
經(jīng)驗之談|處理不平衡數(shù)據(jù)集的7個技巧
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

作者:Ye Wu & Rick Radewagen
編譯:ronghuaiyang
具體的領(lǐng)域中的數(shù)據(jù)集是什么樣的,銀行中的欺詐檢測,市場中的實(shí)時投標(biāo),網(wǎng)絡(luò)中的入侵檢測,常見嗎?
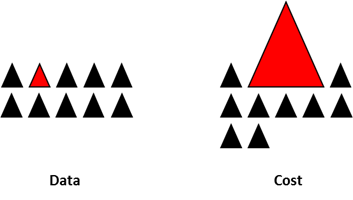
這些領(lǐng)域中的數(shù)據(jù),常常只有不到1%的少數(shù),但是“有興趣”的事件(如信用卡欺詐,用戶的廣告點(diǎn)擊或者掃描網(wǎng)絡(luò)時的服務(wù)器的崩潰)。但是,大多數(shù)的機(jī)器學(xué)習(xí)的算法在非平衡數(shù)據(jù)集上表現(xiàn)的都不太好。下面的這些技巧可以幫助你,訓(xùn)練一個分類器來檢測異常類。

在不均衡數(shù)據(jù)集上訓(xùn)練出來的模型,如果使用不合適的度量方法的話,是很危險的。想象一下,如果你的數(shù)據(jù)集是上面的圖的情況,如果度量方法是準(zhǔn)確率的話,那么一個模型如果對所有的樣本預(yù)測都是0的話,準(zhǔn)確率將達(dá)到非常好的99.8%,但是很顯然,這種模型并沒有什么鳥用。
這種情況下,可以使用一些替代的度量方法,例如:
精確度/特異性:正樣本的預(yù)測準(zhǔn)確率。
召回率/敏感性:所有預(yù)測為正樣本的數(shù)據(jù)的準(zhǔn)確率。
F1得分:精確率和召回率的調(diào)和平均。
MCC:真陽率(tpr)和假陽率(fpr)的關(guān)系。
除了使用不同的評價方法外,還可以想辦法得到不同的數(shù)據(jù)集。有兩個方法來得到平衡的數(shù)據(jù)集,一個是欠采樣,一個是過采樣。
欠采樣通過減小多數(shù)類別的樣本數(shù)量來得到平衡的數(shù)據(jù)集。這種方法用在數(shù)據(jù)量足夠的情況下。保留所有的少數(shù)類別的樣本,隨機(jī)的抽取同樣數(shù)量的多數(shù)類別樣本,可以得到一個均衡的新的數(shù)據(jù)集,用來建模。
相反,過采樣用在數(shù)據(jù)集不夠的情況下。通過增加少數(shù)類的樣本數(shù)量來得到平衡的數(shù)據(jù)集。這次我們不是丟掉多數(shù)類的樣本,而是通過重復(fù),自助抽樣或者SMOTE (合成少數(shù)類過采樣)來生成少數(shù)類的數(shù)據(jù)。
注意,這兩種重新采樣的方法并沒有絕對的好壞之分。使用哪種方法取決于實(shí)際的數(shù)據(jù)集的情況。將兩種方法組合使用也往往是可以的。
需要注意一下,當(dāng)使用過采樣來解決不均衡數(shù)據(jù)集的問題的時候,需要適當(dāng)?shù)氖褂媒徊骝炞C。
需要記住,過采樣使用少數(shù)類的樣本,使用自助抽樣(有放回的隨機(jī)抽樣)是基于分布函數(shù)來生成新的隨機(jī)數(shù)據(jù)。如果在過采樣之后使用了交叉驗證,基本上,我們所做的事情就是將模型過擬合成一個特定的人工采樣的結(jié)果。這就是為什么需要在過采樣數(shù)據(jù)之前使用交叉驗證,就像如何來進(jìn)行特征選擇一樣。只有在對數(shù)據(jù)進(jìn)行重復(fù)采樣的時候,才可以對數(shù)據(jù)集引入隨機(jī)性來確保不會有過擬合的問題。
最簡單的泛化模型的方法就是使用更多的數(shù)據(jù)。問題在于像邏輯回歸和隨機(jī)森林的分類器趨向于在泛化的時候忽略掉少數(shù)類。一個簡單的最佳實(shí)踐是使用所有的少數(shù)類和n個不同的多數(shù)類組成n個不同的數(shù)據(jù)集,構(gòu)建模型。比如你要集成10個模型,你保留1000個少數(shù)類的樣本,隨機(jī)選取10000個多數(shù)類的樣本,然后將這10000個多數(shù)類的樣本分成10份,組成10個數(shù)據(jù)集,訓(xùn)練10個模型。
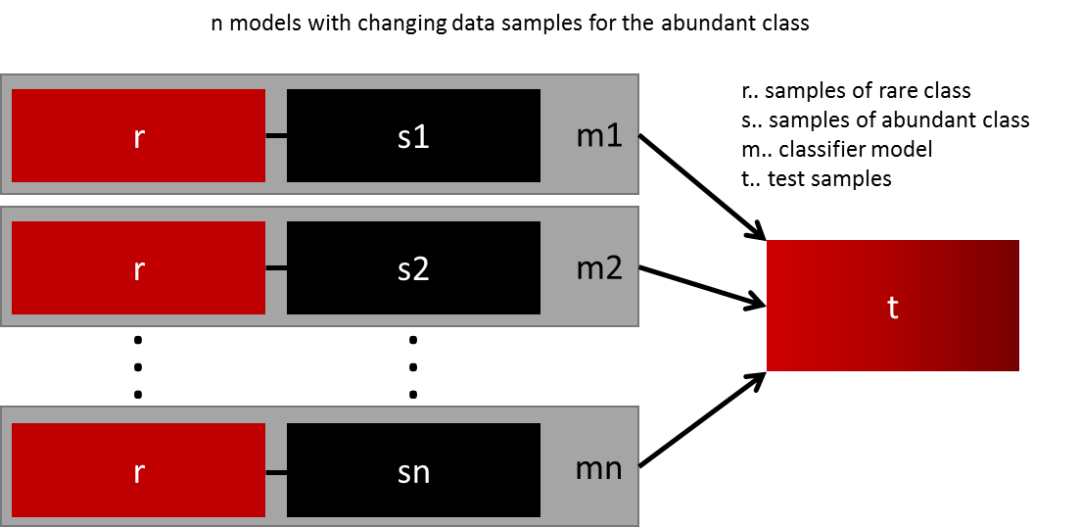
這個方法簡單有效,適用于有很多數(shù)據(jù),而且可以完美的橫向擴(kuò)展,因為你只需要在不同的集群的節(jié)點(diǎn)上訓(xùn)練和運(yùn)行模型就可以了。集成的模型的泛化能力也會更好,這個方法簡單易用。
前面的方法可以通過調(diào)整少數(shù)和多數(shù)類的比例來微調(diào)。最佳的比例依賴于數(shù)據(jù)和使用的模型。不要使用同樣的比例訓(xùn)練模型來集成,可以試試集成不同的比例。所以,如果訓(xùn)練了10個模型,那么使用模型具有1:1,1:2,甚至2:1,取決于用的模型,這個可以影響到一個類別得到的權(quán)值。
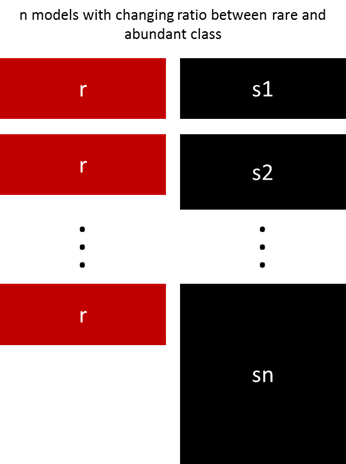
Sergey提出了一個優(yōu)雅的方法。不是通過隨機(jī)采樣的方式來覆蓋訓(xùn)練樣本的多樣性,他建議將多數(shù)類聚類成r個組,這個r是樣本的數(shù)量。對于每一個組,樣本中心保留下來,然后使用少數(shù)類和樣本中心進(jìn)行模型的訓(xùn)練。
以上所有的方法聚焦在數(shù)據(jù)上,將模型作為一個固定的部分。但是實(shí)際上,如果模型本身就是適用于非均衡數(shù)據(jù)的話,就不需要對數(shù)據(jù)進(jìn)行重復(fù)的采樣了。著名的XGBoost就是一個很好的嘗試,如果類別不是非常的不均衡的話,因為這個算法內(nèi)部本身就有在不均衡數(shù)據(jù)上集成學(xué)習(xí)的功能,當(dāng)然,也會做重復(fù)采樣,只不過是悄悄做的。
設(shè)計一個損失函數(shù),對于錯誤分類的少數(shù)類的樣本的懲罰要比多數(shù)類更大,設(shè)計許多的模型,自然的支持少數(shù)類別的泛化,也是可行的。例如,修改一下SVM中對少數(shù)類的錯誤分類的懲罰,設(shè)為多數(shù)樣本數(shù)量和少數(shù)樣本數(shù)量的比例。
這個并不是所有的技巧,只是一個處理不均衡數(shù)據(jù)的開端。沒有哪個方法或者模型可以解決所有的問題,建議嘗試不同的方法和模型來對工作進(jìn)行評估。試著去創(chuàng)造和組合不同的方法。還有一點(diǎn)很重要,在許多的場景中(欺詐檢測,實(shí)時投標(biāo)),但出現(xiàn)不均衡類別的時候,“市場規(guī)則”是不斷在變的,看看之前的數(shù)據(jù)是不是已經(jīng)失效了。
英文原文鏈接:https://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~