
博士筆記 | 深入理解深度學(xué)習(xí)語義分割
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)
本文轉(zhuǎn)自|機(jī)器學(xué)習(xí)初學(xué)者

本文內(nèi)容概述王博Kings最近的語義分割學(xué)習(xí)筆記總結(jié)
引言:最近自動駕駛項(xiàng)目需要學(xué)習(xí)一些語義分割的內(nèi)容,所以看了看論文和視頻做了一個簡單的總結(jié)。筆記思路是:機(jī)器學(xué)習(xí)-->>深度學(xué)習(xí)-->>語義分割
目錄:
機(jī)器學(xué)習(xí)回顧
深度學(xué)習(xí)回顧
語義分割簡介
語義分割代表算法
一、回顧機(jī)器學(xué)習(xí)


二、深度學(xué)習(xí)回顧
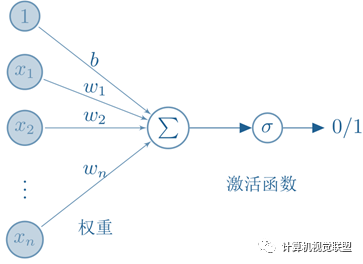
激活函數(shù)


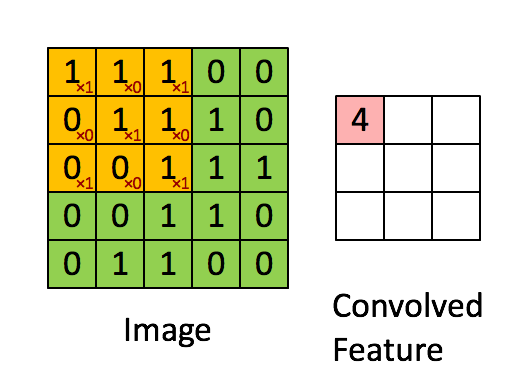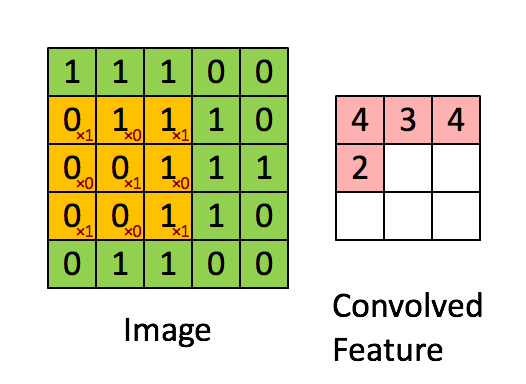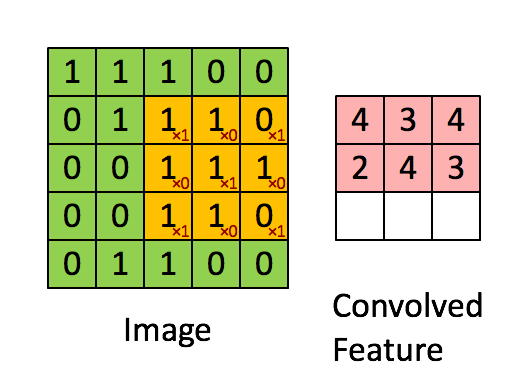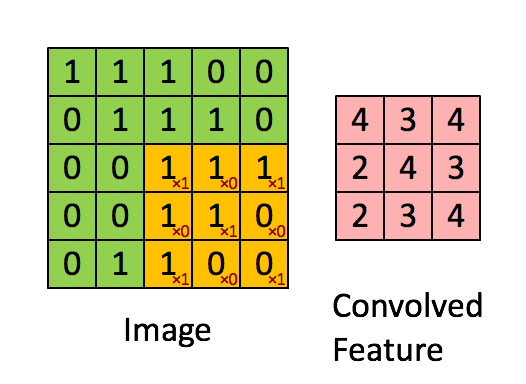
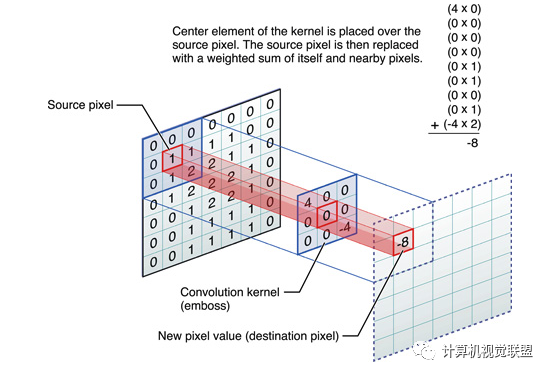
這些卷積是語義分割的一個核心內(nèi)容!
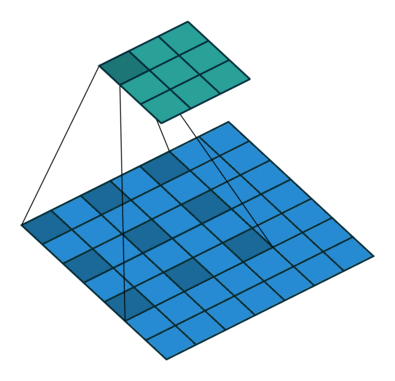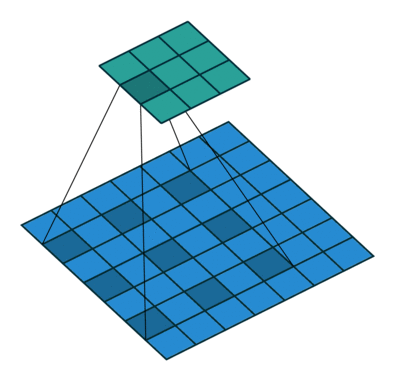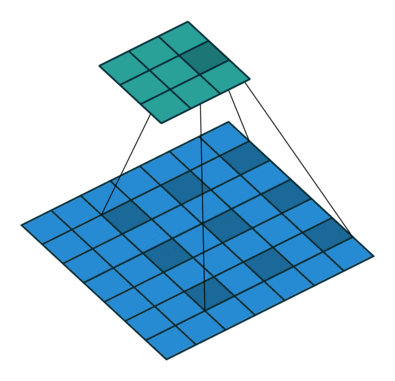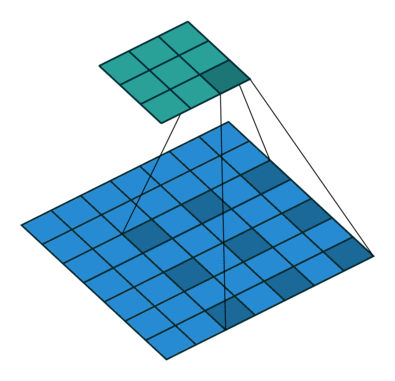
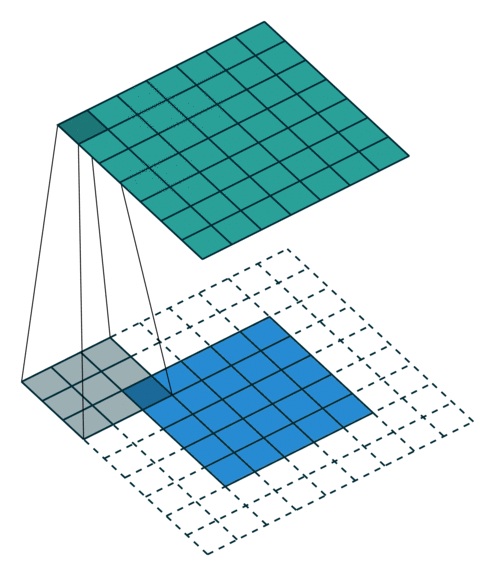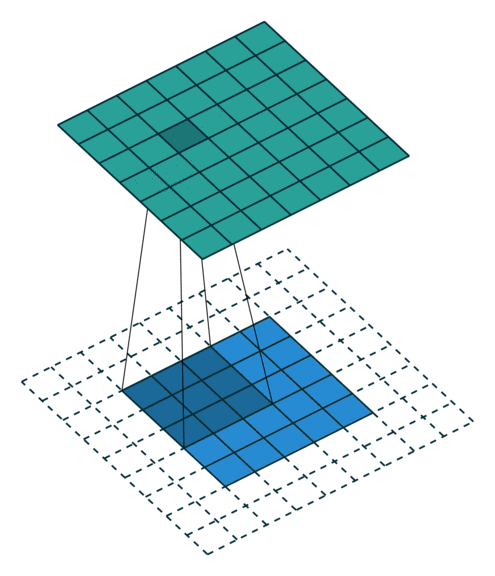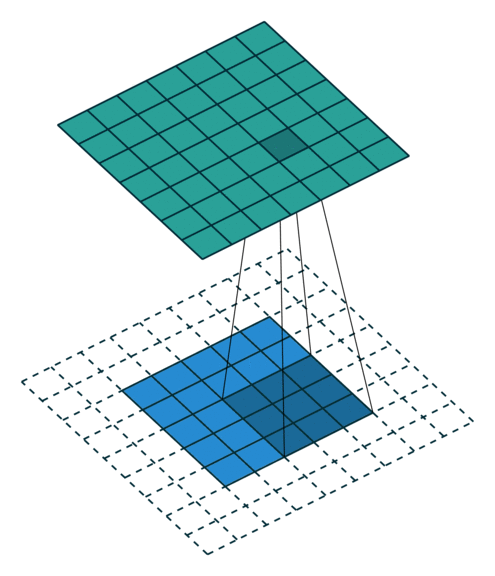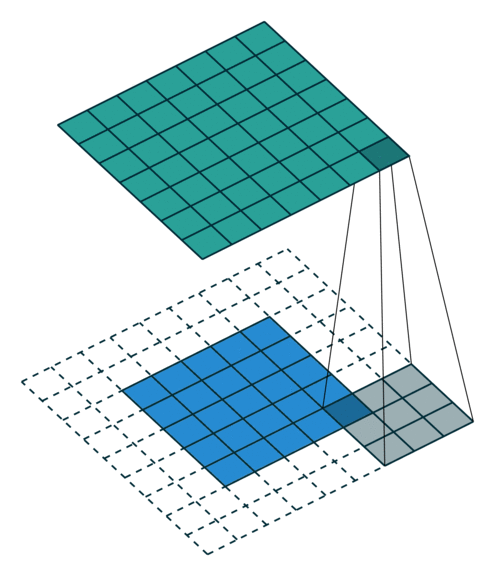
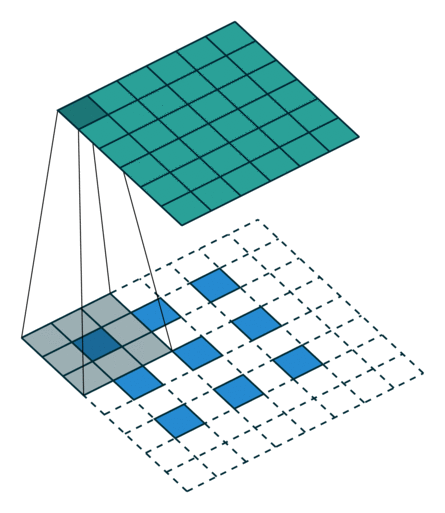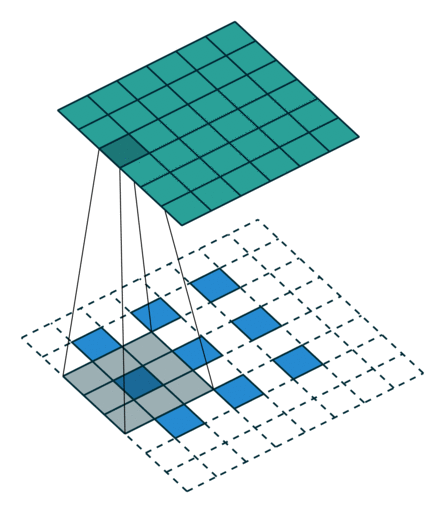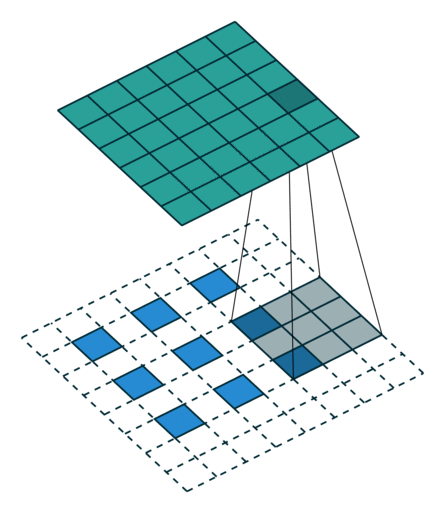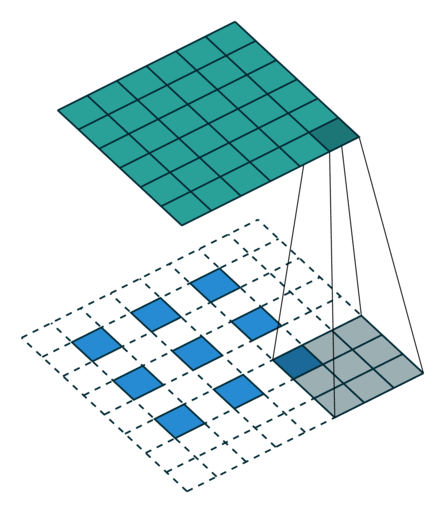
三、語義分割簡介
什么是語義分割?
ü語義分割(semantic segmentation):按照“語義”給圖像上目標(biāo)類別的每一個點(diǎn)打一個標(biāo)簽,使得不同種類的東西在圖像上區(qū)分開,可以理解為像素級別的分類任務(wù)。

語義分割有哪些評價(jià)指標(biāo)?
ü1.像素精度(pixel accuracy ):每一類像素正確分類的個數(shù)/ 每一類像素的實(shí)際個數(shù)。
ü2.均像素精度(mean pixel accuracy ):每一類像素的精度的平均值。
ü3.平均交并比(Mean Intersection over Union):求出每一類的IOU取平均值。IOU指的是兩塊區(qū)域相交的部分/兩個部分的并集,如figure2中 綠色部分/總面積。
ü4.權(quán)頻交并比(Frequency Weight Intersectionover Union):每一類出現(xiàn)的頻率作為權(quán)重
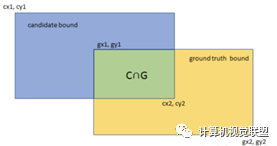
四、語義分割代表算法
全卷積網(wǎng)絡(luò) FullyConvolutional Networks
2015年《Fully Convolutional Networks for SemanticSegmentation》
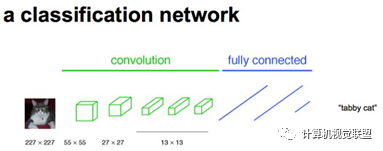
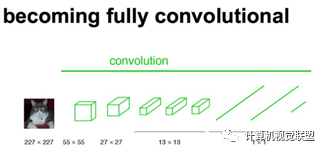
通常CNN網(wǎng)絡(luò)在卷積層之后會接上若干個全連接層, 將卷積層產(chǎn)生的特征圖(feature map)映射成一個固定長度的特征向量。
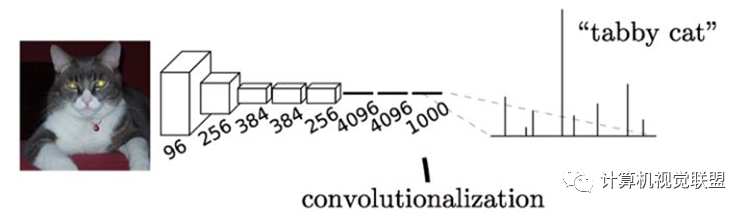
輸入AlexNet, 得到一個長為1000的輸出向量, 表示輸入圖像屬于每一類的概率, 其中在“tabby cat”這一類統(tǒng)計(jì)概率最高。
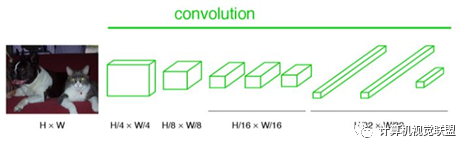
與經(jīng)典的CNN在卷積層之后使用全連接層得到固定長度的特征向量進(jìn)行分類(全聯(lián)接層+softmax輸出)不同,F(xiàn)CN可以接受任意尺寸的輸入圖像,采用反卷積層對最后一個卷積層的feature map進(jìn)行上采樣, 使它恢復(fù)到輸入圖像相同的尺寸,從而可以對每個像素都產(chǎn)生了一個預(yù)測, 同時保留了原始輸入圖像中的空間信息, 最后在上采樣的特征圖上進(jìn)行逐像素分類。
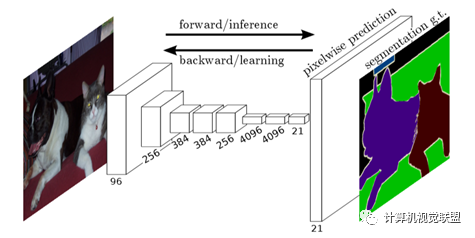
簡單的來說,F(xiàn)CN與CNN的區(qū)域在把于CNN最后的全連接層換成卷積層,輸出的是一張已經(jīng)Label好的圖片。
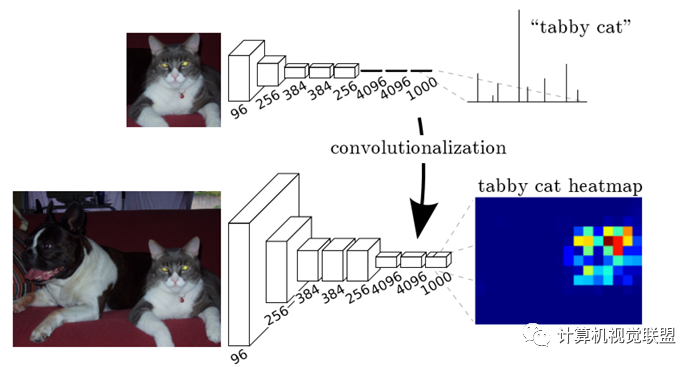

有沒有缺點(diǎn)?
是得到的結(jié)果還是不夠精細(xì)。進(jìn)行8倍上采樣雖然比32倍的效果好了很多,但是上采樣的結(jié)果還是比較模糊和平滑,對圖像中的細(xì)節(jié)不敏感。
是對各個像素進(jìn)行分類,沒有充分考慮像素與像素之間的關(guān)系。忽略了在通常的基于像素分類的分割方法中使用的空間規(guī)整(spatialregularization)步驟,缺乏空間一致性。
對于任何的分類神經(jīng)網(wǎng)絡(luò)我們都可以用卷積層替換FC層,只是換了一種信息的分布式表示。如果我們直接把Heatmap上采樣,就得到FCN-32s。
三種模型FCN-32S,FCN-16S, FCN-8S
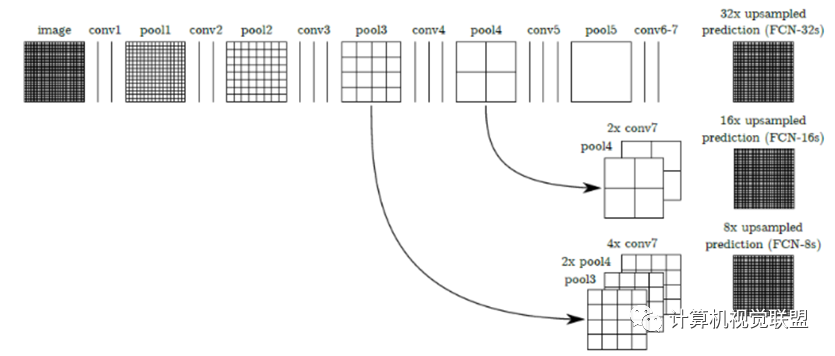
主要貢獻(xiàn):
ü不含全連接層(fc)的全卷積(fully conv)網(wǎng)絡(luò)。可適應(yīng)任意尺寸輸入。
ü增大數(shù)據(jù)尺寸的反卷積(deconv)層。能夠輸出精細(xì)的結(jié)果。
ü結(jié)合不同深度層結(jié)果的跳級(skip)結(jié)構(gòu)。同時確保魯棒性和精確性。
缺點(diǎn):
?得到的結(jié)果還是不夠精細(xì)。進(jìn)行8倍上采樣雖然比32倍的效果好了很多,但是上采樣的結(jié)果還是比較模糊和平滑,對圖像中的細(xì)節(jié)不敏感。
?是對各個像素進(jìn)行分類,沒有充分考慮像素與像素之間的關(guān)系。忽略了在通常的基于像素分類的分割方法中使用的空間規(guī)整(spatial regularization)步驟,缺乏空間一致性。
SegNet
2015年《SegNet: A DeepConvolutionalEncoder-Decoder Architecture for Image Segmentation》
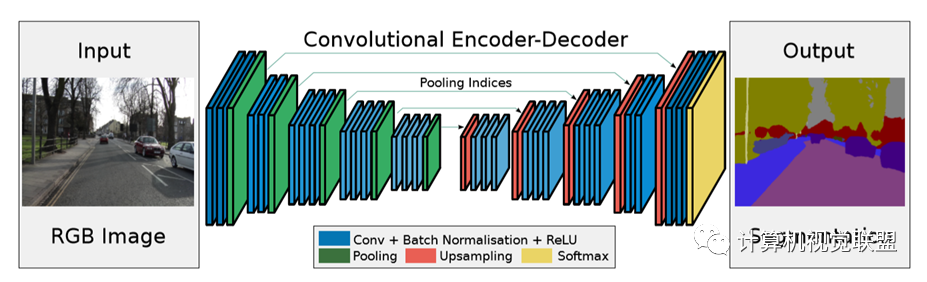
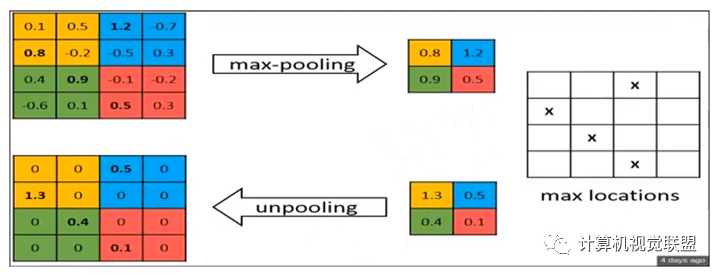
最大池化:反卷積
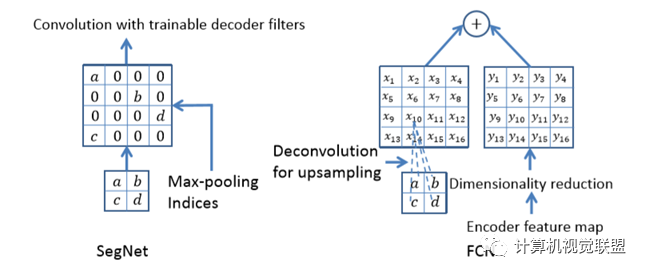
與FCN對比,SegNet的差別就在于上采樣反卷積
U-Net
2015年《U-Net:Convolutional Networks for Biomedical ImageSegmentation》
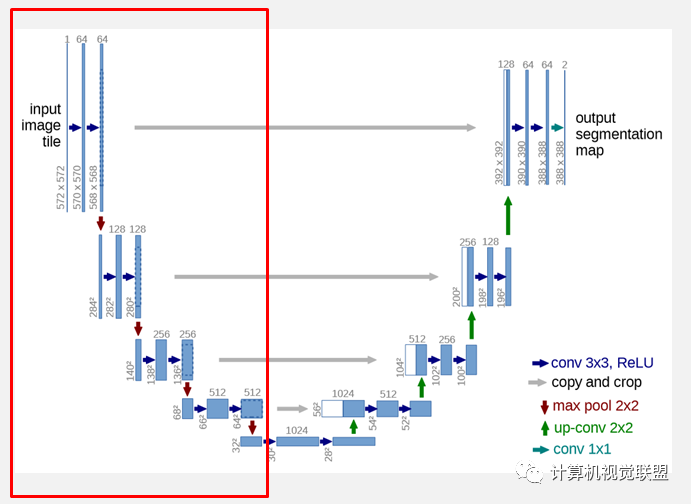
網(wǎng)絡(luò)的左側(cè)(紅色虛線)是由卷積和Max Pooling構(gòu)成的一系列降采樣操作,論文中將這一部分叫做壓縮路徑(contracting path)。壓縮路徑由4個block組成,每個block使用了3個有效卷積和1個Max Pooling降采樣,每次降采樣之后Feature Map的個數(shù)乘2,因此有了圖中所示的Feature Map尺寸變化。最終得到了尺寸為 的Feature Map。
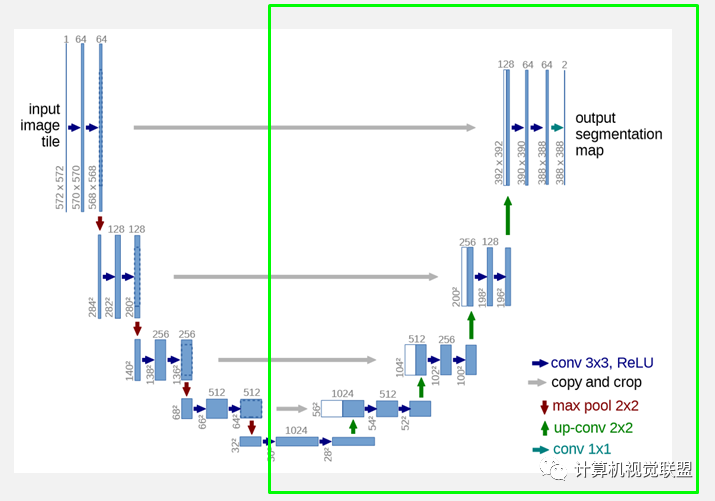
網(wǎng)絡(luò)的右側(cè)部分(綠色虛線)在論文中叫做擴(kuò)展路徑(expansive path)。同樣由4個block組成,每個block開始之前通過反卷積將Feature Map的尺寸乘2,同時將其個數(shù)減半(最后一層略有不同),然后和左側(cè)對稱的壓縮路徑的Feature Map合并,由于左側(cè)壓縮路徑和右側(cè)擴(kuò)展路徑的Feature Map的尺寸不一樣,U-Net是通過將壓縮路徑的Feature Map裁剪到和擴(kuò)展路徑相同尺寸的Feature Map進(jìn)行歸一化的(即圖1中左側(cè)虛線部分)。擴(kuò)展路徑的卷積操作依舊使用的是有效卷積操作,最終得到的Feature Map的尺寸是 。由于該任務(wù)是一個二分類任務(wù),所以網(wǎng)絡(luò)有兩個輸出Feature Map。
U-Net沒有利用池化位置索引信息,而是將編碼階段的整個特征圖傳輸?shù)较鄳?yīng)的解碼器(以犧牲更多內(nèi)存為代價(jià)),并將其連接,再進(jìn)行上采樣(通過反卷積),從而得到解碼器特征圖。
DeepLabV1
2015年《Semantic image segmentation withdeep convolutional nets and fully connected CRFs》
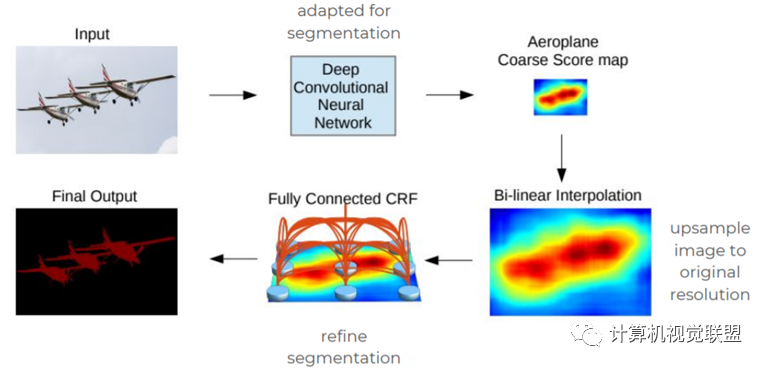
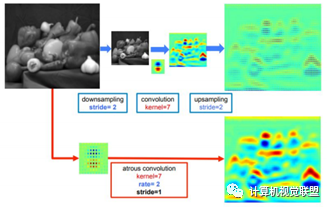
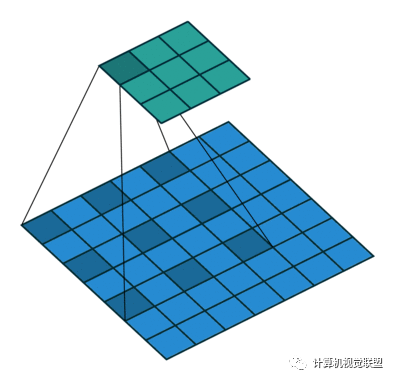
感受野變大
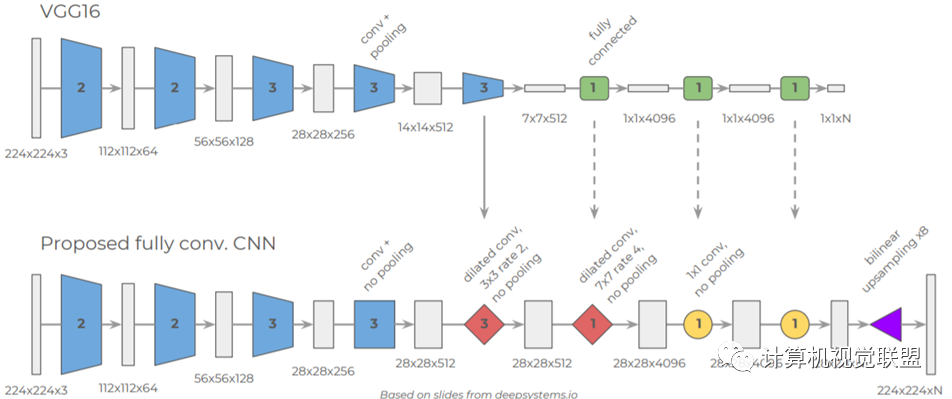
DeepLabV2
2015年《DeepLab-v2: Semantic ImageSegmentation 》
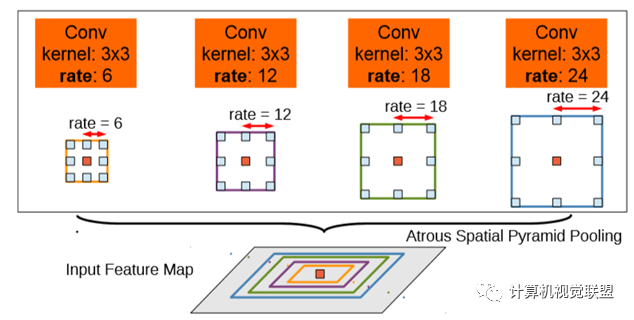
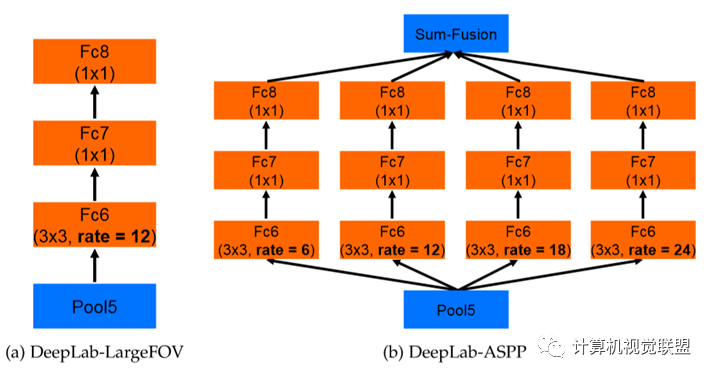
ASPP,空洞卷積池化金字塔;VGG改為ResNet
DeepLabv2是采用全連接的CRF來增強(qiáng)模型捕捉細(xì)節(jié)的能力。
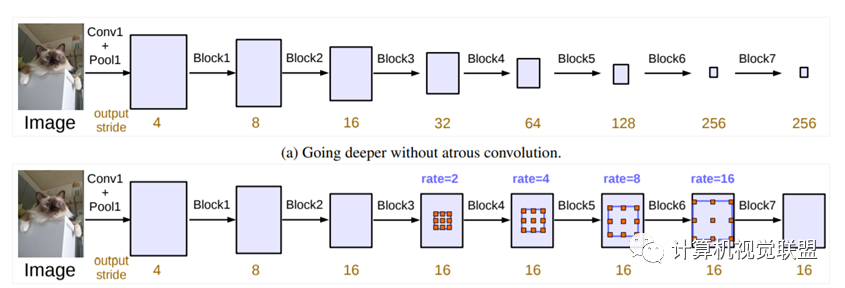
DeepLabv2在最后幾個最大池化層中去除了下采樣的層,取而代之的是使用空洞卷積
DeepLabV3
2017年《Rethinking Atrous Convolution for Semantic ImageSegmentation》
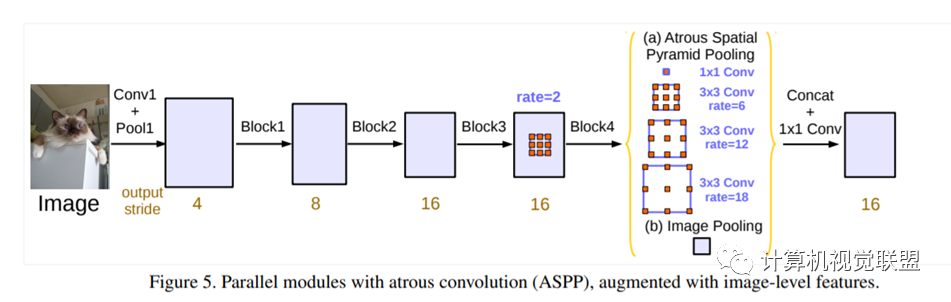
DeepLabV3+
2018年《Encoder-Decoder with Atrous Separable Convolution for SemanticImage Segmentation》
使用了兩種類型的神經(jīng)網(wǎng)絡(luò),使用空間金字塔模塊和encoder-decoder結(jié)構(gòu)做語義分割。
ü空間金字塔:通過在不同分辨率上以池化操作捕獲豐富的上下文信息
üencoder-decoder架構(gòu):逐漸的獲得清晰的物體邊界
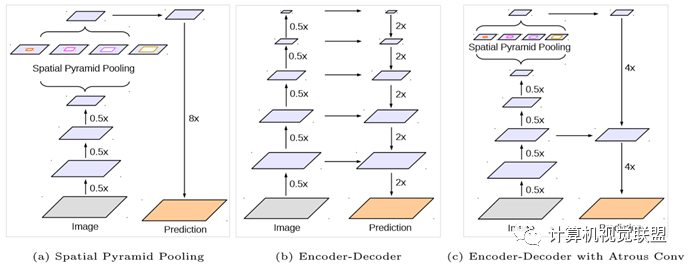
Encoder
Encoder就是原來的DeepLabv3,注意點(diǎn)有2點(diǎn):
輸入尺寸與輸出尺寸比(outputstride = 16),最后一個stage的膨脹率rate為2
AtrousSpatial Pyramid Pooling module(ASPP)有四個不同的rate,額外一個全局平均池化
Decoder
明顯看到先把encoder的結(jié)果上采樣4倍,然后與resnet中下采樣前的Conv2特征concat一起,再進(jìn)行3x3的卷積,最后上采樣4倍得到最終結(jié)果
需要注意點(diǎn):
融合低層次信息前,先進(jìn)行1x1的卷積,目的是降通道(例如有512個通道,而encoder結(jié)果只有256個通道)
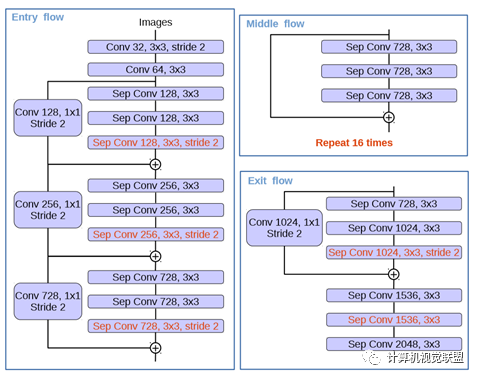
紅色部分為修改
(1)更多層:重復(fù)8次改為16次(基于MSRA目標(biāo)檢測的工作)。
(2)將原來簡單的pool層改成了stride為2的deepwishseperable convolution。
(3)額外的RELU層和歸一化操作添加在每個 3 × 3 depthwise convolution之后(原來只在1*1卷積之后)
DeepLabv1:https://arxiv.org/pdf/1412.7062v3.pdf
DeepLabv2:https://arxiv.org/pdf/1606.00915.pdf
DeepLabv3:https://arxiv.org/pdf/1706.05587.pdf
DeepLabv3+:https://arxiv.org/pdf/1802.02611.pdf
代碼:https://github.com/tensorflow/models/tree/master/research/deeplab
end
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計(jì)算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~