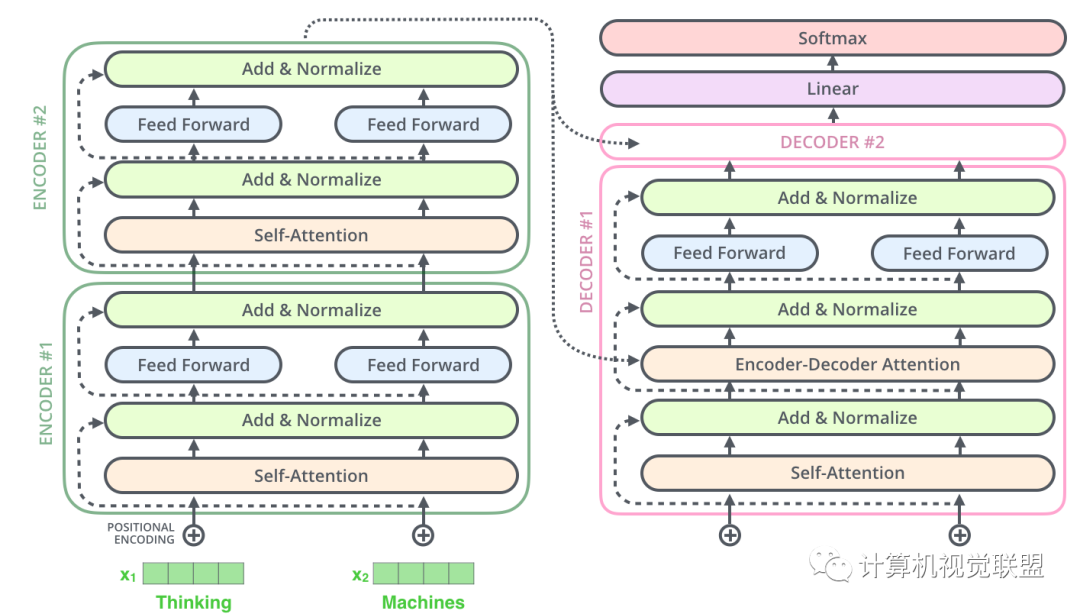 ? ? ?
? ? ?
七、Decoder
Encoder將其轉(zhuǎn)化為一組attention的集合(K,V)
? ? ? ?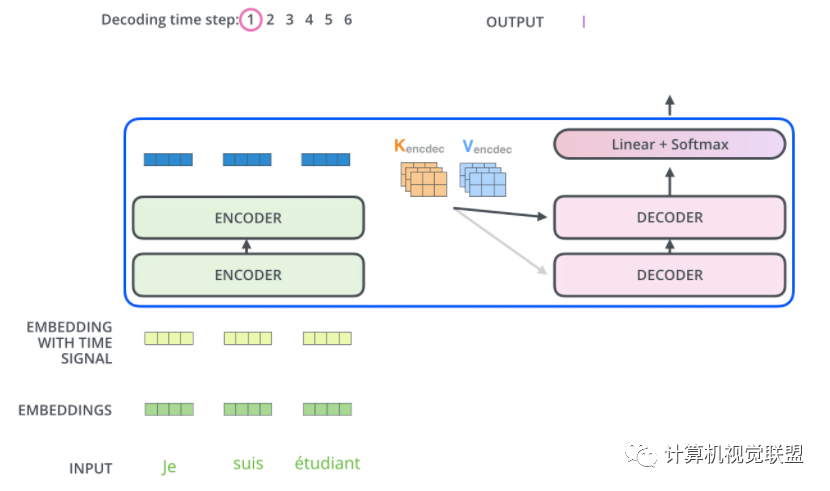 ? ? ?
? ? ?
八、Linear 和 Softmax層
線性層是一個(gè)簡(jiǎn)單的全連接神經(jīng)網(wǎng)絡(luò),由Decoder產(chǎn)生的向量投影到一個(gè)更大的向量中,成為對(duì)數(shù)向量Logits.
假設(shè)實(shí)驗(yàn)?zāi)P偷恼Z(yǔ)料庫(kù)一共1萬(wàn)個(gè)英語(yǔ)單詞,那么Logits的矢量表示1萬(wàn)個(gè)小格子,每個(gè)小格子就表示了一個(gè)單詞。
線性層之后是一個(gè)Softmax層,Softmax層可以通過(guò)轉(zhuǎn)換將分?jǐn)?shù)轉(zhuǎn)換為概率,選取概率最高的作為索引,然后通過(guò)索引找到單詞作為輸出
? ? ? ?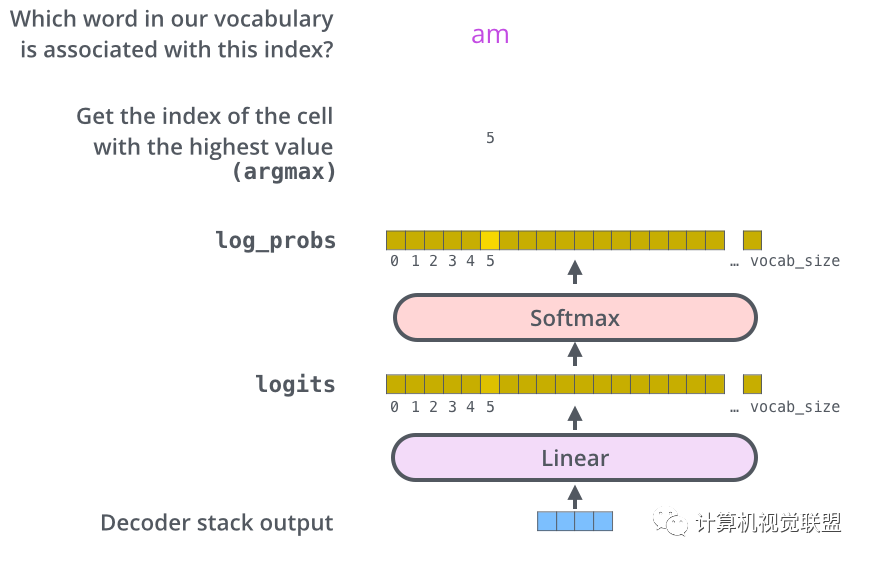 ? ? ?
? ? ?
九、回顧訓(xùn)練過(guò)程
假設(shè)輸出的詞匯只有“a”、“am”、“I”、“thanks”、“student”、“
? ? ? ?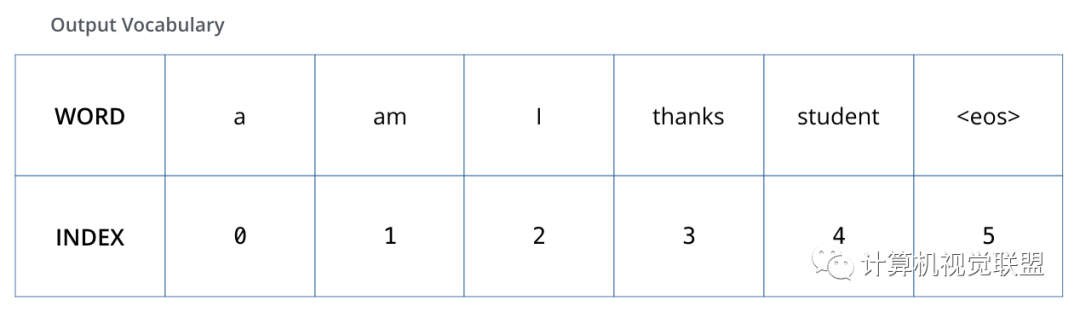 ? ? ?
? ? ?
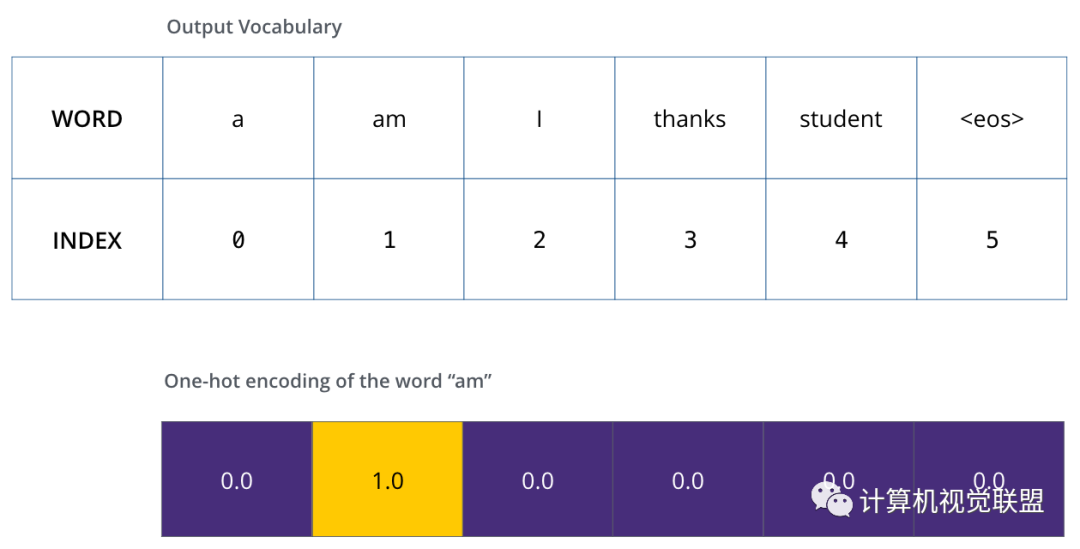
一旦確定了輸出的詞匯表,就可以使用相同寬度的向量來(lái)表示詞匯表中的單詞,稱為one-hot編碼
舉例子以句子中的“am”為例子,one-hot編碼
? ? ? ? ? ? ?
? ? ?
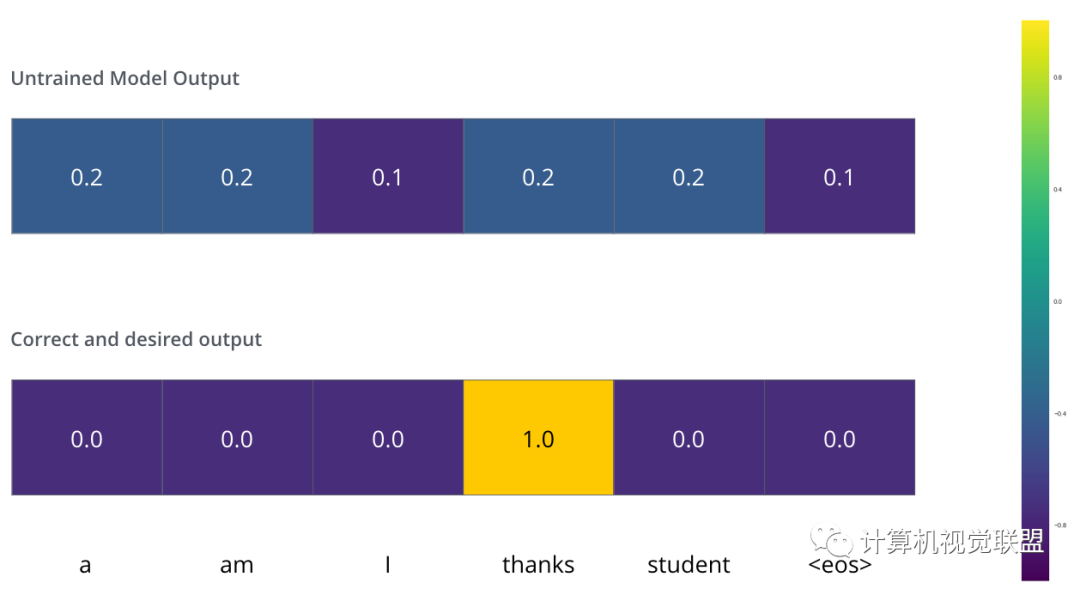
Loss Function
模型的參數(shù)權(quán)重是隨機(jī)初始化的
? ? ? ? ? ? ?
? ? ?
實(shí)際上做一個(gè)簡(jiǎn)單的減法就行
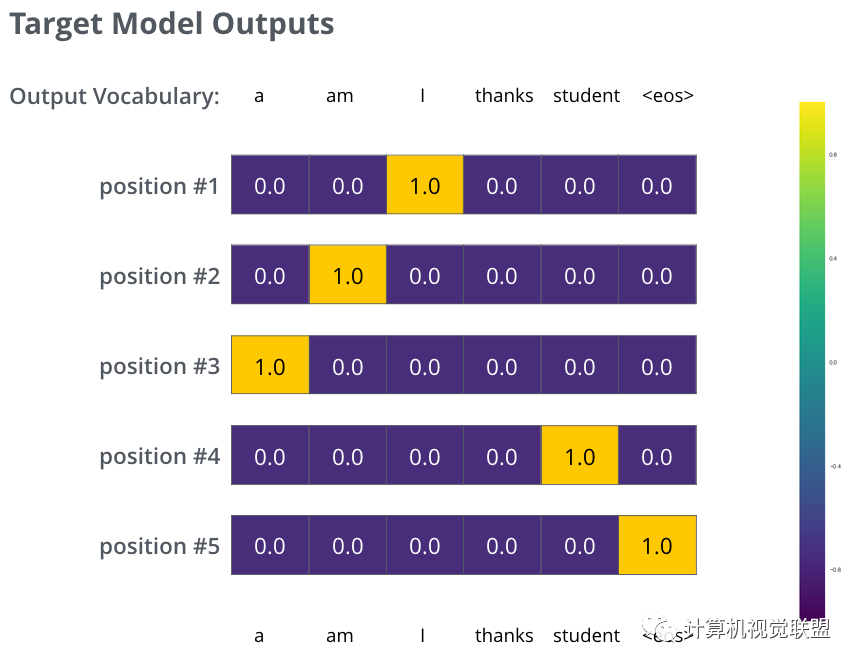
Target Model Outputs
? ? ? ? ? ? ?
? ? ?
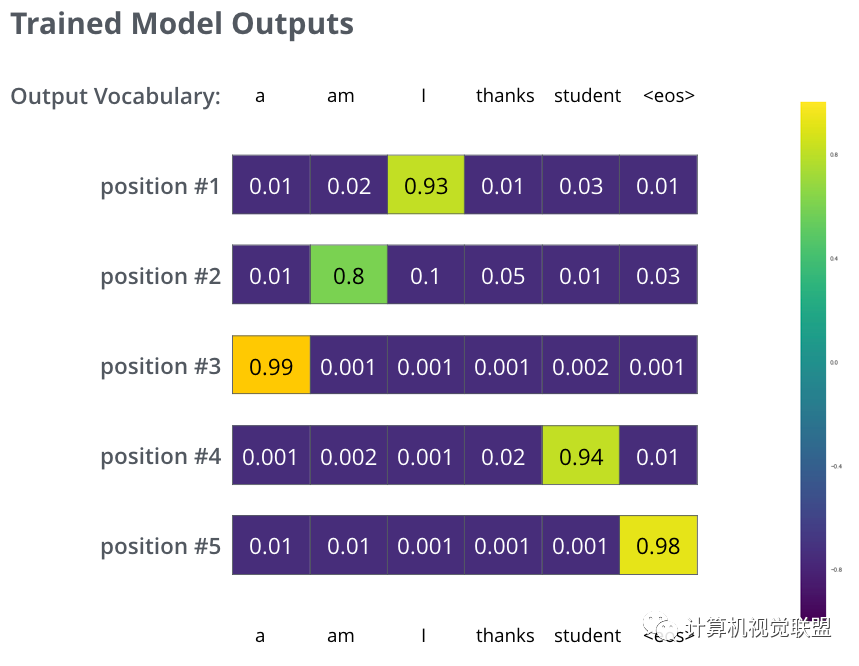
Trained Model Outputs
? ? ? ? ? ? ?
? ? ?
雖然沒(méi)有那么準(zhǔn)確,但是通過(guò)比較可以找到最大的概率值
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~